Recognition: 1 theorem link
· Lean TheoremRollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
Pith reviewed 2026-05-11 02:05 UTC · model grok-4.3
The pith
Steering binary-reward RL rollouts toward a 50% pass rate makes the reward signal strongest and speeds up agent training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The binary reward-side signal is strongest near a 50% rollout pass rate under four criteria: reward entropy, group-filtering survival, leave-one-out (RLOO) advantage energy under Group Relative Policy Optimization (GRPO), and success-failure pair count. Prefix Sampling (PS) steers groups to this regime by replaying successful prefixes for mostly-failing groups and failing prefixes for mostly-passing groups; replayed states are reconstructed through the existing rollout path and replayed tokens are masked from the loss so optimization applies only to current-policy continuations.
What carries the argument
Prefix Sampling (PS), which replays self-generated trajectory prefixes to steer groups toward a 50% pass rate while masking replayed tokens from the policy loss.
If this is right
- The method reaches the baseline high-score regime on SWE-bench Verified within evaluation variability while delivering 2.01x and 1.55x end-to-end wall-clock speedups on Qwen3-14B and Qwen3-32B models.
- The 14B peak score improves from 0.274 to 0.295 under the same evaluation protocol.
- The same pass-rate-control pattern appears on AIME 2025 experiments with 4B and 8B models.
- Ablations on the 4B model attribute the gains specifically to replay, bidirectional coverage, and adaptive control.
Where Pith is reading between the lines
- Pass-rate monitoring during training could serve as a lightweight diagnostic for detecting when binary-reward RL is operating outside its informative regime.
- The replay-and-mask pattern may extend to other grouped RL settings that rely on sparse binary feedback beyond software engineering.
- If the target 50% rate can be adapted dynamically per group, further efficiency gains might be possible without changing the core mechanism.
Load-bearing premise
Replaying prefixes from self-generated trajectories steers groups to the informative regime without introducing bias, distribution shift, or unintended changes to the policy gradient signal in GRPO.
What would settle it
If Prefix Sampling applied to a new binary-reward coding or math task produces no wall-clock speedup and fails to reach the baseline high-score regime, the central claim would be falsified.
Figures



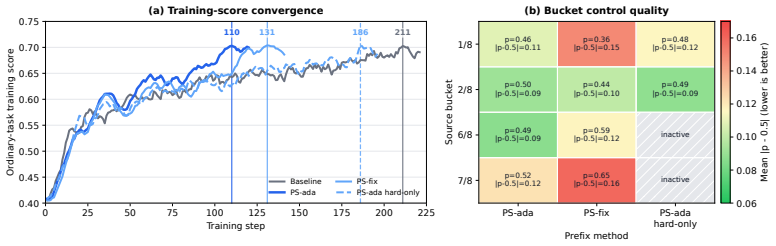
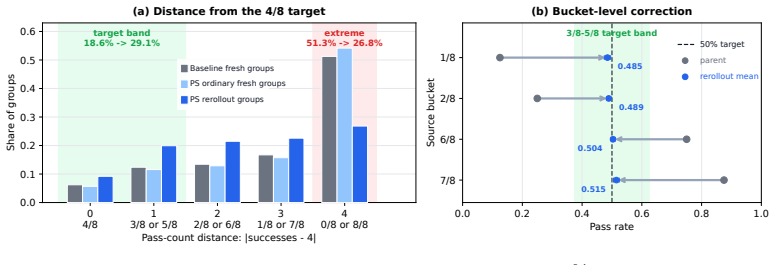




read the original abstract
Agentic reinforcement learning (RL) for software engineering spends much of its compute on stateful trajectories whose grouped binary rewards are highly skewed and weakly contrastive. We frame this as pass-rate control and show that the binary reward-side signal is strongest near a 50% rollout pass rate under four criteria: reward entropy, group-filtering survival, leave-one-out (RLOO) advantage energy under Group Relative Policy Optimization (GRPO), and success-failure pair count. We propose Prefix Sampling (PS), which replays self-generated trajectory prefixes to steer skewed groups toward this regime: successful prefixes give mostly failing groups a head start, while failing prefixes handicap mostly passing groups. Replayed states are reconstructed through the existing rollout path, and replayed tokens are masked from the loss so optimization applies only to current-policy continuations. On SWE-bench Verified, PS reaches the baseline high-score regime within evaluation variability while delivering 2.01x and 1.55x end-to-end wall-clock speedups on Qwen3-14B and Qwen3-32B; the 14B peak improves from 0.274 to 0.295. AIME 2025 experiments on 4B and 8B show the same pass-rate-control pattern, and 4B ablations attribute gains to replay, bidirectional coverage, and adaptive control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in binary-reward RL for agentic tasks (e.g., software engineering), rollout groups with highly skewed pass rates produce weak contrastive signals, and that the strongest learning signal occurs near a 50% pass rate as measured by reward entropy, group-filtering survival, RLOO advantage energy under GRPO, and success-failure pair counts. It introduces Prefix Sampling (PS), which replays prefixes from prior self-generated trajectories (successful prefixes for failing groups, failing prefixes for passing groups) to steer toward this regime; replayed states are reconstructed via the rollout path and masked from the loss so that only current-policy continuations are optimized. On SWE-bench Verified, PS matches the baseline high-score regime within variability while achieving 2.01x and 1.55x end-to-end wall-clock speedups on Qwen3-14B and Qwen3-32B (with 14B peak improving from 0.274 to 0.295); AIME 2025 experiments on 4B/8B models show the same pattern, with 4B ablations attributing gains to replay, bidirectional coverage, and adaptive control.
Significance. If the central claim holds—that PS steers groups to the informative ~50% regime while preserving an unbiased GRPO policy gradient—this provides a practical, low-overhead technique for improving sample efficiency in binary-reward RL settings common to coding agents. The reported speedups, modest performance gains, and component ablations on replay and adaptive control offer concrete engineering value for compute-constrained training. The pass-rate-control framing, grounded in multiple signal-strength metrics, could generalize beyond the tested domains and encourage similar analyses in other sparse-reward RL applications.
major comments (3)
- [Prefix Sampling and GRPO sections] In the Prefix Sampling description (and associated GRPO integration): the claim that masking replayed tokens ensures the policy gradient remains unbiased is not fully supported. While replayed tokens are excluded from the loss, the group composition for RLOO advantage computation now mixes fixed historical prefixes with current-policy continuations; this alters which trajectories are ranked together and can change relative advantage estimates in ways absent from standard GRPO. No derivation or controlled experiment is provided showing that the resulting gradient direction or advantage energy is equivalent to an unbiased 50%-pass-rate sampler.
- [Experiments on SWE-bench and AIME] Experimental results on SWE-bench Verified: the reported 2.01x/1.55x speedups and score improvement (0.274 to 0.295) are presented without full ablation tables, error bars across multiple seeds, or explicit verification that the achieved pass rates are indeed near 50% with no unintended distribution shift. The 4B AIME ablations are helpful but do not address whether the GRPO advantage estimator remains invariant under prefix replay at the 14B/32B scale.
- [Pass-rate control analysis] The four criteria used to identify the 'most informative regime' (reward entropy, group-filtering survival, RLOO advantage energy, success-failure pair count) are presented as justification for targeting 50%, yet the manuscript provides no quantitative sensitivity analysis or derivation showing that deviations from 50% materially degrade these metrics in the specific GRPO setting; the target_pass_rate appears as a free hyperparameter without further justification.
minor comments (2)
- [Abstract and Method] The abstract and method sections would benefit from a one-sentence reminder of the standard GRPO baseline (without prefix replay) to make the incremental contribution of PS clearer to readers unfamiliar with the exact implementation.
- [Prefix Sampling description] Notation for 'replayed states reconstructed through the existing rollout path' is introduced without a diagram or pseudocode; a small figure illustrating the masking and group construction would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: In the Prefix Sampling description (and associated GRPO integration): the claim that masking replayed tokens ensures the policy gradient remains unbiased is not fully supported. While replayed tokens are excluded from the loss, the group composition for RLOO advantage computation now mixes fixed historical prefixes with current-policy continuations; this alters which trajectories are ranked together and can change relative advantage estimates in ways absent from standard GRPO. No derivation or controlled experiment is provided showing that the resulting gradient direction or advantage energy is equivalent to an unbiased 50%-pass-rate sampler.
Authors: We agree that the manuscript's treatment of unbiasedness under prefix replay requires more rigorous support. Masking ensures gradients apply only to current-policy tokens, but the mixed-group RLOO computation does alter rankings relative to pure current-policy groups. In the revision we will add a short derivation showing that the expected advantage (under the induced pass-rate distribution) preserves the same directional signal as standard GRPO at 50% pass rate, together with a controlled small-scale experiment comparing advantage energy and gradient norms with and without replay. revision: yes
-
Referee: Experimental results on SWE-bench Verified: the reported 2.01x/1.55x speedups and score improvement (0.274 to 0.295) are presented without full ablation tables, error bars across multiple seeds, or explicit verification that the achieved pass rates are indeed near 50% with no unintended distribution shift. The 4B AIME ablations are helpful but do not address whether the GRPO advantage estimator remains invariant under prefix replay at the 14B/32B scale.
Authors: We accept that the experimental reporting can be strengthened. The revised manuscript will include complete ablation tables, means and standard deviations across multiple seeds, explicit measurements confirming achieved pass rates near 50%, and an analysis of any distribution shift. For scale invariance we will add a limitations paragraph noting that the 4B ablations validate the core mechanism while the 14B/32B results demonstrate consistent wall-clock gains; we will not claim full invariance at large scale without additional runs. revision: yes
-
Referee: The four criteria used to identify the 'most informative regime' (reward entropy, group-filtering survival, RLOO advantage energy, success-failure pair count) are presented as justification for targeting 50%, yet the manuscript provides no quantitative sensitivity analysis or derivation showing that deviations from 50% materially degrade these metrics in the specific GRPO setting; the target_pass_rate appears as a free hyperparameter without further justification.
Authors: We will strengthen the justification. Reward entropy for binary outcomes is analytically maximized at p=0.5, and the other three metrics are monotonic functions of deviation from 0.5 under the GRPO grouping. The revision will add a quantitative sensitivity section with plots of all four metrics versus pass rate (both analytically and empirically under GRPO) and will fix target_pass_rate=0.5 with this analysis rather than leaving it as an untuned hyperparameter. revision: yes
Circularity Check
No significant circularity; derivation chain is self-contained and empirical
full rationale
The paper frames an analysis of binary-reward RL under GRPO by identifying the 50% pass-rate regime as most informative via four independent criteria (reward entropy, group-filtering survival, RLOO advantage energy, and success-failure pair count). It then proposes Prefix Sampling as a practical steering mechanism whose effects are validated experimentally on SWE-bench Verified and AIME 2025. No equations, derivations, or first-principles claims are shown that reduce by construction to fitted parameters, self-citations, or renamed inputs. The GRPO reference is treated as an external baseline; the replay mechanism is described procedurally with masking to preserve the policy gradient on new tokens. All performance numbers (speedups, score improvements) are reported as measured outcomes on external benchmarks rather than as predictions derived from the method itself. This is the common honest case of an empirical methods paper whose central claims remain falsifiable outside any internal loop.
Axiom & Free-Parameter Ledger
free parameters (1)
- target_pass_rate
axioms (1)
- domain assumption Binary terminal rewards in stateful trajectories provide a usable learning signal under GRPO when pass rates are balanced.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearFour complementary quantities—reward entropy, group-filtering survival, leave-one-out (RLOO) advantage energy under GRPO, and success–failure pair count—all identify the same target: training is most informative when rollout pass rates are close to 50%
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024. doi: 10.48550/arXiv.2402.03300. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[2]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[3]
DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling RL
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Alpay Ariyak, Colin Cai, Tarun Venkat, Shang Zhu, Ben Athiwaratkun, Manan Roongta, Ce Zhang, Li Erran Li, Raluca Ada Popa, Koushik Sen, and Ion Stoica. DeepSWE: Training a fully open-sourced, state-of-the-art coding agent by scaling RL. https://www.together.ai/blog/deepswe, 2025
work page 2025
-
[4]
Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, et al. Let it flow: Agentic crafting on rock and roll, building the ROME model within an open agentic learning ecosystem. arXiv:2512.24873, 2025. URLhttps://arxiv.org/abs/2512.24873
-
[5]
Amrith Setlur, Zijian Wang, Andrew Cohen, Paria Rashidinejad, and Sang Michael Xie. Reuse your FLOPs: Scaling RL on hard problems by conditioning on very off-policy prefixes.CoRR, abs/2601.18795, 2026. URLhttps://arxiv.org/abs/2601.18795
-
[6]
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. POPE: Learning to reason on hard problems via privileged on-policy exploration.CoRR, abs/2601.18779, 2026. URLhttps://arxiv.org/abs/2601.18779
-
[7]
Kaiyi Zhang, Ang Lv, Jinpeng Li, Yongbo Wang, Feng Wang, Haoyuan Hu, and Rui Yan. StepHint: Multi-level stepwise hints enhance reinforcement learning to reason.CoRR, abs/2507.02841, 2025. URLhttps://arxiv.org/abs/2507.02841
-
[8]
Adhint: Adaptive hints with difficulty priors for reinforcement learning, 2026
Feng Zhang, Zezhong Tan, Xinhong Ma, Ziqiang Dong, Xi Leng, Jianfei Zhao, Xin Sun, and Yang Yang. ADHint: Adaptive hints with difficulty priors for reinforcement learning.CoRR, abs/2512.13095, 2025. URLhttps://arxiv.org/abs/2512.13095
-
[9]
Boosting MLLM reasoning with text-debiased Hint-GRPO
Qihan Huang, Weilong Dai, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, Jingyuan Chen, Chang Yao, and Jie Song. Boosting MLLM reasoning with text-debiased Hint-GRPO. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4848–4857, 2025. URL https://openaccess.thecvf.com/content/ICCV2025/html/ Huang_Boosting_MLLM_Reasoning_wit...
work page 2025
-
[10]
Self-hinting language models enhance reinforcement learning, 2026
Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, and Jiang Bian. Self-hinting language models enhance reinforcement learning.CoRR, abs/2602.03143, 2026. URL https://arxiv. org/abs/2602.03143
-
[11]
Yangyi Fang, Jiaye Lin, Xiaoliang Fu, Cong Qin, Haolin Shi, Chaowen Hu, Lu Pan, Ke Zeng, and Xunliang Cai. How to allocate, how to learn? dynamic rollout allocation and advantage modulation for policy optimization.CoRR, abs/2602.19208, 2026. URL https://arxiv. org/abs/2602.19208
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Learning to reason under off-policy guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=vO8LLoNWWk. 11
work page 2025
-
[13]
SRFT: A single-stage method with super- vised and reinforcement fine-tuning for reasoning
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. SRFT: A single-stage method with super- vised and reinforcement fine-tuning for reasoning. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=n6E0r6kQWQ
work page 2026
-
[14]
Learning what rein- forcement learning can’t: Interleaved online fine-tuning for hardest questions
Lu Ma, Hao Liang, Meiyi Qiang, Lexiang Tang, Xiaochen Ma, Zhen Hao Wong, Junbo Niu, Chengyu Shen, Runming He, Yanhao Li, Wentao Zhang, and Bin Cui. Learning what rein- forcement learning can’t: Interleaved online fine-tuning for hardest questions. InInternational Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/ forum?id=LzCBLrNoyM
work page 2026
-
[15]
UFT: Unifying supervised and rein- forcement fine-tuning
Mingyang Liu, Gabriele Farina, and Asuman Ozdaglar. UFT: Unifying supervised and rein- forcement fine-tuning. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=usOkGv1S7M
work page 2025
- [17]
-
[18]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? InInternational Conference on Learning Representations (ICLR), 2024. URL https:// openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[19]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. CoRR, abs/2103.03874, 2021. URLhttps://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Thomas M. Cover and Joy A. Thomas.Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006. ISBN 9780471241959. URL https: //www.wiley-vch.de/en/areas-interest/computing-computer-sciences/ computer-science-17cs/information-technologies-17cs3/ elements-of-information-theory-978-0-471-24195-9
work page 2006
-
[21]
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist rein- forcement learning.Machine Learning, 8:229–256, 1992. doi: 10.1007/BF00992696. URL https://link.springer.com/article/10.1007/BF00992696
-
[22]
Qwen3-14B.https://huggingface.co/Qwen/Qwen3-14B, 2025
Qwen Team. Qwen3-14B.https://huggingface.co/Qwen/Qwen3-14B, 2025
work page 2025
-
[23]
Qwen3-32B.https://huggingface.co/Qwen/Qwen3-32B, 2025
Qwen Team. Qwen3-32B.https://huggingface.co/Qwen/Qwen3-32B, 2025
work page 2025
-
[24]
American Invitational Mathematics Examination (AIME)
Mathematical Association of America. American Invitational Mathematics Examination (AIME). https://maa.org/maa-invitational-competitions/, 2025. Official MAA AIME information page
work page 2025
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. doi: 10.48550/arXiv. 1707.06347. URLhttps://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[26]
arXiv preprint arXiv:2504.07164 , year=
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. R2E- Gym: Procedural environments and hybrid verifiers for scaling open-weights SWE agents. arXiv preprint arXiv:2504.07164, 2025. doi: 10.48550/arXiv.2504.07164. URL https: //arxiv.org/abs/2504.07164
-
[27]
SWE-bench Team. SWE-bench Verified. https://www.swebench.com/verified.html,
-
[28]
Human-validated 500-instance subset created in collaboration with OpenAI
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. doi: 10.48550/arXiv.2505.09388. URL https://arxiv.org/abs/2505.09388. 12
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[30]
Qwen Team. Qwen3-4B-Instruct-2507. https://huggingface.co/Qwen/ Qwen3-4B-Instruct-2507, 2025
work page 2025
-
[31]
Qwen3-8B.https://huggingface.co/Qwen/Qwen3-8B, 2025
Qwen Team. Qwen3-8B.https://huggingface.co/Qwen/Qwen3-8B, 2025
work page 2025
-
[32]
In: EDM 2025 (2025).https://doi.org/10.48550/arXiv.2505
Yang Chen, Zhuolin Yang, Zihan Liu, Chankyu Lee, Peng Xu, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. AceReason-Nemotron: Advancing math and code reasoning through reinforcement learning.arXiv preprint arXiv:2505.16400, 2025. doi: 10.48550/arXiv.2505. 16400. URLhttps://arxiv.org/abs/2505.16400
-
[33]
Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Xin Xu, Clive Bai, Kai Yang, Tianhao Chen, Yangkun Chen, Weijie Liu, Hao Chen, Yang Wang, Saiyong Yang, and Can Yang. Composition-RL: Compose your verifiable prompts for reinforcement learning of large language models.CoRR, abs/2602.12036, 2026. URL https://arxiv.org/abs/2602.12036
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [35]
-
[36]
Yuda Song, Lili Chen, Fahim Tajwar, Rémi Munos, Deepak Pathak, J. Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.CoRR, abs/2602.02482, 2026. URLhttps://arxiv.org/abs/2602.02482
-
[37]
Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. Experiential reinforcement learning.CoRR, abs/2602.13949, 2026. URL https://arxiv.org/abs/2602. 13949
-
[38]
verl: V olcano engine reinforcement learning for LLMs
verl project. verl: V olcano engine reinforcement learning for LLMs. https://github.com/ verl-project/verl/releases/tag/v0.5.0, 2025
work page 2025
-
[39]
Remaining outer surface: 48 m2. Internal tunnel surfaces: 36 m2. Total surface area= 48 + 36 = 84m 2
ModelScope Team. EvalScope: Evaluation framework for large models. https://github. com/modelscope/evalscope, 2024. 13 A Limitations and Scope A.1 Scope of Claims Our claims are scoped to binary-reward RLVR with grouped rollouts, and all main experiments use N= 8 rollouts per task. The largest-scale experiments target the intended stateful-agent setting: S...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.