Recognition: unknown
The First Token Knows: Single-Decode Confidence for Hallucination Detection
Pith reviewed 2026-05-08 16:32 UTC · model grok-4.3
The pith
Uncertainty in the first content token of one greedy decode matches or exceeds multi-sample semantic self-consistency for detecting hallucinations on factual questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
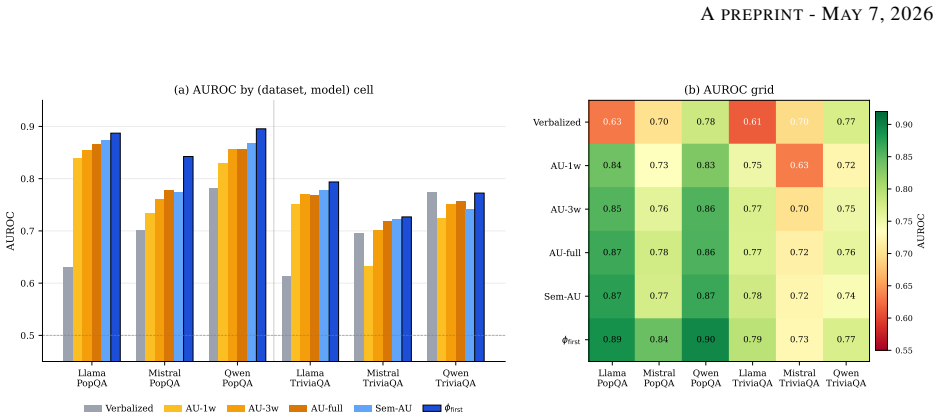
First-token , defined as the normalized entropy of the top-K logits at the first content-bearing token produced by a single greedy decode, achieves a mean AUROC of 0.820 across three 7-8B models and two benchmarks, compared with 0.793 for semantic agreement and 0.791 for surface-form self-consistency. The measure is moderately to strongly correlated with semantic agreement, and their combination improves AUROC only slightly over the single-token signal alone. These results indicate that the uncertainty information needed for hallucination detection is largely present in the model's initial token distribution.
What carries the argument
first-token (phi_first), the normalized entropy computed from the top-K logits at the single first content-bearing token of one greedy decode
If this is right
- Hallucination detection can be performed with one forward pass instead of multiple sampled generations.
- Methods that rely on agreement across samples can be replaced or augmented by a single-token entropy check without loss of performance on short factual answers.
- Uncertainty quantification pipelines can default to reporting phi_first before incurring sampling costs.
- The correlation between first-token entropy and semantic agreement suggests that later tokens add limited new information about factual reliability.
Where Pith is reading between the lines
- If the first token already encodes most uncertainty, training or fine-tuning procedures could be adjusted to make early-token distributions more informative by design.
- The approach may generalize to longer or open-ended generations if the first content token reliably signals the direction of the entire answer.
- Integration into decoding algorithms could allow early termination or reranking when the first token shows high entropy.
Load-bearing premise
The normalized entropy at the single first content-bearing token in a greedy decode serves as a sufficient proxy for the model's overall uncertainty about whether the full answer is factually correct.
What would settle it
On a new set of factual questions or a different model family, compute phi_first and semantic agreement for the same generations and check whether phi_first AUROC falls substantially below that of semantic agreement while the two remain uncorrelated.
Figures
read the original abstract
Self-consistency detects hallucinations by generating multiple sampled answers to a question and measuring agreement, but this requires repeated decoding and can be sensitive to lexical variation. Semantic self-consistency improves this by clustering sampled answers by meaning using natural language inference, but it adds both sampling cost and external inference overhead. We show that first-token confidence, phi_first, computed from the normalized entropy of the top-K logits at the first content-bearing answer token of a single greedy decode, matches or modestly exceeds semantic self-consistency on closed-book short-answer factual question answering. Across three 7-8B instruction-tuned models and two benchmarks, phi_first achieves a mean AUROC of 0.820, compared with 0.793 for semantic agreement and 0.791 for standard surface-form self-consistency. A subsumption test shows that phi_first is moderately to strongly correlated with semantic agreement, and combining the two signals yields only a small AUROC improvement over phi_first alone. These results suggest that much of the uncertainty information captured by multi-sample agreement is already available in the model's initial token distribution. We argue that phi_first should be reported as a default low-cost baseline before invoking sampling-based uncertainty estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes phi_first, a low-cost hallucination detection score computed as the normalized entropy over the top-K logits at the first content-bearing token of a single greedy decode. It reports that this score achieves a mean AUROC of 0.820 on closed-book short-answer factual QA across three 7-8B models and two benchmarks, modestly exceeding semantic self-consistency (0.793) and surface-form self-consistency (0.791). A subsumption analysis finds moderate-to-strong correlation with semantic agreement and only marginal AUROC gains when the signals are combined, suggesting that much of the uncertainty captured by multi-sample methods is already present in the initial token distribution.
Significance. If the empirical results hold under fully specified and reproducible conditions, the work would be significant as a practical baseline for uncertainty estimation: it demonstrates that a single forward pass can rival or exceed the performance of sampling-based methods that require multiple decodes plus external NLI inference. The head-to-head comparison on held-out benchmarks and the subsumption test provide concrete evidence that early-generation token distributions encode substantial factual uncertainty, which could reduce computational overhead in deployment settings.
major comments (3)
- [§3] §3 (Method): The precise criterion used to identify the 'first content-bearing answer token' (e.g., POS filter, stop-word exclusion, position threshold, or heuristic) is not stated. Because the central claim rests on this token serving as a sufficient proxy for overall factual uncertainty, an unspecified or potentially data-dependent selection rule risks post-hoc optimization that could inflate the reported AUROC edge (0.820 vs. 0.793).
- [§4] §4 (Experiments): The value of K for the top-K logits, the exact data splits, benchmark versions, and whether K or the token rule were fixed a priori versus tuned on the evaluation sets are not reported. Without these details the modest exceedance over semantic self-consistency cannot be assessed for statistical significance or freedom from selection bias.
- [§4.3] §4.3 (Subsumption test): The claim of 'moderate to strong' correlation between phi_first and semantic agreement is not accompanied by a numerical coefficient, confidence interval, or p-value. This weakens the interpretation that the two signals largely overlap and that combination yields only small gains.
minor comments (2)
- [§3] The exact formula for 'normalized entropy' (e.g., H / log(K) or another scaling) should be written explicitly as an equation in §3 to ensure reproducibility.
- Table or figure captions should include the precise model names, benchmark names, and number of samples per condition rather than referring only to 'three 7-8B models and two benchmarks.'
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and completeness of reporting.
read point-by-point responses
-
Referee: [§3] §3 (Method): The precise criterion used to identify the 'first content-bearing answer token' (e.g., POS filter, stop-word exclusion, position threshold, or heuristic) is not stated. Because the central claim rests on this token serving as a sufficient proxy for overall factual uncertainty, an unspecified or potentially data-dependent selection rule risks post-hoc optimization that could inflate the reported AUROC edge (0.820 vs. 0.793).
Authors: We agree that the selection criterion for the first content-bearing answer token must be stated explicitly. The manuscript omitted a full description of this heuristic. We will revise §3 to provide the precise rule (including any stop-word exclusion, punctuation handling, or position logic) and include pseudocode or a reference implementation for full reproducibility. We will also add a brief robustness check with an alternative token-selection rule to address concerns about potential optimization. revision: yes
-
Referee: [§4] §4 (Experiments): The value of K for the top-K logits, the exact data splits, benchmark versions, and whether K or the token rule were fixed a priori versus tuned on the evaluation sets are not reported. Without these details the modest exceedance over semantic self-consistency cannot be assessed for statistical significance or freedom from selection bias.
Authors: We acknowledge that these implementation and experimental details were not reported. We will revise §4 to specify the value of K, the exact benchmark versions and data splits used, and to confirm that both K and the token-selection rule were fixed a priori on a separate development set with no overlap to the reported evaluation data. We will also include statistical significance tests for the AUROC comparisons to allow proper assessment of the observed differences. revision: yes
-
Referee: [§4.3] §4.3 (Subsumption test): The claim of 'moderate to strong' correlation between phi_first and semantic agreement is not accompanied by a numerical coefficient, confidence interval, or p-value. This weakens the interpretation that the two signals largely overlap and that combination yields only small gains.
Authors: We agree that the subsumption analysis would be strengthened by quantitative measures. We will revise §4.3 to report the exact correlation coefficient (with confidence interval and p-value) between phi_first and semantic agreement, as well as the AUROC values for the combined signal, to support the interpretation of overlap and limited additional gains. revision: yes
Circularity Check
No circularity: empirical benchmark comparison with no derivation chain
full rationale
The paper reports an empirical head-to-head evaluation of phi_first (normalized entropy at the first content-bearing token in a single greedy decode) against semantic self-consistency and surface-form self-consistency, using AUROC on held-out factual QA benchmarks across three models. No equations, derivations, or first-principles results are presented that reduce to fitted parameters, self-definitions, or self-citation chains by construction. The token-selection rule and K are described as fixed components of the method, and results are presented as direct measurements rather than predictions forced by the inputs. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[2]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[3]
Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. Generating with confidence: Uncertainty quantification for black-box large language models.Transactions on Machine Learning Research, 2024
2024
-
[4]
DeBERTa: Decoding-enhanced BERT with disentangled attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. DeBERTa: Decoding-enhanced BERT with disentangled attention. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[5]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[6]
Can LLMs Express Their Uncertainty? An Empirical Evaluation of Confidence Elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their uncertainty? an empirical evaluation of confidence elicitation in LLMs.arXiv preprint arXiv:2306.13063, 2023
work page internal anchor Pith review arXiv 2023
-
[7]
When not to trust language models: Investigating effectiveness of parametric and non-parametric memories
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
2023
-
[8]
Weld, and Luke Zettlemoyer
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), 2017
2017
-
[9]
Abhimanyu Dubey et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[10]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
An Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Uncertainty estimation in autoregressive structured prediction
Andrey Malinin and Mark Gales. Uncertainty estimation in autoregressive structured prediction. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[13]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[14]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP, 2023. 6
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.