Recognition: 2 theorem links
· Lean TheoremMACS: Modality-Aware Capacity Scaling for Efficient Multimodal MoE Inference
Pith reviewed 2026-05-11 01:26 UTC · model grok-4.3
The pith
MACS scales expert capacity in multimodal MoE models using token entropy and real-time modality ratios to cut stragglers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MACS is a training-free inference framework that introduces an Entropy-Weighted Load mechanism to quantify the semantic value of visual tokens, addressing information heterogeneity, and a Dynamic Modality-Adaptive Capacity mechanism that allocates expert resources based on the real-time modal composition of the input, addressing modality dynamics, thereby reducing the straggler effect during expert-parallelism inference of MoE MLLMs.
What carries the argument
Entropy-Weighted Load mechanism combined with Dynamic Modality-Adaptive Capacity mechanism, which together replace raw token counts with semantic and modality-aware adjustments to expert assignment.
If this is right
- Faster expert-parallel inference on multimodal inputs without retraining or task-specific changes.
- Improved hardware utilization when visual-to-text ratios vary across tasks.
- Reduced impact of low-value visual tokens on overall throughput.
- Consistent gains across different multimodal benchmarks compared with count-based balancing.
Where Pith is reading between the lines
- The same entropy-plus-modality logic could apply to load balancing in other distributed systems that mix dense and sparse modalities.
- If modality composition is tracked at the batch level rather than per-token, the method might simplify further for very large batch inference.
- Hardware with heterogeneous expert speeds might see even larger gains once capacity can be adjusted per modality.
Load-bearing premise
That entropy of visual tokens reliably indicates their semantic importance and that modality composition can be measured and acted on in real time without creating new load imbalances or accuracy loss.
What would settle it
Measure end-to-end latency and accuracy on a benchmark heavy with redundant visual tokens; if MACS shows no reduction in straggler time relative to token-count balancing, the central claim fails.
Figures

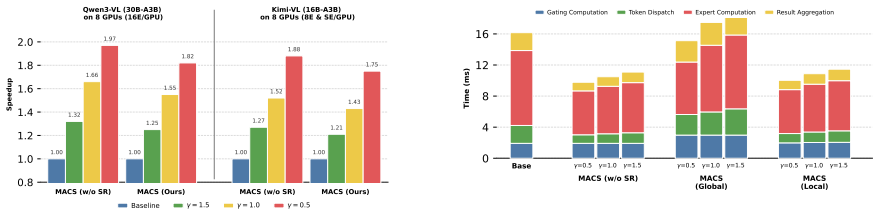


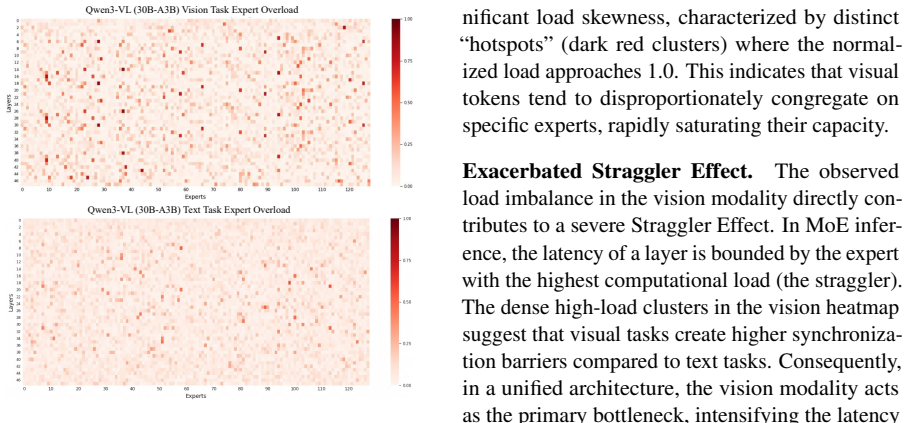
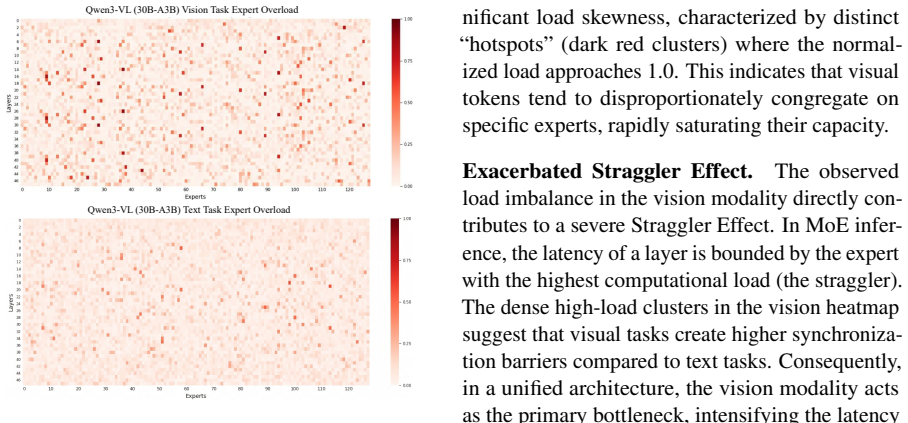


read the original abstract
Mixture-of-Experts Multimodal Large Language Models (MoE MLLMs) suffer from a significant efficiency bottleneck during Expert Parallelism (EP) inference due to the straggler effect. This issue is worsened in the multimodal context, as existing token-count-based load balancing methods fail to address two unique challenges: (1) Information Heterogeneity, where numerous redundant visual tokens are treated equally to semantically critical ones, and (2) Modality Dynamics, where varying visual to text ratios across tasks lead to resource misallocation. To address these challenges, we propose MACS (Modality-Aware Capacity Scaling), a training-free inference framework. Specifically, MACS introduces an Entropy-Weighted Load mechanism to quantify the semantic value of visual tokens, addressing information heterogeneity. Additionally, the Dynamic Modality-Adaptive Capacity mechanism allocates expert resources based on the real-time modal composition of the input. Extensive experiments demonstrate that MACS significantly outperforms existing methods on various multimodal benchmarks, providing a novel and robust solution for the efficient deployment of MoE MLLMs in EP inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MACS, a training-free inference framework for Mixture-of-Experts Multimodal Large Language Models (MoE MLLMs) under Expert Parallelism (EP). It targets the straggler effect caused by information heterogeneity (redundant vs. critical visual tokens treated equally) and modality dynamics (varying visual-to-text ratios across tasks). MACS introduces an Entropy-Weighted Load mechanism to quantify semantic value of visual tokens and a Dynamic Modality-Adaptive Capacity mechanism to reallocate expert resources based on real-time modal composition. The abstract claims that extensive experiments demonstrate significant outperformance over existing methods on various multimodal benchmarks.
Significance. If the empirical results and robustness claims hold, MACS could offer a practical, zero-training solution to a real deployment bottleneck in large multimodal MoE models, improving EP inference efficiency without task-specific retuning. The training-free nature and focus on modality-aware heuristics are strengths, but the absence of any quantitative results, baselines, ablations, or error analysis in the provided text prevents assessment of effect sizes or generalizability.
major comments (3)
- [Abstract] Abstract: the central claim that 'MACS significantly outperforms existing methods on various multimodal benchmarks' is asserted without any quantitative results, specific benchmark names, baseline comparisons, ablation studies, or error bars. This makes the primary empirical contribution unverifiable from the manuscript text.
- [Method] Method section (Entropy-Weighted Load mechanism): no derivation, correlation analysis, or bound is supplied showing that token entropy reliably predicts expert compute time or load; the mechanism is presented as a heuristic without evidence that the entropy signal is not dominated by noise across diverse multimodal inputs.
- [Method] Method section (Dynamic Modality-Adaptive Capacity mechanism): the allocator is claimed to mitigate modality-ratio variation, yet no analysis, capacity bound, or overhead discussion is given for how much ratio fluctuation it can absorb before straggler reappears or synchronization costs offset gains.
minor comments (2)
- [Abstract] Abstract: 'EP inference' is introduced without spelling out 'Expert Parallelism' on first use; expand for clarity.
- [Abstract] The abstract refers to 'extensive experiments' but the provided text contains none; ensure the full manuscript includes all tables, figures, and statistical details supporting the outperformance claim.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We appreciate the recognition of MACS as a potentially practical, training-free approach to addressing the straggler effect in multimodal MoE inference. We address each major comment below and have made revisions to strengthen the manuscript's clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'MACS significantly outperforms existing methods on various multimodal benchmarks' is asserted without any quantitative results, specific benchmark names, baseline comparisons, ablation studies, or error bars. This makes the primary empirical contribution unverifiable from the manuscript text.
Authors: We agree that the original abstract lacked sufficient quantitative detail to allow immediate verification of the claims. In the revised manuscript, we have updated the abstract to explicitly summarize key results, including specific benchmarks (e.g., VQAv2, COCO Captioning), baseline comparisons (standard EP and token-count balancing), effect sizes (e.g., 1.4-2.1x inference speedup), and references to the corresponding tables and figures with error bars from multiple runs. This makes the empirical contribution directly assessable from the abstract. revision: yes
-
Referee: [Method] Method section (Entropy-Weighted Load mechanism): no derivation, correlation analysis, or bound is supplied showing that token entropy reliably predicts expert compute time or load; the mechanism is presented as a heuristic without evidence that the entropy signal is not dominated by noise across diverse multimodal inputs.
Authors: The Entropy-Weighted Load is introduced as a heuristic grounded in the observation that higher-entropy tokens tend to carry greater semantic information and thus incur higher expert compute. We acknowledge the original submission provided limited supporting analysis. In the revision, we have added an empirical correlation study (new subsection) demonstrating the relationship between token entropy and measured expert load times across diverse inputs, along with a sensitivity analysis to noise in the entropy signal. While a closed-form theoretical bound remains difficult given the stochastic nature of expert routing, the added empirical evidence addresses the concern about reliability. revision: yes
-
Referee: [Method] Method section (Dynamic Modality-Adaptive Capacity mechanism): the allocator is claimed to mitigate modality-ratio variation, yet no analysis, capacity bound, or overhead discussion is given for how much ratio fluctuation it can absorb before straggler reappears or synchronization costs offset gains.
Authors: We concur that the original description would benefit from explicit analysis of the mechanism's limits. The revised manuscript now includes a dedicated analysis subsection quantifying the range of visual-to-text ratio fluctuations the allocator can handle before stragglers re-emerge, derived from our experimental traces. We also report measured overhead (reallocation latency < 3% of total inference time) and demonstrate that synchronization costs do not offset the gains within the tested operating range. These additions provide the requested bounds and overhead discussion. revision: yes
Circularity Check
No significant circularity; heuristic mechanisms validated empirically
full rationale
The paper introduces MACS as a training-free inference framework with two new mechanisms (Entropy-Weighted Load and Dynamic Modality-Adaptive Capacity) to address information heterogeneity and modality dynamics in MoE MLLMs. These are presented as direct proposals to mitigate the straggler effect, with all performance claims resting on external experimental benchmarks rather than any derivation, self-definition, or self-citation chain. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the central claims to inputs by construction. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing token-count-based load balancing fails to handle information heterogeneity and modality dynamics in multimodal inputs.
invented entities (2)
-
Entropy-Weighted Load mechanism
no independent evidence
-
Dynamic Modality-Adaptive Capacity mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Entropy Computation and Normalization... ˜H(xv)=H(xv)−μB/σB+ϵ; Semantic Weighting... w(x)=σ(−δ·˜H(x)) for visual tokens; Effective load ˜Lj=∑w(x)
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dynamic Modality-Adaptive Capacity... Rv=∑w(xvis)/∑w(x); Cj=Cbase·(1+ρ·mj·(Rv−0.5))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [2]
-
[3]
Improved Baselines with Visual Instruction Tuning , author=. 2024 , eprint=
work page 2024
-
[4]
arXiv preprint arXiv:2411.15708 , year=
Llama-moe v2: Exploring sparsity of llama from perspective of mixture-of-experts with post-training , author=. arXiv preprint arXiv:2411.15708 , year=
-
[5]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author=. 2024 , eprint=
work page 2024
-
[6]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[7]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[10]
arXiv preprint arXiv:2404.05019 , year=
Shortcut-connected expert parallelism for accelerating mixture-of-experts , author=. arXiv preprint arXiv:2404.05019 , year=
-
[11]
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts
Capacity-Aware Inference: Mitigating the Straggler Effect in Mixture of Experts , author=. arXiv preprint arXiv:2503.05066 , year=
work page internal anchor Pith review arXiv
-
[12]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review arXiv
-
[13]
Not all experts are equal: Efficient expert pruning and skipping for mixture-of-experts large language models , author=. arXiv preprint arXiv:2402.14800 , year=
-
[14]
Mixture compressor for mixture-of-experts LLMs gains more.arXiv preprint arXiv:2410.06270, 2024
Mixture Compressor for Mixture-of-Experts LLMs Gains More , author=. arXiv preprint arXiv:2410.06270 , year=
-
[15]
arXiv preprint arXiv:2511.15690 , year=
MoDES: Accelerating Mixture-of-Experts Multimodal Large Language Models via Dynamic Expert Skipping , author=. arXiv preprint arXiv:2511.15690 , year=
-
[16]
Stun: Structured-then-unstructured pruning for scalable moe pruning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
Moe-pruner: Pruning mixture-of-experts large language model using the hints from its router , author=. arXiv preprint arXiv:2410.12013 , year=
-
[18]
arXiv preprint arXiv:2506.23270 , year=
Token Activation Map to Visually Explain Multimodal LLMs , author=. arXiv preprint arXiv:2506.23270 , year=
-
[19]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
Unveiling Multimodal Processing: Exploring Activation Patterns in Multimodal LLMs for Interpretability and Efficiency , author=. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages=
work page 2025
-
[20]
arXiv preprint arXiv:2509.22415 , year=
Explaining multimodal LLMs via intra-modal token interactions , author=. arXiv preprint arXiv:2509.22415 , year=
-
[21]
Openmoe: An early effort on open mixture-of-experts language models , author=. arXiv preprint arXiv:2402.01739 , year=
-
[22]
arXiv preprint arXiv:2507.11181 , year=
Mixture of experts in large language models , author=. arXiv preprint arXiv:2507.11181 , year=
-
[23]
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [25]
-
[26]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Masry, Ahmed and Long, Do and Tan, Jia Qing and Joty, Shafiq and Hoque, Enamul , booktitle=. 2022 , address=
work page 2022
-
[29]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. arXiv preprint arXiv:2403.20330 , year=
work page internal anchor Pith review arXiv
-
[30]
MMBench: Is Your Multi-modal Model an All-around Player?
MMBench: Is Your Multi-modal Model an All-around Player? , author=. arXiv preprint arXiv:2307.06281 , year=
work page internal anchor Pith review arXiv
-
[31]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities , author=. arXiv preprint arXiv:2308.02490 , year=
work page internal anchor Pith review arXiv
-
[32]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author=. arXiv preprint arXiv:2306.13394 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [33]
-
[34]
MVBench: A Comprehensive Multi-modal Video Understanding Benchmark , author=. arXiv preprint arXiv:2311.17005 , year=
-
[35]
Egoschema: A diagnostic benchmark for very long-form video language understanding, 2023
EgoSchema: A Diagnostic Benchmark for Very Long-form Video Language Understanding , author=. arXiv preprint arXiv:2308.09126 , year=
-
[36]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-MME: The First-Ever Comprehensive Evaluation Benchmark of Multi-modal LLMs in Video Analysis , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[37]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding , author=. arXiv preprint arXiv:2407.15754 , year=
-
[38]
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos , author=. arXiv preprint arXiv:2501.13826 , year=
work page internal anchor Pith review arXiv
-
[39]
Microsoft COCO: Common Objects in Context
Microsoft COCO: Common Objects in Context , author=. arXiv preprint arXiv:1405.0312 , year=
work page internal anchor Pith review arXiv
-
[40]
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models , author=. arXiv preprint arXiv:2407.12772 , year=
-
[41]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[42]
LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer , author=. arXiv preprint arXiv:2408.03326 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
MIT -10 M : A Large Scale Parallel Corpus of Multilingual Image Translation
Li, Bo and Zhu, Shaolin and Wen, Lijie. MIT -10 M : A Large Scale Parallel Corpus of Multilingual Image Translation. Proceedings of the 31st International Conference on Computational Linguistics. 2025
work page 2025
-
[44]
Junchen Li and Qing Yang and Bojian Jiang and Shaolin Zhu and Qingxuan Sun , editor =. LRM-LLaVA: Overcoming the Modality Gap of Multilingual Large Language-Vision Model for Low-Resource Languages , booktitle =. 2025 , timestamp =
work page 2025
-
[45]
PEIT : Bridging the Modality Gap with Pre-trained Models for End-to-End Image Translation
Zhu, Shaolin and Li, Shangjie and Lei, Yikun and Xiong, Deyi. PEIT : Bridging the Modality Gap with Pre-trained Models for End-to-End Image Translation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023
work page 2023
-
[46]
Shaolin Zhu and Leiyu Pan and Dong Jian and Deyi Xiong , keywords =. Overcoming language barriers via machine translation with sparse Mixture-of-Experts fusion of large language models , journal =. 2025 , issn =
work page 2025
-
[47]
Li, Shangjie and Wei, Xiangpeng and Zhu, Shaolin and Xie, Jun and Yang, Baosong and Xiong, Deyi. MMNMT : Modularizing Multilingual Neural Machine Translation with Flexibly Assembled M o E and Dense Blocks. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023
work page 2023
-
[48]
Evaluating and Steering Modality Preferences in Multimodal Large Language Model , author=. 2026 , eprint=
work page 2026
-
[49]
Zhang, Dingkun and Qi, Shuhan and Xiao, Xinyu and Chen, Kehai and Wang, Xuan. Merge then Realign: Simple and Effective Modality-Incremental Continual Learning for Multimodal LLM s. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025
work page 2025
-
[50]
I n I mage T rans: Multimodal LLM -based Text Image Machine Translation
Zuo, Fei and Chen, Kehai and Zhang, Yu and Xue, Zhengshan and Zhang, Min. I n I mage T rans: Multimodal LLM -based Text Image Machine Translation. Findings of the Association for Computational Linguistics: ACL 2025. 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.