Recognition: no theorem link
PersonalAlign: Hierarchical Implicit Intent Alignment for Personalized GUI Agent with Long-Term User-Centric Records
Pith reviewed 2026-05-16 14:29 UTC · model grok-4.3
The pith
Hierarchical memory from long-term records lets GUI agents resolve vague instructions and anticipate routines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
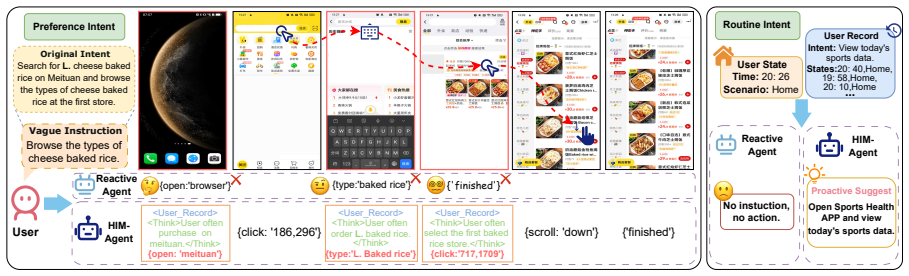
HIM-Agent maintains a continuously updating personal memory and hierarchically organizes user preferences and routines for personalization, enabling the agent to resolve omitted preferences in vague instructions and anticipate latent routines by user state for proactive assistance on the AndroidIntent benchmark.
What carries the argument
HIM-Agent, which maintains a continuously updating personal memory and hierarchically organizes user preferences and routines.
If this is right
- GUI agents can complete vague instructions more reliably by referencing accumulated user history instead of treating each command in isolation.
- Proactive suggestions become possible once the agent infers current user state from stored routines.
- Performance scales with the volume and structure of long-term records rather than prompt length alone.
- Standard multimodal models gain measurable lifts when the same hierarchical memory layer is added.
Where Pith is reading between the lines
- The same hierarchical organization could be adapted to web or desktop agents beyond the Android setting.
- Agents using this memory would eventually need explicit update or forgetting rules to handle preference drift over months or years.
- The annotated preferences and routines could serve as supervision for training smaller, on-device personalized models.
Load-bearing premise
The 20k long-term records contain stable, generalizable user preferences and routines that transfer to new vague instructions without overfitting to the original 20 users.
What would settle it
Testing HIM-Agent on instructions or records from a fresh group of users outside the original 20 would show whether the reported gains in execution and proactive performance hold.
Figures





read the original abstract
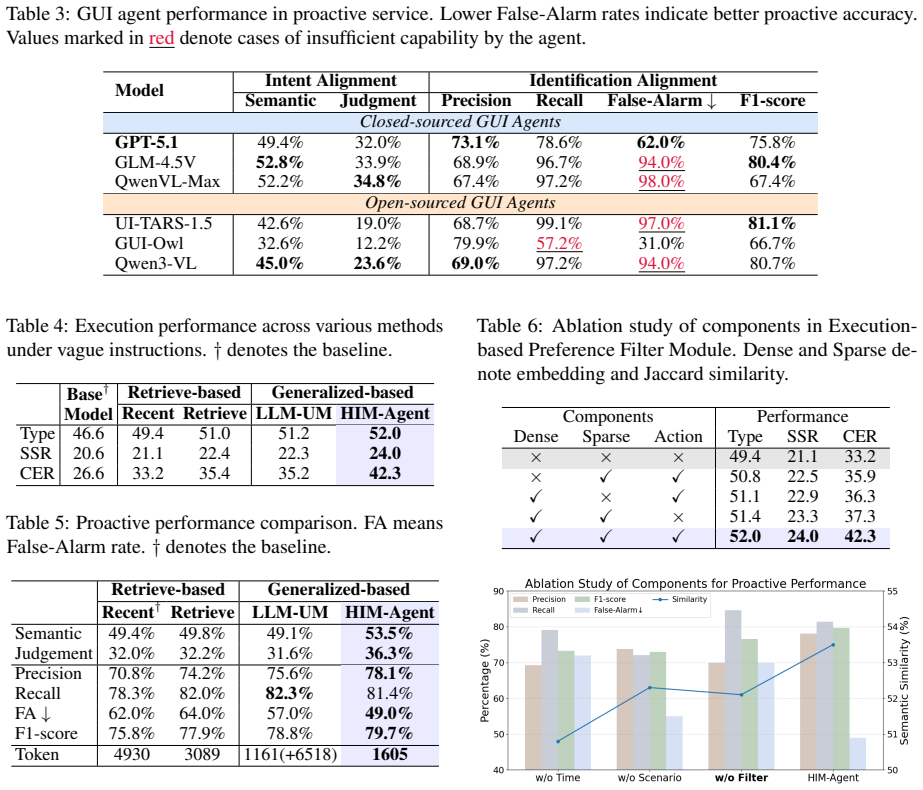
While GUI agents have shown strong performance under explicit and completion instructions, real-world deployment requires aligning with users' more complex implicit intents. In this work, we highlight Hierarchical Implicit Intent Alignment for Personalized GUI Agent (PersonalAlign), a new agent task that requires agents to leverage long-term user records as persistent context to resolve omitted preferences in vague instructions and anticipate latent routines by user state for proactive assistance. To facilitate this study, we introduce AndroidIntent, a benchmark designed to evaluate agents' ability in resolving vague instructions and providing proactive suggestions through reasoning over long-term user records. We annotated 775 user-specific preferences and 215 routines from 20k long-term records across different users for evaluation. Furthermore, we introduce Hierarchical Intent Memory Agent (HIM-Agent), which maintains a continuously updating personal memory and hierarchically organizes user preferences and routines for personalization. Finally, we evaluate a range of GUI agents on AndroidIntent, including GPT-5, Qwen3-VL, and UI-TARS, further results show that HIM-Agent significantly improves both execution and proactive performance by 15.7% and 7.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the PersonalAlign task for GUI agents to resolve implicit intents in vague instructions and provide proactive assistance by leveraging long-term user records. It presents the AndroidIntent benchmark, which annotates 775 user-specific preferences and 215 routines from 20k records across 20 users. The proposed Hierarchical Intent Memory Agent (HIM-Agent) maintains a continuously updating personal memory and organizes preferences and routines hierarchically for personalization. Evaluations on AndroidIntent show HIM-Agent improving execution performance by 15.7% and proactive performance by 7.3% over baselines including GPT-5, Qwen3-VL, and UI-TARS.
Significance. If the reported gains prove robust under proper generalization testing, this work would be significant for advancing personalized GUI agents that handle real-world vague instructions and anticipate user routines. The new benchmark and hierarchical memory mechanism address an important gap in current GUI agent research, providing a concrete foundation for future studies on long-term user-centric alignment. The empirical deltas on a dedicated benchmark constitute a clear strength.
major comments (2)
- [Benchmark construction (AndroidIntent section)] Benchmark construction (AndroidIntent section): The 775 preferences and 215 routines are annotated directly from the same 20 users' 20k records, with benchmark instructions drawn from the identical user pool and no user-holdout split described. This setup risks the 15.7% execution and 7.3% proactive gains reflecting memorization of the small cohort rather than transferable intent alignment via hierarchical memory, directly undermining the central claim of generalizable personalization.
- [Experiments section] Experiments section: The abstract reports concrete percentage gains, but without visible details on the full evaluation protocol, baseline implementations, or statistical significance tests, it is impossible to verify whether the improvements are robust or affected by post-hoc choices.
minor comments (2)
- [HIM-Agent method] The description of how HIM-Agent continuously updates the personal memory and performs hierarchical organization would benefit from additional pseudocode or a detailed diagram.
- [Results tables] Ensure all tables reporting performance metrics include standard deviations or confidence intervals for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment point by point below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: Benchmark construction (AndroidIntent section): The 775 preferences and 215 routines are annotated directly from the same 20 users' 20k records, with benchmark instructions drawn from the identical user pool and no user-holdout split described. This setup risks the 15.7% execution and 7.3% proactive gains reflecting memorization of the small cohort rather than transferable intent alignment via hierarchical memory, directly undermining the central claim of generalizable personalization.
Authors: This is a fair and important point. The benchmark instructions are newly formulated vague queries that require inference over the long-term records rather than direct lookup, and the hierarchical memory is intended to support such reasoning. Nevertheless, to strengthen the evidence for generalizable personalization, we will revise the AndroidIntent section to include an explicit user-holdout protocol: we will partition the 20 users into seen and held-out groups, build memory only from seen users' records, and report separate results on held-out users. This addition will directly address concerns about memorization versus transferable alignment. revision: yes
-
Referee: Experiments section: The abstract reports concrete percentage gains, but without visible details on the full evaluation protocol, baseline implementations, or statistical significance tests, it is impossible to verify whether the improvements are robust or affected by post-hoc choices.
Authors: We agree that the current Experiments section is insufficiently detailed for reproducibility and verification. In the revised manuscript we will expand this section to include: (i) the complete evaluation protocol (instruction sampling procedure, metric definitions, and number of runs); (ii) precise implementation details and prompts used for all baselines (GPT-5, Qwen3-VL, UI-TARS); and (iii) statistical significance results (paired t-tests with p-values) supporting the reported 15.7% and 7.3% gains. We will also add an ablation study isolating the contribution of the hierarchical memory components. revision: yes
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper introduces AndroidIntent as a new benchmark constructed from 20k user records across 20 users, annotates 775 preferences and 215 routines directly from those records, and proposes HIM-Agent to hierarchically organize them into memory for personalization. All reported gains (15.7% execution, 7.3% proactive) are measured as empirical performance deltas on this benchmark rather than any mathematical derivation, fitted parameter renamed as prediction, or self-citation chain that reduces the central claim to its own inputs by construction. No equations, uniqueness theorems, or ansatzes are invoked that would create self-definitional loops; the evaluation remains externally falsifiable against the held-out instructions even if generalization concerns exist separately.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-term user records contain persistent, extractable preferences and routines that generalize to future vague instructions.
Forward citations
Cited by 2 Pith papers
-
ConsisVLA-4D: Advancing Spatiotemporal Consistency in Efficient 3D-Perception and 4D-Reasoning for Robotic Manipulation
ConsisVLA-4D adds cross-view semantic alignment, cross-object geometric fusion, and cross-scene dynamic reasoning to VLA models, delivering 21.6% and 41.5% gains plus 2.3x and 2.4x speedups on LIBERO and real-world tasks.
-
Behavior Latticing: Inferring User Motivations from Unstructured Interactions
Behavior latticing synthesizes connections across unstructured user interactions to generate insights into underlying motivations, yielding deeper and more accurate user understanding than task-only models.
Reference graph
Works this paper leans on
-
[1]
Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661. Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhi- fang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai
Score the steps, not just the goal: Vlm-based subgoal evaluation for robotic manipulation.arXiv preprint arXiv:2509.19524. Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. 2025. Memory os of ai agent.arXiv preprint arXiv:2506.06326. Wei Li, William E Bishop, Alice Li, Christopher Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. 2024...
-
[3]
Multi-adversarial discriminative deep domain generalization for face presentation attack detection. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 10023– 10031. Rui Shao, Tianxing Wu, and Ziwei Liu. 2023. Detecting and grounding multi-modal media manipulation. In Proceedings of the IEEE/CVF Conference on Com- ...
-
[4]
Advances in Neural Information Processing Systems, 37:52040–52094
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Yuquan Xie, Zaijing Li, Rui Shao, Gongwei Chen, Kai- wen Zhou, Yinchuan Li, Dongmei Jiang, and Liqiang Nie. 2025b. Mirage-1: Augmenting and updating gui agent with hierarchical multimodal skills.arX...
-
[5]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Memagent: Reshaping long-context llm with multi-conv rl-based memory agent.arXiv preprint arXiv:2507.02259. Renshan Zhang, Yibo Lyu, Rui Shao, Gongwei Chen, Weili Guan, and Liqiang Nie. 2024. Token-level correlation-guided compression for efficient mul- timodal document understanding.arXiv preprint arXiv:2407.14439. Renshan Zhang, Rui Shao, Gongwei Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Moment Intent If the current intent rarely appears or does not appear in the history, and you believe that a complete and explicit description is required for the agent to execute it correctly
-
[7]
Preference Intent If similar intent have appeared multiple times in history, and you believe the user has performed this action repeatedly, such that only minimal information is needed and the remaining details can be inferred from past interactions. After selecting this option, you are required to choose one personalized instruction from the provided vag...
-
[8]
Except for the preference intent, no additional instruction selection is required
Routine Intent If the intent has appeared many times in nearly identical forms, and you believe the user has performed it frequently enough that the agent can infer the intent directly from historical patterns, especially from the time and scenario, without any additional information. Except for the preference intent, no additional instruction selection i...
-
[9]
Please provide your output in JSON format, following this structure: { "summaries": [ { "reasoning": "Briefly explain your reasoning for the preference", "preference": "A concise summary of what types of apps/items this user is likely to enjoy, e.g.'User preference for shopping with App A'", "confidence": "High/Medium/Low", "action": "Summarize one User's...
-
[10]
Ensure that each "preference" is highly concise. It should clearly describe one app + one specific type of task/content the user prefers
- [11]
-
[12]
However, " action" field must keep the original English types from the`action_list`
The answer should be in Chinese. However, " action" field must keep the original English types from the`action_list`
-
[13]
Do not provide any text outside of the JSON string
-
[14]
- Avoid fabricating preferences when evidence is weak; use'None'when uncertain
Additional requirement: - If several apps appear interchangeable but one is used significantly more often for a specific task, treat that as a preference. - Avoid fabricating preferences when evidence is weak; use'None'when uncertain. ## User Profile: {profile} ## User History: {previous_intents} F.2 Prompt for Proactive You are skilled at analyzing user ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.