Recognition: unknown
GRALIS: A Unified Canonical Framework for Linear Attribution Methods via Riesz Representation
Pith reviewed 2026-05-08 17:00 UTC · model grok-4.3
The pith
Every additive linear continuous attribution method on square-integrable functions has a unique canonical form via the Riesz theorem.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
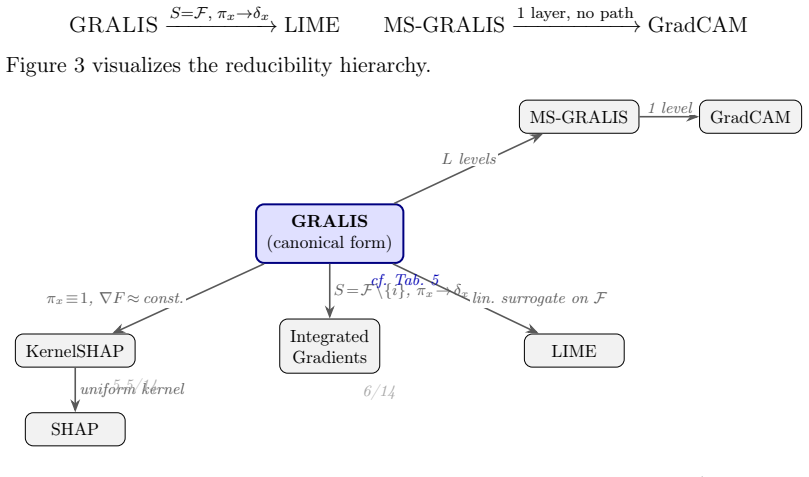
GRALIS establishes that every additive, linear, and continuous attribution functional on L^2(Q, μ) admits a unique canonical representation (Q, w, Δ) proved necessary by the Riesz Representation Theorem. This class encompasses SHAP, IG, LIME and linearized GradCAM. Seven theorems deliver exact completeness, Monte Carlo convergence O(1/sqrt(m))+O(1/k), exact Shapley interaction values, Hoeffding ANOVA decomposition, Sobol sensitivity generalization, and a multi-scale extension (MS-GRALIS) with minimum-variance weights.
What carries the argument
The Riesz Representation Theorem applied to linear continuous functionals on L^2(Q, μ), which forces every such attribution to be expressed by the triple (Q, w, Δ).
Load-bearing premise
The methods being unified must be additive, linear, and continuous functionals on the chosen L^2 space.
What would settle it
An attribution method that is additive, linear and continuous yet cannot be written in the (Q, w, Δ) form, or a listed method that violates one of the seven stated theorems.
Figures


read the original abstract
The main XAI attribution methods for deep neural networks -- GradCAM, SHAP, LIME, Integrated Gradients -- operate on separate theoretical foundations and are not formally comparable. We present GRALIS (Gradient-Riesz Averaged Locally-Integrated Shapley), a mathematical framework establishing a representation theory for attributions: every additive, linear, and continuous attribution functional on L^2(Q,mu) admits a unique canonical representation (Q, w, Delta), proved necessary by the Riesz Representation Theorem. This class encompasses SHAP, IG, LIME and linearized GradCAM, but excludes nonlinear functionals such as standard GradCAM or attention maps. Seven formal theorems provide simultaneous guarantees absent in any individual method: (T1) necessary canonical form; (T2) exact completeness; (T3) Monte Carlo convergence O(1/sqrt(m))+O(1/k); (T4) exact Shapley Interaction Values; (T5) Hoeffding ANOVA decomposition; (T6) Sobol sensitivity generalization; (T7) multi-scale extension (MS-GRALIS) with minimum-variance weights. An algebraic appendix justifies the GRALIS-SIV correspondence via the Mobius transform without circularity. GRALIS satisfies 13.5/14 axiomatic properties vs. 2.5-6/14 for individual methods, including completeness, sensitivity, locality, order-k interactions and optimal multi-scale aggregation simultaneously. Preliminary validation on BreaKHis (1,187 histology images, DenseNet-121) reports deletion faithfulness AUC +0.015 (malignant), 96% class-conditional consistency, SAL = 0.762+/-0.109 and sparsity index 0.39. Extended comparison with baseline XAI methods is planned for a companion paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GRALIS, a framework based on the Riesz Representation Theorem asserting that every additive, linear, and continuous attribution functional on the Hilbert space L^2(Q, mu) admits a unique canonical representation (Q, w, Delta). It claims this class includes SHAP, Integrated Gradients, LIME, and linearized GradCAM (but excludes nonlinear methods such as standard GradCAM), and presents seven theorems guaranteeing necessary form (T1), exact completeness (T2), Monte Carlo convergence (T3), exact Shapley Interaction Values (T4), Hoeffding ANOVA decomposition (T5), Sobol sensitivity generalization (T6), and a multi-scale extension MS-GRALIS with minimum-variance weights (T7). An algebraic appendix justifies the GRALIS-SIV link via the Möbius transform without circularity. The framework is said to satisfy 13.5/14 axiomatic properties simultaneously. Preliminary numerical results on the BreaKHis dataset (1,187 images, DenseNet-121) report deletion faithfulness AUC improvements and other metrics.
Significance. If the central claims hold, the work would be significant for XAI by supplying a single representation theory that simultaneously delivers completeness, sensitivity, locality, order-k interactions, and optimal multi-scale aggregation—properties that no individual method satisfies together. The algebraic appendix addressing non-circularity and the parameter-free character inherited from the Riesz theorem are explicit strengths. The Monte Carlo rate O(1/sqrt(m)) + O(1/k) and the Hoeffding/Sobol connections would also be valuable if rigorously established for the listed methods.
major comments (1)
- [Abstract (statements of T1–T7) and algebraic appendix] The central claim that SHAP, IG, LIME, and linearized GradCAM belong to the class of continuous linear functionals on the entire L^2(Q, mu) is load-bearing for all seven theorems. Standard definitions of these methods are given only for a fixed model f and a specific input distribution; the manuscript must supply explicit embeddings or constructions showing that the resulting functionals remain linear and bounded (hence continuous) when extended to arbitrary square-integrable functions while exactly reproducing the original numerical values. Without this step, T1–T7 apply only to idealized surrogates rather than the published algorithms.
minor comments (2)
- [Empirical validation paragraph] The abstract reports only preliminary results on a single dataset and defers full baseline comparisons to a companion paper; the main text should include at least one additional dataset and direct numerical comparison with the original SHAP/IG/LIME implementations to support the claimed faithfulness gains.
- [Introduction / Theorem statements] Notation for the canonical triple (Q, w, Delta) and the precise definition of the measure mu should be introduced earlier and used consistently when stating the theorems.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying this foundational point. The concern about explicit embeddings is well-taken and directly affects the scope of Theorems T1–T7. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (statements of T1–T7) and algebraic appendix] The central claim that SHAP, IG, LIME, and linearized GradCAM belong to the class of continuous linear functionals on the entire L^2(Q, mu) is load-bearing for all seven theorems. Standard definitions of these methods are given only for a fixed model f and a specific input distribution; the manuscript must supply explicit embeddings or constructions showing that the resulting functionals remain linear and bounded (hence continuous) when extended to arbitrary square-integrable functions while exactly reproducing the original numerical values. Without this step, T1–T7 apply only to idealized surrogates rather than the published algorithms.
Authors: We agree that the referee's observation is correct: the manuscript currently states that the listed methods belong to the class of continuous linear functionals on L^2(Q, mu) but does not supply the explicit embeddings or boundedness proofs needed to justify this for the standard published algorithms. In the revised manuscript we will add a dedicated subsection (placed after the definition of the GRALIS triple and before the statement of the theorems) that provides the required constructions. For each method we will (i) define the corresponding functional on the full L^2 space, (ii) verify linearity in the model output, (iii) prove boundedness with respect to the L^2 norm (using the background measure and the specific form of each method), and (iv) show that the functional coincides with the original numerical output on the domain where the method is conventionally defined. These additions will ensure that T1–T7 apply directly to the published algorithms rather than to idealized surrogates. We will also update the abstract, introduction, and algebraic appendix to reference the new material and will include a short table summarizing the embedding for each method. revision: yes
Circularity Check
No circularity; central claim applies external Riesz theorem to assumed linear functionals
full rationale
The derivation rests on the standard Riesz Representation Theorem (an external result from functional analysis) to obtain the unique canonical (Q, w, Delta) form for any additive linear continuous functional on L^2(Q, mu). The abstract states that the GRALIS-SIV correspondence is justified algebraically via the Möbius transform without circularity. No parameters are fitted on a data subset and then presented as predictions, no self-definitional loops exist (e.g., X defined in terms of Y and vice versa), and no load-bearing self-citations or uniqueness theorems imported from the authors' prior work appear. The claim that SHAP/IG/LIME/linearized GradCAM belong to the class is a substantive modeling assumption rather than a tautology; the paper is therefore self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Riesz Representation Theorem: every continuous linear functional on a Hilbert space has a unique representation via inner product with an element of the space
invented entities (1)
-
GRALIS canonical triple (Q, w, Delta)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., & Batra, D. (2017). Grad-CAM: Visual explanations from deep networks via gradient-based localization. ICCV, 618–626
2017
-
[2]
Lundberg, S.M., & Lee, S.-I. (2017). A unified approach to interpreting model predic- tions.NeurIPS 30
2017
-
[3]
Why should I trust you?
Ribeiro, M.T., Singh, S., & Guestrin, C. (2016). “Why should I trust you?”: Explaining the predictions of any classifier.KDD, 1135–1144
2016
-
[4]
Sundararajan, M., Taly, A., & Yan, Q. (2017). Axiomatic attribution for deep networks. ICML, 3319–3328
2017
-
[5]
Ancona, M., Ceolini, E., Öztireli, C., & Gross, M. (2018). Towards better understanding of gradient-based attribution methods for deep neural networks.ICLR. 23
2018
-
[6]
Montavon, G., Lapuschkin, S., Binder, A., Müller, K.-R., & Samek, W. (2017). Explain- ing nonlinear classification decisions with deep Taylor decomposition.Pattern Recogni- tion, 65, 211–222
2017
-
[7]
Simonyan, K., Vedaldi, A., & Zisserman, A. (2013). Deep inside convolutional net- works: Visualising image classification models and saliency maps.arXiv preprint arXiv:1312.6034
work page Pith review arXiv 2013
-
[8]
Chattopadhyay, A., Sarkar, A., Howlader, P., & Balasubramanian, V.N. (2018). Grad- CAM++: Generalized gradient-based visual explanations for deep convolutional net- works.WACV, 839–847
2018
-
[9]
Covert, I., & Lee, S.-I. (2021). Improving KernelSHAP: Practical Shapley value estima- tion using linear regression.AISTATS
2021
-
[10]
Lundstrom, D., Jain, T., & Koyejo, S. (2022). A rigorous study of integrated gradi- ents method and extensions to internal neuron attributions.Transactions on Machine Learning Research (TMLR)
2022
-
[11]
Kindermans, P.-J., Hooker, S., Adebayo, J., Alber, M., Schütt, K.T., Dähne, S., Erhan, D., & Kim, B. (2019). The (un)reliability of saliency methods. InExplainability of AI, Springer LNCS, pp. 267–280
2019
-
[12]
Hooker, S., Erhan, D., Kindermans, P.-J., & Kim, B. (2019). A benchmark for inter- pretability methods in deep neural networks.NeurIPS 32
2019
-
[13]
Wang, H., Wang, Z., Du, M., Yang, F., Zhang, Z., Ding, S., Mardziel, P., & Hu, X. (2020). Score-CAM: Score-weighted visual explanations for convolutional neural net- works.CVPR Workshops
2020
-
[14]
Fu, R., Hu, Q., Dong, X., Guo, Y., Gao, Y., & Li, B. (2020). Axiom-based Grad-CAM: Towards accurate visualization and explanation of CNNs.BMVC
2020
- [15]
-
[16]
Petsiuk, V., Das, A., & Saenko, K. (2018). RISE: Randomized input sampling for ex- planation of black-box models.BMVC
2018
- [17]
-
[18]
Bhatt, U., Weller, A., &Moura, J.M.F.(2020).Evaluatingandaggregatingfeature-based model explanations.IJCAI, 3016–3022
2020
-
[19]
Grabisch, M., & Roubens, M. (1999). An axiomatic approach to the concept of interac- tion among players in cooperative games.International Journal of Game Theory, 28(4), 547–565
1999
-
[20]
Hoeffding, W. (1948). A class of statistics with asymptotically normal distribution.An- nals of Mathematical Statistics, 19(3), 293–325
1948
-
[21]
Efron, B., & Stein, C. (1981). The jackknife estimate of variance.Annals of Statistics, 9(3), 586–596
1981
-
[22]
Sobol’, I.M. (1993). Sensitivity estimates for nonlinear mathematical models.Mathemat- ical Modelling and Computational Experiments, 1(4), 407–414. 24
1993
-
[23]
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., & Süsstrunk, S. (2012). SLIC su- perpixels compared to state-of-the-art superpixel methods.IEEE TPAMI, 34(11), 2274– 2282
2012
-
[24]
A., Oliveira, L
Spanhol, F. A., Oliveira, L. S., Petitjean, C., & Heutte, L. (2016). A dataset for breast cancer histological image classification.IEEE Transactions on Biomedical Engineering, 63(7), 1455–1462
2016
-
[25]
Riesz, F. (1909). Sur les opérations fonctionnelles linéaires.Comptes Rendus de l’Académie des Sciences, 149, 974–977
1909
-
[26]
Fanale, R., Martini, G., Sciarrone, F., & Caldelli, R. (2026). Explainable ar- tificial intelligence for the analysis of histopathological images of breast cancer: Methods, interpretability and emerging directions.Frontiers in Signal Processing. doi:10.3389/frsip.2026.1795809
-
[27]
Fanale, R. et al. (2025). ExpiScore: A quantitative framework for evaluating XAI meth- ods in medical imaging. Manuscript under review.Transparency note: this work shares authorship with the present paper; results involving ExpiScore should be interpreted with this in mind
2025
-
[28]
Fanale, R. (2026). GRALIS-LLM: Multimodal explainable AI for automated clinical report generation in breast cancer histology. Manuscript in preparation. 25
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.