Recognition: unknown
Improving Minority Population Sampling with BISG Probabilities: Evidence from a Survey of Jewish Americans
Pith reviewed 2026-05-08 15:24 UTC · model grok-4.3
The pith
BISG probabilities incorporated into stratified Poisson sampling let a national Jewish American survey match Pew Research estimates at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
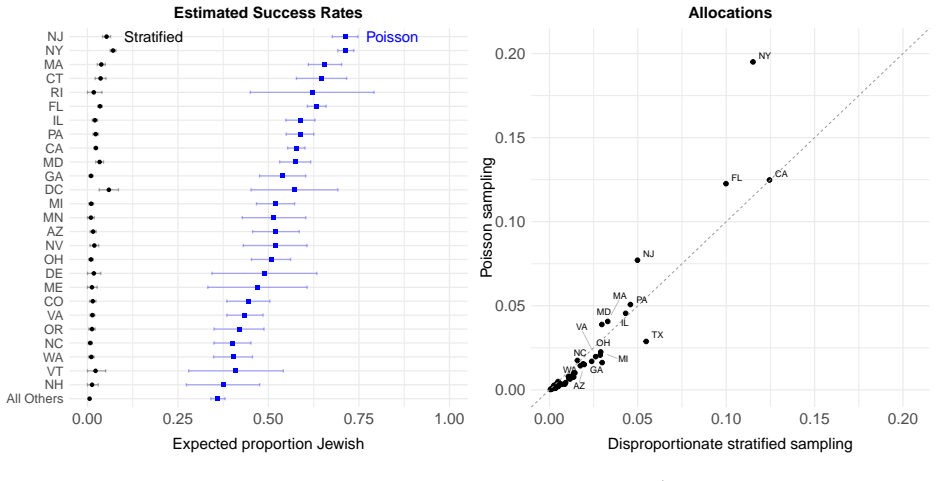
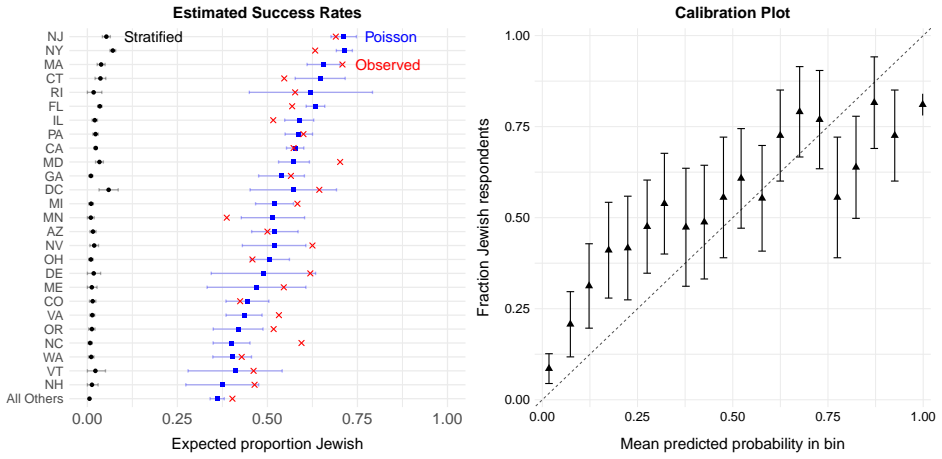
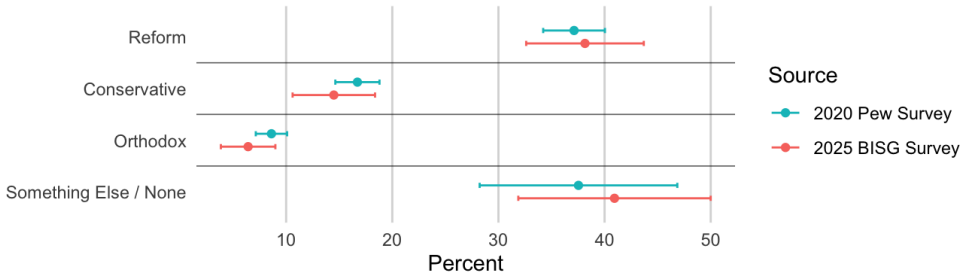
By generating BISG probabilities of Jewish identity from surnames and residential addresses and incorporating them into a stratified Poisson sampling design, the authors conduct a national survey whose estimates of religious affiliation and activity closely reproduce the corresponding figures obtained by the Pew Research Center through geographic stratification and screening.
What carries the argument
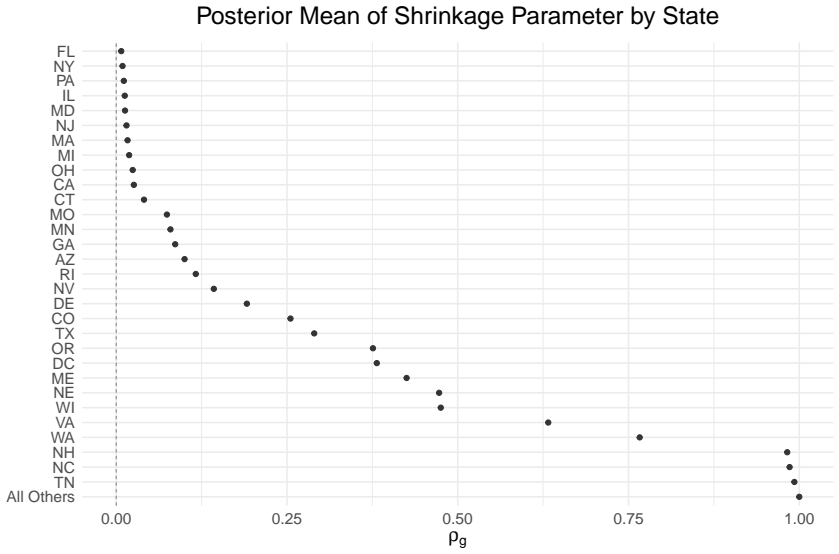
BISG-derived individual probabilities of minority membership used as the basis for stratification in a Poisson probability sampling design.
If this is right
- Other dispersed minority populations can be surveyed with similar efficiency gains without needing exhaustive geographic screening.
- Survey budgets can be reallocated from screening costs to larger sample sizes or repeated waves while preserving accuracy on key traits.
- Estimates of subgroup patterns such as denominational affiliation and ritual participation can be obtained without the expense of intensive screening.
- The method supports national-level inference on hard-to-reach groups by leveraging existing name and address data rather than custom strata.
Where Pith is reading between the lines
- The same probability-weighted sampling framework could be tested on other U.S. religious or ethnic minorities where surname and address data are available.
- If BISG probabilities are updated with newer census or administrative data, sampling efficiency might improve further over time.
- The approach may generalize to online or mixed-mode surveys if address information can be linked to digital panels.
Load-bearing premise
BISG probabilities must be accurate and unbiased for the specific minority population so that the resulting sample is representative rather than systematically skewed.
What would settle it
A replication survey using the same BISG-based design but producing estimates of religious denomination shares or activity participation that differ substantially from an independent high-quality benchmark survey of the same population would falsify the claim of reliable reproduction.
Figures
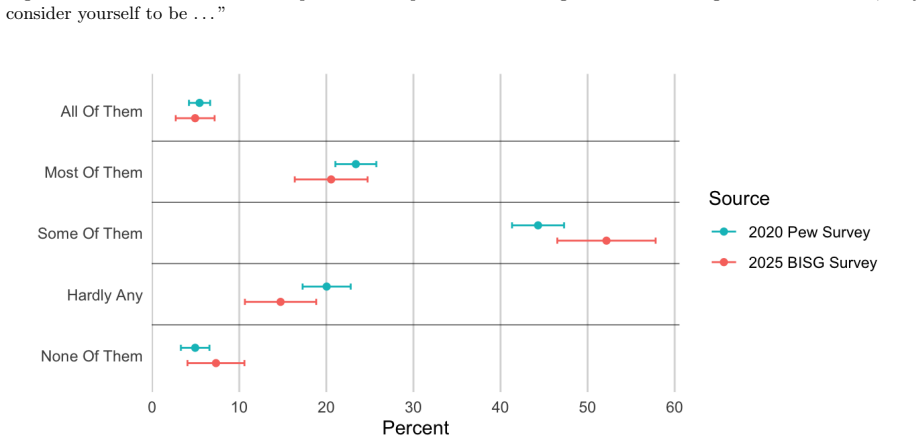
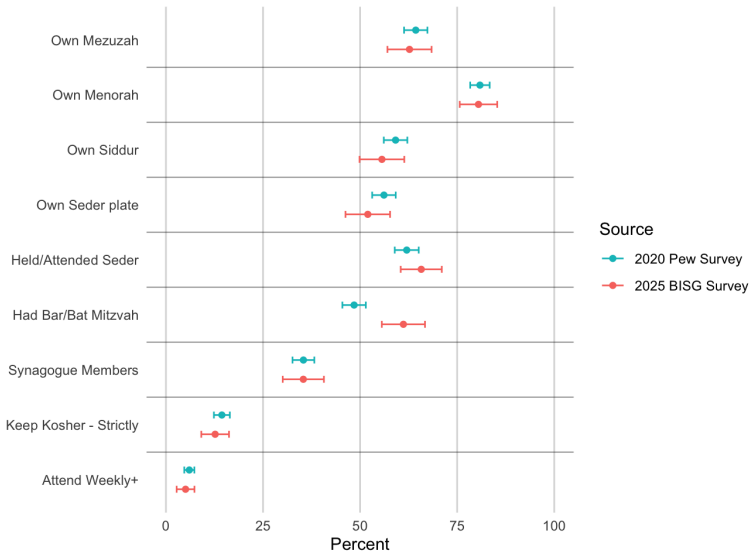
read the original abstract
Sampling geographically dispersed minority populations poses substantial challenges when individual group membership cannot be directly observed. Although stratified sampling can offer efficiency gains, these gains are typically modest unless the minority population is highly concentrated within a small number of strata. In this paper, we propose using Bayesian Improved Surname Geocoding (BISG) to enhance the efficiency of minority population sampling. BISG generates individual-level probabilities of minority group membership based on names and residential addresses. We incorporate these probabilities into a stratified Poisson probability sampling design. Applying the proposed approach to a national survey of Jewish Americans, we find that our estimates closely align with those from a large-scale Pew Research Center survey of the same population, which relied on a substantially more expensive sampling strategy involving geographic stratification and screening. At a fraction of the cost, our survey reproduces nearly identical patterns observed by Pew, including estimates of religious denominations and participation in specific religious activities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes incorporating Bayesian Improved Surname Geocoding (BISG) probabilities into a stratified Poisson probability sampling design to improve efficiency when sampling geographically dispersed minority populations whose membership cannot be directly observed. Applied to a national survey of Jewish Americans, the resulting estimates are reported to closely align with those from the Pew Research Center's substantially more expensive survey (which used geographic stratification and screening), reproducing nearly identical patterns in religious denominations and participation in specific religious activities at a fraction of the cost.
Significance. If the alignment is attributable to the BISG-enhanced design rather than questionnaire overlap or other unmeasured factors, and if BISG probabilities prove accurate for this group, the approach could offer a scalable, lower-cost method for surveying rare populations. The direct empirical comparison to an independent external benchmark is a positive feature that strengthens the practical claim.
major comments (3)
- [Abstract] Abstract: the claim of close alignment with Pew results provides no details on sample sizes, statistical comparisons, error bars, potential confounders, or exact implementation of the Poisson design, preventing evaluation of the evidence strength for the central empirical claim.
- [Abstract] Abstract: no validation is presented that BISG probabilities are accurate or unbiased for Jewish identity (a non-standard racial/ethnic category), such as a calibration check or comparison of predicted probabilities against self-reported data; without this, the assumption that the design improves sampling efficiency without introducing selection bias remains untested.
- [Abstract] Abstract: the manuscript does not address or control for the possibility that observed alignment with Pew stems from similarities in questionnaire content or population characteristics rather than the stratified Poisson sampling design itself.
minor comments (1)
- [Abstract] Clarify in the methods section how the BISG probabilities are exactly incorporated into the stratified Poisson design (e.g., as inclusion probabilities or weights) and provide the precise cost comparison figures.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond to each major comment below, indicating revisions where appropriate to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of close alignment with Pew results provides no details on sample sizes, statistical comparisons, error bars, potential confounders, or exact implementation of the Poisson design, preventing evaluation of the evidence strength for the central empirical claim.
Authors: We agree that the abstract is concise and omits these details, which limits immediate evaluation. The full manuscript reports the sample sizes for both our survey and the Pew benchmark, includes tables and figures with standard errors and confidence intervals for the comparisons, discusses potential confounders in the limitations section, and provides the exact implementation of the stratified Poisson sampling design in the methods. To improve the abstract, we will revise it to incorporate sample sizes and a brief quantitative summary of the alignment (e.g., noting the reproduction of patterns within sampling error on key variables). revision: yes
-
Referee: [Abstract] Abstract: no validation is presented that BISG probabilities are accurate or unbiased for Jewish identity (a non-standard racial/ethnic category), such as a calibration check or comparison of predicted probabilities against self-reported data; without this, the assumption that the design improves sampling efficiency without introducing selection bias remains untested.
Authors: This is a fair criticism. The manuscript applies BISG probabilities based on their established performance for surname- and geography-based prediction of ethnic and religious minorities in the cited literature, but does not include a direct calibration or comparison against self-reported Jewish identity data. We will revise the manuscript to add an explicit discussion of this assumption, including references to prior BISG validations for analogous groups and a clear statement of the limitation. We cannot introduce new empirical calibration without additional data. revision: partial
-
Referee: [Abstract] Abstract: the manuscript does not address or control for the possibility that observed alignment with Pew stems from similarities in questionnaire content or population characteristics rather than the stratified Poisson sampling design itself.
Authors: We recognize that questionnaire overlap and shared population traits are plausible alternative explanations for the alignment. Our survey instrument was deliberately aligned with Pew items on denominations and religious activities to permit direct comparison. In the revised manuscript, we will expand the discussion section to explicitly consider these factors, present evidence on the sampling efficiency gains (e.g., reduced variance relative to unstratified designs), and clarify that while the design enables low-cost comparable estimates, we do not claim to have fully isolated its contribution from questionnaire or other design elements. revision: yes
Circularity Check
No circularity: empirical comparison to external benchmark
full rationale
The paper proposes a BISG-enhanced stratified Poisson sampling design for minority populations and validates it empirically by showing that estimates from a national Jewish American survey closely match those from an independent, more expensive Pew Research Center survey. This alignment is presented as external evidence of efficiency gains, not as a mathematical derivation or fitted parameter. No equations, self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the central claim to its own inputs by construction. The result is self-contained against the external Pew benchmark.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption BISG probabilities provide accurate estimates of individual-level minority group membership based on name and address.
- standard math Stratified Poisson sampling using these probabilities yields unbiased or consistent population estimates.
Reference graph
Works this paper leans on
-
[1]
Amanik, A. (2017). `all will be fine, jewish and promptly attended': Tradition and the rise of new york undertakers, 1890--1950. Shofar , 35(4):91--109
2017
-
[2]
Ambekar, A., Ward, C., Mohammed, J., Male, S., and Skiena, S. (2009). Name-ethnicity classification from open sources. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge Discovery and Data Mining , pages 49--58
2009
-
[3]
K., Boxer, M., and Saxe, L
Aronson, J. K., Boxer, M., and Saxe, L. (2016). ‘all politics is local’: Challenges in the study of local jewish communities. Contemporary Jewry , 36(3):361--380
2016
-
[4]
The belmont report: Ethical principles and guidelines for the protection of human subjects of research
Belmont Report (1979). The belmont report: Ethical principles and guidelines for the protection of human subjects of research. Available at https://www.hhs.gov/ohrp/regulations-and-policy/belmont-report/read-the-belmont-report/index.html
1979
-
[5]
Blitzstein, J. K. and Morris, C. N. (2021). Probability for Statistical Science: Draft Version August 2021 . Unpublished manuscript
2021
-
[6]
Brewer, K. R. W. (1983). Sampling with unequal probabilities . Lecture Notes in Statistics, 15. Springer-Verlag, New York, New York, 1st ed. 1983. edition
1983
-
[7]
Deaths and mortality
Centers for Disease Control and Prevention (2025). Deaths and mortality. CDC FastStats. Accessed: 2025-12-24
2025
-
[8]
Cervantes, I. F. and Kalton, G. (2007). Methods for sampling rare populations in telephone surveys. In Advances in Telephone Survey Methodology , chapter 5, pages 113--132. John Wiley & Sons, Ltd
2007
-
[9]
and Kalton, G
Chen, S. and Kalton, G. (2015). Geographic oversampling for race/ethnicity using data from the 2010 us population census. Journal of Survey Statistics and Methodology , 3(4):543--565
2015
-
[10]
Clark, R. G. (2009). Sampling of subpopulations in two-stage surveys. Statistics in Medicine , 28(29):3697--3717
2009
-
[11]
Cohen, S. M. (2016). Deficient, if not distorted: Jewish community studies that totally rely upon known jewish households. Contemporary Jewry , 36(3):343--360
2016
-
[12]
and Imai, K
Dasanaike, N. and Imai, K. (2026). Using embedding models to improve probabilistic race prediction
2026
-
[13]
Deming, W. E. and Stephan, F. F. (1940). On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. The Annals of Mathematical Statistics , 11(4):427--444
1940
-
[14]
Deville, J.-C., Särndal, C.-E., and Sautory, O. (1993). Generalized raking procedures in survey sampling. Journal of the American Statistical Association , 88(423):1013--1020
1993
-
[15]
Elia-Shalev, A. (2024). How these 29 last names became a cheat code for researchers surveying american jews. Jewish Telegraphic Agency , page 1
2024
-
[16]
N., Morrison, P
Elliott, M. N., Morrison, P. A., Fremont, A., McCaffrey, D. F., Pantoja, P., and Lurie, N. (2009). Using the census bureau’s surname list to improve estimates of race/ethnicity and associated disparities. Health Services and Outcomes Research Methodology , 9(2):69--83
2009
-
[17]
and Gelman, A
Greengard, P. and Gelman, A. (2025). A calibrated bisg for inferring race from surname and geolocation. Journal of the Royal Statistical Society Series A: Statistics in Society , page qnaf003
2025
-
[18]
Groves, R. M. and Couper, M. (1998). Nonresponse in household interview surveys . Wiley series in probability and statistics. Survey methodology section. Wiley, New York
1998
-
[19]
H.-H., Oliver, R
Hage, B. H.-H., Oliver, R. G., Powles, J. W., and Wahlqvist, M. L. (1990). Telephone directory listings of presumptive chinese surnames: An appropriate sampling frame for a dispersed population with characteristic surnames. Epidemiology , 1(5):405--408
1990
-
[20]
H \'a jek, J. (1964). Asymptotic theory of rejective sampling with varying probabilities from a finite population. The Annals of Mathematical Statistics , 35(4):1491--1523
1964
-
[21]
Harter, R. (2016). The quality of auxiliary variables in an enhanced address-based sampling frame. In JSM Proceedings, Government Statistics Section , pages 74--89, Alexandria, VA. American Statistical Association. Invited presentation
2016
-
[22]
and McMichael, J
Harter, R. and McMichael, J. (2022). Predictive modeling using an enhanced address-based sampling frame
2022
-
[23]
and Lyss, D
Hersh, E. and Lyss, D. (2025). A year of campus conflict and growth: An over-time study of the impact of the israel-hamas war on u.s. college students. Technical report, Jim Joseph Foundation
2025
-
[24]
and Shah, S
Hersh, E. and Shah, S. (2025). The partisan realignment of american business: Evidence from a survey of corporate leaders. British Journal of Political Science , 55(e79):1--23
2025
-
[25]
S., Loar, R
Himmelfarb, H. S., Loar, R. M., and Mott, S. H. (1983). Sampling by ethnic surnames: The case of american jews. Public Opinion Quarterly , 47(2):247--260
1983
-
[26]
and Smith, T
Holt, D. and Smith, T. F. (1979). Post stratification. Journal of the Royal Statistical Society Series A: Statistics in Society , 142(1):33--46
1979
-
[27]
and Khanna, K
Imai, K. and Khanna, K. (2016). Improving ecological inference by predicting individual ethnicity from voter registration record. Political Analysis , 24(2):263--272
2016
-
[28]
Imai, K., Olivella, S., and Rosenman, E. T. R. (2022). Addressing census data problems in race imputation via fully bayesian improved surname geocoding and name supplements. Science Advances , 8(49):eadc9824
2022
-
[29]
Jain, V., Enamorado, T., and Rudin, C. (2022). The Importance of Being Ernest , Ekundayo , or Eswari : An Interpretable Machine Learning Approach to Name - Based Ethnicity Classification . Harvard Data Science Review , 4(3). https://hdsr.mitpress.mit.edu/pub/wgss79vu
2022
-
[30]
Jannetti, M., Carroll-Scott, A., Gilliam, E., Headen, I., Beverly, M., and Lê-Scherban, F. (2023). Improving sampling probability definitions with predictive algorithms. Field Methods , 35(2):137--152
2023
-
[31]
Kalton, G. (1993). Sampling rare and elusive populations. Technical Report INT\_92\_P80\_16E, United Nations, Department of Economic and Social Information and Policy Analysis, Statistical Division, National Household Survey Capability Programme, New York
1993
-
[32]
Kalton, G. (2009). Methods for oversampling rare subpopulations in social surveys. Survey methodology , 35(2):125--141
2009
-
[33]
Kalton, G. (2014). Probability sampling methods for hard-to-sample populations. In Tourangeau, R., Edwards, B., Johnson, T. P., Wolter, K. M., and Bates, N., editors, Hard-to-Survey Populations , page 401–423. Cambridge University Press
2014
-
[34]
and Anderson, D
Kalton, G. and Anderson, D. W. (1986). Sampling rare populations. Journal of the Royal Statistical Society: Series A (General) , 149(1):65--82
1986
-
[35]
and Flores-Cervantes, I
Kalton, G. and Flores-Cervantes, I. (2003). Weighting methods. Journal of official statistics , 19(2):81
2003
-
[36]
S., Shin, H.-C., and Lee, Y
Kim, J., Lauderdale, D. S., Shin, H.-C., and Lee, Y. (2013). Surname sampling: Reevaluating kim sampling in korea and the united states. Field Methods , 26(1):87--104. Original work published 2014
2013
-
[37]
Kosmin, B. A. and Waterman, S. (1985). The use and misuse of distinctive jewish names in research on jewish populations. Avraham Harman Institute of Contemporary Jewry, Hebrew Univesity of Jerusalem , pages 1--9
1985
-
[38]
Lauderdale, D. S. and Kestenbaum, B. (2000). Asian american ethnic identification by surname. Population Research and Policy Review , 19(3):283--300
2000
-
[39]
Lepkowski, J. M. (1991). Sampling the difficult-to-sample. The Journal of Nutrition , 121(3):416--423
1991
-
[40]
Lin, J. (2016). On the dirichlet distribution. Department of Mathematics and Statistics, Queens University , 40
2016
-
[41]
Little, R. J. A. (1993). Post-stratification: A modeler's perspective. Journal of the American Statistical Association , 88(423):1001--1012
1993
-
[42]
Little, R. J. A. and Rubin, D. B. (2002). Statistical analysis with missing data . Wiley series in probability and statistics. Wiley, Hoboken, N.J, 2nd ed. edition
2002
-
[43]
Liu, J. S. (1994). The collapsed gibbs sampler in bayesian computations with applications to a gene regulation problem. Journal of the American Statistical Association , 89(427):958--966
1994
-
[44]
S., Wong, W
Liu, J. S., Wong, W. H., and Kong, A. (1994). Covariance structure of the gibbs sampler with applications to the comparisons of estimators and augmentation schemes. Biometrika , 81(1):27--40
1994
-
[45]
Lohr, S. L. (1999). Sampling : design and analysis . Duxbury Press, Pacific Grove, CA
1999
-
[46]
E., and Imai, K
McCartan, C., Goldin, J., Ho, D. E., and Imai, K. (2023). Estimating racial disparities when race is not observed
2023
-
[47]
McPhee, C. (2022). Applications of predictive modeling to survey design and operation in address-based samples. PowerPoint presentation, available online. Accessed: 2025-01-07. Available at https://aapor.org/wp-content/uploads/2023/01/Predictive-Modeling_McPhee_March2022_Final.pdf
2022
-
[48]
Mercer, A., Lau, A., and Kennedy, C. (2018). For weighting online opt-in samples, what matters most? the right variables make a big difference for accuracy. complex statistical methods, not so much. Report, Pew Research Center
2018
-
[49]
Jewish americans in 2020
Pew Research Center (2021a). Jewish americans in 2020. Pew Research Center website
2020
-
[50]
The size of the u.s
Pew Research Center (2021b). The size of the u.s. jewish population. https://www.pewresearch.org/religion/2021/05/11/the-size-of-the-u-s-jewish-population/
2021
-
[51]
Pew Research Center (2021c). U.s. jews' political views. Accessed: 2026-04-08
2026
-
[52]
Rao, J. N. and Scott, A. J. (1984). On chi-squared tests for multiway contingency tables with cell proportions estimated from survey data. The Annals of statistics , pages 46--60
1984
-
[53]
and McMichael, J
Ridenhour, J. and McMichael, J. (2017). Propensity stratification with auxiliary data for address-based sampling frames. In Annual Conference of the American Association for Public Opinion Research, New Orleans, LA
2017
-
[54]
Robert, C. (1999). Monte Carlo Statistical Methods . Springer Texts in Statistics. Springer New York : Imprint: Springer, New York, NY, 1st ed. 1999. edition
1999
-
[55]
Rosenman, E. T. R., Olivella, S., and Imai, K. (2023). Race and ethnicity data for first, middle, and surnames. Scientific Data , 10:299
2023
-
[56]
Saxe, L., Kallista, D., Palmer, D., Nussbaum, D., Tighe, E., Seabrum, X., Magidin de Kramer, R., and Mandell, J. (2021). American jewish population estimates 2020 summary and highlights. Technical report, Brandeis University
2021
-
[57]
Schnell, R., Gramlich, T., Bachteler, T., Trappmann, M., Smid, M., Becher, I., et al. (2013). A new name-based sampling method for migrants. methods, data, analyses , 7(1):29
2013
-
[58]
H., Dutwin, D., and Saxe, L
Seeskin, Z. H., Dutwin, D., and Saxe, L. (2022). Address-based sampling for socio-demographic studies of the u.s. jewish community. In AAPOR 2022 -- Survey Research Methods Section . American Association for Public Opinion Research
2022
-
[59]
Smith, T. M. F. (2018). Post-stratification. Journal of the Royal Statistical Society Series D: The Statistician , 40(3):315--323
2018
-
[60]
Tighe, E., Magidin de Kramer, R., Seabrum, X., Parmer, D., Kallista, D., Nussbaum, D., and Mandell, J. (2021). Ajpp technical report 2020: Zip code-based jewish population estimates. Technical report, Brandeis University
2021
-
[61]
Till\'e, Y. (2006). Sampling algorithms . Springer Series in Statistics. Springer, New York, NY, 1 edition
2006
-
[62]
Torvik, V. I. and Agarwal, S. (2016). Ethnea--an instance-based ethnicity classifier based on geo-coded author names in a large-scale bibliographic database
2016
-
[63]
P., Wolter, K
Tourangeau, R., Edwards, B., Johnson, T. P., Wolter, K. M., and Bates, N., editors (2014). Hard-to-survey populations . Cambridge University Press, New York
2014
-
[64]
M., Abebe, E
Twenge, J. M., Abebe, E. M., and Campbell, W. K. (2010). Fitting in or standing out: Trends in american parents' choices for children’s names, 1880–2007. Social Psychological and Personality Science , 1(1):19--25
2010
-
[65]
Tzioumis, K. (2018). Demographic aspects of first names. Scientific Data , 5:180025
2018
-
[66]
Voicu, I. (2018). Using first name information to improve race and ethnicity classification. Statistics and Public Policy , 5(1):1--13
2018
-
[67]
Waksberg, J., Judkins, D., and Massey, J. T. (1997). Geographic-based oversampling in demographic surveys of the united states. Survey Methodology , 23(1):61--71
1997
-
[68]
Wald, K. D. and Martinez, M. D. (2001). Jewish religiosity and political attitudes in the united states and israel. Political Behavior , 23(4):377--397
2001
-
[69]
Walter, T. (2005). Three ways to arrange a funeral: Mortuary variation in the modern west. Mortality , 10(3):173--192
2005
-
[70]
Weisberg, H. F. (2019). The Politics of American Jews . University of Michigan Press, Ann Arbor
2019
-
[71]
Ye, J., Han, S., Hu, Y., Coskun, B., Liu, M., Qin, H., and Skiena, S. (2017). Nationality classification using name embeddings. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management , pages 1897--1906
2017
-
[72]
and Skiena, S
Ye, J. and Skiena, S. (2019). The secret lives of names? name embeddings from social media. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages 3000--3008
2019
-
[73]
Zhang, L.-C. (2000). Post-stratification and calibration—a synthesis. The American Statistician , 54(3):178--184
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.