Recognition: 2 theorem links
· Lean TheoremComposition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
Pith reviewed 2026-05-16 02:37 UTC · model grok-4.3
The pith
Composition-RL improves LLM reasoning by automatically composing multiple verifiable prompts into new training questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
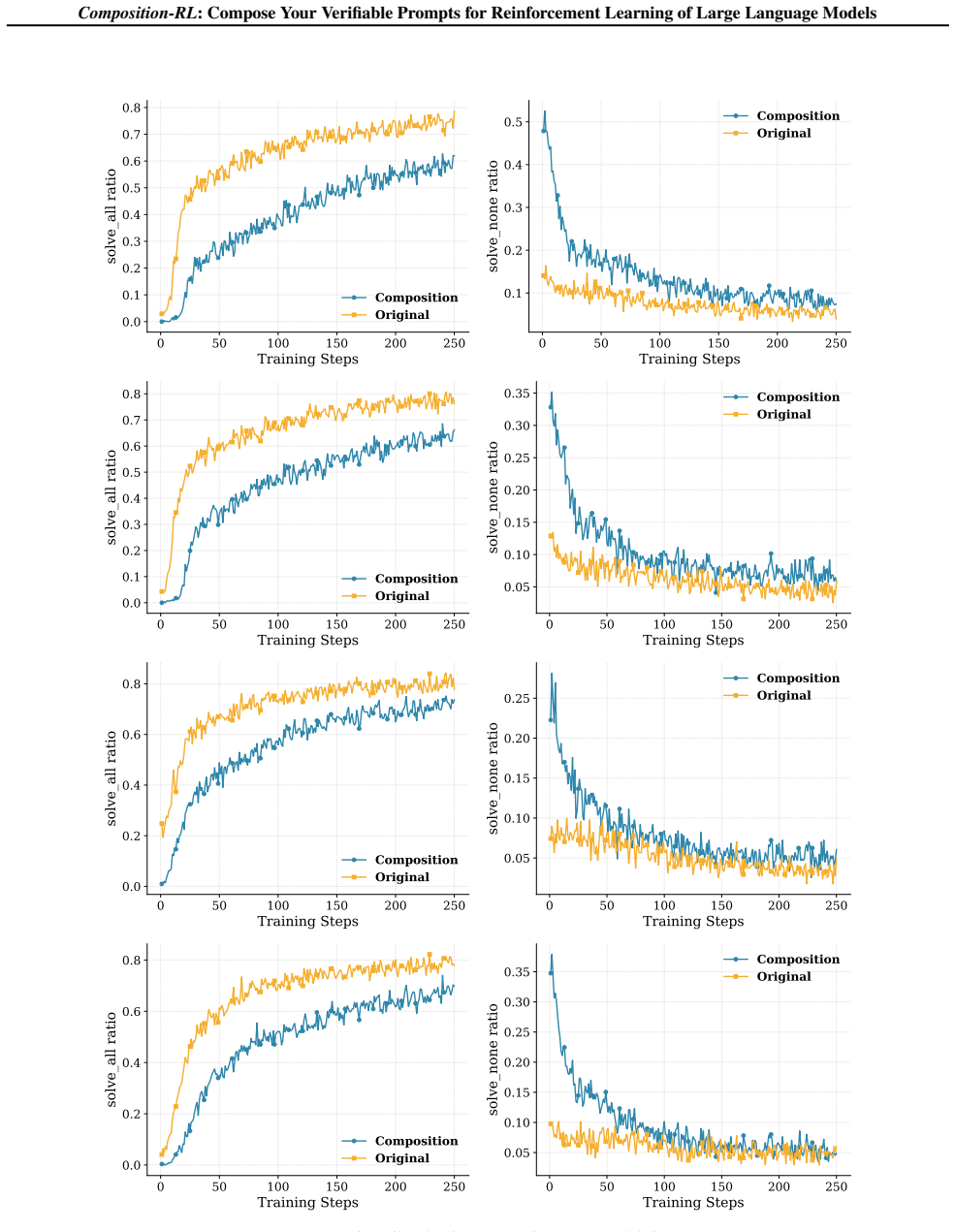
By automatically composing multiple pass-rate-1 prompts into new verifiable questions, Composition-RL supplies continued learning signals during RLVR training and yields higher reasoning performance than training on the original dataset alone, with further gains from a curriculum variant that increases compositional depth and from cross-domain composition.
What carries the argument
Automatic composition of multiple original prompts into a single new verifiable question that preserves verifiability and raises reasoning demand.
If this is right
- Consistent gains in reasoning capability over baseline RL on the original dataset.
- Additional performance lift from a curriculum that gradually raises compositional depth.
- More effective cross-domain RL when prompts from different domains are composed together.
- Continued utility of the fixed prompt set as training progresses and individual examples become trivial.
Where Pith is reading between the lines
- The approach could lower reliance on ever-larger collections of hand-written prompts by recycling existing ones.
- It may apply to other RL settings where easy examples begin to dilute gradient signals.
- Composed prompts could expose interactions between reasoning skills that isolated prompts do not reveal.
Load-bearing premise
Composed prompts remain valid and produce useful learning signals rather than introducing noise or invalid reasoning chains.
What would settle it
Training runs that use Composition-RL prompts produce no measurable gain or show worse performance on standard reasoning benchmarks compared with identical runs using only the original prompts.
Figures






read the original abstract
Large-scale verifiable prompts underpin the success of Reinforcement Learning with Verifiable Rewards (RLVR), but they contain many uninformative examples and are costly to expand further. Recent studies focus on better exploiting limited training data by prioritizing hard prompts whose rollout pass rate is 0. However, easy prompts with a pass rate of 1 also become increasingly prevalent as training progresses, thereby reducing the effective data size. To mitigate this, we propose Composition-RL, a simple yet useful approach for better utilizing limited verifiable prompts targeting pass-rate-1 prompts. More specifically, Composition-RL automatically composes multiple problems into a new verifiable question and uses these compositional prompts for RL training. Extensive experiments across model sizes from 4B to 30B show that Composition-RL consistently improves reasoning capability over RL trained on the original dataset. Performance can be further boosted with a curriculum variant of Composition-RL that gradually increases compositional depth over training. Additionally, Composition-RL enables more effective cross-domain RL by composing prompts drawn from different domains. Codes, datasets, and models are available at https://github.com/XinXU-USTC/Composition-RL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Composition-RL, a method that automatically composes multiple pass-rate-1 verifiable prompts into new questions for RL training of LLMs. It claims this yields consistent reasoning improvements over standard RL on the original dataset across 4B–30B models, with further gains from a curriculum variant that increases compositional depth and benefits for cross-domain RL.
Significance. If the composed prompts reliably preserve verifiability and produce clean learning signals, the approach could meaningfully improve data efficiency in RLVR by recycling easy prompts that dominate later training stages. The multi-size empirical evaluation and public release of code, datasets, and models are positive contributions that would support reproducibility.
major comments (3)
- [§3 (Composition-RL method) and Abstract] The central claim that automatically composed prompts remain verifiable (with unique, consistent ground-truth answers) is load-bearing for all reported gains, yet the manuscript provides no explicit composition rules, measured error rates on malformed outputs, or ablation showing that reward noise is not introduced. This directly affects the validity of the RL signal and the comparison to baseline RL on the original dataset.
- [§4 Experiments and Table 1] Table 1 and §4.2 report consistent improvements, but without quantitative metrics (e.g., exact pass-rate deltas, standard deviations, or statistical tests) or detailed baseline comparisons (including other data-augmentation or hard-prompt prioritization methods), it is impossible to judge whether the gains are robust or merely incremental.
- [§4.3 Curriculum variant] The curriculum variant is presented as further boosting performance by gradually increasing compositional depth, but no analysis is given on how depth is measured, whether intermediate compositions remain verifiable, or an ablation isolating the curriculum schedule from simple composition.
minor comments (2)
- [§3] Notation for pass-rate-1 prompts and compositional depth should be formalized with a short definition or equation in §3 to avoid ambiguity when readers replicate the method.
- [§4.4] The cross-domain experiment description would benefit from an explicit statement of how prompts from different domains are selected and composed without domain-specific inconsistencies.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that clarifying the verifiability guarantees, adding quantitative metrics and baselines, and analyzing the curriculum component will strengthen the manuscript. We address each major comment below and commit to the indicated revisions.
read point-by-point responses
-
Referee: The central claim that automatically composed prompts remain verifiable (with unique, consistent ground-truth answers) is load-bearing for all reported gains, yet the manuscript provides no explicit composition rules, measured error rates on malformed outputs, or ablation showing that reward noise is not introduced. This directly affects the validity of the RL signal and the comparison to baseline RL on the original dataset.
Authors: We thank the referee for highlighting this foundational point. The composition procedure is designed to preserve verifiability by operating exclusively on pass-rate-1 prompts whose answers are unique and by concatenating them with explicit separators that do not alter the underlying ground truth. In the revised manuscript we will (i) state the exact composition rules and pseudocode in §3, (ii) report the measured malformation rate on a held-out sample of 500 composed prompts, and (iii) add an ablation that trains with deliberately noisy rewards to quantify any degradation relative to our clean compositional signal. revision: yes
-
Referee: Table 1 and §4.2 report consistent improvements, but without quantitative metrics (e.g., exact pass-rate deltas, standard deviations, or statistical tests) or detailed baseline comparisons (including other data-augmentation or hard-prompt prioritization methods), it is impossible to judge whether the gains are robust or merely incremental.
Authors: We agree that the current presentation of results is insufficiently quantitative. In the revision we will expand Table 1 to report exact pass-rate deltas, standard deviations across three random seeds, and p-values from paired t-tests. We will also add a new table comparing Composition-RL against representative data-augmentation baselines (e.g., prompt paraphrasing) and hard-example prioritization methods to demonstrate that the observed gains exceed those obtainable by simpler alternatives. revision: yes
-
Referee: The curriculum variant is presented as further boosting performance by gradually increasing compositional depth, but no analysis is given on how depth is measured, whether intermediate compositions remain verifiable, or an ablation isolating the curriculum schedule from simple composition.
Authors: We appreciate the request for a more rigorous curriculum analysis. In the revised §4.3 we will (i) formally define compositional depth as the number of atomic prompts concatenated, (ii) report verification success rates for all intermediate compositions generated during training, and (iii) include an ablation that trains with the same set of composed prompts but without the depth-scheduling curriculum, thereby isolating the contribution of the curriculum itself. revision: yes
Circularity Check
No significant circularity; purely empirical method with independent experimental validation
full rationale
The paper introduces Composition-RL as an algorithmic procedure for automatically composing multiple pass-rate-1 problems into new verifiable questions, then trains RL on these composed prompts and measures gains against a baseline RL run on the original dataset. No mathematical derivation, first-principles equations, or uniqueness theorems are claimed; the central results are empirical performance deltas across model sizes 4B–30B and a curriculum variant. Because the method is defined procedurally and evaluated externally against held-out or original data rather than by fitting parameters that are then relabeled as predictions, no self-definitional, fitted-input, or self-citation-load-bearing reductions exist. The approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Composition-RL automatically composes multiple problems into a new verifiable question... SPC applies Compose recursively for K-1 steps
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
JGRPO objective... advantage estimator... dynamic sampling to filter solve-all prompts
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Rollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
Prefix Sampling steers binary-reward agentic RL rollouts to a 50% pass rate to maximize learning signal, yielding up to 2.01x speedups on SWE-bench with maintained or improved verified performance.
-
Rollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
Prefix Sampling replays self-generated trajectory prefixes to control rollout pass rates to ~50% in binary-reward GRPO, delivering 2.01x and 1.55x speedups on Qwen3-14B/32B with slight score improvements on SWE-bench ...
Reference graph
Works this paper leans on
-
[1]
Mathematical reasoning:We evaluate on AIME24, AIME25, BeyondAIME (ByteDance-Seed, 2025), and IMO- Bench (Luong et al., 2025). Since AIME24 and AIME25 each contain 30 problems, we report pass@1 using 32 samples per problem (avg@32). BeyondAIME contains 100 problems; we report avg@8. For IMO-Bench, we use the AnswerBench subset to enable rule-based verifica...
work page 2025
-
[2]
Multi-task reasoning:We evaluate on GPQA-Diamond (Rein et al., 2024) (approximately 200 problems) and report pass@1 using 8 samples per problem. We also evaluate on MMLU-Pro (Wang et al., 2024); since it contains over 5K problems, we report results from a single run. All evaluation codes are adapted from the DeepscaleR (Luo et al., 2025) codebase, and we ...
work page 2024
-
[3]
Compare it with the correct answer:{correct answer}
-
[4]
Determine if the model correctly solved for ${symbol}$. **Important Notes: ** - Focus ONLY on whether ${symbol}$ was correctly computed; ignore the final answer of the composite problem. - The value might be stated explicitly (e.g., ‘‘${symbol}$ = 7’’) or implicitly derived. - Accept equivalent forms (e.g., ‘‘7’’, ‘‘7.0’’, ‘‘seven’’ are all correct if the...
work page 2025
-
[5]
If thefinal answercontains unknown variables: (a) If the final answer is an expression, choose one coefficient as new variable1, for example, 2x+ 3 , you can choose the coefficient of x as new variable1, which is 2, and in the case of sin(x), there is a hidden coefficient1and a hidden amplitude1, you can choose either one asnew variable1; (b) If the final...
-
[6]
If thefinal answerhas no unknown variables, there are several situations: (a) If the final answer itself is a numerical value, like ‘four’, ‘4’, ‘2 + √ 2’, ‘3π’, and ‘3 4’, use it directly as new variable1; (b) If the final answer contains 2 or more numerical values, use the largest or the smallest one as new variable1; (c) If the final answer is an inter...
-
[7]
Check the extraction of variablev 1: {Problem 1} Assume that the final answer of the problem is{FINAL_ANSWER}.{DEFINITION_OF_NEW_VARIABLE1} Then what is the value ofnew variable1? Please output the value ofnew variable1directly, wrapping it in\boxed{}, for example,\boxed{3}
-
[8]
Check the value ofv 1 using Python: **Task Description:** Write a Python program to compare two given values and determine if they are equal. Follow these guidelines:
-
[9]
Use the sympy library to handle symbolic comparisons, ensuring that equivalent expressions (e.g., 2 4 and 1
-
[10]
are recognized as equal
-
[11]
For values involving irrational constants (e.g., π, e), perform comparisons up totwo decimal placesfor practical equivalence
-
[12]
Include clear intermediate steps in the program, such as evaluating or simplifying the values where appropriate
-
[13]
Wrap the final comparison outcome in a\boxed{}command for clarity
-
[14]
Provide both the Python code and the results of running the code. **Output Format:** ‘‘‘python {The Python code that compares the two given values, including print statements for intermediate steps and the \boxed{final comparison outcome}.} ‘‘‘ ‘‘‘output {The output of the Python program.} ‘‘‘ --- [Examples Here] Figure 7.The Prompt for Verifying the Modi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.