Recognition: unknown
Sparse Prefix Caching for Hybrid and Recurrent LLM Serving
Pith reviewed 2026-05-10 08:46 UTC · model grok-4.3
The pith
Sparse prefix caching via dynamic programming for optimal checkpoint placement under overlap distributions improves the Pareto frontier for recurrent and hybrid LLM serving on shared-prefix data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
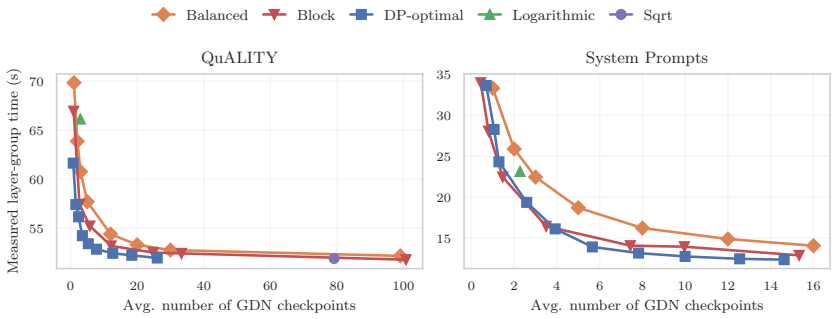
distribution-aware placement dominates every fixed-budget baseline on the measured layer-group Pareto frontier and matches or outperforms the strongest heuristic (block caching) while typically using substantially fewer checkpoints, with the largest gains at low checkpoint budgets where the overlap distribution is most non-uniform.
Load-bearing premise
Requests share a non-trivial prefix (e.g., asking different questions about a single long document) and that the distribution over overlap depths is known or estimable in advance; also that recurrent states can be extracted and restored exactly without changing the computation.
Figures




read the original abstract
Prefix caching is a key latency optimization for autoregressive LLM serving, yet existing systems assume dense per-token key/value reuse. State-space models change the structure of the problem: a recurrent layer can resume from a single stored state rather than requiring the entire token history. This asymmetry opens a new design point between no reuse and dense caching: store exact recurrent states at a sparse set of checkpoint positions and, on a cache hit, resume from the deepest stored checkpoint and recompute the remaining suffix exactly. We formalize sparse prefix caching as checkpoint placement under a distribution over overlap depths, yielding an exact O(NM) dynamic program. For use cases where requests share a non-trivial prefix (e.g. asking different questions about a single long document), we show that our method consistently improves the Pareto frontier traced by standard heuristics on real-world data. Across QuALITY and System Prompts, distribution-aware placement dominates every fixed-budget baseline on the measured layer-group Pareto frontier and matches or outperforms the strongest heuristic (block caching) while typically using substantially fewer checkpoints, with the largest gains at low checkpoint budgets where the overlap distribution is most non-uniform. The method is most relevant when many requests share a substantial but not identical prefix within a retained cache entry. It preserves exact outputs, does not change the recurrent computation itself or require new recurrent update kernels, applies to recurrent/SSM layers whose hidden state can be extracted and restored exactly, and for hybrid models can be combined with existing KV-cache compression techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes sparse prefix caching for hybrid and recurrent LLM serving. It formalizes checkpoint placement under a distribution over prefix overlap depths as an exact O(NM) dynamic program. On QuALITY and System Prompts, distribution-aware placement is shown to dominate fixed-budget baselines on the layer-group Pareto frontier, match or exceed block caching while using fewer checkpoints, and yield largest gains at low budgets where the overlap distribution is most non-uniform. The method preserves exact outputs, requires no new kernels, and applies to recurrent/SSM layers with extractable states; it can be combined with KV-cache compression.
Significance. If the DP is correct and the empirical results hold under the stated assumptions, the work provides a principled, distribution-aware alternative to heuristic caching for recurrent and hybrid models. It exploits the asymmetry that a single recurrent state suffices for resumption rather than full token history, achieving better memory-latency trade-offs in shared-prefix workloads while remaining exact. The explicit Pareto dominance over strong baselines on real data, combined with the O(NM) exact solver, strengthens the case for adoption in serving systems.
major comments (2)
- [§3] §3, DP recurrence: the manuscript claims an exact O(NM) solution, but the cost function definition (how the overlap-depth distribution enters the expected recomputation cost) is not shown to be independent of any fitted parameters; if the distribution must be estimated from data, the optimality guarantee becomes conditional on estimation quality.
- [§4.2] §4.2, Pareto frontier results: the claim that distribution-aware placement 'dominates every fixed-budget baseline' is load-bearing, yet the reported curves do not include error bars or sensitivity to distribution mismatch; without this, it is unclear whether the observed gains remain statistically significant when the overlap distribution is estimated rather than known exactly.
minor comments (3)
- [Figure 2] Figure 2: axis labels and legend for the layer-group Pareto plots are too small; enlarge and clarify which recurrent layers belong to each group.
- [§5] §5: the limitations paragraph should explicitly list the assumption that recurrent states can be extracted and restored without numerical drift or kernel changes.
- [Related Work] Related work: the citation to prior KV-cache compression techniques is present but the discussion of how sparse prefix caching composes with them is only one sentence; expand to a short paragraph.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and recommendation for minor revision. We address each major comment below with clarifications and proposed manuscript updates.
read point-by-point responses
-
Referee: [§3] §3, DP recurrence: the manuscript claims an exact O(NM) solution, but the cost function definition (how the overlap-depth distribution enters the expected recomputation cost) is not shown to be independent of any fitted parameters; if the distribution must be estimated from data, the optimality guarantee becomes conditional on estimation quality.
Authors: The dynamic program yields an exact optimum for any fixed input distribution p over overlap depths. The expected recomputation cost is formed by weighting the per-depth recomputation cost by p(d) and the recurrence follows directly from this expectation; no auxiliary fitted parameters appear in the DP. In the experiments we compute p(d) as the empirical frequency over the QuALITY and System Prompts evaluation sets, so the reported solutions are optimal for those exact distributions. In deployment p(d) would be estimated from historical logs, rendering the guarantee conditional on estimation accuracy. We will revise §3 to state explicitly how p enters the cost and to note the conditional optimality when p is estimated. revision: partial
-
Referee: [§4.2] §4.2, Pareto frontier results: the claim that distribution-aware placement 'dominates every fixed-budget baseline' is load-bearing, yet the reported curves do not include error bars or sensitivity to distribution mismatch; without this, it is unclear whether the observed gains remain statistically significant when the overlap distribution is estimated rather than known exactly.
Authors: The Pareto curves are deterministic given the empirical p(d) extracted from each dataset, so no stochastic error bars apply to the placement itself. Dominance holds exactly under these measured distributions and is consistent across both QuALITY and System Prompts. We agree that sensitivity to mismatch between the estimated and true p is not shown. We will revise §4.2 to state the assumption of an accurate distribution estimate and add a brief discussion of robustness under small perturbations of p(d), thereby clarifying the scope of the dominance claim. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives an exact O(NM) dynamic program for checkpoint placement directly from a given overlap-depth distribution, treating the distribution as an external input that is either known or estimated separately from data. This formulation is self-contained and does not reduce any claimed optimality or prediction back to fitted parameters, self-definitions, or prior self-citations by construction. Empirical Pareto comparisons on QuALITY and System Prompts are performed against independent baselines (fixed-budget and block caching) using the DP outputs, with the method explicitly preserving exact recurrent computation and outputs. No load-bearing step collapses to renaming, ansatz smuggling, or uniqueness imported from the authors' prior work; the central result follows from standard DP optimality applied to the stated inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Recurrent/SSM layers allow exact extraction and restoration of hidden states without approximation or kernel changes
- domain assumption A distribution over prefix overlap depths is known or can be estimated from data
Reference graph
Works this paper leans on
-
[1]
Klawe, Shlomo Moran, Peter Shor, and Robert Wilber
Alok Aggarwal, Maria M. Klawe, Shlomo Moran, Peter Shor, and Robert Wilber. Geometric applications of a matrix-searching algorithm.Algorithmica, 2:195–208, 1987
1987
-
[2]
Onthecomplexityoflearningfromdriftingdistributions
RakeshD.BarveandPhilipM.Long. Onthecomplexityoflearningfromdriftingdistributions. Information and Computation, 138(2):170–193, 1997
1997
-
[3]
On the convergence of the empirical distribution
Daniel Berend and Aryeh Kontorovich. On the convergence of the empirical distribution. arXiv preprint arXiv:1205.6711, 2012
-
[4]
PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Baobao Chang, Junjie Hu, and Wen Xiao. PyramidKV: Dynamic KV cache compression based on pyramidal information funneling.arXiv preprint arXiv:2406.02069, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost, 2016. URLhttps://arxiv.org/abs/1604.06174
work page internal anchor Pith review arXiv 2016
-
[6]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness.Advances in Neural Information Processing Systems (NeurIPS), 35, 2022. 11
2022
-
[8]
Springer, 2001
Luc Devroye and Gábor Lugosi.Combinatorial Methods in Density Estimation. Springer, 2001
2001
-
[9]
Yao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Challenges in deploying long-context transformers: A theoretical peak performance analysis.arXiv preprint arXiv:2405.08944, 2024
-
[10]
L. K. Grover. A new algorithm for thek-median problem.Information Processing Letters, 57(3):151–155, 1996
1996
-
[11]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page Pith review arXiv 2023
-
[12]
Improved complexity bounds for location problems on the real line.Operations Research Letters, 10(7):395–402, 1991
Refael Hassin and Arie Tamir. Improved complexity bounds for location problems on the real line.Operations Research Letters, 10(7):395–402, 1991
1991
-
[13]
The NarrativeQA reading comprehension challenge
Tomáš Kočiský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. The NarrativeQA reading comprehension challenge. Transactions of the Association for Computational Linguistics, 6:317–328, 2018
2018
-
[14]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention.arXiv preprint arXiv:2309.06180, 2023
work page internal anchor Pith review arXiv 2023
-
[15]
xFormers: A modular and hackable transformer modelling library.https://github
Benjamin Lefaudeux, Francisco Massa, Diana Liskovich, Wenhan Xiong, Vittorio Caggiano, Sean Nber, Tian Xu, Jieru Hu, Marta Tintore, Susan Ho, Patrick Labatut, and Daniel Haziza. xFormers: A modular and hackable transformer modelling library.https://github. com/facebookresearch/xformers, 2022
2022
-
[16]
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review arXiv 2024
-
[17]
arXiv preprint arXiv:2305.17118 , year =
Zichang Liu, Aashiq Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anas- tasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time.arXiv preprint arXiv:2305.17118, 2024
-
[18]
Nonparametric density estimation under distribution drift
Alessio Mazzetto and Eli Upfal. Nonparametric density estimation under distribution drift. InInternational Conference on Machine Learning (ICML), pages 24251–24270, 2023
2023
-
[19]
On the method of bounded differences
Colin McDiarmid. On the method of bounded differences. In J. Siemons, editor,Surveys in Combinatorics, volume 141 ofLondon Mathematical Society Lecture Note Series, pages 148–188. Cambridge University Press, 1989
1989
-
[20]
Nimrod Megiddo and Kenneth J. Supowit. The complexity of some common geometric location problems.Journal of Algorithms, 5(4):544–554, 1984
1984
-
[21]
New analysis and algorithm for learning with drifting distributions
Mehryar Mohri and Andrés Muñoz Medina. New analysis and algorithm for learning with drifting distributions. InAlgorithmic Learning Theory (ALT), pages 124–138, 2012
2012
- [22]
-
[23]
Marconi: Prefix caching for the era of hybrid llms, 2025
Rui Pan, Zhuang Wang, Zhen Jia, Can Karakus, Luca Zancato, Tri Dao, Yida Wang, and Ravi Netravali. Marconi: Prefix caching for the era of hybrid LLMs.arXiv preprint arXiv:2411.19379, 2024
-
[24]
Richard Yuanzhe Pang, Alicia Parrish, Nitish Joshi, Nikita Nangia, Jason Phang, Angelica Chen, Vishakh Padmakumar, Johnny Ma, Jana Thompson, He He, and Samuel R. Bowman. QuALITY: Question answering with long input texts, yes!Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 533...
2022
-
[25]
Splitwise: Efficient generative llm inference using phase splitting,
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative LLM inference using phase splitting. arXiv preprint arXiv:2311.18677, 2024
-
[26]
RWKV: Reinventing RNNs for the Transformer Era
Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grber, et al. RWKV: Reinventing RNNs for the transformer era.arXiv preprint arXiv:2305.13048, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Qwen3.5 technical report.https://qwen.ai/blog?id=qwen3.5, 2025
Qwen Team. Qwen3.5 technical report.https://qwen.ai/blog?id=qwen3.5, 2025
2025
-
[28]
ShareGPT.https://sharegpt.com, 2023
ShareGPT Community. ShareGPT.https://sharegpt.com, 2023
2023
-
[29]
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. Preble: Efficient distributed prompt scheduling for LLM serving.arXiv preprint arXiv:2407.00023, 2024
-
[30]
System prompts leaks
Ásgeir Thorsteinsson. System prompts leaks. https://github.com/asgeirtj/system_ prompts_leaks, 2024
2024
-
[31]
Pyramid- infer: Pyramid kv cache compression for high-throughput llm inference
Dongjie Yang, XiaoDong Han, Yan Gao, Yao Hu, Shilin Zhang, and Hai Zhao. Pyramid- Infer: Pyramid KV cache compression for high-throughput LLM inference.arXiv preprint arXiv:2405.12532, 2024
-
[32]
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2024
work page internal anchor Pith review arXiv 2024
-
[33]
flash-linear-attention
Songlin Yang et al. flash-linear-attention. https://github.com/fla-org/ flash-linear-attention, 2024
2024
-
[34]
CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. Cacheblend: Fast large language model serving for RAG with cached knowledge fusion.arXiv preprint arXiv:2405.16444, 2024
-
[35]
Chunkattention: Efficient self-attention with prefix-aware kv cache and two-phase partition
Lu Ye, Ze Liang, Yong Guan, Zhen Jia, and Lingfei Li. ChunkAttention: Efficient self-attention with prefix-aware KV cache and two-phase partition.arXiv preprint arXiv:2402.15220, 2024
-
[36]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models.Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI), pages 521–538, 2022. 13
2022
-
[37]
arXiv preprint arXiv:2306.14048 , year=
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, Zhangyang Wang, and Beidi Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models.arXiv preprint arXiv:2306.14048, 2024
-
[38]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs.arXiv preprint arXiv:2312.07104, 2023. 14 A Proofs All theorem and lemma statements in this appendix appear in the ...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.