Recognition: unknown
Topology-Driven Anti-Entanglement Control for Soft Robots
Pith reviewed 2026-05-09 19:25 UTC · model grok-4.3
The pith
Sharing topological states during training helps multi-robot systems avoid entanglement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
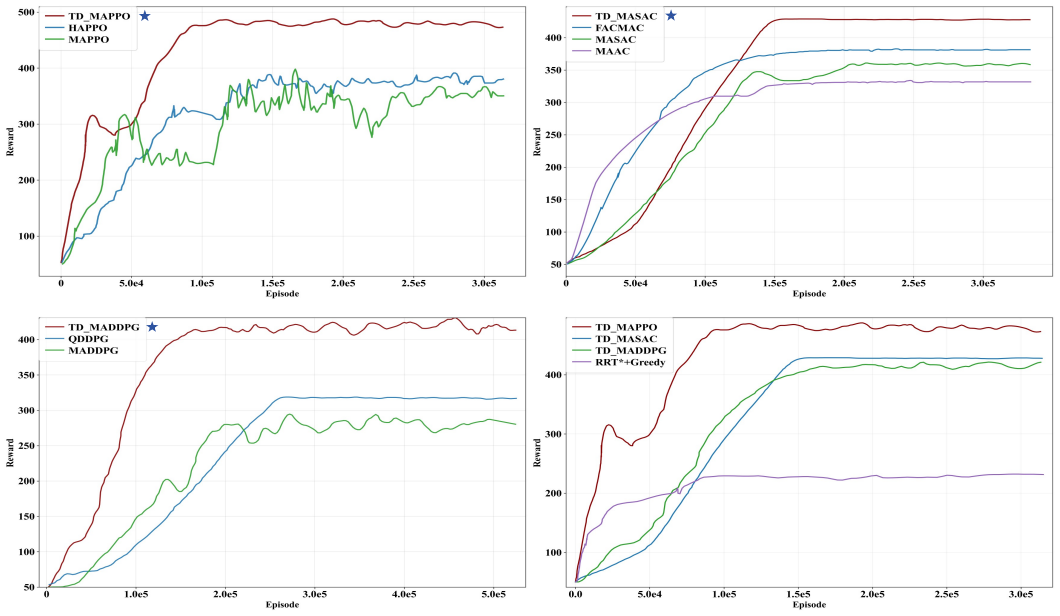
The TD-MARL framework coordinates multiple soft robots for unwinding operations by adopting centralized learning with shared topological states to address observability challenges, combined with a topological security layer using invariants to mitigate entanglement risks, and demonstrates through simulation experiments better convergence and anti-winding effects than current advanced DRL methods.
What carries the argument
The topology-driven multi-agent reinforcement learning (TD-MARL) framework, which integrates centralized training with topological state sharing and a topological security layer to evaluate entanglement risks.
If this is right
- Each robot perceives others' strategies without direct communication during execution.
- Training instability from complex interactions is alleviated.
- The topological security layer prevents strategies from entering local difficulties.
- Overall system reliability increases in multi-robot precision manufacturing tasks.
Where Pith is reading between the lines
- This method could reduce communication overhead in real-world robotic deployments.
- Similar topological approaches might address coordination issues in other constrained multi-agent systems.
- Validation on physical hardware would test if simulation benefits hold for actual soft robot materials and sensors.
Load-bearing premise
Sharing topological state information during centralized training will reliably alleviate observability challenges and training instability in high-density barrier environments without introducing new failure modes or requiring communication at execution time.
What would settle it
Running the full simulation in a high-density barrier environment and finding that TD-MARL does not outperform advanced DRL in convergence speed or anti-winding success rate would falsify the claimed advantages.
Figures



read the original abstract
In the field of precision manufacturing in complex constrained environments, the role of soft robots is increasingly prominent, and the realization of anti-winding control based on multi-intelligent body reinforcement learning has become a research hotspot. One of the core problems at present is to coordinate multiple robots to complete the unwinding operation in a highly constrained environment. The existing distributed training framework faces some observability challenges in high-density barrier and unstable environments, resulting in poor learning results. This paper proposes a topology-driven Multi-Agent Reinforcement Learning (TD-MARL) framework to coordinate multi-robot systems to avoid entanglement. Specifically, the critical network adopts centralized learning, so that each intelligent body can perceive the strategies of other intelligent bodies by sharing the topological state, thus alleviating the training instability caused by complex interactions; eliminating the demand for communication resources between robots through distributed execution, Upgrade system reliability; the integrated topological security layer uses topological invariants to accurately assess and mitigate the risk of entanglement to avoid the strategy from falling into local difficulties. Finally, the full simulation experiments carried out in the real simulation environment show that the method is better than the current advanced deep reinforcement learning (DRL) method in terms of convergence and anti-winding effect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Topology-Driven Multi-Agent Reinforcement Learning (TD-MARL) framework for coordinating multiple soft robots to perform anti-entanglement (unwinding) operations in highly constrained environments. It employs centralized training in which agents share topological state information to mitigate observability and instability issues, distributed execution to avoid inter-robot communication at runtime, and an integrated topological security layer that uses topological invariants to assess and reduce entanglement risk. The central claim is that full simulation experiments in a real simulation environment demonstrate superior convergence speed and anti-winding performance relative to current advanced deep reinforcement learning methods.
Significance. If the performance claims are substantiated with reproducible experiments, the integration of topological invariants into multi-agent RL could offer a principled way to handle entanglement constraints in soft-robot teams, which is relevant to precision manufacturing. The centralized-training/distributed-execution pattern is standard, but its combination with topology-based safety layers for soft-robot contact dynamics would be a useful contribution if shown to be robust. The current manuscript, however, provides no experimental details, so its significance cannot yet be assessed.
major comments (3)
- [Abstract / Simulation Experiments] Abstract and simulation-experiments description: the central claim that TD-MARL outperforms advanced DRL methods in convergence and anti-winding rests entirely on 'full simulation experiments' whose setup, baselines, metrics (e.g., reward curves, entanglement counts, success rates), number of trials, statistical tests, or failure cases are never specified. Without these, the superiority statement cannot be evaluated and is not load-bearing evidence.
- [TD-MARL Framework] Framework description (centralized training with shared topological states): the paper assumes that sharing topological invariants during centralized training reliably alleviates observability challenges in high-density barrier environments without introducing new failure modes or execution-time costs. No analysis or ablation is provided on how invariants are computed from soft-robot deformation/contact models, nor on robustness when those invariants are noisy, delayed, or imperfect—conditions that are likely in real soft-robot simulation.
- [Topological Security Layer] Topological security layer: the claim that topological invariants 'accurately assess and mitigate the risk of entanglement' and prevent the policy from falling into local difficulties is stated without any derivation, definition of the invariants used, or proof that they remain invariant under the soft-robot dynamics and contact models employed.
minor comments (2)
- [Abstract] The abstract is unusually long and contains the entire technical narrative; a shorter abstract focused on the contribution plus a dedicated methods/experiments section would improve readability.
- [Throughout] No equations, pseudocode, or network architectures are shown, making it difficult to understand exactly how the critical network incorporates the shared topological state.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that the current manuscript lacks sufficient experimental details and theoretical elaboration to fully support its claims. We will revise the paper to address all points raised, adding the necessary sections on experiments, ablations, and formal definitions to make the contributions more robust and reproducible.
read point-by-point responses
-
Referee: [Abstract / Simulation Experiments] Abstract and simulation-experiments description: the central claim that TD-MARL outperforms advanced DRL methods in convergence and anti-winding rests entirely on 'full simulation experiments' whose setup, baselines, metrics (e.g., reward curves, entanglement counts, success rates), number of trials, statistical tests, or failure cases are never specified. Without these, the superiority statement cannot be evaluated and is not load-bearing evidence.
Authors: We acknowledge that the manuscript does not provide the required experimental details, which prevents proper evaluation of the performance claims. In the revised version, we will add a comprehensive Simulation Experiments section specifying the simulation environment and parameters, the exact baseline DRL methods (e.g., MADDPG and QMIX), all metrics including reward curves, entanglement counts, success rates, number of independent trials with statistical tests, and analysis of failure cases. This will substantiate the superiority claims with reproducible evidence. revision: yes
-
Referee: [TD-MARL Framework] Framework description (centralized training with shared topological states): the paper assumes that sharing topological invariants during centralized training reliably alleviates observability challenges in high-density barrier environments without introducing new failure modes or execution-time costs. No analysis or ablation is provided on how invariants are computed from soft-robot deformation/contact models, nor on robustness when those invariants are noisy, delayed, or imperfect—conditions that are likely in real soft-robot simulation.
Authors: The design relies on topological states to mitigate partial observability during centralized training. However, the manuscript indeed lacks analysis of invariant computation from deformation models and robustness to noise or delays. In the revision, we will include an ablation study on invariant computation methods, sensitivity analysis to noise/delay, and discussion of potential failure modes and runtime costs to address these concerns. revision: yes
-
Referee: [Topological Security Layer] Topological security layer: the claim that topological invariants 'accurately assess and mitigate the risk of entanglement' and prevent the policy from falling into local difficulties is stated without any derivation, definition of the invariants used, or proof that they remain invariant under the soft-robot dynamics and contact models employed.
Authors: We recognize that the topological security layer is presented at a conceptual level without explicit definitions or proofs. In the revised manuscript, we will provide formal definitions of the topological invariants, derive their application to entanglement risk assessment based on the robot dynamics and contact models, and include a justification (or proof sketch) of invariance under the relevant transformations. revision: yes
Circularity Check
No circularity; descriptive framework with no derivation chain or equations
full rationale
The paper proposes the TD-MARL framework (centralized training with shared topological states, distributed execution, topological security layer) and claims superior simulation performance versus DRL baselines. No equations, mathematical derivations, fitted parameters, or self-citations appear in the abstract or description. Performance claims rest on experimental results rather than any reduction of outputs to inputs by construction. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Held, D., Tamar, A., Abbeel, P.,
doi:10.1007/s11701-025-02853-w. Achiam, J., Held, D., Tamar, A., Abbeel, P.,
-
[2]
arXiv preprint URL:https://arxiv.org/abs/1705.10528
Constrained policy optimiza- tion. arXiv preprint URL:https://arxiv.org/abs/1705.10528. Adil,A.A.,Sakhrieh,S.,Mounsef,J.,Maalouf,N.,2025. Amulti-robotcollabo- rativemanipulationframeworkfordynamicandobstacle-denseenvironments: integrationofdeeplearningforreal-timetaskexecution. FrontiersinRobotics and AI 12, 1585544. doi:10.3389/frobt.2025.1585544. Artin, E.,
-
[3]
American Scientist 38, 112–119
The theory of braids. American Scientist 38, 112–119. URL: http://www.jstor.org/stable/27826294. Betts, J.T.,
-
[4]
Survey of numerical methods for trajectory optimization. J. Guid. Control Dyn. 21, 193–207. URL:https://ui.adsabs.harvard.edu/abs/ 1998JGCD...21..193B, doi:10.2514/2.4231. Birman,J.S.,1974.Braids,links,andmappingclassgroups.volume82ofAnnals of Mathematics Studies. Princeton University Press, Princeton, NJ. URL: http://www.jstor.org/stable/j.ctt1b9rzv3, do...
-
[5]
IEEE Transactions on Industrial Informatics doi:10.1109/TII.2022.3158978
Knowl- edge sharing enabled multi-robot collaboration for preventive maintenance in mixed model assembly. IEEE Transactions on Industrial Informatics doi:10.1109/TII.2022.3158978. Dai,T.,Ma,A.,Mao,J.,etal.,2024. Aprogrammabletopologicalphotonicchip. Nature Materials 23, 928–936. doi:10.1038/s41563-024-01904-1. Du,Y.,Liu,B.,Moens,V.,Liu,Z.,Ren,Z.,Wang,J.,C...
-
[6]
Engineering Applications of Artificial Intelligence 153, 110791
Autonomous control of soft robots using safe reinforcement learning and covariance matrix adaptation. Engineering Applications of Artificial Intelligence 153, 110791. URL:https://www.sciencedirect.com/science/article/pii/ S0952197625007912, doi:https://doi.org/10.1016/j.engappai.2025.110791. Guo, S.K., Ma, Z.L., Xia, G.H., et al.,
-
[7]
Ben Britton, Tea-Sung Jun, Weimin Gan, Michael Hofmann, Fionn P.E
Pursuing ultrastrong and ductile medium entropy alloys via architecting nanoprecipitates-enhanced hierarchi- cal heterostructure. Acta Materialia 263, 119492. doi:10.1016/j.actamat. 2023.119492. Halverson, J., Ruehle, F.,
-
[8]
arXiv preprint URL:https://arxiv.org/abs/2504.12390
Learning topological invariance. arXiv preprint URL:https://arxiv.org/abs/2504.12390. Jin, Z., Yu, J., Liang, Y., Wang, Y., Wang, Z., Hu, C.,
-
[9]
AdvancedEngineeringInformatics 69, 103923
Co-dosp: A hi- erarchicaloptimization-basedmotionplannerformulti-robotmanipulationin confinedandtask-constrainedworkspace. AdvancedEngineeringInformatics 69, 103923. doi:https://doi.org/10.1016/j.aei.2025.103923. Karaman, S., Frazzoli, E.,
-
[10]
arXiv preprint URL:https://arxiv.org/abs/1105.1186
Sampling-based algorithms for optimal motion planning. arXiv preprint URL:https://arxiv.org/abs/1105.1186. arXiv:1105.1186. Kavraki, L.E., Svestka, P., Latombe, J.C., Overmars, M.H.,
-
[11]
IEEE Transactions on Robotics and Automation 12, 566–580
Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Transactions on Robotics and Automation 12, 566–580. doi:10.1109/70. 508439. Kuba, J.G., Chen, R., Wen, M., Wen, Y., Sun, F., Wang, J., Yang, Y.,
-
[12]
Jakub Grudzien Kuba, Ruiqing Chen, Muning Wen, Ying Wen, Fanglei Sun, Jun Wang, and Yaodong Yang
Trustregionpolicyoptimisationinmulti-agentreinforcementlearning. arXiv preprint URL:https://arxiv.org/abs/2109.11251. Kuskonmaz, B., Wisniewski, R., Kallesøe, C.,
-
[13]
Topological data analysis- based replay attack detection for water networks. IFAC-PapersOnLine 58, 91–96. URL:https://www.sciencedirect.com/science/article/pii/ S2405896324002830, doi:https://doi.org/10.1016/j.ifacol.2024.07.199. 12th IFAC Symposium on Fault Detection, Supervision and Safety for Technical Processes SAFEPROCESS
-
[14]
Cooperative open-ended learning frame- work for zero-shot coordination, in: Proceedings of the 40th International Conference on Machine Learning, pp. 19837–19854. URL:https://sites. google.com/view/cole-2023/. Lou,G.,Wang,C.,Xu,Z.,Liang,J.,Zhou,Y.,2024.Controllingsoftroboticarms usinghybridmodellingandreinforcementlearning.IEEERobot.Autom.Lett. 9, 7070–70...
-
[15]
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments, March 2020
Multi-agent actor-critic for mixed cooperative-competitive environments. arXiv preprint URL:https://arxiv. org/abs/1706.02275. arXiv:1706.02275. Mohammad, N., Bezzo, N.,
-
[16]
Annals of Mathematics 43, 223–243
On theories with a combinatorial definition of ‘equiv- alence’. Annals of Mathematics 43, 223–243. URL:http://www.jstor.org/ stable/1968867. Onder, C.E., Koc, G., Gokbulut, P., et al.,
-
[17]
Perolat,J.,DeVylder,B.,Hennes,D.,etal.,2022
doi:10.1038/s41598-023-50884-w. Perolat,J.,DeVylder,B.,Hennes,D.,etal.,2022. Masteringthegameofstratego with model-free multiagent reinforcement learning. Science 378, 990–996. doi:10.1126/science.add4679. Qu,T.,Wang,M.,Cheng,X.,etal.,2024. Topologicalphotonicalloy. Phys.Rev. Lett. 132, 223802. doi:10.1103/PhysRevLett.132.223802. Rashid, T., Samvelyan, M....
-
[18]
Applicationsofknottheoryinfluidmechanics
Ricca,R.L.,1998. Applicationsofknottheoryinfluidmechanics. BanachCent. Publ. 42, 321–346. Le, Wang, Chen, Feng:Preprint submitted to ElsevierPage 15 of 16 Rucker, D.C., Jones, B.A., Webster, R.J.,
1998
-
[19]
IEEE Transactions on Robotics 26, 769–780
A geometrically exact model for externally loaded concentric-tube continuum robots. IEEE Transactions on Robotics 26, 769–780. doi:10.1109/TRO.2010.2062570. Rus,D.,Tolley,M.T.,2015.Design,fabricationandcontrolofsoftrobots.Nature 521, 467–475. Sá Barreto, A., Stefanov, P.,
-
[20]
Conflict-based search for optimal multi-agent pathfinding. Artificial Intelligence 219, 40–66. doi:10.1016/j. artint.2014.11.006. Shiller, Z.,
work page doi:10.1016/j 2014
-
[21]
Online sub-optimal obstacle avoidance, in: Proc. IEEE Int. Conf. Robot. Autom., pp. 335–340. doi:10.1109/ROBOT.1999.770001. Solis, I., Motes, J., Sandström, R., et al.,
-
[22]
IEEE Robotics and Automation Letters 6, 4608–4615
Representation-optimal multi- robot motion planning using conflict-based search. IEEE Robotics and Automation Letters 6, 4608–4615. doi:10.1109/LRA.2021.3068910. Sun, H.h., Hu, C.h., Zhang, J.g.,
-
[23]
Control and Decision 38, 1420–1429
Cooperative countermeasure strategy based on active risk defense multi-agent reinforcement learning. Control and Decision 38, 1420–1429. doi:10.13195/j.kzyjc.2022.1375. Trivedi, D., Rahn, C.D., Kier, W.M., et al.,
-
[24]
Soft robotics: Biological inspiration, state of the art, and future research. Applied Bionics and Biomechanics 5, 99–117. doi:10.1080/11762320802557865. Wang, F., Zhou, Y., Wang, S., et al.,
-
[25]
arXiv preprint URL:https://arxiv.org/abs/2210.06044
Multi-granularity cross-modal alignment for generalized medical visual representation learning. arXiv preprint URL:https://arxiv.org/abs/2210.06044. arXiv:2210.06044. Wang, H., Chen, W.,
-
[26]
IEEE Robotics and Automation Letters 7, 4829–4836
Multi-robot path planning with due times. IEEE Robotics and Automation Letters 7, 4829–4836. doi:10.1109/LRA.2022. 3152701. Wang, M., Dong, X., Ba, W., Mohammad, A., Axinte, D., Norton, A.,
-
[27]
arXiv preprint URL:https: //arxiv.org/abs/1910.04572
Design, modelling and validation of a novel extra slender continuum robot for in-situ inspection and repair in aeroengine. arXiv preprint URL:https: //arxiv.org/abs/1910.04572. Webster, R.J., Jones, B.A.,
-
[28]
Design and kinematic modeling of constant curvature continuum robots: A review. Int. J. Robot. Res. 29, 1661–1683. URL:https://api.semanticscholar.org/CorpusID:14607408. Yang,Z.,Wang,Y.,Jiang,Y.,Zhang,H.,Yang,C.,2024. Deformernetbased3d deformable objects shape servo control for bimanual robot manipulation, in: Proc. IEEE Int. Conf. Ind. Technol. (ICIT), ...
-
[29]
Reactive human–robot collaborative manipula- tionofdeformablelinearobjectsusinganewtopologicallatentcontrolmodel. Robot. Comput.-Integr. Manuf. 88, 1–20. doi:10.1016/j.rcim.2024.102727. Le, Wang, Chen, Feng:Preprint submitted to ElsevierPage 16 of 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.