Recognition: 1 theorem link
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
Pith reviewed 2026-05-08 19:06 UTC · model grok-4.3
The pith
Agents retrieve information more effectively by directly probing raw text with tools like grep than by relying on semantic similarity interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
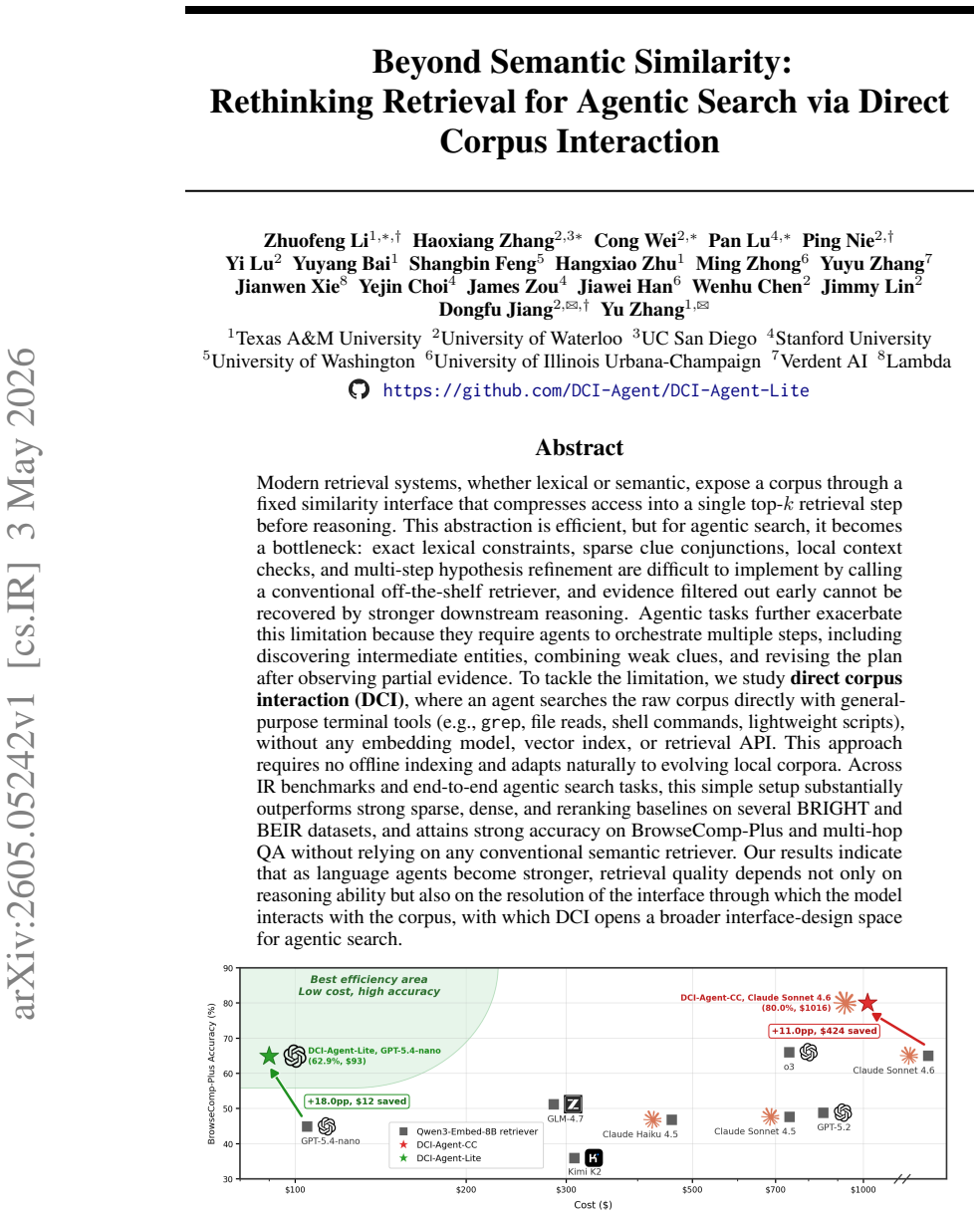
Direct corpus interaction lets an agent search the raw corpus using general-purpose terminal tools such as grep, file reads, and lightweight scripts without embedding models, vector indexes, or retrieval APIs; this setup substantially outperforms strong sparse, dense, and reranking baselines on several BRIGHT and BEIR datasets and reaches strong accuracy on BrowseComp-Plus and multi-hop QA.
What carries the argument
Direct corpus interaction (DCI), the approach of letting agents apply everyday terminal commands and scripts directly to raw text files to enforce exact lexical constraints, combine sparse clues, and revise plans from partial evidence.
If this is right
- Agents no longer lose evidence filtered out in an early similarity step and can recover it through later direct checks.
- Exact lexical constraints and multi-step hypothesis refinement become straightforward to implement without calling an off-the-shelf retriever.
- Systems adapt to evolving local corpora with no offline indexing required.
- Retrieval quality for agents depends on the resolution of the interaction interface as much as on reasoning ability.
Where Pith is reading between the lines
- Agent architectures may treat terminal tool access as the primary retrieval layer for knowledge tasks rather than an add-on.
- Efficiency of general tools could replace embedding quality as the main engineering target when corpora change frequently.
- The same direct-interaction pattern might apply to other structured data sources where fixed APIs currently limit flexibility.
Load-bearing premise
Agents can efficiently and effectively use general-purpose terminal tools to explore and extract information from raw corpora of varying sizes without specialized indexing or retrieval infrastructure.
What would settle it
A controlled test on a corpus where direct tool calls recover fewer relevant passages than a standard top-k retriever on tasks that require conjunction of multiple weak clues or local context checks would falsify the performance advantage.
Figures




read the original abstract
Modern retrieval systems, whether lexical or semantic, expose a corpus through a fixed similarity interface that compresses access into a single top-k retrieval step before reasoning. This abstraction is efficient, but for agentic search, it becomes a bottleneck: exact lexical constraints, sparse clue conjunctions, local context checks, and multi-step hypothesis refinement are difficult to implement by calling a conventional off-the-shelf retriever, and evidence filtered out early cannot be recovered by stronger downstream reasoning. Agentic tasks further exacerbate this limitation because they require agents to orchestrate multiple steps, including discovering intermediate entities, combining weak clues, and revising the plan after observing partial evidence. To tackle the limitation, we study direct corpus interaction (DCI), where an agent searches the raw corpus directly with general-purpose terminal tools (e.g., grep, file reads, shell commands, lightweight scripts), without any embedding model, vector index, or retrieval API. This approach requires no offline indexing and adapts naturally to evolving local corpora. Across IR benchmarks and end-to-end agentic search tasks, this simple setup substantially outperforms strong sparse, dense, and reranking baselines on several BRIGHT and BEIR datasets, and attains strong accuracy on BrowseComp-Plus and multi-hop QA without relying on any conventional semantic retriever. Our results indicate that as language agents become stronger, retrieval quality depends not only on reasoning ability but also on the resolution of the interface through which the model interacts with the corpus, with which DCI opens a broader interface-design space for agentic search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Direct Corpus Interaction (DCI) as an alternative retrieval paradigm for agentic search. Instead of exposing corpora through fixed lexical or semantic similarity interfaces that return top-k results, DCI lets LLM agents interact directly with raw corpus files using general-purpose terminal tools (grep, file reads, shell commands, lightweight scripts). The authors claim this higher-resolution interface enables better handling of exact constraints, clue conjunctions, and multi-step reasoning, yielding substantial outperformance over strong sparse, dense, and reranking baselines on several BRIGHT and BEIR datasets plus strong accuracy on BrowseComp-Plus and multi-hop QA, all without any conventional semantic retriever or offline index.
Significance. If the empirical claims hold under the stated conditions, the work would demonstrate that retrieval quality for capable agents depends as much on interface resolution as on model reasoning, opening a broader design space beyond similarity-based abstractions. The no-indexing property is practically attractive for dynamic or local corpora. The absence of quantitative results, protocols, or controls in the abstract, however, leaves the magnitude and robustness of the reported gains unevaluable at present.
major comments (2)
- [Abstract] Abstract: the central claim of substantial outperformance on BRIGHT and BEIR (and strong accuracy on BrowseComp-Plus/multi-hop QA) is asserted without any numerical results, experimental protocols, error analysis, or controls. This prevents assessment of whether the gains are large enough, statistically reliable, or attributable to DCI rather than other factors.
- [Experimental Evaluation] Experimental sections (methods and results): the headline attribution of gains to the 'higher-resolution DCI interface' rather than conventional retrievers is load-bearing on the assumption that agents used only general-purpose terminal tools on full-scale raw corpora (tens of thousands to >1 M documents). The manuscript must explicitly report corpus sizes actually used, total tool-call budgets, confirmation that no custom indexing scripts or down-sampling occurred, and evidence that exhaustive or narrow-command searches remained tractable; otherwise the interface-resolution argument does not follow from the results.
minor comments (2)
- [Methods] Clarify the precise boundary between 'general-purpose terminal tools' and any agent-written scripts that might implicitly re-implement indexing or caching; this distinction is essential for reproducibility.
- [Abstract] The abstract and introduction would benefit from a short table or bullet list of the key quantitative improvements (e.g., nDCG or accuracy deltas) to make the claims immediately evaluable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to enhance transparency and evaluability of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of substantial outperformance on BRIGHT and BEIR (and strong accuracy on BrowseComp-Plus/multi-hop QA) is asserted without any numerical results, experimental protocols, error analysis, or controls. This prevents assessment of whether the gains are large enough, statistically reliable, or attributable to DCI rather than other factors.
Authors: We agree that the abstract would benefit from quantitative support to make the claims more immediately assessable. In the revised manuscript we will incorporate key numerical results (e.g., relative gains on the relevant BRIGHT and BEIR subsets together with absolute accuracies on BrowseComp-Plus and the multi-hop QA tasks) while remaining within length limits. A brief reference to the evaluation protocol will also be added so readers can contextualize the reported figures. revision: yes
-
Referee: [Experimental Evaluation] Experimental sections (methods and results): the headline attribution of gains to the 'higher-resolution DCI interface' rather than conventional retrievers is load-bearing on the assumption that agents used only general-purpose terminal tools on full-scale raw corpora (tens of thousands to >1 M documents). The manuscript must explicitly report corpus sizes actually used, total tool-call budgets, confirmation that no custom indexing scripts or down-sampling occurred, and evidence that exhaustive or narrow-command searches remained tractable; otherwise the interface-resolution argument does not follow from the results.
Authors: We concur that these experimental controls are essential for substantiating the interface-resolution claim. The current manuscript states that DCI operates directly on raw corpora with general-purpose tools and no indexing, but we will expand the experimental sections to include: (i) explicit corpus sizes for every benchmark (confirming full-scale usage without down-sampling), (ii) statistics on tool-call budgets, (iii) explicit confirmation that no custom indexing scripts were employed, and (iv) discussion of search tractability, including any observed limits and the strategies used to keep exhaustive or narrow-command searches feasible. These additions will be placed in a new or expanded subsection so the attribution to DCI follows directly from the reported conditions. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential fits
full rationale
The paper advances an empirical claim that direct corpus interaction via general terminal tools outperforms conventional retrievers on BRIGHT/BEIR and agentic tasks. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text or abstract. The central argument rests on benchmark results that are externally falsifiable and do not reduce to any definitional or constructional equivalence with the proposed interface. This is the expected non-finding for an engineering/empirical IR paper without mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption General-purpose terminal tools enable agents to perform effective multi-step exploration and evidence gathering on raw corpora.
invented entities (1)
-
Direct Corpus Interaction (DCI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Search directly using ripgrep/Bash — do NOT use the Agent tool, spawn subagents, or browse the web
-
[2]
Run multipleripgrep/Bashsearches IN PARALLEL within a single response to save time
-
[3]
INSTRUCTIONS: • Search @corpus thoroughly with multiple relevant keyword combinations
Use diverse, targeted keywords to maximize recall before drawing conclusions. INSTRUCTIONS: • Search @corpus thoroughly with multiple relevant keyword combinations. • Identify and rule out competing candidate answers before committing to one. • Cite every supporting finding inline using the document’s path, e.g.[@corpus/relative_path]. Your response MUST ...
-
[4]
UseGrep/BashONLY — do NOT use the Agent tool, spawn subagents, or browse the web
-
[5]
Run multipleGrep/Bashsearches IN PARALLEL within a single response to save time
-
[6]
Use diverse, targeted keywords to maximize recall before drawing conclusions
-
[7]
After each round, reflect on gaps and launch follow-up searches to cover missing angles
-
[8]
pattern":
Do NOT stop after finding a few documents — exhaust all plausible search angles. RETRIEV AL INSTRUCTIONS: • Both recall AND precision matter equally — the output is evaluated with NDCG, which penalizes both missing relevant documents and including irrelevant ones. • Find EVERY document that is genuinely relevant. Missing a gold document hurts recall. • Re...
-
[9]
technique
Under 35,000 spectators 6. Stadium built more than 50 years before the match 7. Three refereeing officials with different nationalities 8. Goalscorer started professional career at age 18, less than 10 years before the match 9. The goalscorer said the goal was scored with "technique" rather than power (in an interview) 10. The goalscorer also scored in th...
1970
-
[10]
command":
Stadium built more than 50 years before—Renato Dall’Ara stadium in Bologna—need to verify 7. Three refereeing officials with different nationalities—Denmark, Italy, Yugoslavia—YES 8-12. Need to verify goalscorer details and Belgium players. Tool:Bash Tool Call: { "command": "cat \"browsecomp-plus-corpus/theguardian.com/David\_Platt\_\_Italia\_90\ _and\_En...
1966
-
[11]
do it at Auxerre a lot
The difference is 20 days—less than a month! Both are born in 1966, the same year as David Platt (10 June 1966). Scifo is the older of the two (February vs. March). Paul Parker mentioned Scifo in the Guardian interview. Chris Waddle said he’d seen Scifo “do it at Auxerre a lot.” Therefore, the club is AJ Auxerre. Tool:Bash Tool Call: { "command": "cat \"b...
1966
-
[12]
scoreboard,
txt bc \ _plus \ _docs / www . frieze . com / The Trouble With Harry Nilsson . txt bc \ _plus \ _docs / www . hampton . gov / Fort Monroe . txt bc \ _plus \ _docs / www . beltandr oadforum . org / A Global Community of Shared Future China's Proposals and Actions . txt bc \ _plus \ _docs / www . beltandr oadforum . org / The Belt ... Turn 2: Reasoning Cont...
1919
-
[13]
The Lobster Tank,
There’s also a mention of "The Lobster Tank," which seems related to the story’s tank filled with lobsters. I need to confirm the publication date, which is May 19, 2015. The clues seem to align well regarding the main character, the boy with blue eyes, and the principal’s obsession with the scoreboard. **Confirming author’s background** I’m noticing that...
2015
-
[14]
Barcelona’s 2018-19 UCL Group B opponents: PSV Eindhoven, Tottenham Hotspur, Inter Milan 3
Denis Suarez was loaned from Barcelona to Arsenal on January 31, 2019 2. Barcelona’s 2018-19 UCL Group B opponents: PSV Eindhoven, Tottenham Hotspur, Inter Milan 3. Denis Suarez scored 0 UCL goals for Barcelona in 2018-19 but could have been on the bench 4. I can’t find a specific document confirming which UCL game Denis Suarez was on the bench for
2019
-
[15]
a football match in England in 2019
I also can’t locate any corpus evidence about the water bottle incident itself Based on what I can verify, Denis Suarez was likely on Barcelona’s bench during their fall 2018 UCL group stage matches before his January loan to Arsenal, though I don’t have documentation confirming the specific game or the water bottle incident the question references. For B...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.