Recognition: unknown
Syn4D: A Multiview Synthetic 4D Dataset
Pith reviewed 2026-05-08 17:11 UTC · model grok-4.3
The pith
Syn4D supplies multiview synthetic videos of dynamic scenes with full ground-truth depth, tracking, camera motion, and human poses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Syn4D is a multiview synthetic dataset of dynamic scenes that includes ground-truth camera motion, depth maps, dense tracking, and parametric human pose annotations, with the ability to unproject any pixel into 3D to any time and to any camera.
What carries the argument
The pixel-to-3D unprojection operation across arbitrary time steps and camera views, enabled by the complete synthetic ground-truth annotations.
If this is right
- Algorithms for dense 3D reconstruction of moving scenes can be trained and evaluated with exact geometric supervision.
- 3D point tracking methods gain access to complete, dense ground-truth trajectories across multiple views and time.
- Geometry-aware retargeting of camera paths becomes feasible using the provided motion and depth data.
- Human pose estimation pipelines can leverage parametric annotations synchronized with the 3D scene geometry.
Where Pith is reading between the lines
- If the synthetic scenes capture sufficient motion variety, the dataset could serve as a pre-training source that improves performance when fine-tuned on limited real data.
- The unprojection capability might enable new self-supervised losses that enforce consistency across time and views without manual labels.
- Extending the scene generation process to include more complex interactions or lighting changes would test how far the current annotation quality scales.
Load-bearing premise
The distribution of the generated synthetic dynamic scenes is close enough to real-world videos that models trained or tested on Syn4D will generalize.
What would settle it
A 4D reconstruction or tracking model trained only on Syn4D that produces substantially worse results on real captured dynamic scenes than on the synthetic test set.
Figures







read the original abstract
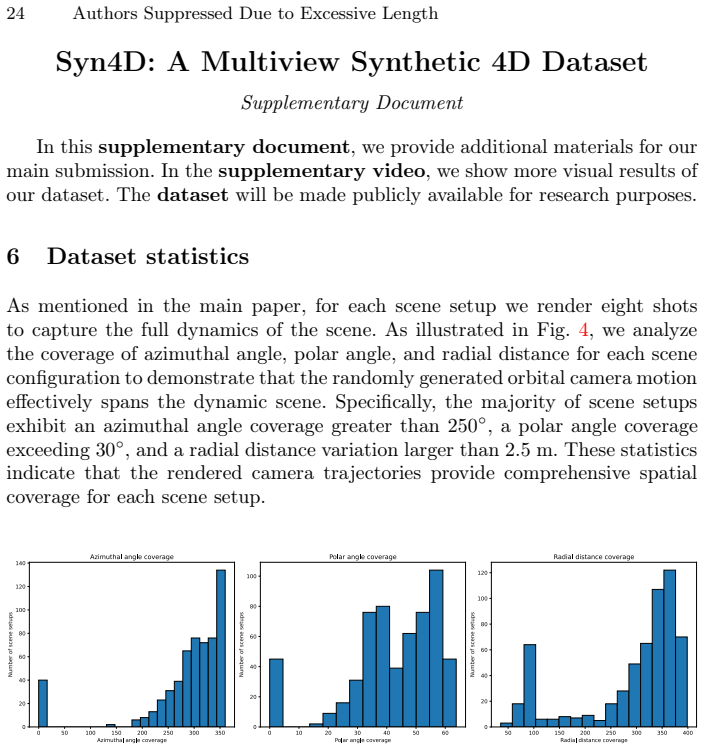
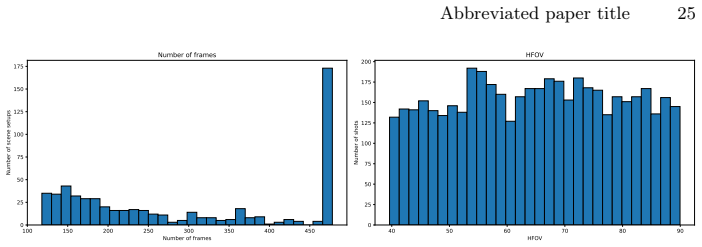
Dense 3D reconstruction and tracking of dynamic scenes from monocular video remains an important open challenge in computer vision. Progress in this area has been constrained by the scarcity of high-quality datasets with dense, complete, and accurate geometric annotations. To address this limitation, we introduce Syn4D, a multiview synthetic dataset of dynamic scenes that includes ground-truth camera motion, depth maps, dense tracking, and parametric human pose annotations. A key feature of Syn4D is the ability to unproject any pixel into 3D to any time and to any camera. We conduct extensive evaluations across multiple downstream tasks to demonstrate the utility and effectiveness of the proposed dataset, including 4D scene reconstruction, 3D point tracking, geometry-aware camera retargeting, and human pose estimation. The experimental results highlight Syn4D's potential to facilitate research in dynamic scene understanding and spatiotemporal modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Syn4D, a multiview synthetic 4D dataset of dynamic scenes that provides exact ground-truth annotations for camera motion, depth maps, dense point tracking, and parametric human poses. A central feature is the ability to unproject any pixel into consistent 3D coordinates across arbitrary times and camera views. The authors report evaluations on downstream tasks including 4D scene reconstruction, 3D point tracking, geometry-aware camera retargeting, and human pose estimation to demonstrate the dataset's utility for dynamic scene understanding.
Significance. If the synthetic scenes are sufficiently diverse and the ground-truth annotations are as exact as claimed by construction in the renderer, Syn4D could provide a valuable resource for benchmarking and training models on tasks where real-world dense 4D annotations are scarce or noisy. The cross-time/cross-view unprojection capability is a direct consequence of the synthetic generation process and represents a clear strength for tasks requiring spatiotemporal consistency.
major comments (1)
- The abstract asserts that 'extensive evaluations across multiple downstream tasks' were conducted and that 'experimental results highlight Syn4D's potential,' yet the manuscript provides no quantitative metrics, baseline comparisons, experimental setups, or result tables to support these claims. This absence is load-bearing for the utility argument, as the central contribution is positioned as enabling progress on these tasks.
minor comments (2)
- Clarify the exact number of scenes, cameras, frames, and human subjects in the dataset description to allow readers to assess scale and diversity.
- The weakest assumption—that synthetic data distribution is close enough to real-world data for generalization—should be explicitly discussed with any available domain-gap analysis or failure cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential value of Syn4D for tasks where real-world dense 4D annotations are scarce. We address the major comment below.
read point-by-point responses
-
Referee: The abstract asserts that 'extensive evaluations across multiple downstream tasks' were conducted and that 'experimental results highlight Syn4D's potential,' yet the manuscript provides no quantitative metrics, baseline comparisons, experimental setups, or result tables to support these claims. This absence is load-bearing for the utility argument, as the central contribution is positioned as enabling progress on these tasks.
Authors: We agree with the referee that the current manuscript does not contain quantitative metrics, baseline comparisons, detailed experimental setups, or result tables for the downstream tasks. While the paper describes how Syn4D supports 4D scene reconstruction, 3D point tracking, geometry-aware camera retargeting, and human pose estimation, the abstract's phrasing implies more concrete empirical support than is currently provided. In the revised manuscript we will add a dedicated experimental section that includes quantitative evaluations, baseline comparisons, full experimental protocols, and result tables for each task to substantiate the utility claims. revision: yes
Circularity Check
No significant circularity: dataset paper with no derivations
full rationale
The paper introduces Syn4D, a synthetic multiview 4D dataset generated via rendering, with all annotations (camera poses, depths, tracks, poses) provided exactly by construction in the renderer. No mathematical derivations, fitted parameters, predictions, or self-referential claims exist. Central claims concern the dataset's existence, release, and utility for downstream tasks (evaluated via standard baselines). No load-bearing steps reduce to inputs by definition or self-citation. This is self-contained against external benchmarks as a resource contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proc
Ankur, H., Viorica, P., Vijay, B., Simon, S., Roberto, C.: SceneNet: understanding real world indoor scenes with synthetic data. In: Proc. CVPR (2015) 5
2015
-
[2]
In: CVPR (2022) 12, 13
Azinović, D., Martin-Brualla, R., Goldman, D.B., Nießner, M., Thies, J.: Neural RGB-D surface reconstruction. In: CVPR (2022) 12, 13
2022
-
[3]
Bahmani, S., Skorokhodov, I., Siarohin, A., Menapace, W., Qian, G., Vasilkovsky, M., Lee, H.Y., Wang, C., Zou, J., Tagliasacchi, A., Lindell, D.B., Tulyakov, S.: Vd3d: Taming large video diffusion transformers for 3d camera control. Proc. ICLR (2025) 6
2025
-
[4]
In: Proc
Bai, J., Xia, M., Fu, X., Wang, X., Mu, L., Cao, J., Liu, Z., Hu, H., Bai, X., Wan, P., Zhang, D.: ReCamMaster: camera-controlled generative rendering from a single video. In: Proc. ICCV (2025) 11
2025
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Bai, J., Xia, M., Fu, X., Wang, X., Mu, L., Cao, J., Liu, Z., Hu, H., Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14834–14844 (2025) 6, 24
2025
-
[6]
Bai, J., Xia, M., Wang, X., Yuan, Z., Fu, X., Liu, Z., Hu, H., Wan, P., Zhang, D.: Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints. arXiv preprint arXiv:2412.07760 (2024) 6
-
[7]
International journal of computer vision (IJCV)92(1), 1–31 (2011) 5
Baker, S., Scharstein, D., Lewis, J.P., Roth, S., Black, M.J., Szeliski, R.: A database and evaluation methodology for optical flow. International journal of computer vision (IJCV)92(1), 1–31 (2011) 5
2011
-
[8]
In: European Conference on Computer Vision
Baradel, F., Armando, M., Galaaoui, S., Brégier, R., Weinzaepfel, P., Rogez, G., Lucas, T.: Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. In: European Conference on Computer Vision. pp. 202–218. Springer (2024) 6
2024
-
[9]
In: Neural Information Processing Systems Datasets and Benchmarks Track (Round
Baruch, G., Chen, Z., Dehghan, A., Dimry, T., Feigin, Y., Fu, P., Gebauer, T., Joffe, B., Kurz, D., Schwartz, A., Shulman, E.: ARKitscenes - a diverse real- world dataset for 3d indoor scene understanding using mobile RGB-d data. In: Neural Information Processing Systems Datasets and Benchmarks Track (Round
-
[10]
(2021),https://openreview.net/forum?id=tjZjv_qh_CE5
2021
-
[11]
In: Proc
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke, S., Stachniss, C., Gall, J.: SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Se- quences. In: Proc. of the IEEE/CVF International Conf. on Computer Vision (ICCV) (2019) 5
2019
-
[12]
In: Proc
Black, M.J., Patel, P., Tesch, J., Yang, J.: BEDLAM: a synthetic dataset of bodies exhibiting detailed lifelike animated motion. In: Proc. CVPR (2023) 2, 4, 5, 6, 14
2023
-
[13]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., Jampani, V., Rombach, R.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv.cs abs/2311.15127(2023) 6
work page internal anchor Pith review arXiv 2023
-
[14]
In: Proc
Butler, D.J., Wulff, J., Stanley, G.B., Black, M.J.: A naturalistic open source movie for optical flow evaluation. In: Proc. ECCV (2012) 4, 12, 13, 27, 28
2012
-
[15]
Cabon, Y., Murray, N., Humenberger, M.: Virtual KITTI 2. arXiv2001.10773 (2020) 4
work page internal anchor Pith review arXiv 2020
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR)
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan,Y.,Baldan,G.,Beijbom,O.:nuscenes:Amultimodaldatasetforautonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR). pp. 11621–11631 (2020) 5 16 Authors Suppressed Due to Excessive Length
2020
-
[17]
International Conference on 3D Vision (3DV) (2017) 5
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., Zhang, Y.: Matterport3d: Learning from rgb-d data in indoor envi- ronments. International Conference on 3D Vision (3DV) (2017) 5
2017
-
[18]
ShapeNet: An Information-Rich 3D Model Repository
Chang, A.X., Funkhouser, T.A., Guibas, L.J., Hanrahan, P., Huang, Q., Li, Z., Savarese, S., Savva, M., Song, S., Su, H., Xiao, J., Yi, L., Yu, F.: ShapeNet: An information-rich 3D model repository. arXiv.csabs/1512.03012(2015) 4
work page internal anchor Pith review arXiv 2015
-
[19]
In: Proceedings of the International Conference on Computer Vision (ICCV) (2025) 11
Chen, W., Zhang, G., Wimbauer, F., Wang, R., Araslanov, N., Vedaldi, A., Cre- mers, D.: Back on track: Bundle adjustment for dynamic scene reconstruction. In: Proceedings of the International Conference on Computer Vision (ICCV) (2025) 11
2025
-
[20]
In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 6
Chen, Y., Zheng, C., Xu, H., Zhuang, B., Vedaldi, A., Cham, T.J., Cai, J.: MVS- plat360: Benchmarking 360 generalizable 3D novel view synthesis from sparse views. In: Proceedings of Advances in Neural Information Processing Systems (NeurIPS) (2024) 6
2024
-
[21]
4dnex: Feed-forward 4d generative modeling made easy.arXiv preprint arXiv:2508.13154, 2025
Chen, Z., Liu, T., Zhuo, L., Ren, J., Tao, Z., Zhu, H., Hong, F., Pan, L., Liu, Z.: 4dnex: Feed-forward 4d generative modeling made easy. arXiv preprint arXiv:2508.13154 (2025) 25
-
[22]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022) 5
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Yago Vicente, T.F., Dideriksen, T., Arora, H., Guillaumin, M., Malik, J.: Abo: Dataset and benchmarks for real-world 3d object understanding. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022) 5
2022
-
[23]
In: Proc
Dai, A., Chang, A.X., Savva, M., Halber, M., Funkhouser, T., Nießner, M.: ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In: Proc. CVPR (2017) 5, 12, 13
2017
-
[24]
Objaverse-xl: A universe of 10m+ 3d objects.arXiv preprint arXiv:2307.05663, 2023
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., VanderBilt, E., Kembhavi, A., Vondrick, C., Gkioxari, G., Ehsani, K., Schmidt, L., Farhadi, A.: Objaverse-XL: A universe of 10M+ 3D objects. CoRRabs/2307.05663(2023) 2, 4, 5
-
[25]
In: Proc
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3D objects. In: Proc. CVPR (2023) 2, 4, 5
2023
-
[26]
In: Proc
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Ehsani, K., Salvador, J., Han, W., Kolve, E., Kembhavi, A., Mottaghi, R.: ProcTHOR: large-scale embodied AI using procedural generation. In: Proc. NeurIPS (2022) 4
2022
-
[27]
Journal of Open Source Software8(82), 4901 (2023) 4
Denninger, M., Winkelbauer, D., Sundermeyer, M., Boerdijk, W., Knauer, M., Strobl, K.H., Humt, M., Triebel, R.: BlenderProc2: A procedural pipeline for photorealistic rendering. Journal of Open Source Software8(82), 4901 (2023) 4
2023
-
[28]
In: Conference on Robot Learning (2017) 5
Dosovitskiy, A., Ros, G., Codevilla, F., López, A.M., Koltun, V.: CARLA: an open urban driving simulator. In: Conference on Robot Learning (2017) 5
2017
-
[29]
In: Proc
Downs, L., Francis, A., Koenig, N., Kinman, B., Hickman, R., Reymann, K., McHugh, T.B., Vanhoucke, V.: Google Scanned Objects: A high-quality dataset of 3D scanned household items. In: Proc. ICRA (2022) 4, 5
2022
-
[30]
In: Proc
Fabbri,M.,Lanzi,F.,Calderara,S.,Palazzi,A.,Vezzani,R.,Cucchiara,R.:Learn- ing to detect and track visible and occluded body joints in a virtual world. In: Proc. ECCV (2018) 4
2018
-
[31]
In: Proc
Feng, H., Zhang, J., Wang, Q., Ye, Y., Yu, P., Black, M.J., Darrell, T., Kanazawa, A.: St4RTrack: simultaneous 4D reconstruction and tracking in the world. In: Proc. ICCV (2025) 6 Abbreviated paper title 17
2025
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fieraru, M., Zanfir, M., Oneata, E., Popa, A.I., Olaru, V., Sminchisescu, C.: Three-dimensional reconstruction of human interactions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7214– 7223 (2020) 14, 26
2020
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Fu, H., Cai, B., Gao, L., Zhang, L.X., Wang, J., Li, C., Zeng, Q., Sun, C., Jia, R., Zhao, B., et al.: 3d-front: 3d furnished rooms with layouts and semantics. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10933–10942 (2021) 4
2021
-
[34]
In: Proc
Gaidon, A., Wang, Q., Cabon, Y., Vig, E.: Virtual KITTI. In: Proc. CVPR (2016) 4
2016
-
[35]
International Journal of Robotics Research (IJRR) (2013) 5, 13
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The KITTI dataset. International Journal of Robotics Research (IJRR) (2013) 5, 13
2013
-
[36]
arXiv.cs abs/2305.20091(2023) 6
Goel, S., Pavlakos, G., Rajasegaran, J., Kanazawa, A., Malik, J.: Humans in 4D: Reconstructing and tracking humans with transformers. arXiv.cs abs/2305.20091(2023) 6
-
[37]
In: Proc
Greff, K., Belletti, F., Beyer, L., Doersch, C., Du, Y., Duckworth, D., Fleet, D.J., Gnanapragasam, D., Golemo, F., Herrmann, C., Kipf, T., Kundu, A., Lagun, D., Laradji, I., Liu, H.T.D., Meyer, H., Miao, Y., Nowrouzezahrai, D., Oztireli, C., Pot, E., Radwan, N., Rebain, D., Sabour, S., Sajjadi, M.S.M., Sela, M., Sitz- mann, V., Stone, A., Sun, D., Vora, ...
2022
-
[38]
In: IEEE Intl
Handa, A., Whelan, T., McDonald, J., Davison, A.: A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In: IEEE Intl. Conf. on Robotics and Automation, ICRA. Hong Kong, China (May 2014) 5
2014
-
[39]
In: International Conference on Computer Vision (ICCV)
Hassan, M., Choutas, V., Tzionas, D., Black, M.J.: Resolving 3D human pose ambiguities with 3D scene constraints. In: International Conference on Computer Vision (ICCV). pp. 2282–2292 (2019) 6
2019
-
[40]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: Enabling camera control for text-to-video generation (2024) 6
2024
-
[41]
In: Proc
Hu, W., Gao, X., Li, X., Zhao, S., Cun, X., Zhang, Y., Quan, L., Shan, Y.: DepthCrafter: generating consistent long depth sequences for open-world videos. In: Proc. CVPR (2025) 6
2025
-
[42]
In: Proc
Huang, P.H., Matzen, K., Kopf, J., Ahuja, N., Huang, J.B.: DeepMVS: Learning multi-view stereopsis. In: Proc. CVPR (2018) 26
2018
-
[43]
Hunyuan3D, T., Yang, S., Yang, M., Feng, Y., Huang, X., Zhang, S., He, Z., Luo, D., Liu, H., Zhao, Y., Lin, Q., Lai, Z., Yang, X., Shi, H., Zhao, Z., Zhang, B., Yan, H., Wang, L., Liu, S., Zhang, J., Chen, M., Dong, L., Jia, Y., Cai, Y., Yu, J., Tang, Y., Guo, D., Yu, J., Zhang, H., Ye, Z., He, P., Wu, R., Wei, S., Zhang, C., Tan, Y., Sun, Y., Niu, L., Hu...
-
[44]
arXiv (2019) 5
Hurl, B., Czarnecki, K., Waslander, S.: Precise synthetic image and LiDAR (Pre- SIL) dataset for autonomous vehicle perception. arXiv (2019) 5
2019
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jiang, W., Kolotouros, N., Pavlakos, G., Zhou, X., Daniilidis, K.: Coherent re- construction of multiple humans from a single image. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5579– 5588 (2020) 6 18 Authors Suppressed Due to Excessive Length
2020
-
[46]
In: Proceedings of the Interna- tional Conference on Computer Vision (ICCV) (2025) 6
Jiang, Z., Zheng, C., Laina, I., Larlus, D., Vedaldi, A.: Geo4D: Leveraging video generators for geometric 4D scene reconstruction. In: Proceedings of the Interna- tional Conference on Computer Vision (ICCV) (2025) 6
2025
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026) 4
Jiang, Z., Zheng, C., Laina, I., Larlus, D., Vedaldi, A.: Mesh4d: 4d mesh recon- struction and tracking from monocular video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2026) 4
2026
-
[48]
In: Proc
Jiang, Z., Zheng, C., Laina, I., Larlus, D., Vedaldi, A.: Mesh4d: 4d mesh recon- struction and tracking from monocular video. In: Proc. CVPR (2026) 6
2026
-
[49]
Jin, L., Tucker, R., Li, Z., Fouhey, D., Snavely, N., Holynski, A.: Stereo4D: Learn- ing how things move in 3D from internet stereo videos. arXiv2412.09621(2024) 2, 6
-
[50]
In: The IEEE International Conference on Computer Vision (ICCV) (2015) 5
Joo, H., Liu, H., Tan, L., Gui, L., Nabbe, B., Matthews, I., Kanade, T., Nobuhara, S., Sheikh, Y.: Panoptic studio: A massively multiview system for social motion capture. In: The IEEE International Conference on Computer Vision (ICCV) (2015) 5
2015
-
[51]
IEEE Transactions on Pattern Analysis and Machine Intelligence41(1), 190–204 (2019) 12, 13
Joo, H., Simon, T., Li, X., Liu, H., Tan, L., Gui, L., Banerjee, S., Godisart, T., Nabbe, B., Matthews, I., Kanade, T., Nobuhara, S., Sheikh, Y.: Panoptic studio: A massively multiview system for social interaction capture. IEEE Transactions on Pattern Analysis and Machine Intelligence41(1), 190–204 (2019) 12, 13
2019
-
[52]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2017) 5
Joo, H., Simon, T., Li, X., Liu, H., Tan, L., Gui, L., Banerjee, S., Godisart, T.S., Nabbe, B., Matthews, I., Kanade, T., Nobuhara, S., Sheikh, Y.: Panoptic studio: A massively multiview system for social interaction capture. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2017) 5
2017
-
[53]
In: Proc
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of hu- man shape and pose. In: Proc. CVPR (2018) 6
2018
-
[54]
In: Proceedings of the European Conference on Computer Vision (ECCV) (2024) 2
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Co- Tracker: It is better to track together. In: Proceedings of the European Conference on Computer Vision (ECCV) (2024) 2
2024
-
[55]
CVPR (2023) 4, 5, 26
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: Dynamicstereo: Consistent dynamic depth from stereo videos. CVPR (2023) 4, 5, 26
2023
-
[56]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023) 5
Karaev, N., Rocco, I., Graham, B., Neverova, N., Vedaldi, A., Rupprecht, C.: DynamicStereo: Consistent dynamic depth from stereo videos. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023) 5
2023
-
[57]
Karhade,J.,Keetha,N.,Zhang,Y.,Gupta,T.,Sharma,A.,Scherer,S.,Ramanan, D.: Any4D: Unified feed-forward metric 4D reconstruction (2025), arXiv preprint 6
2025
-
[58]
In: Proc
Kästingschäfer, M., Gieruc, T., Bernhard, S., Campbell, D., Insafutdinov, E., Brox, T.: SEED4D: a synthetic ego–exo dynamic 4D data generator, driving dataset and benchmark. In: Proc. WACV (2025) 4, 5
2025
-
[59]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., Luiten, J., Lopez-Antequera, M., Bulò, S.R., Richardt, C., Ramanan, D., Scherer, S., Kontschieder, P.: Ma- pAnything: universal feed-forward metric 3D reconstruction. arXiv2509.13414 (2025) 2, 6
work page internal anchor Pith review arXiv 2025
-
[60]
In: ICCV (2019) 6
Kolotouros, N., Pavlakos, G., Black, M.J., Daniilidis, K.: Learning to reconstruct 3D human pose and shape via model-fitting in the loop. In: ICCV (2019) 6
2019
-
[61]
arXiv (2017) 4 Abbreviated paper title 19
Kolve, E., Mottaghi, R., Han, W., VanderBilt, E., Weihs, L., Herrasti, A., Deitke, M., Ehsani, K., Gordon, D., Zhu, Y., Kembhavi, A., Gupta, A., Farhadi, A.: AI2-THOR: An interactive 3D environment for visual ai. arXiv (2017) 4 Abbreviated paper title 19
2017
-
[62]
In: NeurIPS (2024) 13
Koppula, S., Rocco, I., Yang, Y., Heyward, J., Carreira, J., Zisserman, A., Bros- tow, G., Doersch, C.: Tapvid-3d: A benchmark for tracking any point in 3d. In: NeurIPS (2024) 13
2024
-
[63]
In: ICLR (2026) 13
Lan, Y., Luo, Y., Hong, F., Zhou, S., Chen, H., Lyu, Z., Yang, S., Dai, B., Loy, C.C., Pan, X.: STream3R: Scalable sequential 3D reconstruction with causal transformer. In: ICLR (2026) 13
2026
-
[64]
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)45(3), 3292–3310 (2022) 5
Liao, Y., Xie, J., Geiger, A.: Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)45(3), 3292–3310 (2022) 5
2022
-
[65]
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything3:Recoveringthevisualspacefromanyviews.arXiv2511.10647(2025) 2, 6, 29
work page internal anchor Pith review arXiv 2025
-
[66]
In: Proc
Ling, L., Sheng, Y., Tu, Z., Zhao, W., Xin, C., Wan, K., Yu, L., Guo, Q., Yu, Z., Lu, Y., Li, X., Sun, X., Ashok, R., Mukherjee, A., Kang, H., Kong, X., Hua, G., Zhang, T., Benes, B., Bera, A.: DL3DV-10K: a large-scale scene dataset for deep learning-based 3d vision. In: Proc. CVPR (2024) 26
2024
-
[67]
In: Proc
Liu, R., Wu, R., Hoorick, B.V., Tokmakov, P., Zakharov, S., Vondrick, C.: Zero- 1-to-3: Zero-shot one image to 3D object. In: Proc. ICCV (2023) 4, 6
2023
-
[68]
In: Proc
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and transfer data with rectified flow. In: Proc. ICLR (2023) 25
2023
-
[69]
ACM Trans
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: SMPL: A skinned multi-person linear model. ACM Trans. Graphics (Proc. SIGGRAPH Asia)34(6), 248:1–248:16 (Oct 2015) 6, 13
2015
-
[70]
4RC: 4D Reconstruction via Conditional Querying Anytime and Anywhere
Luo, Y., Zhou, S., Lan, Y., Pan, X., Loy, C.C.: 4RC: 4D reconstruction via con- ditional querying anytime and anywhere. arXiv preprint arXiv:2602.10094 (2026) 6, 12, 13, 26, 27, 28
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[71]
In: European Conference on Computer Vision (ECCV) (sep 2018) 5
von Marcard, T., Henschel, R., Black, M., Rosenhahn, B., Pons-Moll, G.: Recov- ering accurate 3d human pose in the wild using imus and a moving camera. In: European Conference on Computer Vision (ECCV) (sep 2018) 5
2018
-
[72]
In: Proc
Mayer, N., Ilg, E., Häusser, P., Fischer, P., Cremers, D., Dosovitskiy, A., Brox, T.: A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In: Proc. CVPR (2016) 4
2016
-
[73]
ICCV (2017) 4, 5
McCormac, J., Handa, A., Leutenegger, S., Davison, A.J.: SceneNet RGB-D: can 5M synthetic images beat generic ImageNet pre-training on indoor segmentation? In: Proc. ICCV (2017) 4, 5
2017
-
[74]
In: Proc
Mehl, L., Schmalfuss, J., Jahedi, A., Nalivayko, Y., Bruhn, A.: Spring: A high- resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In: Proc. CVPR (2023) 4
2023
-
[75]
arXiv (2019) 13
Palazzolo, E., Behley, J., Lottes, P., Giguère, P., Stachniss, C.: ReFusion: 3D Reconstruction in Dynamic Environments for RGB-D Cameras Exploiting Resid- uals. arXiv (2019) 13
2019
-
[76]
In: ICCV (2023) 12, 13
Pan, X., Charron, N., Yang, Y., Peters, S., Whelan, T., Kong, C., Parkhi, O., Newcombe, R., Ren, C.Y.: Aria digital twin: A new benchmark dataset for ego- centric 3D machine perception. In: ICCV (2023) 12, 13
2023
-
[77]
In: 2025 International Conference on 3D Vision (3DV)
Patel, P., Black, M.J.: Camerahmr: Aligning people with perspective. In: 2025 International Conference on 3D Vision (3DV). pp. 1562–1571. IEEE (2025) 6
2025
-
[78]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Patel, P., Huang, C.H.P., Tesch, J., Hoffmann, D.T., Tripathi, S., Black, M.J.: Agora: Avatars in geography optimized for regression analysis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 13468–13478 (2021) 6, 14 20 Authors Suppressed Due to Excessive Length
2021
-
[79]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10975–10985 (2019) 6, 13
2019
-
[80]
In: International conference on machine learning (ICML)
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning (ICML). pp. 8748–8763. PmLR (2021) 11
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.