Recognition: unknown
ConsisVLA-4D: Advancing Spatiotemporal Consistency in Efficient 3D-Perception and 4D-Reasoning for Robotic Manipulation
Pith reviewed 2026-05-08 16:35 UTC · model grok-4.3
The pith
ConsisVLA-4D adds cross-view semantic, cross-object geometric, and cross-scene spatiotemporal consistency to vision-language-action models for better robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
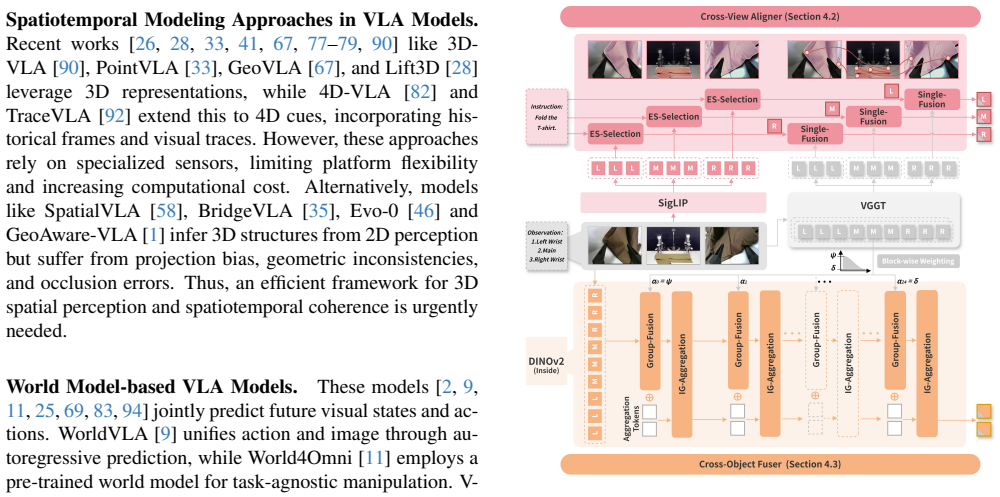
ConsisVLA-4D is a unified framework that improves spatiotemporal consistency for 3D perception and 4D reasoning by combining CV-Aligner for cross-view object semantic alignment, CO-Fuser for cross-object geometric consistency via latent representations, and CS-Thinker that fuses semantic and geometric tokens to track local dynamics and global depth under scene changes.
What carries the argument
Three modules (CV-Aligner, CO-Fuser, CS-Thinker) that separately enforce cross-view semantic consistency, cross-object geometric consistency, and cross-scene spatiotemporal consistency.
If this is right
- Multi-view inputs can be used directly for 3D perception without extra depth sensors or high compute.
- Action sequences become more reliable under changing object relations and camera motion.
- Inference remains fast enough for closed-loop control on real hardware.
- Long-horizon tasks benefit from implicit modeling of object dynamics and scene evolution.
Where Pith is reading between the lines
- The same consistency modules could be tested on other VLA backbones to check if gains are architecture-independent.
- Compact latent representations from CO-Fuser might allow lower-resolution input images while preserving geometric accuracy.
- The approach suggests a path toward VLA models that reason over longer time horizons by maintaining token-level consistency rather than frame-by-frame prediction.
Load-bearing premise
The three consistency modules actually produce the claimed alignments and fusions without hidden benchmark-specific tuning that would not transfer to new tasks or hardware.
What would settle it
Run the model on a new robot platform with different camera placements and a manipulation task sequence never seen during training, then measure whether the reported performance and speed gains over the baseline disappear.
Figures










read the original abstract
Current Vision-Language-Action (VLA) models primarily focus on mapping 2D observations to actions, but exhibit notable limitations in spatiotemporal perception and reasoning: 1) spatial representations often rely on additional sensors, introducing substantial computational overhead; 2) visual reasoning is typically limited to future-frame prediction, lacking alignment with the instruction-grounded scene and thus compromising spatiotemporal consistency. To address these challenges, we propose ConsisVLA-4D, a unified and efficient framework that enhances spatiotemporal consistency in 3D perception and 4D reasoning. Specifically, we design: 1) CV-Aligner, which ensures cross-view object semantic consistency by filtering instruction-relevant regions and aligning object identities across multiple viewpoints; 2) CO-Fuser, which guarantees cross-object spatial geometric consistency by eliminating spatial relation ambiguities between objects across views using compact latent representations. Building upon these, we introduce 3) CS-Thinker to achieve cross-scene spatiotemporal consistency as actions unfold. It learns implicit knowledge of local dynamics from object-semantic tokens of CV-Aligner and global depth from geometric tokens of CO-Fuser, thereby enhancing efficient visual reasoning under scene variations. Extensive experiments demonstrate that, benefiting from its efficient spatiotemporal consistency design, ConsisVLA-4D achieves 21.6% and 41.5% performance improvements, along with 2.3-fold and 2.4-fold inference speedups compared to OpenVLA on the LIBERO benchmark and real-world platforms, respectively.ConsisVLA-4D is open-sourced and publicly available at
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ConsisVLA-4D, a unified framework for Vision-Language-Action (VLA) models that improves spatiotemporal consistency in 3D perception and 4D reasoning for robotic manipulation. It proposes three components: CV-Aligner to ensure cross-view object semantic consistency by filtering instruction-relevant regions and aligning object identities; CO-Fuser to guarantee cross-object spatial geometric consistency via compact latent representations that eliminate spatial relation ambiguities; and CS-Thinker to achieve cross-scene spatiotemporal consistency by learning local dynamics from semantic tokens and global depth from geometric tokens. The paper reports 21.6% performance improvement and 2.3-fold inference speedup versus OpenVLA on the LIBERO benchmark, plus 41.5% improvement and 2.4-fold speedup on real-world platforms.
Significance. If the central claims are supported by isolating experiments, this work could advance efficient VLA models by addressing consistency limitations without extra sensors, potentially improving generalization in manipulation tasks. The open-sourcing of the code is a positive contribution that supports reproducibility and follow-on research.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The reported 21.6% and 41.5% gains and speedups are attributed to the consistency mechanisms, yet no direct quantitative consistency metrics (e.g., cross-view object ID alignment error, geometric relation ambiguity scores, or dynamics prediction accuracy) are provided to verify that CV-Aligner, CO-Fuser, and CS-Thinker actually deliver the claimed properties.
- [§3] §3 (Methods): The design descriptions of CV-Aligner, CO-Fuser, and CS-Thinker do not specify the loss terms, regularizers, or training objectives that enforce cross-view semantic, cross-object geometric, and cross-scene spatiotemporal consistency; without these, it is unclear whether the properties are explicitly optimized or emerge incidentally.
- [§4] §4 (Experiments): No ablation studies or controls are described that hold training data, optimizer, and backbone fixed while varying only the proposed modules, so the attribution of gains specifically to the consistency components versus other unstated changes cannot be verified.
minor comments (1)
- [Abstract] The abstract states that ConsisVLA-4D is open-sourced but the provided text cuts off before the repository link; ensure the final version includes a persistent, accessible URL.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We address each major point below and will incorporate revisions to strengthen the empirical validation and methodological clarity.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The reported 21.6% and 41.5% gains and speedups are attributed to the consistency mechanisms, yet no direct quantitative consistency metrics (e.g., cross-view object ID alignment error, geometric relation ambiguity scores, or dynamics prediction accuracy) are provided to verify that CV-Aligner, CO-Fuser, and CS-Thinker actually deliver the claimed properties.
Authors: We agree that direct quantitative consistency metrics would provide stronger, more isolated evidence for the claimed properties. In the revised manuscript we will add explicit evaluations of cross-view object ID alignment error, geometric relation ambiguity scores, and dynamics prediction accuracy (computed on held-out validation sequences) to Section 4. These metrics will be reported alongside the existing task success rates and speedups to directly link the modules to the consistency improvements. revision: yes
-
Referee: [§3] §3 (Methods): The design descriptions of CV-Aligner, CO-Fuser, and CS-Thinker do not specify the loss terms, regularizers, or training objectives that enforce cross-view semantic, cross-object geometric, and cross-scene spatiotemporal consistency; without these, it is unclear whether the properties are explicitly optimized or emerge incidentally.
Authors: We acknowledge the need for explicit training objectives. The revised Section 3 will include the precise loss formulations: a contrastive alignment loss for CV-Aligner, a geometric consistency regularizer on latent embeddings for CO-Fuser, and a combined spatiotemporal prediction loss (local dynamics from semantic tokens plus global depth regression from geometric tokens) for CS-Thinker, together with the overall multi-task objective and any weighting hyperparameters. revision: yes
-
Referee: [§4] §4 (Experiments): No ablation studies or controls are described that hold training data, optimizer, and backbone fixed while varying only the proposed modules, so the attribution of gains specifically to the consistency components versus other unstated changes cannot be verified.
Authors: We agree that controlled ablations are essential for attribution. The revised Section 4 will present a full set of ablation experiments that keep the training dataset, optimizer, learning rate schedule, and backbone identical while incrementally adding or removing CV-Aligner, CO-Fuser, and CS-Thinker (and their associated losses). This will isolate the contribution of each consistency module to both performance and inference speed. revision: yes
Circularity Check
No circularity: empirical claims rest on independent experimental comparisons
full rationale
The paper describes an architectural framework (CV-Aligner for cross-view semantic consistency, CO-Fuser for cross-object geometric consistency, CS-Thinker for cross-scene spatiotemporal consistency) and reports performance gains (21.6% on LIBERO, 41.5% on real-world) plus speedups versus OpenVLA. No equations, parameter-fitting steps presented as predictions, self-citations, or uniqueness theorems appear in the text. The derivation chain consists of component definitions followed by benchmark results; these results are not shown to reduce to the inputs by construction. The central claims therefore remain self-contained against external baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Geoaware- vla: Implicit geometry aware vision-language-action model,
Ali Abouzeid, Malak Mansour, Zezhou Sun, and Dezhen Song. Geoaware-vla: Implicit geometry aware vision- language-action model.arXiv preprint arXiv:2509.14117,
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self- supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. 2, 3
work page internal anchor Pith review arXiv 2025
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al.π 0: A vision-language- action flow model for general robot control, 2024.URL https://arxiv. org/abs/2410.24164, 2024. 1, 2, 6, 7
work page internal anchor Pith review arXiv 2024
-
[5]
Binocular vision.Vision research, 51(7):754–770, 2011
Randolph Blake and Hugh Wilson. Binocular vision.Vision research, 51(7):754–770, 2011. 2
2011
-
[6]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818, 2023. 2, 6
work page internal anchor Pith review arXiv 2023
-
[7]
UniVLA: Learning to Act Anywhere with Task-centric Latent Actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Figure 9.Visualization of Task 1 and Task 2 Execution, illustrating key execution-stage observations in full. Figure 10.Additional Qualitative Visualizations of CV-Aligner.This figure illustrates the attention heatmaps generated by the CV- Aligner mod...
work page internal anchor Pith review arXiv 2025
-
[8]
Hanyu Cai, Binqi Shen, Lier Jin, Lan Hu, and Xiaojing Fan. Does tone change the answer? evaluating prompt politeness effects on modern LLMs: GPT, Gemini, LLaMA.arXiv preprint arXiv:2512.12812, 2025. 2
-
[9]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Figure 11.Additional Qualitative Visualizations of CO-Fuser.This figure illustrates the attention heatmap between the Aggregation Tokens extracted by the CO-Fuser module and the original visual patch tokens. Unlike the single-point focus of CV-Alig...
work page internal anchor Pith review arXiv 2025
-
[10]
Less is more: Empowering gui agent with context-aware simplification
Gongwei Chen, Xurui Zhou, Rui Shao, Yibo Lyu, Kaiwen Zhou, Shuai Wang, Wentao Li, Yinchuan Li, Zhongang Qi, and Liqiang Nie. Less is more: Empowering gui agent with context-aware simplification. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5901–5911, 2025. 2
2025
-
[11]
Haonan Chen, Bangjun Wang, Jingxiang Guo, Tianrui Zhang, Yiwen Hou, Xuchuan Huang, Chenrui Tie, and Lin Shao. World4omni: A zero-shot framework from image gen- eration world model to robotic manipulation.arXiv preprint arXiv:2506.23919, 2025. 2, 3
-
[12]
An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024. 9
2024
-
[13]
Integration and competition between space and time in the hippocampus.Neuron, 112(21):3651–3664, 2024
Shijie Chen, Ning Cheng, Xiaojing Chen, and Cheng Wang. Integration and competition between space and time in the hippocampus.Neuron, 112(21):3651–3664, 2024. 2
2024
-
[14]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data gen- erator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 7, 2
work page internal anchor Pith review arXiv 2025
-
[15]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research,
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research,
-
[16]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[17]
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowl- edge insulating vision-language-action models: Train fast, run fast, generalize better.arXiv preprint arXiv:2505.23705,
-
[18]
Zhao, and Chelsea Finn
Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. Mobile aloha: Learning bimanual mobile manipulation with low- cost whole-body teleoperation. InConference on Robot Learning (CoRL), 2024. 7, 2
2024
-
[19]
Galaxea r1 lite.https://galaxea-dynamics.com/,
Galaxea. Galaxea r1 lite.https://galaxea-dynamics.com/,
-
[20]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[21]
(2023) Maniskill2: A unified benchmark for generalizable manipulation skills
Jiayuan Gu, Fanbo Xiang, Xuanlin Li, Zhan Ling, Xiqiang Liu, Tongzhou Mu, Yihe Tang, Stone Tao, Xinyue Wei, Yunchao Yao, et al. Maniskill2: A unified bench- mark for generalizable manipulation skills.arXiv preprint arXiv:2302.04659, 2023. 7
-
[22]
Zhi Hou, Tianyi Zhang, Yuwen Xiong, Haonan Duan, Hengjun Pu, Ronglei Tong, Chengyang Zhao, Xizhou Zhu, Yu Qiao, Jifeng Dai, et al. Dita: Scaling diffusion trans- former for generalist vision-language-action policy.arXiv preprint arXiv:2503.19757, 2025. 6
-
[23]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2
2022
-
[24]
CoDES: A context-efficient framework for enhancing small language models via domain-specific adaptation and model ensembling.Preprints, 2026
Lan Hu, Yuting Xin, Binqi Shen, Hanyu Cai, and Lier Jin. CoDES: A context-efficient framework for enhancing small language models via domain-specific adaptation and model ensembling.Preprints, 2026. 2
2026
-
[25]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A general- ist robot policy with predictive visual representations.arXiv preprint arXiv:2412.14803, 2024. 3
work page internal anchor Pith review arXiv 2024
-
[26]
An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world.arXiv preprint arXiv:2311.12871, 2023. 3
-
[27]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision-language-action model with open-world generaliza- tion.arXiv preprint arXiv:2504.16054, 2025. 2, 6
work page internal anchor Pith review arXiv 2025
-
[28]
Yueru Jia, Jiaming Liu, Sixiang Chen, Chenyang Gu, Zhilue Wang, Longzan Luo, Lily Lee, Pengwei Wang, Zhongyuan Wang, Renrui Zhang, et al. Lift3d foundation policy: Lifting 2d large-scale pretrained models for robust 3d robotic ma- nipulation.arXiv preprint arXiv:2411.18623, 2024. 3
-
[29]
doi:10.48550/ARXIV.2410.11831 SA Conference Papers ’25, December 15–18, 2025, Hong Kong, Hong Kong
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos. InProc. arXiv:2410.11831, 2024. 5
-
[30]
Co- tracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker: It is better to track together. InEuropean conference on computer vision, pages 18–35. Springer, 2024. 5
2024
-
[31]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 1, 2, 6, 7
work page internal anchor Pith review arXiv 2024
-
[32]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Opti- mizing speed and success.arXiv preprint arXiv:2502.19645,
work page internal anchor Pith review arXiv
-
[33]
arXiv preprint arXiv:2503.07511 (2025)
Chengmeng Li, Junjie Wen, Yan Peng, Yaxin Peng, Feifei Feng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.arXiv preprint arXiv:2503.07511, 2025. 2, 3
-
[34]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational conference on machine learning, pages 19730– 19742. PMLR, 2023. 2
2023
-
[35]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipu- lation learning with vision-language models.arXiv preprint arXiv:2506.07961, 2025. 3
-
[36]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision- language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650,
-
[37]
Lion-fs: Fast & slow video-language thinker as on- line video assistant
Wei Li, Bing Hu, Rui Shao, Leyang Shen, and Liqiang Nie. Lion-fs: Fast & slow video-language thinker as on- line video assistant. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 3240–3251, 2025. 2
2025
-
[38]
Wei Li, Renshan Zhang, Rui Shao, Zhijian Fang, Kai- wen Zhou, Zhuotao Tian, and Liqiang Nie. Se- manticvla: Semantic-aligned sparsification and enhance- ment for efficient robotic manipulation.arXiv preprint arXiv:2511.10518, 2025. 1
-
[39]
Wei Li, Renshan Zhang, Rui Shao, Jie He, and Liqiang Nie. Cogvla: Cognition-aligned vision-language-action model via instruction-driven routing & sparsification.arXiv preprint arXiv:2508.21046, 2025. 1
-
[40]
Manipllm: Embodied multimodal large language model for object-centric robotic manipulation
Xiaoqi Li, Mingxu Zhang, Yiran Geng, Haoran Geng, Yux- ing Long, Yan Shen, Renrui Zhang, Jiaming Liu, and Hao Dong. Manipllm: Embodied multimodal large language model for object-centric robotic manipulation. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18061–18070, 2024. 6
2024
-
[41]
3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation
Xiaoqi Li, Liang Heng, Jiaming Liu, Yan Shen, Chenyang Gu, Zhuoyang Liu, Hao Chen, Nuowei Han, Renrui Zhang, Hao Tang, et al. 3ds-vla: A 3d spatial-aware vision language action model for robust multi-task manipulation. In9th An- nual Conference on Robot Learning, 2025. 3
2025
-
[42]
Taco: Enhancing multimodal in- context learning via task mapping-guided sequence configu- ration
Yanshu Li, Jianjiang Yang, Tian Yun, Pinyuan Feng, Jinfa Huang, and Ruixiang Tang. Taco: Enhancing multimodal in- context learning via task mapping-guided sequence configu- ration. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 736–763,
2025
-
[43]
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Weili Guan, Dongmei Jiang, Yaowei Wang, and Liqiang Nie. Optimus-3: Dual-router aligned mixture-of-experts agent with dual-granularity reasoning-aware policy optimization. arXiv preprint arXiv:2506.10357, 2025. 2
-
[44]
Optimus-2: Multimodal minecraft agent with goal-observation-action conditioned policy
Zaijing Li, Yuquan Xie, Rui Shao, Gongwei Chen, Dongmei Jiang, and Liqiang Nie. Optimus-2: Multimodal minecraft agent with goal-observation-action conditioned policy. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 9039–9049, 2025. 2
2025
-
[45]
arXiv preprint arXiv:2602.20200 , year=
Zaijing Li, Bing Hu, Rui Shao, Gongwei Chen, Dongmei Jiang, Pengwei Xie, Jianye Hao, and Liqiang Nie. Global prior meets local consistency: Dual-memory augmented vision-language-action model for efficient robotic manipu- lation.arXiv preprint arXiv:2602.20200, 2026. 1
-
[46]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-language- action model with implicit spatial understanding.arXiv preprint arXiv:2507.00416, 2025. 2, 3
-
[47]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310, 2023. 7, 2
work page internal anchor Pith review arXiv 2023
-
[48]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2
2023
-
[49]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024. 2
2024
-
[50]
Hybridvla: Collaborative diffusion and autoregression in a unified vision-language-action model
Jiaming Liu, Hao Chen, Pengju An, Zhuoyang Liu, Ren- rui Zhang, Chenyang Gu, Xiaoqi Li, Ziyu Guo, Sixiang Chen, Mengzhen Liu, et al. Hybridvla: Collaborative diffu- sion and autoregression in a unified vision-language-action model.arXiv preprint arXiv:2503.10631, 2025. 2
-
[51]
Puma: Layer-pruned language model for efficient unified multimodal retrieval with modality-adaptive learning
Yibo Lyu, Rui Shao, Gongwei Chen, Yijie Zhu, Weili Guan, and Liqiang Nie. Puma: Layer-pruned language model for efficient unified multimodal retrieval with modality-adaptive learning. InProceedings of the 33rd ACM International Con- ference on Multimedia, pages 7653–7662, 2025. 2
2025
-
[52]
Yibo Lyu, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Personalalign: Hierarchical implicit intent alignment for personalized gui agent with long-term user- centric records.arXiv preprint arXiv:2601.09636, 2026. 2
work page internal anchor Pith review arXiv 2026
-
[53]
Chaojun Ni, Cheng Chen, Xiaofeng Wang, Zheng Zhu, Wen- zhao Zheng, Boyuan Wang, Tianrun Chen, Guosheng Zhao, Haoyun Li, Zhehao Dong, et al. Swiftvla: Unlocking spa- tiotemporal dynamics for lightweight vla models at minimal overhead.arXiv preprint arXiv:2512.00903, 2025. 1
-
[54]
arXiv preprint arXiv:2504.02261 (2025)
Chaojun Ni, Xiaofeng Wang, Zheng Zhu, Weijie Wang, Haoyun Li, Guosheng Zhao, Jie Li, Wenkang Qin, Guan Huang, and Wenjun Mei. Wonderturbo: Generating interactive 3d world in 0.72 seconds.arXiv preprint arXiv:2504.02261, 2025. 2
-
[55]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 3, 1
work page internal anchor Pith review arXiv 2023
-
[56]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Du- moulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI con- ference on artificial intelligence, 2018. 4, 1
2018
-
[57]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision- language-action models.arXiv preprint arXiv:2501.09747,
work page internal anchor Pith review arXiv
-
[58]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, et al. Spatialvla: Exploring spatial represen- tations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025. 2, 3, 6, 7
work page internal anchor Pith review arXiv 2025
-
[59]
Vi- sion transformers for dense prediction.ArXiv preprint, 2021
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction.ArXiv preprint, 2021. 3
2021
-
[60]
Deep con- volutional dynamic texture learning with adaptive channel- discriminability for 3d mask face anti-spoofing
Rui Shao, Xiangyuan Lan, and Pong C Yuen. Deep con- volutional dynamic texture learning with adaptive channel- discriminability for 3d mask face anti-spoofing. In2017 IEEE International Joint Conference on Biometrics (IJCB), pages 748–755. IEEE, 2017. 2
2017
-
[61]
Multi-adversarial discriminative deep domain generalization for face presentation attack detection
Rui Shao, Xiangyuan Lan, Jiawei Li, and Pong C Yuen. Multi-adversarial discriminative deep domain generalization for face presentation attack detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10023–10031, 2019
2019
-
[62]
Detecting and grounding multi-modal media manipulation
Rui Shao, Tianxing Wu, and Ziwei Liu. Detecting and grounding multi-modal media manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 6904–6913, 2023
2023
-
[63]
Detecting and grounding multi-modal media manip- ulation and beyond.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
Rui Shao, Tianxing Wu, Jianlong Wu, Liqiang Nie, and Zi- wei Liu. Detecting and grounding multi-modal media manip- ulation and beyond.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 2
2024
-
[64]
arXiv preprint arXiv:2508.13073 , year=
Rui Shao, Wei Li, Lingsen Zhang, Renshan Zhang, Zhiyang Liu, Ran Chen, and Liqiang Nie. Large vlm-based vision- language-action models for robotic manipulation: A survey. arXiv preprint arXiv:2508.13073, 2025. 1
-
[65]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Ar- actingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844,
work page internal anchor Pith review arXiv
-
[66]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Jun Ma, and Haoang Li. Accelerating vision-language-action model integrated with action chunking via parallel decoding.arXiv preprint arXiv:2503.02310, 2025. 2
-
[67]
Geovla: Em- powering 3d representations in vision-language-action models,
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representations in vision- language-action models.arXiv preprint arXiv:2508.09071,
-
[68]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024. 2, 6
work page internal anchor Pith review arXiv 2024
-
[69]
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024. 3
-
[70]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 1
2017
-
[71]
Open x-embodiment: Robotic learning datasets and rt-x models
Quan Vuong, Sergey Levine, Homer Rich Walke, Karl Pertsch, Anikait Singh, Ria Doshi, Charles Xu, Jianlan Luo, Liam Tan, Dhruv Shah, et al. Open x-embodiment: Robotic learning datasets and rt-x models. InTowards General- ist Robots: Learning Paradigms for Scalable Skill Acquisi- tion@ CoRL2023, 2023. 2
2023
-
[72]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 3, 1
2025
-
[73]
Gui-explorer: Au- tonomous exploration and mining of transition-aware knowl- edge for gui agent
Bin Xie, Rui Shao, Gongwei Chen, Kaiwen Zhou, Yinchuan Li, Jie Liu, Min Zhang, and Liqiang Nie. Gui-explorer: Au- tonomous exploration and mining of transition-aware knowl- edge for gui agent. InAnnual Meeting of the Association for Computational Linguistics (ACL), 2025. 2
2025
-
[74]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[75]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024. 5
2024
-
[76]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 5
2024
-
[77]
Instrucrobo: Object-centric multi-instruction decou- pling model for explainable robotic manipulation.Engineer- ing Applications of Artificial Intelligence, 171:114166, 2026
Panqi Yang, Haodong Jing, Nanning Zheng, and Yongqiang Ma. Instrucrobo: Object-centric multi-instruction decou- pling model for explainable robotic manipulation.Engineer- ing Applications of Artificial Intelligence, 171:114166, 2026. 3
2026
-
[78]
Unibvr: Balancing visual and reasoning abilities in uni- fied 3d scene understanding.Neurocomputing, 671:132599, 2026
Panqi Yang, Haodong Jing, Nanning Zheng, and Yongqiang Ma. Unibvr: Balancing visual and reasoning abilities in uni- fied 3d scene understanding.Neurocomputing, 671:132599, 2026
2026
-
[79]
Fp3: A 3d foundation policy for robotic manipulation.arXiv preprint arXiv:2503.08950, 2025
Rujia Yang, Geng Chen, Chuan Wen, and Yang Gao. Fp3: A 3d foundation policy for robotic manipulation.arXiv preprint arXiv:2503.08950, 2025. 3
-
[80]
Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024
Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, and Gao Huang. Deer-vla: Dynamic inference of multimodal large language models for efficient robot execution.Advances in Neural Information Processing Systems, 37:56619–56643, 2024. 2
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.