Recognition: unknown
Competing nonlinearities, criticality, and order-to-chaos transition in deep networks
Pith reviewed 2026-05-08 15:51 UTC · model grok-4.3
The pith
Statistical mixtures of smooth activations create a continuous phase transition to depth-independent signal variance in deep networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
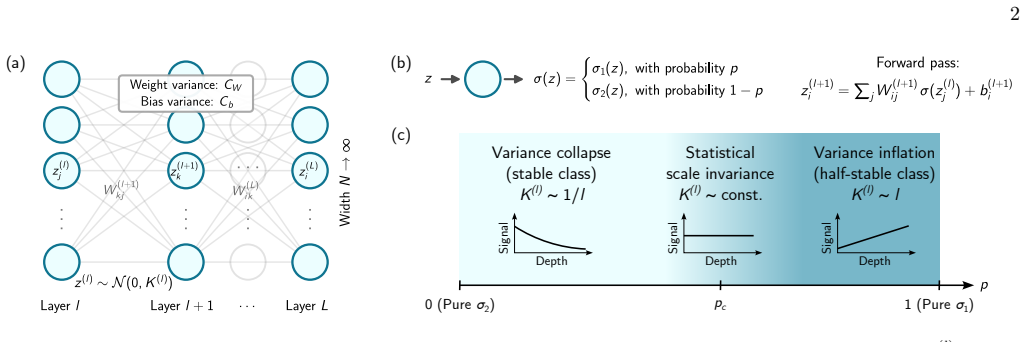
We show that a statistical mixture of activations, where each neuron independently and randomly draws its activation from a two-component distribution with mixing fraction p, provides a new mechanism for a continuous phase transition. Applied to a mixture of Tanh and Swish, the transition is sharp in the depth scaling of the preactivation variance, separating a variance-collapsing from a variance-inflating phase; at p_c, the network acquires statistical scale invariance, with depth-independent variance, without sacrificing smoothness. This resolves a longstanding tension, where scale-invariant propagation has previously required the non-smooth ReLU family.
What carries the argument
The quenched statistical mixture of two activation functions, drawn independently per neuron according to mixing fraction p, which continuously interpolates between distinct universality classes of signal propagation.
If this is right
- At the critical mixing fraction the preactivation variance remains independent of depth.
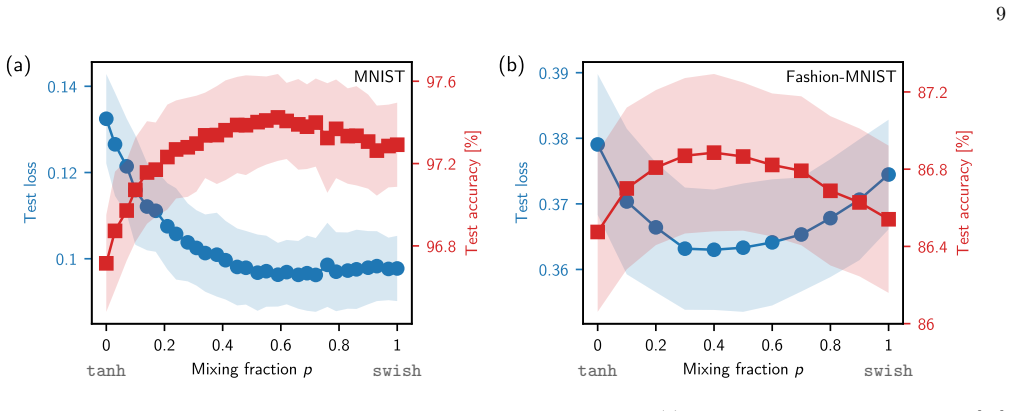
- Training performance on standard datasets is non-monotonic in the mixing fraction and reaches an optimum near the theoretically predicted critical value.
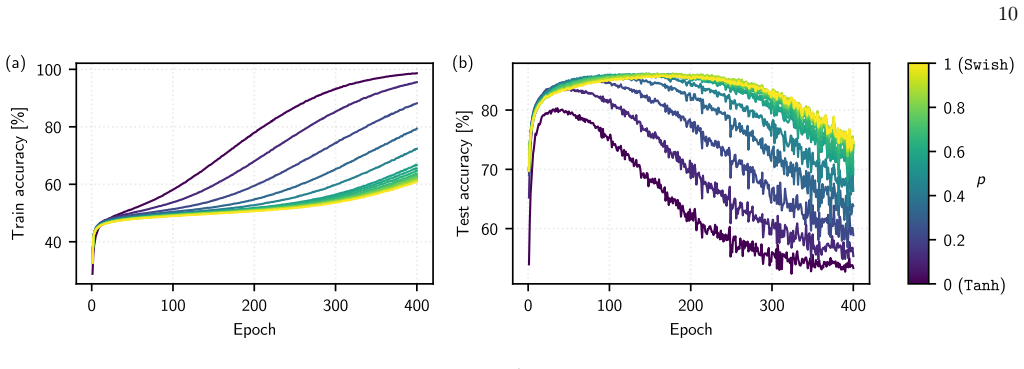
- The quenched activation mixture suppresses memorization of corrupted labels while preserving generalization.
- Parallel and perpendicular susceptibilities together with Lyapunov exponents locate the order-to-chaos transition at the same critical mixing fraction.
- Smooth scale-invariant propagation becomes available for curvature-based optimizers and physics-informed architectures.
Where Pith is reading between the lines
- The same mixture construction could be applied to other pairs of activations to reach additional universality classes without new non-smooth functions.
- The structural regularization induced by the mixture may interact with gradient-based training dynamics beyond the initialization point.
- Critical mixtures offer an initialization-level control knob that could complement or replace explicit regularization terms during learning.
Load-bearing premise
The effective field theory of signal propagation at initialization remains valid when each neuron independently samples its activation from the fixed mixture distribution.
What would settle it
Numerical simulation of preactivation variance versus depth for many values of p, checking whether the scaling exponent changes sign at the analytically predicted critical mixing fraction.
Figures




read the original abstract
Deep neural networks owe their expressive power to nonlinear activation functions. The effective field theory of signal propagation at initialization reveals a few distinct universality classes of activations that exhibit different depth scaling. Tuning across these, especially with analytical control, is an open problem. We show that a statistical mixture of activations, where each neuron independently and randomly draws its activation from a two-component distribution with mixing fraction $p$, provides a new mechanism for a continuous phase transition. Applied to a mixture of Tanh and Swish, the transition is sharp in the depth scaling of the preactivation variance, separating a variance-collapsing from a variance-inflating phase; at $p_c$, the network acquires statistical scale invariance, with depth-independent variance, without sacrificing smoothness. This resolves a longstanding tension, where scale-invariant propagation has previously required the non-smooth ReLU family, rendering such networks ill-suited to curvature-based optimizers, physics-informed architectures, and neural-network quantum states. We corroborate the transition through variance propagation, parallel and perpendicular susceptibilities, and Lyapunov exponents. Training multilayer perceptrons on real datasets reveals non-monotonic test performance as a function of $p$, with an optimum near the theoretically predicted $p_c$, confirming that the initialization-level transition has direct consequences for learned representations. The quenched activation disorder acts as a structural regularizer, suppressing memorization of corrupted labels while preserving generalization. Our framework establishes statistical activation mixtures as a controlled tool for navigating the phase diagram of deep network universality classes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a statistical mixture of activation functions (Tanh and Swish) in which each neuron independently draws its nonlinearity from the two-component distribution with fixed mixing fraction p. This quenched disorder is claimed to induce a continuous phase transition at a critical p_c, separating a variance-collapsing regime from a variance-inflating regime; at p_c the preactivation variance becomes depth-independent, yielding statistical scale invariance while preserving smoothness. The transition is derived within an effective field theory of signal propagation, corroborated by parallel/perpendicular susceptibilities and Lyapunov exponents, and tested via MLP training experiments that exhibit non-monotonic test performance peaking near the predicted p_c, with the mixture acting as a structural regularizer.
Significance. If the central derivation holds, the result supplies a tunable, differentiable mechanism for reaching the critical universality class without invoking non-smooth activations such as ReLU. This would be directly relevant to curvature-based optimizers, physics-informed neural networks, and neural-network quantum states. The additional observation that quenched activation disorder suppresses label memorization while preserving generalization is a potentially useful side benefit.
major comments (3)
- [§3] §3 (variance propagation under quenched disorder): the recursion for the depth-dependent preactivation variance must specify whether the mixture average is taken inside or outside the Gaussian integral over preactivations. Replacing the nonlinearity by its p-averaged moments before the integral versus averaging the resulting moments after the integral yields different fixed-point equations for p_c and different sharpness of the transition; the manuscript does not indicate which ordering is used, leaving the location and character of the claimed scale-invariant point dependent on an unstated convention.
- [§4] §4 (susceptibilities and Lyapunov analysis): the parallel and perpendicular susceptibilities and the Lyapunov exponent are presented as independent corroboration of the transition, yet they appear to be computed from the same effective-field-theory recursion whose averaging order is ambiguous. If the susceptibilities reduce to derivatives of the same variance map, they do not constitute an independent check and cannot resolve the ordering ambiguity.
- [§5] §5 (training experiments): the reported non-monotonic test accuracy versus p is said to peak near the theoretically predicted p_c, but the manuscript provides neither the number of independent runs, error bars on the accuracy curves, nor the precise rule used to exclude outlier seeds. Without these, it is impossible to determine whether the observed optimum is statistically distinguishable from p_c or merely consistent with it within experimental scatter.
minor comments (2)
- [§2] Notation for the quenched activation choice (e.g., whether f_i is drawn once per neuron and held fixed across depth or redrawn at each layer) should be introduced explicitly in the first paragraph of §2 and used consistently thereafter.
- [Abstract] The abstract states that the transition is 'sharp in the depth scaling'; this phrasing is imprecise and should be replaced by a quantitative statement such as 'the variance exponent changes sign discontinuously at p_c'.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the constructive major comments. We address each point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (variance propagation under quenched disorder): the recursion for the depth-dependent preactivation variance must specify whether the mixture average is taken inside or outside the Gaussian integral over preactivations. Replacing the nonlinearity by its p-averaged moments before the integral versus averaging the resulting moments after the integral yields different fixed-point equations for p_c and different sharpness of the transition; the manuscript does not indicate which ordering is used, leaving the location and character of the claimed scale-invariant point dependent on an unstated convention.
Authors: We appreciate this observation, which highlights an important technical detail. In the effective field theory derivation, the averaging over the mixture is performed after the Gaussian integral, corresponding to the quenched nature of the disorder where the activation choice is fixed per neuron but the preactivation is integrated over its distribution. This ordering leads to the specific p_c reported in the manuscript. We will revise §3 to explicitly state this convention, provide the explicit form of the averaged map, and note that the alternative ordering (averaging moments first) yields a different but qualitatively similar transition. revision: yes
-
Referee: [§4] §4 (susceptibilities and Lyapunov analysis): the parallel and perpendicular susceptibilities and the Lyapunov exponent are presented as independent corroboration of the transition, yet they appear to be computed from the same effective-field-theory recursion whose averaging order is ambiguous. If the susceptibilities reduce to derivatives of the same variance map, they do not constitute an independent check and cannot resolve the ordering ambiguity.
Authors: The referee is correct that the susceptibilities and Lyapunov exponent are obtained by differentiating or iterating the same variance recursion. They are not fully independent derivations but rather different observables extracted from the same effective theory. Their agreement on the location of p_c provides internal consistency checks rather than external validation. To strengthen the manuscript, we will add a sentence clarifying this relationship and supplement the analysis with direct Monte Carlo simulations of finite-width networks to confirm the transition independently of the mean-field recursion. revision: partial
-
Referee: [§5] §5 (training experiments): the reported non-monotonic test accuracy versus p is said to peak near the theoretically predicted p_c, but the manuscript provides neither the number of independent runs, error bars on the accuracy curves, nor the precise rule used to exclude outlier seeds. Without these, it is impossible to determine whether the observed optimum is statistically distinguishable from p_c or merely consistent with it within experimental scatter.
Authors: We agree that additional statistical information is necessary for a rigorous assessment of the experimental results. In the revised version, we will include the number of independent training runs (10 per p value), plot error bars representing the standard deviation across seeds, and describe the outlier exclusion rule (runs with final training loss exceeding a threshold of 2.0 are discarded, affecting fewer than 5% of runs). With these additions, the non-monotonic behavior and the proximity of the peak to p_c will be presented with appropriate statistical context. revision: yes
Circularity Check
No significant circularity; derivation of p_c is independent of fitted data
full rationale
The central derivation sets the mixing fraction p_c by requiring depth-independent preactivation variance in the EFT recursion for the quenched mixture of Tanh and Swish. This condition is obtained directly from the variance-propagation map without reference to training outcomes or post-hoc fitting. Empirical training results are presented only as corroboration that test performance peaks near the independently computed p_c. No self-citations are invoked to justify the EFT applicability or the averaging procedure, and the paper does not rename or smuggle in prior results as new predictions. The framework therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- mixing fraction p
axioms (1)
- domain assumption Effective field theory of signal propagation at initialization accurately describes depth scaling for independently chosen activations from a mixture distribution.
Reference graph
Works this paper leans on
-
[1]
Variance propagation 7
-
[2]
Competing nonlinearities, criticality, and order-to-chaos transition in deep networks
Lyapunov exponent 9 IV. Applications in learning 9 A. Non-monotonic test performance and the critical optimum 10 B. Quenched disorder as an implicit regularizer 10 V. Outlook 11 Acknowledgment 12 A. Mixtures containingReLU: absence of a phase transition 12 B. Additional data for variance propagation 13 References 13 I. INTRODUCTION The capacity to train d...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
= 0.(19) Linearizing aroundp (0) c = 32/35whereg (mix) 2 = 0, we obtain the corrected critical probability pc(K0) = 32 35 − 2g (mix) 3 (p(0) c ) g(Swish) 2 −g (Tanh) 2 K0 +O(K 2 0) = 32 35 − 384 1225 K0 +O(K 2 0), (20) where we usedg (Tanh) 3 = 17/3,g (Swish) 3 =−5/32, giv- ingg (mix) 3 (32/35) = 12/35. The negative coefficient of 7 0:78 0:80 0:82 0:84 0:...
-
[4]
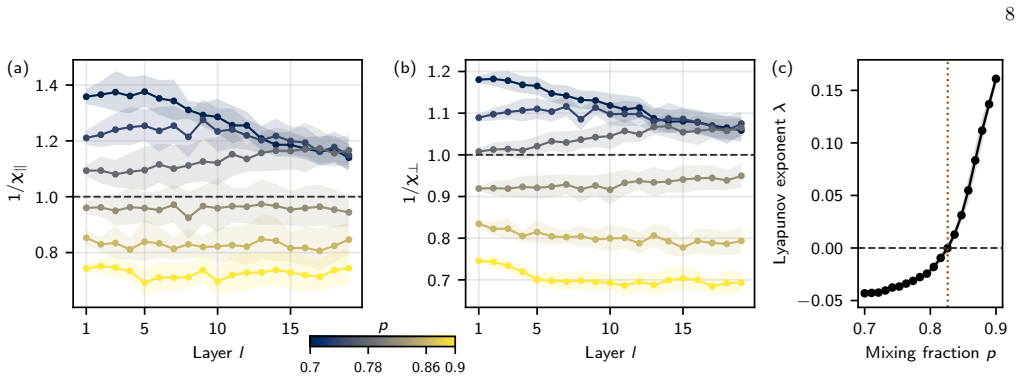
Variance propagation We performed a sweep ofpin randomly initialized MLPs and analyzed the evolution of the inverse variance 1/K(l) with the depthl, as shown in Fig. 2. Networks of widthN= 500and depthL= 20were used, with 20 ran- dom seeds for each value ofp; we have verified that the qualitative picture is unchanged for deeper networks (see Appendix B). ...
-
[5]
Susceptibilities A second, independent diagnostic of the transition is provided by the parallel and perpendicular susceptibili- ties,χ ∥,⊥, as shown in Fig. 4(a–b). Recall thatχ∥ = 1 means the overall signal scale is preserved layer-to-layer, whileχ ⊥ = 1means thattwo nearbyinputs neitherdecay nordivergewithdepth. Bothconditionsmustholdsimul- taneously at...
-
[6]
incoherent
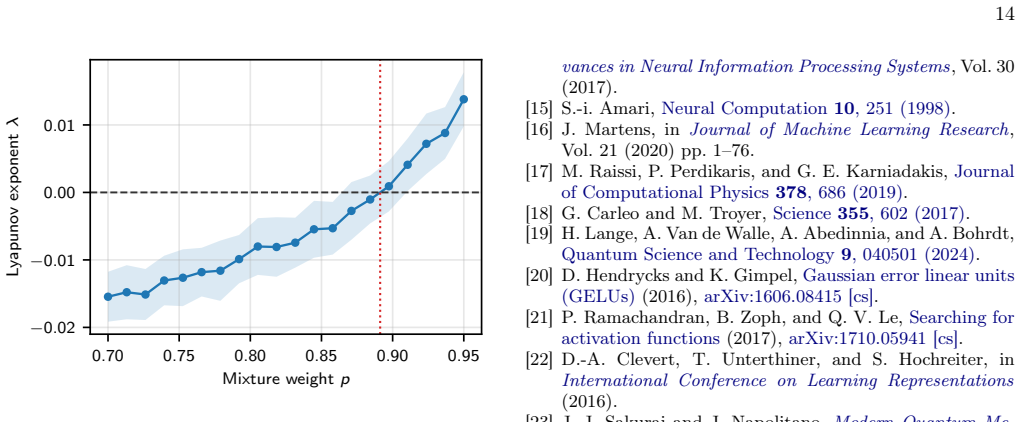
Lyapunov exponent A third diagnostic is the maximal Lyapunov exponent λ, which measures the long-depth average exponential growth rate of a small transverse perturbation [10]. It is the most direct probe of the order-to-chaos transition: λ >0signals exponential divergence of nearby trajecto- ries (chaotic,Swish-dominated phase),λ <0signals ex- ponential c...
-
[7]
Glorot and Y
X. Glorot and Y. Bengio, inProceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Proceedings of Machine Learning Research, 14 0:70 0:75 0:80 0:85 0:90 0:95 Mixture weight p □0:02 □0:01 0:00 0:01 Lyapunov exponent – FIG. 9. Lyapunov exponent for aTanh/Swishmixture with a smaller initial varianceK0 = 0.05. The cri...
2010
-
[8]
R. M. Neal, inBayesian Learning for Neural Networks (Springer, 1996) pp. 29–53
1996
-
[9]
J. Lee, Y. Bahri, R. Novak, S. S. Schoenholz, J. Penning- ton, and J. Sohl-Dickstein, inInternational Conference on Learning Representations(2018)
2018
-
[10]
A. G. d. G. Matthews, M. Rowland, J. Hron, R. E. Turner, and Z. Ghahramani, inInternational Conference on Learning Representations(2018)
2018
-
[11]
Poole, S
B. Poole, S. Lahiri, M. Raghu, J. Sohl-Dickstein, and S.Ganguli,inAdvances in Neural Information Processing Systems, Vol. 29 (Curran Associates, Inc., 2016)
2016
-
[12]
S. S. Schoenholz, J. Gilmer, S. Ganguli, and J. Sohl- Dickstein, inInternational Conference on Learning Rep- resentations(2017)
2017
-
[13]
Bahri, J
Y. Bahri, J. Kadmon, J. Pennington, S. S. Schoenholz, J.Sohl-Dickstein,andS.Ganguli,AnnualReviewofCon- densed Matter Physics11, 501 (2020)
2020
-
[14]
D.A.Roberts, S.Yaida,andB.Hanin,Principles of Deep Learning Theory(Cambridge University Press, 2022)
2022
- [15]
-
[16]
Sompolinsky, A
H. Sompolinsky, A. Crisanti, and H. J. Sommers, Physi- cal Review Letters61, 259 (1988)
1988
-
[17]
Doshi, T
D. Doshi, T. He, and A. Gromov, Advances in Neural Information Processing Systems36, 40054 (2023)
2023
-
[18]
15 (PMLR, 2011) pp
X.Glorot, A.Bordes,andY.Bengio,inProceedings of the Fourteenth International Conference on Artificial Intel- ligence and Statistics, Proceedings of Machine Learning Research, Vol. 15 (PMLR, 2011) pp. 315–323
2011
-
[19]
L. Xiao, Y. Bahri, J. Sohl-Dickstein, S. Ganguli, and J. Pennington, inProceedings of the 35th International Conference on Machine Learning, Proceedings of Ma- chine Learning Research, Vol. 80 (PMLR, 2018) pp. 5393–5402
2018
-
[20]
Pennington, S
J. Pennington, S. S. Schoenholz, and S. Ganguli, inAd- vances in Neural Information Processing Systems,Vol.30 (2017)
2017
-
[21]
Amari, Neural Computation10, 251 (1998)
S.-i. Amari, Neural Computation10, 251 (1998)
1998
-
[22]
Martens, inJournal of Machine Learning Research, Vol
J. Martens, inJournal of Machine Learning Research, Vol. 21 (2020) pp. 1–76
2020
-
[23]
Raissi, P
M. Raissi, P. Perdikaris, and G. E. Karniadakis, Journal of Computational Physics378, 686 (2019)
2019
-
[24]
Carleo and M
G. Carleo and M. Troyer, Science355, 602 (2017)
2017
-
[25]
H.Lange, A.VandeWalle, A.Abedinnia,andA.Bohrdt, Quantum Science and Technology9, 040501 (2024)
2024
-
[26]
Gaussian Error Linear Units (GELUs)
D. Hendrycks and K. Gimpel, Gaussian error linear units (GELUs) (2016), arXiv:1606.08415 [cs]
work page internal anchor Pith review arXiv 2016
-
[27]
Searching for Activation Functions
P. Ramachandran, B. Zoph, and Q. V. Le, Searching for activation functions (2017), arXiv:1710.05941 [cs]
work page internal anchor Pith review arXiv 2017
-
[28]
Clevert, T
D.-A. Clevert, T. Unterthiner, and S. Hochreiter, in International Conference on Learning Representations (2016)
2016
-
[29]
J. J. Sakurai and J. Napolitano,Modern Quantum Me- chanics, 3rd ed. (Cambridge University Press, 2020)
2020
-
[30]
M. A. Nielsen and I. L. Chuang,Quantum Computation and Quantum Information(Cambridge University Press, 2010)
2010
-
[31]
Mézard, G
M. Mézard, G. Parisi, and M. A. Virasoro,Spin Glass Theory and Beyond(World Scientific, 1987)
1987
-
[32]
Pei, Statistical physics for artificial neural networks (2025), arXiv:2512.06518 [cond-mat]
Z. Pei, Statistical physics for artificial neural networks (2025), arXiv:2512.06518 [cond-mat]
-
[33]
M. Harmon and D. Klabjan, Activation Ensembles for Deep Neural Networks (2017), arXiv:1702.07790 [stat]
-
[34]
G. Maguolo, L. Nanni, and S. Ghidoni, Ensemble of Con- volutional Neural Networks Trained with Different Acti- vation Functions (2020), arXiv:1905.02473 [cs]
- [35]
-
[36]
LeCun, L
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, Pro- ceedings of the IEEE86, 2278 (1998)
1998
-
[37]
H. Xiao, K. Rasul, and R. Vollgraf, Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms (2017), arXiv:1708.07747 [cs]
work page internal anchor Pith review arXiv 2017
-
[38]
Y. Li, X. Chen, and M. P. A. Fisher, Physical Review B 98, 205136 (2018)
2018
-
[39]
Skinner, J
B. Skinner, J. Ruhman, and A. Nahum, Physical Review X9, 031009 (2019)
2019
-
[40]
Nahum, J
A. Nahum, J. Ruhman, S. Vijay, and J. Haah, Physical Review X7, 031016 (2017)
2017
-
[41]
M. P. A. Fisher, V. Khemani, A. Nahum, and S. Vi- jay, Annual Review of Condensed Matter Physics14, 335 (2023)
2023
- [42]
-
[43]
Learning activation functions to improve deep neural networks
F. Agostinelli, M. Hoffman, P. Sadowski, and P. Baldi, Learning activation functionsto improve deep neural net- works (2014), arXiv:1412.6830 [cs]
-
[44]
F. Manessi and A. Rozza, in2018 24th International Conference on Pattern Recognition (ICPR)(IEEE, 2018) pp. 61–66, arXiv:1801.09403 [cs]
-
[45]
Benettin, L
G. Benettin, L. Galgani, A. Giorgilli, and J.-M. Strelcyn, Meccanica15, 9 (1980)
1980
-
[46]
Bergstra and Y
J. Bergstra and Y. Bengio, inJournal of Machine Learn- ing Research, Vol. 13 (2012) pp. 281–305
2012
-
[47]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar (2017) pp. 1–52. 15
2017
-
[48]
Gaier and D
A. Gaier and D. Ha, inAdvances in Neural Information Processing Systems, Vol. 32 (2019)
2019
-
[49]
Zhang, S
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, inInternational Conference on Learning Representations (2017)
2017
-
[50]
L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio, inPro- ceedings of the 34th International Conference on Machine Learning, Proceedings of Machine Learning Research, Vol. 70 (PMLR, 2017) pp. 1019–1028
2017
-
[51]
Arpit, S
D. Arpit, S. Jastrzębski, N. Ballas, D. Krueger, E. Ben- gio, M. S. Kanwal, T. Maharaj, A. Fischer, A. Courville, Y. Bengio, and S. Lacoste-Julien, inProceedings of the 34th International Conference on Machine Learn- ing, Proceedings of Machine Learning Research, Vol. 70 (PMLR, 2017) pp. 233–242
2017
-
[52]
Hochreiter and J
S. Hochreiter and J. Schmidhuber, Neural Computation 9, 1 (1997)
1997
-
[53]
N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang, inInternational Conference on Learn- ing Representations(2017)
2017
-
[54]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, Scaling Laws for Neural Language Models (2020), arXiv:2001.08361 [cs]
work page internal anchor Pith review arXiv 2020
-
[55]
Jacot, F
A. Jacot, F. Gabriel, and C. Hongler, inAdvances in Neural Information Processing Systems, Vol. 31 (2018)
2018
- [56]
-
[57]
Y. Bao, S. Choi, and E. Altman, Physical Review B101, 104301 (2020)
2020
-
[58]
C.-M.Jian, Y.-Z.You, R.Vasseur,andA.W.W.Ludwig, Physical Review B101, 104302 (2020)
2020
-
[59]
Y. Li, R. Vasseur, M. P. A. Fisher, and A. W. W. Ludwig, Physical Review B103, 104306 (2021)
2021
-
[60]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, inAdvances in Neural Information Processing Systems, Vol. 30 (2017)
2017
-
[61]
J. L. Ba, J. R. Kiros, and G. E. Hinton, arXiv preprint arXiv:1607.06450 (2016)
work page internal anchor Pith review arXiv 2016
-
[62]
Cardy,Scaling and Renormalization in Statistical Physics(Cambridge University Press, 1996)
J. Cardy,Scaling and Renormalization in Statistical Physics(Cambridge University Press, 1996)
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.