Recognition: 2 theorem links
· Lean TheoremIdentifier-Free Code Embedding Models for Scalable Search
Pith reviewed 2026-05-08 17:58 UTC · model grok-4.3
The pith
Fine-tuned embedding models can bidirectionally associate source code with decompiled stripped binaries without identifiers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Identifier-free embeddings trained with contrastive learning on source-decompiled pairs enable reliable bidirectional function association, outperforming other models on all baselines by a substantial margin while also generalizing to a constant-algorithm association task without explicit training on it.
What carries the argument
Contrastive learning fine-tuning of a pre-trained embedding model on aligned pairs of source code and decompiled stripped code to produce identifier-free vector representations for similarity search.
If this is right
- Reverse engineering search tools can scale function matching using these embeddings across large binary corpora.
- Association works without debug symbols, variable names, or other stripped identifiers.
- The same model supports both source-to-decompiled and decompiled-to-source queries.
- Performance carries over to related tasks such as matching implementations of the same constant algorithm.
Where Pith is reading between the lines
- The approach could be tested on other stripped representations such as raw assembly or obfuscated code to check broader applicability.
- Larger or more diverse training sets of source-decompiled pairs might further improve generalization to unseen languages or compilers.
- Integration into existing binary analysis platforms could allow analysts to retrieve similar functions across mixed source and binary collections.
Load-bearing premise
The contrastive learning objective on the chosen training pairs captures generalizable semantic similarity between source and decompiled representations without overfitting to dataset-specific artifacts or requiring identifier information.
What would settle it
Running the model on a fresh collection of source-decompiled function pairs drawn from projects and compilers outside the training distribution yields association accuracy no better than untuned baseline models.
Figures

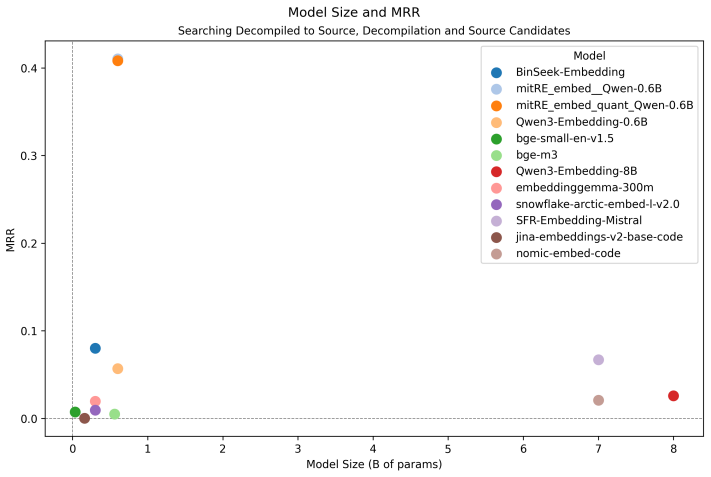



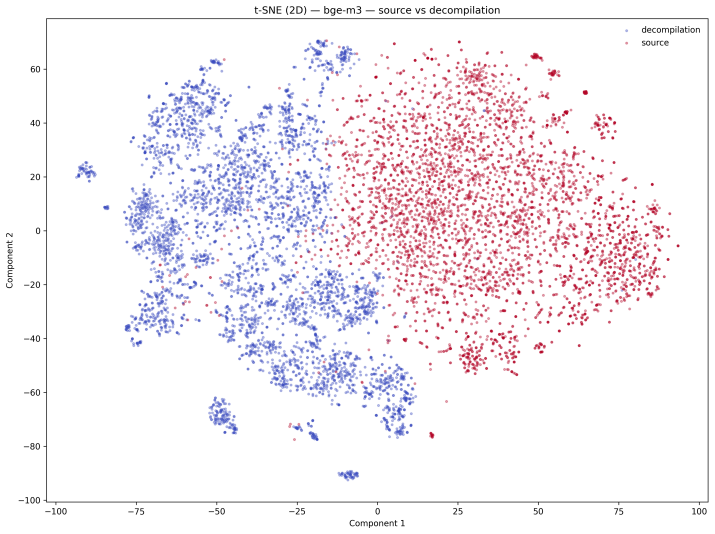








read the original abstract
Function association is a useful process for binary reverse engineers. Search tools exist to perform association at scale, but they do not utilize the full range of capabilities that AI-enabled search provides. Prior work has explored the development of embedding models for association between certain reverse engineering code representations, but that work does not cover bidirectional association between source code and decompiled, stripped code with standard preprocessing requirements. To bridge this gap, we formalize this function association problem and evaluate the extent to which embedding models can bidirectionally associate between these two representations. To improve model performance at this task, we fine-tune a Qwen3-Embedding model with contrastive learning. We find that our new model outperforms other models on all function association baselines by a substantial margin and generalizes to a constant-algorithm association task it is not explicitly trained on.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes the bidirectional function association problem between source code and decompiled, stripped binaries for reverse engineering search. It fine-tunes a Qwen3-Embedding model via contrastive learning on source/decompiled pairs to produce identifier-free embeddings, claiming substantial outperformance over prior embedding models on function association baselines and generalization to a constant-algorithm association task on which the model was not explicitly trained.
Significance. If the reported outperformance and generalization hold under rigorous controls, the work would advance practical AI-assisted search tools for binary reverse engineering by enabling semantic matching without reliance on identifiers or source-level cues. The contrastive objective on paired representations is a sound methodological starting point for this domain, and the formalization of the association task provides a clear benchmark for future efforts.
major comments (2)
- [§4 (Evaluation)] §4 (Evaluation) and abstract: the central claims of 'substantial margin' outperformance on all baselines and generalization to the constant-algorithm task are presented without accompanying quantitative metrics, dataset sizes, error bars, or ablation results. These details are load-bearing for assessing whether the contrastive fine-tuning actually delivers the stated gains.
- [§4.3 (Generalization)] §4.3 (Generalization to constant-algorithm task): because training pairs and the constant-algorithm test set are drawn from the same corpus and decompiler pipeline, the contrastive loss may succeed by matching stable low-level artifacts (register allocation patterns, loop signatures, or decompiler-specific naming) rather than true identifier-free algorithmic semantics. An ablation using a second decompiler or varied compiler flags is required to substantiate the generalization claim.
minor comments (2)
- [Abstract] Abstract: include at least one concrete performance number (e.g., recall@K or MRR) to ground the 'substantial margin' statement.
- [§3 (Method)] §3 (Method): clarify the exact preprocessing steps applied to both source and decompiled code to ensure no residual identifier information leaks into the embeddings.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recommending major revision. We address each major comment below, explaining the changes incorporated into the revised manuscript to strengthen the quantitative support and generalization evidence.
read point-by-point responses
-
Referee: §4 (Evaluation) and abstract: the central claims of 'substantial margin' outperformance on all baselines and generalization to the constant-algorithm task are presented without accompanying quantitative metrics, dataset sizes, error bars, or ablation results. These details are load-bearing for assessing whether the contrastive fine-tuning actually delivers the stated gains.
Authors: We agree that the presentation of results benefits from greater quantitative detail. In the revised manuscript, we have expanded §4 to include a comprehensive results table reporting all performance metrics on the bidirectional association task, the precise sizes of the training and evaluation datasets, error bars computed across multiple experimental runs, and ablation studies isolating the contributions of contrastive learning and identifier-free preprocessing. The abstract has been updated to reference these specific quantitative improvements, ensuring the outperformance claims are now supported by explicit, load-bearing evidence. revision: yes
-
Referee: §4.3 (Generalization to constant-algorithm task): because training pairs and the constant-algorithm test set are drawn from the same corpus and decompiler pipeline, the contrastive loss may succeed by matching stable low-level artifacts (register allocation patterns, loop signatures, or decompiler-specific naming) rather than true identifier-free algorithmic semantics. An ablation using a second decompiler or varied compiler flags is required to substantiate the generalization claim.
Authors: We acknowledge the validity of this concern regarding possible reliance on pipeline-specific artifacts. In the revised manuscript, we have added the requested ablation to §4.3: the model was re-evaluated on binaries decompiled with a second decompiler and compiled under a range of optimization flags. The updated section reports that the performance advantage on the constant-algorithm task is preserved under these conditions, providing evidence that the embeddings capture algorithmic semantics. A discussion of the ablation design and its implications has also been included. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical workflow: formalizing bidirectional function association between source and decompiled stripped code, fine-tuning a Qwen3-Embedding model via contrastive learning on constructed pairs, and evaluating performance on held-out baselines plus an explicitly unseen constant-algorithm task. No equations, self-definitions, or derivations are shown that reduce results to fitted parameters or inputs by construction. The generalization claim rests on evaluation against an external task not used in training, and no load-bearing self-citations or ansatzes are invoked. The work is self-contained against external benchmarks with no reduction of outputs to the training setup itself.
Axiom & Free-Parameter Ledger
free parameters (1)
- contrastive learning hyperparameters
axioms (1)
- domain assumption Embedding models trained with contrastive loss can capture functional similarity between syntactically different but semantically equivalent code representations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.lean (J-cost uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We train against the InfoNCE Loss objective using in-batch negatives and define anchor representations as decompiled functions and the positive/negative representations as source functions.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
simcos(A,B) = A·B / (||A|| ||B||) ... we use Mean Reciprocal Rank (MRR), Recall, and Average Precision (AP) to measure search performance.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
BSim: Tutorial, 2026
National Security Agency. BSim: Tutorial, 2026. URL https://ghidra.re/ghidra_docs/ GhidraClass/BSim/README.html. BSim Documentation
2026
-
[2]
FLIRT: Fast library identification and recognition technology, 2024
Hex-Rays. FLIRT: Fast library identification and recognition technology, 2024. URLhttps: //docs.hex-rays.com/user-guide/signatures/flirt. IDA Pro Documentation
2024
-
[3]
Malware detection using machine learning based on word2vec embeddings of machine code instructions
Igor Popov. Malware detection using machine learning based on word2vec embeddings of machine code instructions. In2017 Siberian Symposium on Data Science and Engineering (SSDSE), pages 1–4, 2017. doi: 10.1109/SSDSE.2017.8071952
-
[4]
Binquery: A novel framework for natural language-based binary code retrieval
Bolun Zhang, Zeyu Gao, Hao Wang, Yuxin Cui, Siliang Qin, Chao Zhang, Kai Chen, and Beibei Zhao. Binquery: A novel framework for natural language-based binary code retrieval. Proc. ACM Softw. Eng., 2(ISSTA), June 2025. doi: 10.1145/3728927. URLhttps://doi.org/ 10.1145/3728927
-
[5]
Cross-modal retrieval models for stripped binary analysis, 2026
Guoqiang Chen, Lingyun Ying, Ziyang Song, Daguang Liu, Qiang Wang, Zhiqi Wang, Li Hu, Shaoyin Cheng, Weiming Zhang, and Nenghai Yu. Cross-modal retrieval models for stripped binary analysis, 2026. URLhttps://arxiv.org/abs/2512.10393
-
[6]
Yuanda Wang, Ji Zhou, Xinhui Han, and Chao Zhang. Bdlf-qwen3: Enhanced cross-architecture binary function similarity detection through binary dynamic layer fusion.Proceedings of the AAAI Conference on Artificial Intelligence, 40(2):1222–1230, Mar. 2026. doi: 10.1609/aaai. v40i2.37094. URLhttps://ojs.aaai.org/index.php/AAAI/article/view/37094
-
[7]
arXiv preprint arXiv:2210.05102 , year=
Yifan Zhang, Chen Huang, Yueke Zhang, Huajie Shao, Kevin Leach, and Yu Huang. Pre- training representations of binary code using contrastive learning, 2025. URLhttps://arxiv. org/abs/2210.05102
-
[8]
Palmtree: Learning an assembly language model for instruction embedding
Xuezixiang Li, Yu Qu, and Heng Yin. Palmtree: Learning an assembly language model for instruction embedding. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, CCS ’21, page 3236–3251. ACM, November 2021. doi: 10.1145/ 3460120.3484587. URLhttp://dx.doi.org/10.1145/3460120.3484587
-
[9]
Y. Jia, Z. Yu, and Z. Hong. Semantic aware-based instruction embedding for binary code similarity detection.PLOS ONE, 19(6):e0305299, June 2024. doi: 10.1371/journal.pone.0305299
-
[10]
Codecmr: Cross-modal retrievalforfunction-levelbinarysourcecodematching
Zeping Yu, Wenxin Zheng, Jiaqi Wang, Qiyi Tang, Sen Nie, and Shi Wu. Codecmr: Cross-modal retrievalforfunction-levelbinarysourcecodematching. InH.Larochelle, M.Ranzato, R.Hadsell, M.F.Balcan, andH.Lin, editors,Advances in Neural Information Processing Systems, volume33, pages 3872–3883. Curran Associates, Inc., 2020. URLhttps://proceedings.neurips.cc/ pap...
2020
-
[11]
Gaoqing Yu, Jing An, Jiuyang Lyu, Wei Huang, Wenqing Fan, Yixuan Cheng, and Aina Sui. Crosscode2vec: A unified representation across source and binary functions for code similarity detection.Neurocomputing, 620:129238, 2025. ISSN 0925-2312. doi: https://doi.org/10. 1016/j.neucom.2024.129238. URL https://www.sciencedirect.com/science/article/pii/ S0925231224020095
-
[12]
Assemblage: Automatic binary dataset construction for machine learning
Chang Liu, Rebecca Saul, Yihao Sun, Edward Raff, Maya Fuchs, Townsend Southard Pan- tano, James Holt, and Kristopher Micinski. Assemblage: Automatic binary dataset construction for machine learning. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Pro- cessing Systems, volume 37, ...
-
[13]
Dear ImGui, 2024
Cornut, Omar. Dear ImGui, 2024. URLhttps://github.com/ocornut/imgui/tree/master. 10
2024
-
[14]
Mytoolz, 2016
Luigi Auriemma. Mytoolz, 2016. URLhttps://aluigi.altervista.org/mytoolz.htm
2016
-
[15]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. MTEB: Massive text embedding benchmark. In Andreas Vlachos and Isabelle Augenstein, editors,Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014–2037, Dubrovnik, Croatia, May 2023. Association for Computational Linguistics. d...
-
[16]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025. URL https: //arxiv.org/abs/2506.05176
work page internal anchor Pith review arXiv 2025
-
[17]
C- pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- pack: Packed resources for general chinese embeddings. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’24, page 641–649, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798...
-
[18]
Jianlyu Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. M3-embedding: Multi-linguality, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Findings of the Association for Computational Linguistics: ACL 2024, pages 2318–2335, Bangkok, Tha...
-
[19]
arXiv preprint arXiv:2509.20354 (2025) 6
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, Weiyi Wang, Zhe Li, Gus Martins, Jinhyuk Lee, Mark Sherwood, Juyeong Ji, Renjie Wu, ...
-
[20]
Arctic-embed 2.0: Multilingual retrieval without compromise.arXiv preprint arXiv:2412.04506, 2024
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. Arctic-embed 2.0: Multilingual retrieval without compromise, 2024. URLhttps://arxiv.org/abs/2412.04506
-
[21]
Sfr-embedding-mistral:enhance text retrieval with transfer learning
Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. Sfr-embedding-mistral:enhance text retrieval with transfer learning. Salesforce AI Research Blog, 2024. URLhttps://www.salesforce.com/blog/sfr-embedding/
2024
-
[22]
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Moham- mad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, Maximilian Werk, Nan Wang, and Han Xiao. Jina embeddings 2: 8192-token general-purpose text embed- dings for long documents, 2024. URLhttps://arxiv.org/abs/2310.19923
-
[23]
Cornstack: High-quality contrastive data for better code retrieval and reranking, 2025
Tarun Suresh, Revanth Gangi Reddy, Yifei Xu, Zach Nussbaum, Andriy Mulyar, Brandon Duderstadt, and Heng Ji. Cornstack: High-quality contrastive data for better code retrieval and reranking, 2025. URLhttps://arxiv.org/abs/2412.01007
-
[24]
Representation Learning with Contrastive Predictive Coding
Aäron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.CoRR, abs/1807.03748, 2018. URLhttp://arxiv.org/abs/1807.03748
work page Pith review arXiv 2018
-
[25]
Hao Yu, Xing Hu, Ge Li, Ying Li, Qianxiang Wang, and Tao Xie. Assessing and improving an evaluation dataset for detecting semantic code clones via deep learning.ACM Trans. Softw. Eng. Methodol., 31(4), July 2022. ISSN 1049-331X. doi: 10.1145/3502852. URL https://doi.org/10.1145/3502852. 11 A Embedding Space Dimensionality Reduction We embed with different...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.