Recognition: 3 theorem links
· Lean TheoremTriAlignGR: Triangular Multitask Alignment with Multimodal Deep Interest Mining for Generative Recommendation
Pith reviewed 2026-05-08 18:41 UTC · model grok-4.3
The pith
TriAlignGR embeds visual semantics directly into Semantic IDs to fix content loss and opacity in generative recommendation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
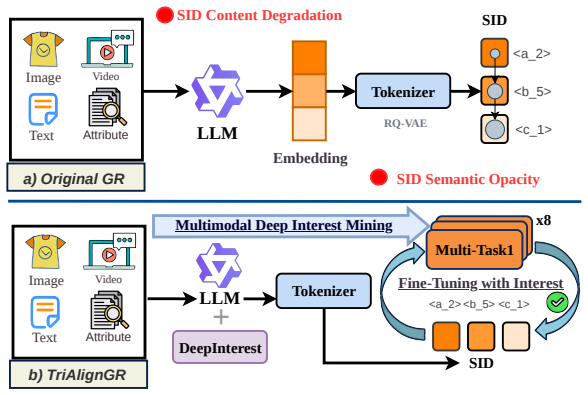
TriAlignGR resolves SID Content Degradation and SID Semantic Opacity by establishing two-stage multimodal semantic propagation: encoding visual semantics into SIDs through multimodal embeddings and VLM descriptions, then enabling decoding via visual description tasks, all achieved through Cross-Modal Semantic Alignment, Multimodal Deep Interest Mining, and Triangular Multitask training on eight complementary generation tasks.
What carries the argument
Triangular Multitask (TMT) training with Cross-Modal Semantic Alignment (CMSA) and Multimodal Deep Interest Mining (MDIM), which jointly optimizes eight tasks including novel visual-semantic mappings to ensure SIDs carry and allow comprehension of multimodal meaning.
Load-bearing premise
VLM-generated descriptions and multimodal embeddings preserve critical semantics without introducing new noise or bias, and joint training on the eight tasks improves rather than interferes with core generative recommendation performance.
What would settle it
A controlled experiment showing that ablating the two novel visual-semantic tasks or injecting noisy VLM descriptions produces equal or worse NDCG and hit-rate scores on standard recommendation benchmarks would falsify the claim that the alignment resolves SCD and SSO.
Figures



read the original abstract
We introduce TriAlignGR, a unified multitask-multimodal framework for generative recommendation that establishes two-stage multimodal semantic propagation: (i) encoding visual semantics directly into SIDs via multimodal embeddings, and (ii) enabling the model to decode these semantics through visual description tasks. Existing Semantic ID (SID) pipelines suffer from two fundamental but underexplored problems: \textbf{SID Content Degradation (SCD)}, where cascaded encoding and residual quantization discard critical multimodal and interest-level semantics; and \textbf{SID Semantic Opacity (SSO)}, where models autoregressively generate SID sequences without truly comprehending their underlying meaning, leading to hallucination and poor generalization. Prior work addresses at most text-SID alignment, leaving visual semantics and latent user interests entirely unexploited. TriAlignGR resolves both problems through three tightly integrated components: (1)~\textbf{Cross-Modal Semantic Alignment (CMSA)} integrates visual content into SID construction through both VLM-generated textual descriptions and a multimodal embedding model that directly encodes image features alongside text, ensuring that SIDs inherently carry multimodal semantics; (2)~\textbf{Multimodal Deep Interest Mining (MDIM)} leverages LLM Chain-of-Thought reasoning to extract latent user intents (\eg ``productivity-focused lifestyle'' from noise-canceling headphones) beyond surface attributes, enriching SID semantics before discretization; and (3)~\textbf{Triangular Multitask (TMT)} jointly trains on eight complementary generation tasks under a single autoregressive loss -- including two novel visual-semantic tasks (VisDesc$\to$SID, VisDesc$\to$Title) that map VLM-generated image descriptions to SIDs and titles, completing the SID-Text-Image triangle -- without requiring task-specific towers or complex loss weighting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TriAlignGR, a unified multitask-multimodal framework for generative recommendation. It identifies two underexplored problems in Semantic ID (SID) pipelines—SID Content Degradation (SCD), where cascaded encoding and residual quantization discard multimodal and interest-level semantics, and SID Semantic Opacity (SSO), where models generate SID sequences without comprehending their meaning. TriAlignGR addresses these via three components: Cross-Modal Semantic Alignment (CMSA) that integrates visual content into SID construction using VLM-generated descriptions and multimodal embeddings; Multimodal Deep Interest Mining (MDIM) that uses LLM Chain-of-Thought to extract latent user intents; and Triangular Multitask (TMT) that jointly trains on eight generation tasks (including two novel visual-semantic tasks) under a single autoregressive loss to complete the SID-Text-Image triangle.
Significance. If the empirical claims hold, the work could advance generative recommendation by explicitly propagating multimodal semantics and latent interests into SIDs, potentially reducing hallucinations and improving generalization beyond text-only SID alignment. The triangular multitask setup and use of VLM/LLM for semantic enrichment represent a novel integration that builds on existing SID methods without requiring task-specific towers.
major comments (3)
- [CMSA and MDIM components] The central claims that CMSA and MDIM resolve SCD by encoding accurate visual semantics and latent interests via VLM captions and LLM CoT, and that TMT resolves SSO via the SID-Text-Image triangle, rest on untested assumptions about noise-free semantic preservation. VLMs are known to hallucinate or omit fine-grained details, and LLM CoT can fabricate intents; the manuscript provides no ablation or error analysis measuring whether these components degrade rather than enrich the semantics already lost in residual quantization (see description of CMSA and MDIM).
- [TMT component] TMT jointly optimizes eight tasks under a single autoregressive loss with no explicit mechanisms (task weighting, gradient surgery, or per-task validation) to prevent negative transfer from the two novel visual-semantic tasks back to core SID generation. This directly risks undermining the claimed resolution of SCD/SSO if the auxiliary tasks dilute the primary recommendation signal (see TMT description).
- [Experimental section] No quantitative results, ablations, baselines, or error analysis are supplied to support that the proposed components actually resolve SCD and SSO or outperform prior text-SID alignment methods. Without these, the framework remains a plausible but unverified construction.
minor comments (2)
- [TMT description] Clarify the exact definition and construction of the eight tasks, including how the two novel visual-semantic tasks (VisDesc→SID, VisDesc→Title) are formulated and sampled during training.
- [CMSA description] The notation for multimodal embeddings and SID discretization could be formalized with equations to make the two-stage semantic propagation precise.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important considerations for validating our framework. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [CMSA and MDIM components] The central claims that CMSA and MDIM resolve SCD by encoding accurate visual semantics and latent interests via VLM captions and LLM CoT, and that TMT resolves SSO via the SID-Text-Image triangle, rest on untested assumptions about noise-free semantic preservation. VLMs are known to hallucinate or omit fine-grained details, and LLM CoT can fabricate intents; the manuscript provides no ablation or error analysis measuring whether these components degrade rather than enrich the semantics already lost in residual quantization (see description of CMSA and MDIM).
Authors: We agree that VLMs and LLMs can introduce noise through hallucinations or omissions, and that the manuscript currently relies on design rationale rather than direct measurement of semantic preservation. The CMSA and MDIM components are intended to enrich SIDs beyond residual quantization by incorporating multimodal embeddings and CoT-extracted intents, but empirical checks are needed. In the revised manuscript, we will add ablations that isolate CMSA and MDIM effects on SID quality, plus error analysis of VLM caption fidelity and LLM intent accuracy (via automated metrics and human review) to quantify any degradation versus enrichment. revision: yes
-
Referee: [TMT component] TMT jointly optimizes eight tasks under a single autoregressive loss with no explicit mechanisms (task weighting, gradient surgery, or per-task validation) to prevent negative transfer from the two novel visual-semantic tasks back to core SID generation. This directly risks undermining the claimed resolution of SCD/SSO if the auxiliary tasks dilute the primary recommendation signal (see TMT description).
Authors: We acknowledge the potential for negative transfer when jointly optimizing multiple tasks under a single loss. Although the eight tasks (including the two novel visual-semantic ones) are chosen to complete the SID-Text-Image triangle and reinforce semantic understanding, the initial design lacks explicit safeguards. We will revise the TMT section to include task weighting, per-task validation during training, and analysis of task interference (e.g., via gradient monitoring) to demonstrate that auxiliary tasks support rather than dilute core SID generation. revision: yes
-
Referee: [Experimental section] No quantitative results, ablations, baselines, or error analysis are supplied to support that the proposed components actually resolve SCD and SSO or outperform prior text-SID alignment methods. Without these, the framework remains a plausible but unverified construction.
Authors: We recognize that the current manuscript presents the TriAlignGR framework and its motivations without empirical results. The revised version will include comprehensive experiments on standard generative recommendation benchmarks, direct comparisons to prior text-SID alignment methods, component-wise ablations for CMSA, MDIM, and TMT, and quantitative metrics plus error analysis demonstrating improvements in semantic preservation, reduced hallucinations, and overall recommendation performance. revision: yes
Circularity Check
No circularity: additive framework on existing SID pipelines
full rationale
The paper introduces TriAlignGR as a new multitask-multimodal framework with three components (CMSA, MDIM, TMT) to address SCD and SSO in generative recommendation. No equations, derivations, or mathematical reductions are shown that equate claimed improvements to fitted parameters, self-definitions, or prior self-citations. The construction is presented as an additive integration (encoding visual semantics into SIDs, LLM-based interest mining, and joint training on eight tasks under a single autoregressive loss) atop existing SID pipelines, without any load-bearing step that reduces by construction to its own inputs. The central claims rest on empirical integration rather than tautological redefinition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal embeddings and VLM descriptions can be integrated into SIDs without critical semantic loss.
- domain assumption LLM Chain-of-Thought reasoning reliably extracts latent user intents beyond surface attributes.
Lean theorems connected to this paper
-
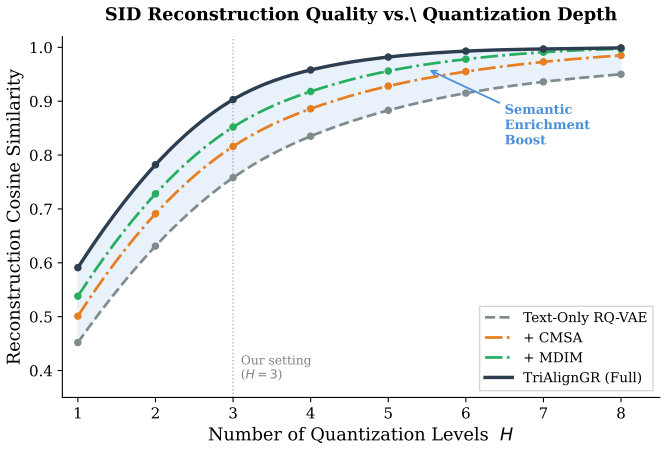
Foundation/Breath1024.lean (8-tick periodicity)period8 := 8 unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Triangular Multitask (TMT) jointly trains on eight complementary generation tasks under a single autoregressive loss
-
Foundation/RealityFromDistinction (zero-parameter forcing)reality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RQ-VAE with 3 quantization levels and codebook sizes of 4096, 2048, and 1024 ... learning rate 3×10^-4 for 3 epochs with batch size 64
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. Recommender systems with generative retrieval. InNeurIPS, 2023
2023
-
[2]
Recgpt technical report.arXiv preprint arXiv:2507.22879, 2025
Chao Yi, Dian Chen, Gaoyang Guo, Jiakai Tang, Jian Wu, Jing Yu, Mao Zhang, Sunhao Dai, Wen Chen, Wenjun Yang, et al. Recgpt technical report.arXiv preprint arXiv:2507.22879, 2025
-
[3]
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Xin Zhang, Yanzhao Zhang, Wen Xie, Mingxin Li, Ziqi Dai, Dingkun Long, Pengjun Xie, Meishan Zhang, Wenjie Li, and Min Zhang. Gme: Improving universal multimodal retrieval by multimodal llms.arXiv preprint arXiv:2412.16855, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Lamra: Large multimodal model as your advanced retrieval assistant
Yikun Liu, Yajie Zhang, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, and Weidi Xie. Lamra: Large multimodal model as your advanced retrieval assistant. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4015–4025, 2025
2025
-
[5]
Jun Zhang, Yi Li, Yue Liu, Changping Wang, Yuan Wang, Yuling Xiong, Xun Liu, Haiyang Wu, Qian Li, Enming Zhang, et al. Gpr: Towards a generative pre-trained one-model paradigm for large-scale advertising recommendation.arXiv preprint arXiv:2511.10138, 2025
-
[6]
ADS-POI: Agentic Spatiotemporal State Decomposition for Next Point-of-Interest Recommendation
Zhenyu Yu, Chunlei Meng, Yangchen Zeng, Mohd Yamani Idna Idris, and Shuigeng Zhou. Ads-poi: Agentic spatiotemporal state decomposition for next point-of-interest recommendation. arXiv preprint arXiv:2604.20846, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
CaST-POI: Candidate-Conditioned Spatiotemporal Modeling for Next POI Recommendation
Zhenyu Yu, Chunlei Meng, Yangchen Zeng, Mohd Yamani Idna Idris, and Shuigeng Zhou. Cast-poi: Candidate-conditioned spatiotemporal modeling for next poi recommendation.arXiv preprint arXiv:2604.20845, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Reasoning over semantic IDs enhances generative recommenda- tion, 2026
Yingzhi He, Yan Sun, Junfei Tan, Yuxin Chen, Xiaoyu Kong, Chunxu Shen, Xiang Wang, An Zhang, and Tat-Seng Chua. Reasoning over semantic ids enhances generative recommenda- tion.arXiv preprint arXiv:2603.23183, 2026
-
[9]
Chi, and Xinyang Yi
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, Ed H. Chi, and Xinyang Yi. Better generalization with semantic ids: A case study in ranking for recommendations. In RecSys, 2024
2024
-
[10]
Learnable item tokenization for generative recommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 2400–2409, 2024
2024
-
[11]
Session-based recommendation with graph neural networks
Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. Session-based recommendation with graph neural networks. InAAAI, 2019
2019
-
[12]
Recjpq: training large-catalogue sequential recom- menders
Aleksandr V Petrov and Craig Macdonald. Recjpq: training large-catalogue sequential recom- menders. InProceedings of the 17th ACM International Conference on Web Search and Data Mining, pages 538–547, 2024
2024
-
[13]
Learning vector-quantized item representation for transferable sequential recommenders
Yupeng Hou, Zhankui He, Julian McAuley, and Wayne Xin Zhao. Learning vector-quantized item representation for transferable sequential recommenders. InProceedings of the ACM Web Conference 2023, pages 1162–1171, 2023
2023
-
[14]
Hyperman: Hypergraph- enhanced meta-learning adaptive network for next poi recommendation
Jinze Wang, Tiehua Zhang, Lu Zhang, Yang Bai, Xin Li, and Jiong Jin. Hyperman: Hypergraph- enhanced meta-learning adaptive network for next poi recommendation. In2025 IEEE Interna- tional Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025. 10
2025
-
[15]
Onerec-v2 technical report.arXiv preprint arXiv:2508.20900, 2025
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900, 2025
-
[16]
A survey of generative recommendation from a tri-decoupled perspective: Tokenization, architecture, and optimization
Xiaopeng Li, Bo Chen, Junda She, Shiteng Cao, You Wang, Qinlin Jia, Haiying He, Zheli Zhou, Zhao Liu, Ji Liu, et al. A survey of generative recommendation from a tri-decoupled perspective: Tokenization, architecture, and optimization. 2025
2025
-
[17]
Align 3gr: Unified multi-level alignment for llm-based generative recommendation
Wencai Ye, Mingjie Sun, Shuhang Chen, Wenjin Wu, and Peng Jiang. Align 3gr: Unified multi-level alignment for llm-based generative recommendation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 16154–16162, 2026
2026
-
[18]
Generating long semantic ids in parallel for recom- mendation
Yupeng Hou, Jiacheng Li, Ashley Shin, Jinsung Jeon, Abhishek Santhanam, Wei Shao, Kaveh Hassani, Ning Yao, and Julian McAuley. Generating long semantic ids in parallel for recom- mendation. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 956–966, 2025
2025
-
[19]
Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5)
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). InRecSys, 2022
2022
-
[20]
Yongqi Li, Xinyu Lin, Wenjie Wang, Fuli Feng, Liang Pang, Wenjie Li, Liqiang Nie, Xiangnan He, and Tat-Seng Chua. A survey of generative search and recommendation in the era of large language models.arXiv preprint arXiv:2404.16924, 2024
-
[21]
Generative large recommendation models: Emerging trends in llms for recommendation
Hao Wang, Wei Guo, Luankang Zhang, Jin Yao Chin, Yufei Ye, Huifeng Guo, Yong Liu, Defu Lian, Ruiming Tang, and Enhong Chen. Generative large recommendation models: Emerging trends in llms for recommendation. InCompanion Proceedings of the ACM on Web Conference 2025, pages 49–52, 2025
2025
-
[22]
Wang-Cheng Kang and Julian J. McAuley. Self-attentive sequential recommendation. InICDM, 2018
2018
-
[23]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. InPro- ceedings of the 28th ACM international conference on information and knowledge management, pages 1441–1450, 2019
2019
-
[24]
Mtgr: Industrial-scale generative recommendation framework in meituan
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al. Mtgr: Industrial-scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 5731–5738, 2025
2025
-
[25]
Longer: Scaling up long sequence modeling in industrial recommenders
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems, pages 247–256, 2025
2025
-
[26]
Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender
Zhaoqi Zhang, Haolei Pei, Jun Guo, Tianyu Wang, Yufei Feng, Hui Sun, Shaowei Liu, and Aixin Sun. Onetrans: Unified feature interaction and sequence modeling with one transformer in industrial recommender. InProceedings of the ACM Web Conference 2026, pages 8162–8170, 2026
2026
-
[27]
Towards large-scale generative ranking.arXiv preprint arXiv:2505.04180, 2025
Yanhua Huang, Yuqi Chen, Xiong Cao, Rui Yang, Mingliang Qi, Yinghao Zhu, Qingchang Han, Yaowei Liu, Zhaoyu Liu, Xuefeng Yao, et al. Towards large-scale generative ranking.arXiv preprint arXiv:2505.04180, 2025
-
[28]
arXiv preprint arXiv:2409.12740 , year=
Junyi Chen, Lu Chi, Bingyue Peng, and Zehuan Yuan. Hllm: Enhancing sequential recom- mendations via hierarchical large language models for item and user modeling.arXiv preprint arXiv:2409.12740, 2024. 11
-
[29]
Unlocking scaling law in industrial recommendation systems with a three-step paradigm based large user model
Bencheng Yan, Shilei Liu, Zhiyuan Zeng, Zihao Wang, Yizhen Zhang, Yujin Yuan, Langming Liu, Jiaqi Liu, Di Wang, Wenbo Su, et al. Unlocking scaling law in industrial recommendation systems with a three-step paradigm based large user model. InProceedings of the Nineteenth ACM International Conference on Web Search and Data Mining, pages 798–807, 2026
2026
-
[30]
LLM-FE: Automated Feature Engineering for Tabular Data with LLMs as Evolutionary Optimizers
Nikhil Abhyankar, Parshin Shojaee, and Chandan K Reddy. Llm-fe: Automated feature engi- neering for tabular data with llms as evolutionary optimizers.arXiv preprint arXiv:2503.14434, 2025
work page internal anchor Pith review arXiv 2025
-
[31]
Optimized feature generation for tabular data via llms with decision tree reasoning.Advances in neural information processing systems, 37:92352–92380, 2024
Jaehyun Nam, Kyuyoung Kim, Seunghyuk Oh, Jihoon Tack, Jaehyung Kim, and Jinwoo Shin. Optimized feature generation for tabular data via llms with decision tree reasoning.Advances in neural information processing systems, 37:92352–92380, 2024
2024
-
[32]
Large language models make sample-efficient recommender systems.Frontiers of Computer Science, 19(4):194328, 2025
Jianghao Lin, Xinyi Dai, Rong Shan, Bo Chen, Ruiming Tang, Yong Yu, and Weinan Zhang. Large language models make sample-efficient recommender systems.Frontiers of Computer Science, 19(4):194328, 2025
2025
-
[33]
Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations. InInternational Conference on Machine Learning, pages 58484–58509. PMLR, 2024
2024
-
[34]
Generative recommender with end-to-end learnable item tokenization
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. Generative recommender with end-to-end learnable item tokenization. InProceedings of the 48th Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pages 729–739, 2025
2025
-
[35]
Guorui Zhou, Honghui Bao, Jiaming Huang, Jiaxin Deng, Jinghao Zhang, Junda She, Kuo Cai, Lejian Ren, Lu Ren, Qiang Luo, et al. Openonerec technical report.arXiv preprint arXiv:2512.24762, 2025
-
[36]
Onesug: The unified end-to-end generative framework for e-commerce query suggestion
Xian Guo, Ben Chen, Siyuan Wang, Ying Yang, Mingyue Cheng, Chenyi Lei, Yuqing Ding, and Han Li. Onesug: The unified end-to-end generative framework for e-commerce query suggestion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 14774–14782, 2026
2026
-
[37]
One model, two markets: Bid-aware generative recommendation.arXiv preprint arXiv:2603.22231, 2026
Yanchen Jiang, Zhe Feng, Christopher P Mah, Aranyak Mehta, and Di Wang. One model, two markets: Bid-aware generative recommendation.arXiv preprint arXiv:2603.22231, 2026
-
[38]
Yunsheng Pang, Zijian Liu, Yudong Li, Shaojie Zhu, Zijian Luo, Chenyun Yu, Sikai Wu, Shichen Shen, Cong Xu, Bin Wang, et al. Higr: Efficient generative slate recommendation via hierar- chical planning and multi-objective preference alignment.arXiv preprint arXiv:2512.24787, 2025
-
[39]
Sayak Chakrabarty and Souradip Pal. Pixrec: Leveraging visual context for next-item prediction in sequential recommendation.arXiv preprint arXiv:2601.06458, 2026
-
[40]
Plum: Adapting pre-trained language models for industrial-scale generative recommendations
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al. Plum: Adapting pre-trained language models for industrial-scale generative recommendations. InProceedings of the ACM Web Conference 2026, pages 8093–8104, 2026
2026
-
[41]
Entire space multi-task model: An effective approach for estimating post-click conversion rate
Xiao Ma, Liqin Zhao, Guan Huang, Zhi Wang, Zelin Hu, Xiaoqiang Zhu, and Kun Gai. Entire space multi-task model: An effective approach for estimating post-click conversion rate. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pages 1137–1140, 2018
2018
-
[42]
Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. InProceedings of the 14th ACM conference on recommender systems, pages 269–278, 2020. 12
2020
-
[43]
Mmoe: Enhancing multimodal models with mixtures of multi- modal interaction experts
Haofei Yu, Zhengyang Qi, Lawrence Keunho Jang, Russ Salakhutdinov, Louis-Philippe Morency, and Paul Pu Liang. Mmoe: Enhancing multimodal models with mixtures of multi- modal interaction experts. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 10006–10030, 2024
2024
-
[44]
Residual multi-task learner for applied ranking
Cong Fu, Kun Wang, Jiahua Wu, Yizhou Chen, Guangda Huzhang, Yabo Ni, Anxiang Zeng, and Zhiming Zhou. Residual multi-task learner for applied ranking. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 4974–4985, 2024
2024
-
[45]
Hinet: Novel multi-scenario & multi-task learning with hierarchical information extraction
Jie Zhou, Xianshuai Cao, Wenhao Li, Lin Bo, Kun Zhang, Chuan Luo, and Qian Yu. Hinet: Novel multi-scenario & multi-task learning with hierarchical information extraction. In2023 IEEE 39th International Conference on Data Engineering (ICDE), pages 2969–2975. IEEE, 2023
2023
-
[46]
Xiaoyu Kong, Leheng Sheng, Junfei Tan, Yuxin Chen, Jiancan Wu, An Zhang, Xiang Wang, and Xiangnan He. Minionerec: An open-source framework for scaling generative recommendation. arXiv preprint arXiv:2510.24431, 2025
-
[47]
McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel
Julian J. McAuley, Christopher Targett, Qinfeng Shi, and Anton van den Hengel. Image-based recommendations on styles and substitutes. InSIGIR, 2015
2015
-
[48]
switch modes
Kun Zhou, Hui Wang, Wayne Xin Zhao, Yutao Zhu, Sirui Wang, Fuzheng Zhang, Zhongyuan Wang, and Ji-Rong Wen. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. InCIKM, 2020. A Experimental Setup Datasets.We conduct experiments on three real-world public datasets from Amazon Product Reviews [47]:Beauty,Sports...
2020
-
[49]
CMSA preprocessing.For each item image, we generate a concise but semantically rich textual description with Qwen2.5-VL
-
[50]
MDIM preprocessing.We concatenate title, description, and the CMSA caption, and then use Qwen2.5-7B-Instruct to mine 2–4 deep interest tags per item
-
[51]
We then train the RQ-V AE tokenizer offline with 3 quantization levels and codebook sizes of 4096, 2048, and 1024, and generate fixed SID targets for all items
RQ-V AE fitting.We encode each item using gme-Qwen2-VL, which jointly processes the enriched text (title, description, CMSA caption, MDIM interests) and the original product image to produce a unified multimodal embedding. We then train the RQ-V AE tokenizer offline with 3 quantization levels and codebook sizes of 4096, 2048, and 1024, and generate fixed ...
2048
-
[52]
The CMSA captions, MDIM interests, and SID targets are cached offline and reused during training
Multitask fine-tuning.We jointly train the LLM on all eight tasks using a single autoregressive cross-entropy loss with uniform task sampling. The CMSA captions, MDIM interests, and SID targets are cached offline and reused during training. This keeps the recommendation training loop stable and avoids repeated calls to the VLM/LLM preprocessing modules. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.