Recognition: unknown
Taming Outlier Tokens in Diffusion Transformers
Pith reviewed 2026-05-08 17:15 UTC · model grok-4.3
The pith
Dual-stage registers tame outlier tokens in diffusion transformers to reduce artifacts and improve image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Outlier tokens emerge in both the encoder and denoiser of RAE-DiT pipelines; they reflect corrupted local patch semantics that masking does not resolve. Dual-Stage Registers correct this by inserting register tokens at the two stages—trained registers for the encoder when possible, recursive test-time registers when not, and diffusion-specific registers for the denoiser—yielding measurable reductions in artifacts and gains in generation quality.
What carries the argument
Dual-Stage Registers (DSR), a register-based intervention that supplies dedicated tokens to both the encoder and denoiser to restore local semantics.
If this is right
- Outlier artifacts decrease in the final generated images.
- Generation quality rises on ImageNet benchmarks.
- The same gains appear in large-scale text-to-image settings.
- The fix applies uniformly to both pretrained ViT encoders and internal DiT layers.
Where Pith is reading between the lines
- Attention layers in transformers may generally benefit from explicit register tokens to quarantine semantically damaged patches.
- Similar register stages could be tested in non-diffusion transformer generators or in vision-language models.
- If outlier control proves scalable, it might reduce the need for ever-larger DiT models to achieve clean outputs.
Load-bearing premise
That the performance drag comes from corrupted local patch semantics rather than raw norm extremes, and that registers can restore semantics without introducing new distortions or degrading other generation aspects.
What would settle it
Running the same DiT pipelines with Dual-Stage Registers applied and finding no change or a drop in standard image quality metrics such as FID, or discovering that high-norm masking suddenly improves results.
Figures

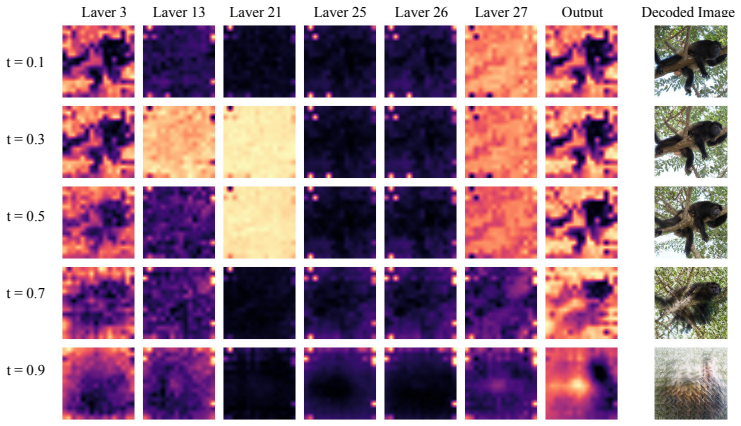
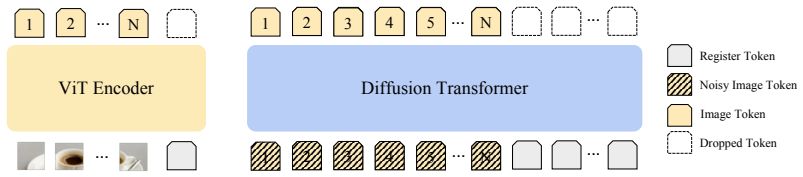



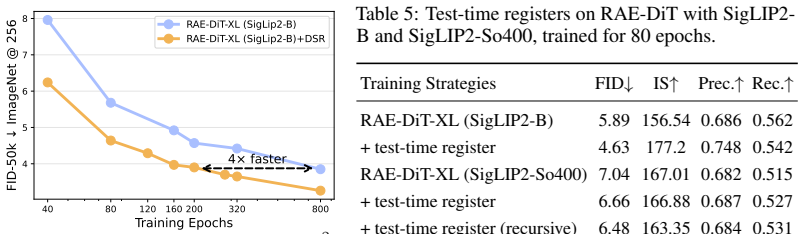












read the original abstract
We study outlier tokens in Diffusion Transformers (DiTs) for image generation. Prior work has shown that Vision Transformers (ViTs) can produce a small number of high-norm tokens that attract disproportionate attention while carrying limited local information, but their role in generative models remains underexplored. We show that this phenomenon appears in both the encoder and denoiser of modern Representation Autoencoder (RAE)-DiT pipelines: pretrained ViT encoders can produce outlier representations, and DiTs themselves can develop internal outlier tokens, especially in intermediate layers. Moreover, simply masking high-norm tokens does not improve performance, indicating that the problem is not only caused by a few extreme values, but is more closely related to corrupted local patch semantics. To address this issue, we introduce Dual-Stage Registers (DSR), a register-based intervention for both components: trained registers when available, recursive test-time registers otherwise, and diffusion registers for the denoiser. Across ImageNet and large-scale text-to-image generation, these interventions consistently reduce outlier artifacts and improve generation quality. Our results highlight outlier-token control as an important ingredient in building stronger DiTs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines outlier tokens (high-norm tokens attracting disproportionate attention with limited local information) in Diffusion Transformers (DiTs) for image generation. It observes their presence in both pretrained ViT encoders and internal DiT layers, argues that the issue stems from corrupted local patch semantics rather than merely extreme norm values (because simply masking high-norm tokens does not improve performance), and proposes Dual-Stage Registers (DSR) consisting of trained registers, recursive test-time registers, and diffusion registers. The central claim is that these interventions reduce outlier artifacts and improve generation quality across ImageNet and large-scale text-to-image tasks.
Significance. If the empirical claims hold with proper controls and metrics, the work could offer a practical, register-based technique for stabilizing DiT training and inference, addressing a previously underexplored artifact in generative transformers. The multi-stage application (encoder and denoiser) is a reasonable extension of prior register ideas from ViTs.
major comments (2)
- [Abstract] Abstract: The claim that 'simply masking high-norm tokens does not improve performance' is used to conclude that the root cause is corrupted local patch semantics rather than extreme norms. However, masking removes the token's full contribution to attention and residuals, which can disrupt global context independently of norm magnitude; without a control that preserves token presence while clamping or normalizing norms, this does not cleanly isolate semantics from magnitude effects.
- [Abstract] Abstract: The assertion of 'consistent' improvements in outlier reduction and generation quality on ImageNet and text-to-image tasks lacks any quantitative support (FID, CLIP scores, artifact counts, baselines, error bars, or ablation tables). This makes the central empirical claim unverifiable from the provided text and load-bearing for the paper's contribution.
minor comments (2)
- [Abstract] The acronym DSR is introduced in the abstract without prior expansion.
- Notation for 'registers' (trained vs. test-time vs. diffusion) is used without a clear upfront definition or diagram of their placement in the pipeline.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below with clarifications from the full paper and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: The claim that 'simply masking high-norm tokens does not improve performance' is used to conclude that the root cause is corrupted local patch semantics rather than extreme norms. However, masking removes the token's full contribution to attention and residuals, which can disrupt global context independently of norm magnitude; without a control that preserves token presence while clamping or normalizing norms, this does not cleanly isolate semantics from magnitude effects.
Authors: We appreciate this observation on the limitations of the masking probe. The experiment was designed to show that removing high-norm tokens entirely fails to resolve the observed artifacts and performance issues, which we interpret as evidence that the problem extends beyond isolated extreme values to the underlying corrupted patch semantics. We agree that a cleaner control—such as clamping or normalizing the norms of these tokens while preserving their presence, attention contributions, and residual connections—would better isolate magnitude from semantic effects. In the revised manuscript we will add this ablation experiment (with quantitative results on both ImageNet and text-to-image settings) to strengthen the causal argument. revision: yes
-
Referee: The assertion of 'consistent' improvements in outlier reduction and generation quality on ImageNet and text-to-image tasks lacks any quantitative support (FID, CLIP scores, artifact counts, baselines, error bars, or ablation tables). This makes the central empirical claim unverifiable from the provided text and load-bearing for the paper's contribution.
Authors: The abstract is intentionally concise and summarizes results whose details appear in the full manuscript. Sections 4 and 5 present the supporting quantitative evidence, including FID scores on ImageNet, CLIP scores on text-to-image benchmarks, artifact counts, comparisons against baselines, ablation tables, and error bars across multiple runs. To make the central claims more immediately verifiable, we will revise the abstract to include representative quantitative highlights (e.g., key FID and CLIP deltas) while respecting length constraints. revision: yes
Circularity Check
No circularity: purely empirical observations and interventions
full rationale
The paper reports observations of high-norm tokens in ViT encoders and DiT denoisers, states that masking them fails to improve performance (directly measured), and introduces DSR registers as an empirical fix that is shown to reduce artifacts on ImageNet and text-to-image tasks. No equations, fitted parameters, predictions, or derivations appear. The interpretive claim linking outliers to 'corrupted local patch semantics' follows from the masking result but does not reduce any quantity to itself by construction. No self-citations are visible or load-bearing for the central claims.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Dual-Stage Registers (DSR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Latent forcing: Reordering the diffusion trajectory for pixel-space image generation
Alan Baade, Eric Ryan Chan, Kyle Sargent, Changan Chen, Justin Johnson, Ehsan Adeli, and Li Fei-Fei. Latent forcing: Reordering the diffusion trajectory for pixel-space image generation. arXiv preprint arXiv:2602.11401, 2026
-
[2]
Black Forest Labs. Flux. https://github.com/black-forest-labs/flux, 2024. GitHub repository
2024
-
[3]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
2021
-
[4]
When vision transformers outperform resnets without pre-training or strong data augmentations
Xiangning Chen, Cho-Jui Hsieh, and Boqing Gong. When vision transformers outperform resnets without pre-training or strong data augmentations. InInternational Conference on Learning Representation, 2022
2022
-
[5]
Vision Transformers Need Registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[8]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[9]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[10]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[11]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[12]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Openclip
Gabriel Ilharco, Mitchell Wortsman, Ross Wightman, Cade Gordon, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, Hongseok Namkoong, John Miller, Hannaneh Hajishirzi, Ali Farhadi, and Ludwig Schmidt. Openclip
-
[14]
Vision transformers don’t need trained registers.arXiv preprint arXiv:2506.08010, 2025
Nick Jiang, Amil Dravid, Alexei Efros, and Yossi Gandelsman. Vision transformers don’t need trained registers.arXiv preprint arXiv:2506.08010, 2025
-
[15]
Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025
2025
-
[16]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InEuropean Conference on Computer Vision, pages 23–40. Springer, 2024. 10
2024
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review arXiv 2023
-
[19]
Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256, 2025
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256, 2025
-
[20]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[21]
Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, et al. A unified view of attention and residual sinks: Outlier-driven rescaling is essential for transformer training.arXiv preprint arXiv:2601.22966, 2026
-
[22]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[23]
Do vision transformers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128, 2021
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128, 2021
2021
-
[24]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[25]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
Jaskirat Singh, Xingjian Leng, Zongze Wu, Liang Zheng, Richard Zhang, Eli Shechtman, and Saining Xie. What matters for representation alignment: Global information or spatial structure? arXiv preprint arXiv:2512.10794, 2025
-
[27]
Deep unsuper- vised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsuper- vised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr, 2015
2015
-
[28]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[29]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review arXiv 2011
-
[30]
Mingjie Sun, Xinlei Chen, J Zico Kolter, and Zhuang Liu. Massive activations in large language models.arXiv preprint arXiv:2402.17762, 2024
-
[31]
Shengbang Tong, Boyang Zheng, Ziteng Wang, Bingda Tang, Nanye Ma, Ellis Brown, Jihan Yang, Rob Fergus, Yann LeCun, and Saining Xie. Scaling text-to-image diffusion transformers with representation autoencoders.arXiv preprint arXiv:2601.16208, 2026
-
[32]
Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International conference on machine learning, pages 10347–10357. PMLR, 2021
2021
-
[33]
Deit iii: Revenge of the vit
Hugo Touvron, Matthieu Cord, and Hervé Jégou. Deit iii: Revenge of the vit. InEuropean conference on computer vision, pages 516–533. Springer, 2022. 11
2022
-
[34]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alab- dulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025
work page internal anchor Pith review arXiv 2025
-
[35]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[36]
Interpretingtherepeated token phenomenon in large language models.arXiv preprint arXiv:2503.08908,
Itay Yona, Ilia Shumailov, Jamie Hayes, Federico Barbero, and Yossi Gandelsman. Interpreting the repeated token phenomenon in large language models.arXiv preprint arXiv:2503.08908, 2025
-
[37]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review arXiv 2024
-
[38]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
2023
-
[39]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025. 12 A Outlier Visualization on SIGLIP2-So400 We further analyze the norm distribution of SIGLIP2-So400 and observe that its outliers do not form a single homogeneous group. Instead, they appear as two clear...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.