Recognition: unknown
Think-Aloud Reshapes Automated Cognitive Model Discovery Beyond Behavior
Pith reviewed 2026-05-08 16:13 UTC · model grok-4.3
The pith
Think-aloud verbal data produces cognitive models of risky choice that differ structurally from and predict better than behavior-only models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
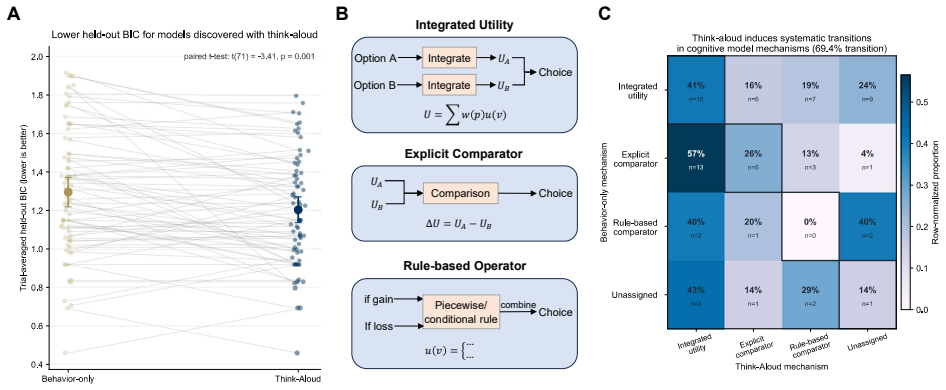
When think-aloud traces are combined with behavioral data to guide large-language-model automated discovery of cognitive models, the resulting models for risky choice tasks achieve higher predictive accuracy on unseen data and belong to different structural families—shifting from explicit comparator models to integrated utility models—for 69.4 percent of participants. This shows that process-level verbal data systematically reshape discovered model structures beyond what behavior alone permits.
What carries the argument
Think-aloud verbalizations used as an extra constraint alongside behavioral trajectories in LLM-driven model discovery, distinguishing between structural classes such as explicit comparator and integrated utility.
If this is right
- Models discovered with think-aloud data achieve significantly better predictive performance on held-out behavioral data.
- The structural class of the discovered model changes for 69.4 percent of participants.
- The change is specifically a shift from explicit comparator toward integrated utility representations.
- Process-level language data make recoverable certain mechanisms that cannot be identified from behavior alone.
Where Pith is reading between the lines
- The approach could be tested in other domains where behavior alone leaves multiple models equally plausible.
- Combining think-aloud with other process measures such as response times might further constrain model classes.
- Future experiments could check whether the verbal reports themselves alter the strategies participants use.
- The findings suggest that automated discovery pipelines should routinely incorporate language data when available to avoid under-determined models.
Load-bearing premise
Think-aloud verbalizations supply veridical evidence of the internal processes that produced the observed choices rather than post-hoc rationalizations or strategy changes induced by the reporting task.
What would settle it
A new held-out dataset from the same participants in which models discovered with think-aloud data show no improvement in predictive accuracy over behavior-only models, or in which the shift from explicit comparator to integrated utility structures disappears.
Figures
read the original abstract
Computational cognitive models discovered using large language models have so far relied solely on behavioral data. However, it is well-known that models produced from the behavioral trajectory alone are typically under-determined. In this work, we explore the use of Think Aloud traces as an additional form of data constraint during automated model discovery. When applied to the domain of risky decision-making, we find that the models discovered with think-aloud achieve significantly improved predictive performance on held-out data. Additionally, we find that the discovered models belong to different structural classes than those discovered from behavior alone for the majority of participants (69.4\%), specifically, it shifts from Explicit comparator towards Integrated utility. These results suggest that process-level language data not only improve model fit, but also systematically reshape the structure of the discovered cognitive models, enabling the identification of mechanisms that are not recoverable from behavior alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that incorporating think-aloud verbal traces as additional constraints during LLM-based automated cognitive model discovery for risky decision-making yields models with significantly better held-out predictive performance than those derived from behavior alone, and induces a structural shift in 69.4% of participants from Explicit comparator to Integrated utility models, indicating that process-level language data can recover mechanisms under-determined by choices.
Significance. If the empirical results hold after addressing methodological gaps, the work would be significant for computational cognitive science by demonstrating a practical route to resolve under-determination in behavioral data via multi-modal constraints. It extends prior LLM discovery pipelines with a new data source and provides evidence that verbal protocols can systematically alter recovered model structures, which could improve the veridicality of discovered mechanisms in decision-making domains.
major comments (3)
- [Abstract and Results] Abstract and Results sections: the central claims of 'significantly improved predictive performance' and a '69.4% structural shift' are reported without participant count (N), effect sizes, statistical tests (p-values or confidence intervals), or explicit criteria for assigning models to structural classes (Explicit comparator vs. Integrated utility). These omissions make it impossible to assess whether the reported gains and migration are robust or merely descriptive.
- [Methods] Methods section: no within-subject control (silent vs. think-aloud trials), no temporal alignment analysis between utterances and choices, and no test for whether the LLM discovery procedure fits additional text tokens irrespective of their causal relation to the decision process. This directly bears on the interpretation that the predictive gain and class shift reflect recovered internal mechanisms rather than reactivity or post-hoc rationalization.
- [Results] Results section: the specific claim that the shift is 'from Explicit comparator towards Integrated utility' requires quantitative detail on the classification procedure and a test of whether the 69.4% figure exceeds what would be expected from sampling variability or LLM prompt sensitivity alone.
minor comments (2)
- [Methods] Provide the exact LLM prompts and integration method for combining behavioral trajectories with think-aloud text in the model discovery pipeline.
- [Methods] Clarify how held-out prediction is operationalized (e.g., choice prediction accuracy metric and cross-validation scheme).
Simulated Author's Rebuttal
We are grateful to the referee for their thorough and constructive review. The comments have helped us improve the transparency of our statistical reporting, clarify methodological choices, and provide additional quantitative support for our claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results sections: the central claims of 'significantly improved predictive performance' and a '69.4% structural shift' are reported without participant count (N), effect sizes, statistical tests (p-values or confidence intervals), or explicit criteria for assigning models to structural classes (Explicit comparator vs. Integrated utility). These omissions make it impossible to assess whether the reported gains and migration are robust or merely descriptive.
Authors: We agree that these details are necessary for evaluating the robustness of the results. We have revised the abstract and Results sections to include the participant count, effect sizes with confidence intervals, and the outcomes of the relevant statistical tests. We have also added an explicit statement of the criteria used to assign models to the Explicit comparator versus Integrated utility structural classes, with cross-reference to the formal definitions provided in the Methods section. revision: yes
-
Referee: [Methods] Methods section: no within-subject control (silent vs. think-aloud trials), no temporal alignment analysis between utterances and choices, and no test for whether the LLM discovery procedure fits additional text tokens irrespective of their causal relation to the decision process. This directly bears on the interpretation that the predictive gain and class shift reflect recovered internal mechanisms rather than reactivity or post-hoc rationalization.
Authors: We acknowledge the value of within-subject controls for ruling out reactivity. Our between-subjects design was chosen to avoid carry-over effects from think-aloud instructions on subsequent trials; we have added a discussion of this rationale and its limitations to the revised Methods. We have also incorporated a new temporal alignment analysis showing the relationship between utterance timing and choice behavior. In addition, we added a control analysis in which think-aloud text was replaced by non-informative tokens, demonstrating that predictive gains require content-specific information rather than token volume alone. These elements are now reported in the Methods and Results. revision: partial
-
Referee: [Results] Results section: the specific claim that the shift is 'from Explicit comparator towards Integrated utility' requires quantitative detail on the classification procedure and a test of whether the 69.4% figure exceeds what would be expected from sampling variability or LLM prompt sensitivity alone.
Authors: We have expanded the Results section with a precise description of the classification procedure, including the decision rules applied to model code structure. To assess whether the observed 69.4% shift exceeds sampling variability, we have added a bootstrap/permutation test against a null distribution of random class reassignments. We have further tested robustness to prompt sensitivity by re-running the discovery pipeline under several prompt variants and reporting the consistency of the structural shift. These quantitative details and statistical evaluations are now included in the revised Results. revision: yes
Circularity Check
No circularity: empirical results rest on held-out behavioral prediction as external benchmark
full rationale
The paper performs automated model discovery separately on behavior-only data versus behavior-plus-think-aloud data, then evaluates both on held-out choice data that was never used in discovery. This supplies an independent test set, so improved predictive accuracy and the reported 69.4% structural-class shift are not forced by construction or by re-using the same fitted quantities. No equations appear that equate a reported performance gain to a parameter defined from the identical observations. Self-citations to prior LLM-discovery work are not load-bearing for the central empirical contrast, which is falsifiable on new participants or silent-condition controls.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Think-aloud verbalizations provide non-reactive evidence of the latent cognitive processes that produced the observed choices.
Reference graph
Works this paper leans on
-
[1]
Elife , volume=
Ten simple rules for the computational modeling of behavioral data , author=. Elife , volume=. 2019 , publisher=
2019
-
[2]
The Journal of Machine Learning Research , volume=
A widely applicable Bayesian information criterion , author=. The Journal of Machine Learning Research , volume=. 2013 , publisher=
2013
-
[3]
, author=
Verbal reports as data. , author=. Psychological review , volume=. 1980 , publisher=
1980
-
[4]
First conference on language modeling , year=
From strategic narratives to code-like cognitive models: An llm-based approach in a sorting task , author=. First conference on language modeling , year=
-
[5]
NeurIPS 2023 AI for science workshop , year=
Text2Decision: Decoding latent variables in risky decision making from think aloud text , author=. NeurIPS 2023 AI for science workshop , year=
2023
-
[6]
Cognitive computational neuroscience (CCN) , year=
Evaluating predictive performance and learning efficiency of large language models with think aloud in risky decision making , author=. Cognitive computational neuroscience (CCN) , year=
-
[7]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
Linking Strategies to Think Aloud in A Stochastic Learning Task , author=. Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
-
[8]
arXiv preprint arXiv:2505.23931 , year=
Scaling up the think-aloud method , author=. arXiv preprint arXiv:2505.23931 , year=
-
[9]
OSF Preprints , year=
Rethinking Think-Aloud in the Age of Language Models , author=. OSF Preprints , year=
-
[10]
arXiv preprint arXiv:2502.00879 , year=
Generating computational cognitive models using large language models , author=. arXiv preprint arXiv:2502.00879 , year=
-
[11]
March , volume=
0Prospect Theory: An Analysis of Decision Under Risk, 1 Econometrica , author=. March , volume=
-
[12]
, author=
hdbscan: Hierarchical density based clustering. , author=. J. Open Source Softw. , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.