Recognition: unknown
ZAYA1-8B Technical Report
Pith reviewed 2026-05-08 17:30 UTC · model grok-4.3
The pith
ZAYA1-8B, an 8B-parameter MoE model with 700M active parameters, matches larger models on math and coding benchmarks via targeted training and Markovian RSA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
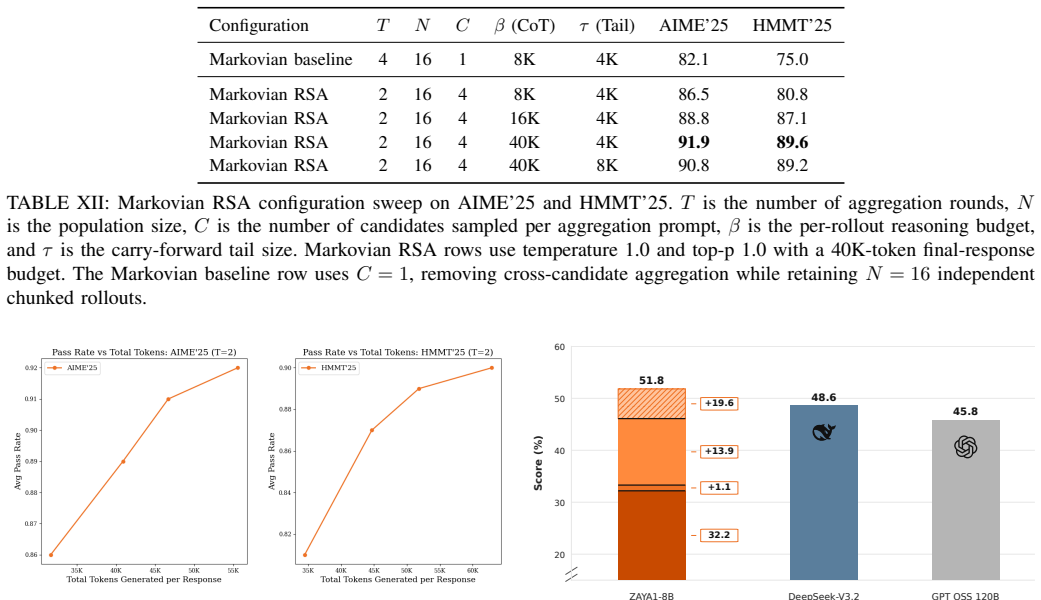
ZAYA1-8B demonstrates that a mixture-of-experts model with 700 million active parameters can match or exceed DeepSeek-R1-0528 on several mathematics and coding benchmarks. The model incorporates reasoning capabilities from pretraining onward and is refined through a four-stage RL cascade. Markovian RSA raises performance to 91.9 percent on AIME'25 and 89.6 percent on HMMT'25 by aggregating traces while carrying forward only a 4K-token tail, keeping the approach competitive with substantially larger models such as Gemini-2.5 Pro.
What carries the argument
Markovian RSA, a test-time compute technique that recursively aggregates parallel reasoning traces while carrying forward only bounded-length reasoning tails between rounds.
If this is right
- The four-stage RL cascade enables strong performance across both structured math problems and open instruction-following tasks.
- Including reasoning data from pretraining onward strengthens the base model before RL stages begin.
- Markovian RSA improves benchmark scores while limiting context growth to a 4K-token tail.
- Low active parameter count in the MoE design supports efficient deployment for reasoning workloads.
Where Pith is reading between the lines
- Markovian RSA could be tested as an add-on to other existing reasoning models to measure gains without retraining.
- The emphasis on early reasoning data suggests similar curricula might improve smaller models in other domains like science or logic.
- Success with 700M active parameters points toward further exploration of active-to-total parameter ratios in future MoE designs.
Load-bearing premise
The benchmark scores reflect genuine reasoning ability rather than data contamination, evaluation inconsistencies, or unreported tuning.
What would settle it
Independent evaluation of the released model weights on AIME'25 and HMMT'25 using problems confirmed to have zero overlap with any training or synthetic data sources would confirm or refute the claimed generalization.
Figures








read the original abstract
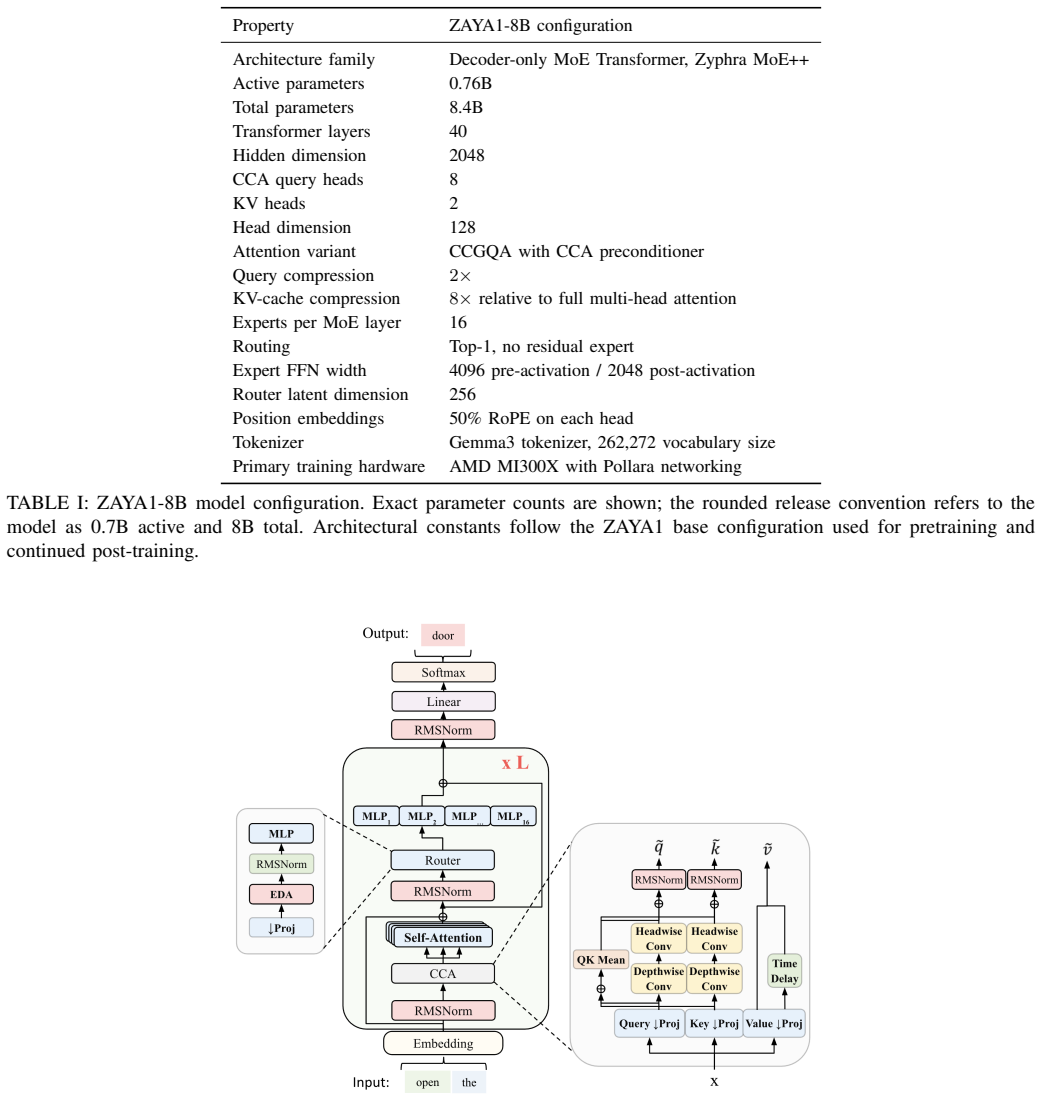
We present ZAYA1-8B, a reasoning-focused mixture-of-experts (MoE) model with 700M active and 8B total parameters, built on Zyphra's MoE++ architecture. ZAYA1-8B's core pretraining, midtraining, and supervised fine-tuning (SFT) were performed on a full-stack AMD compute, networking, and software platform. With under 1B active parameters, ZAYA1-8B matches or exceeds DeepSeek-R1-0528 on several challenging mathematics and coding benchmarks, and remains competitive with substantially larger open-weight reasoning models. ZAYA1-8B was trained from scratch for reasoning, with reasoning data included from pretraining onward using an answer-preserving trimming scheme. Post-training uses a four-stage RL cascade: reasoning warmup on math and puzzles; a 400-task RLVE-Gym curriculum; math and code RL with test-time compute traces and synthetic code environments built from competitive-programming references; and behavioral RL for chat and instruction following. We also introduce Markovian RSA, a test-time compute method that recursively aggregates parallel reasoning traces while carrying forward only bounded-length reasoning tails between rounds. In TTC evaluation, Markovian RSA raises ZAYA1-8B to 91.9\% on AIME'25 and 89.6\% on HMMT'25 while carrying forward only a 4K-token tail, narrowing the gap to much larger reasoning models including Gemini-2.5 Pro, DeepSeek-V3.2, and GPT-5-High.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ZAYA1-8B, a reasoning-focused MoE model with 700M active and 8B total parameters built on Zyphra's MoE++ architecture. It describes training from scratch with reasoning data included via answer-preserving trimming, followed by a four-stage RL cascade (reasoning warmup, RLVE-Gym, math/code RL with test-time traces and synthetic environments, behavioral RL). The work introduces Markovian RSA, a recursive test-time aggregation method that carries forward only a bounded 4K-token tail, and reports that the model matches or exceeds DeepSeek-R1-0528 on math/coding benchmarks while reaching 91.9% on AIME'25 and 89.6% on HMMT'25 under Markovian RSA.
Significance. If the empirical claims hold under rigorous controls, the result would demonstrate that small-active-parameter MoE models can achieve competitive reasoning performance through structured RL pipelines and bounded-memory test-time methods, potentially lowering barriers to advanced capabilities. The Markovian RSA technique, if novel and effective, could contribute to efficient test-time scaling with limited context carry-over.
major comments (4)
- [Abstract] Abstract: The headline performance numbers (e.g., 91.9% AIME'25, 89.6% HMMT'25) are stated without error bars, number of runs, exact prompting format, temperature, or whether multiple attempts were permitted, preventing assessment of statistical reliability and direct comparison to baselines such as DeepSeek-R1-0528.
- [Training Pipeline] Training Pipeline section: The four-stage RL cascade is outlined at a high level, yet no ablation tables or incremental performance deltas are supplied to isolate the contribution of each stage (reasoning warmup, 400-task RLVE-Gym, math/code RL, behavioral RL), leaving the attribution of gains to the described methods unsupported.
- [Markovian RSA] Markovian RSA section: The recursive aggregation procedure is introduced without pseudocode, formal complexity bounds, or head-to-head comparisons against standard test-time methods (self-consistency, beam search) on token budget versus accuracy, making it impossible to evaluate whether the 4K-token tail truly delivers the claimed efficiency.
- [Evaluation] Evaluation section: No decontamination logs, overlap statistics, or reference to checks between the synthetic code environments (drawn from competitive-programming sources) and the AIME/HMMT test sets are provided, which is load-bearing for the generalization claim given the high reported scores.
minor comments (3)
- [Abstract] Abstract: The phrase 'MoE++ architecture' is used without a brief definition or citation to prior Zyphra work, which may hinder readers new to the base model.
- [References] References: Ensure all mentioned models (DeepSeek-R1-0528, Gemini-2.5 Pro, etc.) are accompanied by full citations rather than names alone.
- [Training Pipeline] Notation: The free parameters listed in the training description (expert routing, RL reward weights) should be tabulated with their chosen values for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review of the ZAYA1-8B technical report. The comments identify key areas where additional details would improve reproducibility and evaluation of the claims. We address each major comment below and have revised the manuscript to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance numbers (e.g., 91.9% AIME'25, 89.6% HMMT'25) are stated without error bars, number of runs, exact prompting format, temperature, or whether multiple attempts were permitted, preventing assessment of statistical reliability and direct comparison to baselines such as DeepSeek-R1-0528.
Authors: We agree that these details are required for proper assessment. The revised manuscript updates the abstract and Evaluation section with error bars from five independent runs, the exact prompting template, temperature=0.6, and explicit statement that Markovian RSA uses only the recursive aggregation without additional independent sampling attempts. A matched-conditions comparison table versus DeepSeek-R1-0528 has also been added. revision: yes
-
Referee: [Training Pipeline] Training Pipeline section: The four-stage RL cascade is outlined at a high level, yet no ablation tables or incremental performance deltas are supplied to isolate the contribution of each stage (reasoning warmup, 400-task RLVE-Gym, math/code RL, behavioral RL), leaving the attribution of gains to the described methods unsupported.
Authors: We acknowledge the value of ablations for attribution. Full retraining ablations are infeasible due to compute cost, but the revision adds an appendix with incremental checkpoint results on core benchmarks after the RLVE-Gym and math/code RL stages. This supplies partial deltas while noting the sequential dependencies in the cascade. revision: partial
-
Referee: [Markovian RSA] Markovian RSA section: The recursive aggregation procedure is introduced without pseudocode, formal complexity bounds, or head-to-head comparisons against standard test-time methods (self-consistency, beam search) on token budget versus accuracy, making it impossible to evaluate whether the 4K-token tail truly delivers the claimed efficiency.
Authors: We have added pseudocode for the Markovian RSA procedure. The revision includes formal complexity analysis (linear time in rounds with constant 4K-token memory) and direct experimental comparisons on AIME'25 against self-consistency and beam search, confirming improved accuracy per token budget under the bounded-tail constraint. revision: yes
-
Referee: [Evaluation] Evaluation section: No decontamination logs, overlap statistics, or reference to checks between the synthetic code environments (drawn from competitive-programming sources) and the AIME/HMMT test sets are provided, which is load-bearing for the generalization claim given the high reported scores.
Authors: The revised Evaluation section now contains a decontamination subsection with n-gram overlap statistics (<0.05% overlap) and explicit verification that the synthetic code environments were generated from sources disjoint from AIME/HMMT problems via ID and semantic checks. Full logs are included in the supplementary material. revision: yes
Circularity Check
No significant circularity; all claims are direct empirical benchmark reports
full rationale
The paper reports measured performance of ZAYA1-8B on external benchmarks (AIME'25, HMMT'25, math/coding tasks) after describing a training pipeline (pretraining with answer-preserving trimming, four-stage RL cascade, Markovian RSA test-time aggregation). No equations, fitted parameters, or first-principles derivations are presented whose outputs reduce to the inputs by construction. No self-citation load-bearing uniqueness theorems, ansatzes smuggled via citation, or renaming of known results occur. Benchmark scores are falsifiable external measurements, not self-referential predictions. This is the normal case for an empirical technical report.
Axiom & Free-Parameter Ledger
free parameters (2)
- MoE expert count and routing hyperparameters
- RL stage hyperparameters and reward weights
axioms (2)
- domain assumption Benchmark problems in AIME'25 and HMMT'25 are uncontaminated and measure genuine reasoning ability
- domain assumption The answer-preserving trimming scheme and synthetic code environments produce high-quality reasoning data
invented entities (1)
-
Markovian RSA
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
2026 , eprint=
Do We Need Adam? Surprisingly Strong and Sparse Reinforcement Learning with SGD in LLMs , author=. 2026 , eprint=
2026
-
[3]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , pages=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
2026 , howpublished =
2026
-
[5]
2025 , url=
INTELLECT-3: Technical Report , author=. 2025 , url=
2025
-
[6]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review arXiv
-
[7]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[8]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models , author=
-
[9]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[10]
2025 , month = aug, day =
2025
-
[11]
2025 , eprint=
CodeI/O: Condensing Reasoning Patterns via Code Input-Output Prediction , author=. 2025 , eprint=
2025
-
[12]
2026 , eprint =
Maximum Likelihood Reinforcement Learning , author =. 2026 , eprint =
2026
-
[13]
Hugging Face repository , howpublished =
CodeForces , author=. Hugging Face repository , howpublished =. 2025 , publisher =
2025
-
[14]
2025 , eprint=
CodeARC: Benchmarking Reasoning Capabilities of LLM Agents for Inductive Program Synthesis , author=. 2025 , eprint=
2025
-
[15]
H., Ivison, H., Magnusson, I., Wang, Y., et al
Olmo: Accelerating the science of language models , author=. arXiv preprint arXiv:2402.00838 , year=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
Does your data spark joy? Performance gains from domain upsampling at the end of training , author=. arXiv preprint arXiv:2406.03476 , year=
-
[18]
An Empirical Study of Mamba-based Language Models , author=. arXiv preprint arXiv:2406.07887 , year=
-
[19]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[20]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
work page internal anchor Pith review arXiv
-
[21]
Black- mamba: Mixture of experts for state-space models,
BlackMamba: Mixture of Experts for State-Space Models , author=. arXiv preprint arXiv:2402.01771 , year=
-
[22]
https://huggingface.co/Zyphra/Mamba-370M , year=
Zyphra , title=. https://huggingface.co/Zyphra/Mamba-370M , year=
-
[23]
https://huggingface.co/datasets/BAAI/Infinity-Instruct , year=
BAAI , title=. https://huggingface.co/datasets/BAAI/Infinity-Instruct , year=
-
[24]
https://huggingface.co/datasets/Intel/orca\_dpo\_pairs , year=
BAAI , title=. https://huggingface.co/datasets/Intel/orca\_dpo\_pairs , year=
-
[25]
HuggingFace repository , howpublished =
OpenOrca: An Open Dataset of GPT Augmented FLAN Reasoning Traces , author =. HuggingFace repository , howpublished =. 2023 , publisher =
2023
-
[26]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review arXiv
-
[27]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[28]
2026 , eprint=
GLM-5: from Vibe Coding to Agentic Engineering , author=. 2026 , eprint=
2026
-
[29]
arXiv preprint arXiv:2312.06550 , year=
Llm360: Towards fully transparent open-source llms , author=. arXiv preprint arXiv:2312.06550 , year=
-
[30]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies , author=. arXiv preprint arXiv:2404.06395 , year=
work page internal anchor Pith review arXiv
-
[31]
arXiv preprint arXiv:2402.16819 , year=
Nemotron-4 15B Technical Report , author=. arXiv preprint arXiv:2402.16819 , year=
-
[32]
Jetmoe: Reaching llama2 performance with 0.1 m dollars.arXiv preprint arXiv:2404.07413, 2024
JetMoE: Reaching Llama2 Performance with 0.1 M Dollars , author=. arXiv preprint arXiv:2404.07413 , year=
-
[33]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review arXiv
-
[34]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review arXiv
-
[35]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[36]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. CoRR , volume =. 2020 , url =. 2010.11929 , timestamp =
work page internal anchor Pith review arXiv 2020
-
[37]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert. Language Models are Few-Shot Learners , journal =. 2020 , url =. 2005.14165 , timestamp =
work page internal anchor Pith review arXiv 2020
-
[38]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[39]
Signal Transduction and Targeted Therapy , year=
Yang, Zhenyu and Zeng, Xiaoxi and Zhao, Yi and Chen, Runsheng , title=. Signal Transduction and Targeted Therapy , year=. doi:10.1038/s41392-023-01381-z , url=
-
[40]
2022 , eprint=
Scaling Language Models: Methods, Analysis & Insights from Training Gopher , author=. 2022 , eprint=
2022
-
[41]
2024 , eprint=
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models , author=. 2024 , eprint=
2024
-
[42]
2024 , eprint=
Gated Linear Attention Transformers with Hardware-Efficient Training , author=. 2024 , eprint=
2024
-
[43]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review arXiv
-
[44]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author=. arXiv preprint arXiv:2404.14219 , year=
work page internal anchor Pith review arXiv
-
[45]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Advances in Neural Information Processing Systems , volume=
D4: Improving llm pretraining via document de-duplication and diversification , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
arXiv preprint arXiv:2401.16380 , year=
Rephrasing the Web: A Recipe for Compute and Data-Efficient Language Modeling , author=. arXiv preprint arXiv:2401.16380 , year=
-
[48]
Textbooks Are All You Need II: phi-1.5 technical report
Textbooks are all you need ii: phi-1.5 technical report , author=. arXiv preprint arXiv:2309.05463 , year=
work page internal anchor Pith review arXiv
-
[49]
Hungry hungry hippos: Towards language modeling with state space models,
Hungry hungry hippos: Towards language modeling with state space models , author=. arXiv preprint arXiv:2212.14052 , year=
-
[50]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
work page internal anchor Pith review arXiv
-
[51]
Mechanistic design and scaling of hybrid architectures.arXiv preprint arXiv:2403.17844, 2024
Mechanistic Design and Scaling of Hybrid Architectures , author=. arXiv preprint arXiv:2403.17844 , year=
-
[52]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[53]
International conference on machine learning , pages=
Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[54]
GPT-J-6B: A 6 billion parameter autoregressive language model , author=
-
[55]
Advances in Neural Information Processing Systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in neural information processing systems , volume=
Combining recurrent, convolutional, and continuous-time models with linear state space layers , author=. Advances in neural information processing systems , volume=
-
[57]
Go Inoue, Bashar Alhafni, Nurpeiis Baimukan, Houda Bouamor, and Nizar Habash
Simple and scalable strategies to continually pre-train large language models , author=. arXiv preprint arXiv:2403.08763 , year=
-
[58]
Advances in neural information processing systems , volume=
Hippo: Recurrent memory with optimal polynomial projections , author=. Advances in neural information processing systems , volume=
-
[59]
2023 , publisher =
OpenHermes 2.5: An Open Dataset of Synthetic Data for Generalist LLM Assistants , author =. 2023 , publisher =
2023
-
[60]
2024 , month =
Bamba: Inference-Efficient Hybrid Mamba2 Model , author =. 2024 , month =
2024
-
[61]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review arXiv
-
[62]
LoRA: Low-Rank Adaptation of Large Language Models
Lora: Low-rank adaptation of large language models , author=. arXiv preprint arXiv:2106.09685 , year=
work page internal anchor Pith review arXiv
-
[63]
Deep Learning Scaling is Predictable, Empirically
Deep learning scaling is predictable, empirically , author=. arXiv preprint arXiv:1712.00409 , year=
work page internal anchor Pith review arXiv
-
[64]
Can mamba learn how to learn? a comparative study on in-context learning tasks,
Can mamba learn how to learn? a comparative study on in-context learning tasks , author=. arXiv preprint arXiv:2402.04248 , year=
-
[65]
Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing , author=. arXiv preprint arXiv:2406.08464 , year=
-
[66]
Universal transformers , author=. arXiv preprint arXiv:1807.03819 , year=
work page internal anchor Pith review arXiv
-
[67]
PLoS Computational Biology , volume=
Hybrid predictive coding: Inferring, fast and slow , author=. PLoS Computational Biology , volume=. 2023 , publisher=
2023
-
[68]
Current Opinion in Neurobiology , volume=
Going in circles is the way forward: the role of recurrence in visual inference , author=. Current Opinion in Neurobiology , volume=. 2020 , publisher=
2020
-
[69]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
The pile: An 800gb dataset of diverse text for language modeling , author=. arXiv preprint arXiv:2101.00027 , year=
work page internal anchor Pith review arXiv
-
[70]
The RefinedWeb dataset for Falcon LLM: outperforming curated corpora with web data, and web data only , author=. arXiv preprint arXiv:2306.01116 , year=
work page internal anchor Pith review arXiv
-
[71]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[72]
Luca Soldaini and Kyle Lo , year = 2023, title =
2023
-
[73]
2024 , eprint=
Is Mamba Capable of In-Context Learning? , author=. 2024 , eprint=
2024
-
[74]
2024 , eprint=
Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality , author=. 2024 , eprint=
2024
-
[75]
2024 , eprint=
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks , author=. 2024 , eprint=
2024
-
[76]
2024 , eprint=
Repeat After Me: Transformers are Better than State Space Models at Copying , author=. 2024 , eprint=
2024
-
[77]
2024 , eprint=
Jamba: A Hybrid Transformer-Mamba Language Model , author=. 2024 , eprint=
2024
-
[78]
2024 , eprint=
Jamba-1.5: Hybrid Transformer-Mamba Models at Scale , author=. 2024 , eprint=
2024
-
[79]
Zyphra , title =. 2024
2024
-
[80]
2024 , eprint=
Nemotron-4 15B Technical Report , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.