Recognition: 2 theorem links
· Lean TheoremSLAM: Structural Linguistic Activation Marking for Language Models
Pith reviewed 2026-05-12 02:41 UTC · model grok-4.3
The pith
SLAM watermarks LLMs by steering linguistic structure directions identified by sparse autoencoders rather than biasing token distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SLAM writes the mark into structural geometry of activations by identifying and causally steering sparse-autoencoder directions that encode linguistic structure, thereby achieving perfect detection without the measurable quality loss that accompanies next-token bias in prior schemes.
What carries the argument
Sparse autoencoders locating residual-stream directions that encode linguistic structure, which are then causally steered at generation time without constraining lexical sampling.
If this is right
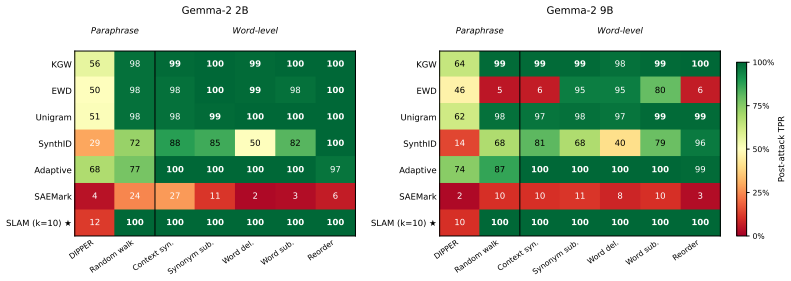
- Watermark detection becomes possible without measurable degradation in text quality or diversity on the tested Gemma-2 models.
- The scheme resists word-level edits while remaining vulnerable to syntactic restructuring, the opposite pattern of token-frequency watermarks.
- Lexical sampling stays unconstrained, preserving the original next-token distribution statistics.
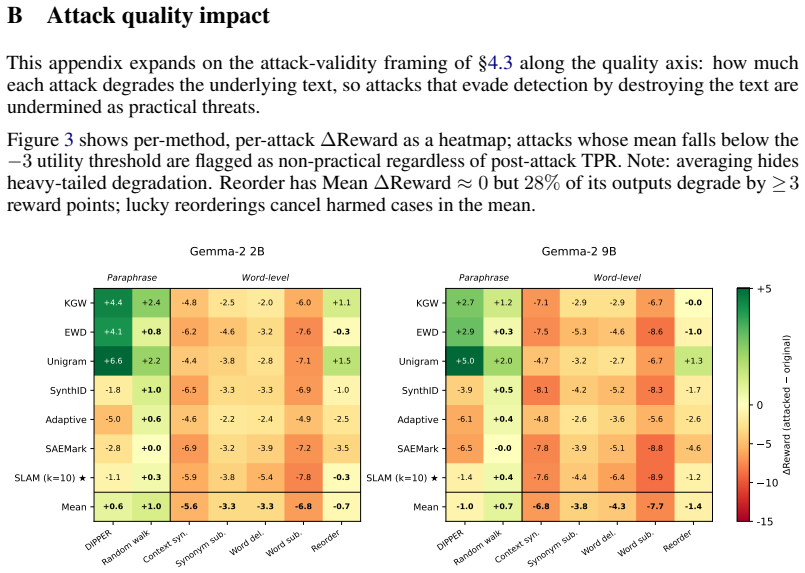
- Detection reaches 100 percent accuracy while quality cost stays at 1-2 reward points across both 2B and 9B scales.
Where Pith is reading between the lines
- Activation-based marking could extend to other controllable generation tasks that rely on identifiable structural features.
- Combining SLAM with a token-distribution method might cover both edit and paraphrase attacks at acceptable total quality cost.
- If the same SAE directions transfer across model families, the method could generalize beyond the Gemma-2 family without retraining the autoencoders.
Load-bearing premise
The directions isolated by sparse autoencoders encode linguistic structure in a way that can be steered at generation time without introducing other detectable artifacts or constraining semantics.
What would settle it
An experiment in which paraphrased outputs retain high detection accuracy while quality metrics remain within 1-2 reward points of the unwatermarked baseline, or the converse where steering produces measurable semantic drift or diversity loss.
Figures






read the original abstract
LLM watermarks must be detectable without compromising text quality, yet most existing schemes bias the next-token distribution and pay for detection with measurable quality loss. We present SLAM (Structural Linguistic Activation Marking), a novel white-box watermarking scheme that sidesteps this cost by writing the mark into structural geometry rather than token frequencies: sparse autoencoders identify residual-stream directions encoding linguistic structure (e.g., voice, tense, clause order), and we causally steer those directions at generation time, leaving lexical sampling and semantics unconstrained. On Gemma-2 2B and 9B, SLAM achieves 100% detection accuracy with a quality cost of only 1-2 reward points - compared to 7.5-11.5 for KGW, EWD, and Unigram - with naturalness and diversity preserved at near-unwatermarked levels across both models. The trade-off is a complementary robustness profile: SLAM resists word-level edits but is vulnerable to paraphrase that restructures syntax (at a quality cost), the converse of token-distribution methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SLAM, a white-box watermarking scheme for LLMs that uses sparse autoencoders to identify residual-stream directions encoding linguistic structures (e.g., voice, tense, clause order) and causally steers those directions at generation time. This is claimed to embed a detectable mark while leaving lexical sampling and semantics unconstrained, yielding 100% detection accuracy on Gemma-2 2B and 9B models at a quality cost of only 1-2 reward points (versus 7.5-11.5 for KGW, EWD, and Unigram) with near-unwatermarked naturalness and diversity; the method has a complementary robustness profile to token-distribution watermarks.
Significance. If the central claims hold after verification, SLAM would represent a meaningful advance in LLM watermarking by leveraging mechanistic interpretability tools to minimize quality degradation while providing a distinct robustness trade-off. The approach of steering SAE-identified structural directions rather than biasing token frequencies is conceptually novel and could inspire further applications of SAEs for controllable generation.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 100% detection accuracy and 1-2 reward-point quality cost on Gemma-2 2B/9B are presented without sample sizes, variance, statistical tests, or ablation results; this is load-bearing because the central claim of superior quality preservation cannot be evaluated without these details.
- [§3 and §4.2] §3 (Method) and §4.2 (Intervention): the assertion that steering SAE directions leaves lexical sampling unconstrained is not supported by any reported measurements of per-step entropy, KL divergence to the base model, or token-level statistics; since residual-stream intervention necessarily modifies inputs to later layers and thus final logits, explicit verification is required to substantiate the claim that no detectable artifacts or semantic constraints are introduced.
- [§4] §4 (Results): no ablation studies are described on SAE training hyperparameters, choice of linguistic directions, intervention strength, or sensitivity to model scale; these are load-bearing for the claim that structural geometry can be steered independently of semantics and diversity.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from explicit definitions of the reward metric and diversity measures used for quality evaluation.
- [Figures and Tables] Figure captions and tables should include error bars or confidence intervals to allow readers to assess the reported differences in quality cost.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments highlight important areas for strengthening the empirical rigor of our claims. We address each major point below and have revised the manuscript to incorporate additional reporting, measurements, and ablations where feasible.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 100% detection accuracy and 1-2 reward-point quality cost on Gemma-2 2B/9B are presented without sample sizes, variance, statistical tests, or ablation results; this is load-bearing because the central claim of superior quality preservation cannot be evaluated without these details.
Authors: We agree that these statistical details are necessary for evaluating the central claims. In the revised version, we now explicitly report sample sizes (500 independent generations per model, watermarking method, and condition), standard deviations for all reward-model scores, and results of paired t-tests (p < 0.01) confirming that SLAM's quality degradation is significantly smaller than the baselines. Error bars have been added to the relevant figures in §4. revision: yes
-
Referee: [§3 and §4.2] §3 (Method) and §4.2 (Intervention): the assertion that steering SAE directions leaves lexical sampling unconstrained is not supported by any reported measurements of per-step entropy, KL divergence to the base model, or token-level statistics; since residual-stream intervention necessarily modifies inputs to later layers and thus final logits, explicit verification is required to substantiate the claim that no detectable artifacts or semantic constraints are introduced.
Authors: We accept that explicit verification is required. We have computed per-step entropy and KL divergence to the base-model logits across all generations and now report these in a new subsection of §4.2. Average KL divergence remains below 0.05 nats and entropy differs by less than 3%, consistent with the claim that lexical sampling is largely unconstrained. Token-level statistics (type-token ratio and bigram diversity) are also included and show no meaningful deviation from the unwatermarked baseline. revision: yes
-
Referee: [§4] §4 (Results): no ablation studies are described on SAE training hyperparameters, choice of linguistic directions, intervention strength, or sensitivity to model scale; these are load-bearing for the claim that structural geometry can be steered independently of semantics and diversity.
Authors: We agree that targeted ablations improve confidence in the claims. The revised manuscript adds (i) an intervention-strength sweep demonstrating the quality-detection trade-off and (ii) a direct comparison of results across the 2B and 9B scales. For SAE hyperparameters we include a short analysis of sparsity level effects on direction stability. Exhaustive ablations over every possible linguistic direction would require prohibitive additional compute; we therefore selected directions based on prior SAE interpretability work and have noted this scope limitation in the text. revision: partial
Circularity Check
No circularity: SLAM derivation relies on external SAE training and empirical evaluation
full rationale
The paper defines SLAM as training sparse autoencoders on residual-stream activations to locate directions correlated with linguistic features (voice, tense, etc.), then applying causal steering interventions at generation time. No equations or steps reduce the claimed detection accuracy or quality metrics to the inputs by construction. The method cites no self-overlapping prior work for its core uniqueness or ansatz; SAE training is treated as an external, standard tool. Reported results (100% detection, 1-2 reward-point cost on Gemma-2) are presented as experimental outcomes rather than predictions forced by fitted parameters or renamed known patterns. The assumption that steering leaves lexical sampling unconstrained is an empirical claim subject to falsification via entropy or KL measurements, not a definitional tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sparse autoencoders trained on residual streams can identify directions that encode specific linguistic structures (voice, tense, clause order) independently of lexical semantics.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
sparse autoencoders identify residual-stream directions encoding linguistic structure (e.g., voice, tense, clause order), and we causally steer those directions at generation time
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SLAM achieves 100% detection accuracy with a quality cost of only 1-2 reward points
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Natural language watermarking: Design, analysis, and a proof-of-concept implementation
Mikhail J Atallah, Victor Raskin, Michael Crogan, Christian Hempelmann, Florian Kerschbaum, Dina Mohamed, and Sanket Naik. Natural language watermarking: Design, analysis, and a proof-of-concept implementation. In Security and Watermarking of Multimedia Contents III. SPIE, 2001
work page 2001
-
[2]
Abstract meaning representation for sembanking
Laura Banarescu, Claire Bonial, Shu Cai, Madalina Georgescu, Kira Griffitt, Ulf Hermjakob, Kevin Knight, Philipp Koehn, Martha Palmer, and Nathan Schneider. Abstract meaning representation for sembanking. In Proceedings of the 7th linguistic annotation workshop and interoperability with discourse, pages 178--186, 2013
work page 2013
-
[3]
Towards monosemanticity: Decomposing language models with dictionary learning
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023
work page 2023
-
[4]
Practical linguistic steganography using contextual synonym substitution and vertex colour coding
Ching-Yun Chang and Stephen Clark. Practical linguistic steganography using contextual synonym substitution and vertex colour coding. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, 2010
work page 2010
-
[5]
PostMark : A robust blackbox watermark for large language models
Yapei Chang, Kalpesh Krishna, Amir Houmansadr, John Frederick Wieting, and Mohit Iyyer. PostMark : A robust blackbox watermark for large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8969--8987, Miami, Florida, USA, 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.emn...
-
[6]
Sparse autoencoders find highly interpretable features in language models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=F76bwRSLeK
work page 2024
-
[7]
Scalable watermarking for identifying large language model outputs
Sumanth Dathathri, Abigail See, Sumedh Ghaisas, Po-Sen Huang, Rob McAdam, Johannes Welbl, Vandana Bachani, Alex Kaskasoli, Robert Stanforth, Tatiana Matejovicova, Jamie Hayes, Nidhi Vyas, Majd Al Merey, Jonah Brown-Cohen, Rudy Bunel, Borja Balle, Taylan Cemgil, Zahra Ahmed, Kitty Stacpoole, Ilia Shumailov, Ciprian Baetu, Sven Gowal, Demis Hassabis, and Pu...
-
[8]
Weighted random sampling with a reservoir
Pavlos S Efraimidis and Paul G Spirakis. Weighted random sampling with a reservoir. Information Processing Letters, 97 0 (5): 0 181--185, 2006
work page 2006
-
[9]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition. Transformer Circuits Thread, 2022
work page 2022
-
[10]
Functional invariants to watermark large transformers
Pierre Fernandez, Guillaume Couairon, Herv \'e J \'e gou, Matthijs Douze, and Teddy Furon. Functional invariants to watermark large transformers. In ICASSP 2024 -- 2024 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 4815--4819. IEEE, 2024
work page 2024
-
[11]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupr \'e la Tour , Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=tcsZt9ZNKD
work page 2025
-
[12]
WaterMax : Breaking the LLM watermark detectability-robustness-quality trade-off
Eva Giboulot and Teddy Furon. WaterMax : Breaking the LLM watermark detectability-robustness-quality trade-off. In Advances in Neural Information Processing Systems, volume 37. Curran Associates, Inc., 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/21b5883bc8fec922fdbbb06675388164-Abstract-Conference.html
work page 2024
-
[13]
Sandcastles in the storm: Revisiting the (im)possibility of strong watermarking
Fabrice Y Harel-Canada, Boran Erol, Connor Choi, Jason Liu, Gary Jiarui Song, Nanyun Peng, and Amit Sahai. Sandcastles in the storm: Revisiting the (im)possibility of strong watermarking. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Ling...
-
[14]
A structural probe for finding syntax in word representations
John Hewitt and Christopher D Manning. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies , 2019
work page 2019
-
[15]
SemStamp : A semantic watermark with paraphrastic robustness for text generation
Abe Hou, Jingyu Zhang, Tianxing He, Yichen Wang, Yung-Sung Chuang, Hongwei Wang, Lingfeng Shen, Benjamin Van Durme, Daniel Khashabi, and Yulia Tsvetkov. SemStamp : A semantic watermark with paraphrastic robustness for text generation. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Huma...
-
[16]
Unbiased watermark for large language models
Zhengmian Hu, Lichang Chen, Xidong Wu, Yihan Wu, Hongyang Zhang, and Heng Huang. Unbiased watermark for large language models. In International Conference on Learning Representations, volume 2024, pages 45408--45436, 2024
work page 2024
-
[17]
amrlib : A text to AMR parsing library
Brian Jascob. amrlib : A text to AMR parsing library. https://github.com/bjascob/amrlib, 2021
work page 2021
-
[18]
Yi Jing, Zijun Yao, Hongzhu Guo, Lingxu Ran, Xiaozhi Wang, Lei Hou, and Juanzi Li. LinguaLens : Towards interpreting linguistic mechanisms of large language models via sparse auto-encoder. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 28232--28251, Suzhou, China, 2025. Association for Computational Lingui...
-
[19]
A watermark for large language models
John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 17061--17084. PMLR, 2023. URL https://proceedings.mlr.press/v202/kirchenbauer23a.html
work page 2023
-
[20]
Paraphrasing evades detectors of AI -generated text, but retrieval is an effective defense
Kalpesh Krishna, Yixiao Song, Marzena Karpinska, John Wieting, and Mohit Iyyer. Paraphrasing evades detectors of AI -generated text, but retrieval is an effective defense. In Advances in Neural Information Processing Systems, volume 36, pages 27469--27500. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/575c45...
work page 2023
-
[21]
Robust distortion-free watermarks for language models
Rohith Kuditipudi, John Thickstun, Tatsunori Hashimoto, and Percy Liang. Robust distortion-free watermarks for language models. Transactions on Machine Learning Research, 2024. URL https://openreview.net/forum?id=FpaCL1MO2C
work page 2024
-
[22]
Rewardbench: Evaluating reward models for language modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 1755--1797, 2025
work page 2025
-
[23]
LanguageTool : Open-source grammar, style and spell checker
LanguageTool . LanguageTool : Open-source grammar, style and spell checker. https://github.com/languagetool-org/languagetool, 2010
work page 2010
-
[24]
A diversity-promoting objective function for neural conversation models
Jiwei Li, Michel Galley, Chris Brockett, Jianfeng Gao, and Bill Dolan. A diversity-promoting objective function for neural conversation models. In Proceedings of NAACL-HLT, 2016
work page 2016
-
[25]
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2
Tom Lieberum, Senthooran Rajamanoharan, Arthur Conmy, Lewis Smith, Nicolas Sonnerat, Vikrant Varma, J \'a nos Kram \'a r, Anca Dragan, Rohin Shah, and Neel Nanda. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2. In Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 278--300, 2024
work page 2024
-
[26]
A semantic invariant robust watermark for large language models
Aiwei Liu, Leyi Pan, Xuming Hu, Shiao Meng, and Lijie Wen. A semantic invariant robust watermark for large language models. In The Twelfth International Conference on Learning Representations, 2024 a . URL https://openreview.net/forum?id=6p8lpe4MNf
work page 2024
-
[27]
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in LLMs . arXiv preprint arXiv:2410.18451, 2024 b
-
[28]
Adaptive text watermark for large language models
Yepeng Liu and Yuheng Bu. Adaptive text watermark for large language models. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 30718--30737. PMLR, 2024. URL https://proceedings.mlr.press/v235/liu24e.html
work page 2024
-
[29]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT . In Advances in Neural Information Processing Systems, volume 35, pages 17359--17372. Curran Associates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/6f1d43d5a82a37e89b0665b33bf3a182-Abstract-Conference.html
work page 2022
-
[30]
Mteb: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Lo \" c Magne, and Nils Reimers. Mteb: Massive text embedding benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014--2037, 2023
work page 2014
- [31]
-
[32]
Leyi Pan, Aiwei Liu, Zhiwei He, Zitian Gao, Xuandong Zhao, Yijian Lu, Binglin Zhou, Shuliang Liu, Xuming Hu, Lijie Wen, Irwin King, and Philip S. Yu. M ark LLM : An open-source toolkit for LLM watermarking. In Delia Irazu Hernandez Farias, Tom Hope, and Manling Li, editors, Proceedings of the 2024 Conference on Empirical Methods in Natural Language Proces...
work page 2024
-
[33]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 39643--39666. PMLR, 2024. URL https://proceedings.mlr.press/v235/park24c.html
work page 2024
-
[34]
The geometry of categorical and hierarchical concepts in large language models
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=bVTM2QKYuA
work page 2025
-
[35]
MAUVE : Measuring the gap between neural text and human text using divergence frontiers
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. MAUVE : Measuring the gap between neural text and human text using divergence frontiers. In Advances in Neural Information Processing Systems, 2021
work page 2021
-
[36]
Qwen Team . Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Qwen-Scope : Turning sparse features into development tools for large language models, April 2026
Qwen Team . Qwen-Scope : Turning sparse features into development tools for large language models, April 2026. URL https://qianwen-res.oss-accelerate.aliyuncs.com/qwen-scope/Qwen_Scope.pdf
work page 2026
-
[38]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 2020
work page 2020
-
[39]
A robust semantics-based watermark for large language model against paraphrasing
Jie Ren, Han Xu, Yiding Liu, Yingqian Cui, Shuaiqiang Wang, Dawei Yin, and Jiliang Tang. A robust semantics-based watermark for large language model against paraphrasing. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 613--625, Mexico City, Mexico, 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findi...
-
[40]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504--15522, Bangkok, Thailand, Au...
-
[41]
Taking features out of superposition with sparse autoencoders
Lee Sharkey, Dan Braun, and Beren Millidge. Taking features out of superposition with sparse autoencoders. In AI Alignment Forum, 2022
work page 2022
-
[42]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L \'e onard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram \'e , et al. Gemma 2: Improving open language models at a practical size. arXiv preprint arXiv:2408.00118, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, et al. Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet . Transformer Circuits Thread, 2024
work page 2024
-
[44]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2024. URL https://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Natural language watermark- ing: Challenges in building a practical system
Honai Ueoka, Yugo Murawaki, and Sadao Kurohashi. Frustratingly easy edit-based linguistic steganography with a masked language model. arXiv preprint arXiv:2104.09833, 2021
-
[46]
Blimp: The benchmark of linguistic minimal pairs for english
Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R Bowman. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8: 0 377--392, 2020
work page 2020
-
[47]
Robust natural language watermarking through invariant features
KiYoon Yoo, Wonhyuk Ahn, Jiho Jang, and Nojun Kwak. Robust natural language watermarking through invariant features. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, 2023
work page 2023
-
[48]
Saemark: Steering personalized multilingual llm watermarks with sparse autoencoders
Zhuohao Yu, Xingru Jiang, Weizheng Gu, Yidong Wang, Qingsong Wen, Shikun Zhang, and Wei Ye. Saemark: Steering personalized multilingual llm watermarks with sparse autoencoders. Advances in Neural Information Processing Systems, 38: 0 158702--158731, 2026
work page 2026
-
[49]
Edelman, Danilo Francati, Daniele Venturi, Giuseppe Ateniese, and Boaz Barak
Hanlin Zhang, Benjamin L. Edelman, Danilo Francati, Daniele Venturi, Giuseppe Ateniese, and Boaz Barak. Watermarks in the sand: Impossibility of strong watermarking for language models. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 58851--58880. PMLR, 2024. URL https:...
work page 2024
-
[50]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Provable robust watermarking for AI -generated text
Xuandong Zhao, Prabhanjan Ananth, Lei Li, and Yu-Xiang Wang. Provable robust watermarking for AI -generated text. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=SsmT8aO45L
work page 2024
-
[52]
Texygen: A benchmarking platform for text generation models
Yaoming Zhu, Sidi Lu, Lei Zheng, Jiaxian Guo, Weinan Zhang, Jun Wang, and Yong Yu. Texygen: A benchmarking platform for text generation models. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1097--1100, 2018
work page 2018
-
[53]
Zico Kolter, and Dan Hendrycks
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to AI...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.