Recognition: unknown
ReaComp: Compiling LLM Reasoning into Symbolic Solvers for Efficient Program Synthesis
Pith reviewed 2026-05-08 16:08 UTC · model grok-4.3
The pith
LLM reasoning traces can be compiled into reusable symbolic solvers that solve hard program synthesis tasks efficiently without test-time LLM calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
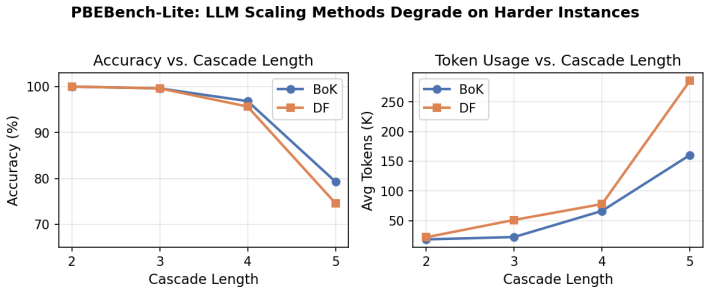
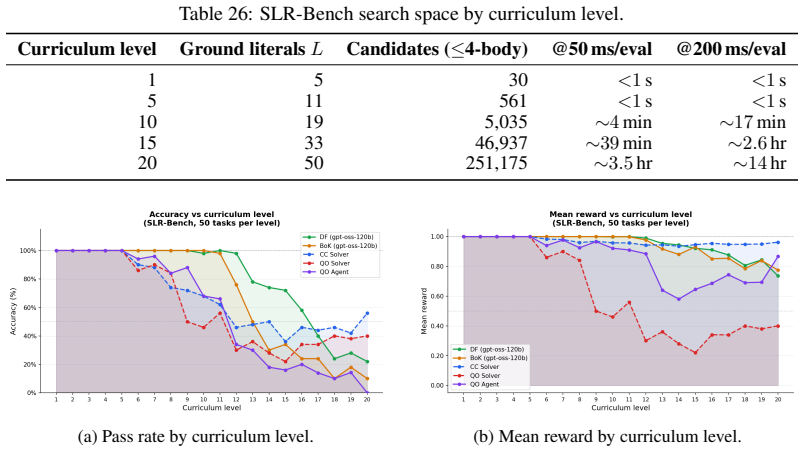
Given a small set of reasoning traces, coding agents compile them into reusable symbolic program synthesizers over constrained DSLs. The resulting solvers require no LLM calls at test time and are strong standalone systems: symbolic solver ensembles reach 91.3% accuracy on PBEBench-Lite and 84.7% on PBEBench-Hard, outperforming LLMs with test-time scaling for the latter by +16.3 percentage points at zero LLM inference cost. They also complement LLM search, improving PBEBench-Hard accuracy from 68.4% to 85.8% while reducing reported token usage by 78%, and raising SLR-Bench hard-tier accuracy from 34.4% to 58.0% in a neuro-symbolic hybrid setting. Most solvers transfer zero-shot to predicting
What carries the argument
Symbolic solvers induced from LLM reasoning traces by coding agents over constrained DSLs, which amortize one-time construction across many zero-token executions.
If this is right
- Symbolic solver ensembles achieve over 84 percent accuracy on hard program synthesis benchmarks with no LLM calls at test time.
- Hybrid neuro-symbolic systems raise accuracy on hard tiers while cutting token usage by 78 percent.
- Induced solvers transfer zero-shot to unrelated domains such as historical linguistics sound-change prediction at 80 percent ensemble accuracy.
- Construction from few traces provides a scalable alternative to per-instance LLM solving by amortizing cost over repeated use.
- Induced solvers are substantially more Pareto-efficient than using coding agents directly for each new instance.
Where Pith is reading between the lines
- The method could extend to other fields with symbolic structure, such as automated theorem proving or scientific modeling, from limited examples.
- Fewer LLM calls for routine synthesis tasks would lower overall inference costs and energy demands.
- Success on linguistics data indicates potential for rule-induction problems in biology or chemistry where DSLs can capture domain constraints.
- Expressiveness limits of the chosen DSLs may restrict use on problems lacking clear symbolic decompositions.
Load-bearing premise
A small set of reasoning traces suffices for coding agents to induce correct and generalizable symbolic solvers over suitable constrained domain-specific languages.
What would settle it
If solvers induced from a handful of traces fail to solve most novel instances in the same domain or underperform direct LLM search on hard cases, the claim that compilation yields reusable general solvers would be falsified.
Figures








read the original abstract
LLMs can solve program synthesis tasks but remain inefficient and unreliable on hard instances requiring large combinatorial search. Given a small set of reasoning traces, we use coding agents to compile them into reusable symbolic program synthesizers over constrained DSLs. The resulting solvers require no LLM calls at test time and are strong standalone systems: symbolic solver ensembles reach 91.3% accuracy on PBEBench-Lite and 84.7% on PBEBench-Hard, outperforming LLMs with test-time scaling for the latter by +16.3 percentage points at zero LLM inference cost. They also complement LLM search, improving PBEBench-Hard accuracy from 68.4% to 85.8% while reducing reported token usage by 78%, and raising SLR-Bench hard-tier accuracy from 34.4% to 58.0% in a neuro-symbolic hybrid setting. Compared to directly using coding agents as per-instance solvers, induced solvers are substantially more Pareto-efficient, amortizing a small one-time construction cost over many zero-token executions. Finally, most solvers transfer zero-shot to a real historical linguistics task - predicting sound changes in natural language data - reaching 80.1% accuracy under ensembling and recovering some plausible linguistic rules. Together, these results show that reasoning traces can be compiled into reusable symbolic solvers that solve many tasks directly, complement LLM inference on hard cases, and provide a scalable route to domain-general solver induction. We release code and data for reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReaComp, a method to compile small sets of LLM reasoning traces into reusable symbolic program synthesizers over constrained DSLs using coding agents. These solvers require no LLM calls at inference time and are shown to achieve strong standalone performance (91.3% on PBEBench-Lite, 84.7% on PBEBench-Hard), complement LLM search in hybrid settings (e.g., raising SLR-Bench hard-tier accuracy from 34.4% to 58.0%), and transfer zero-shot to a historical linguistics task (80.1% under ensembling). The work emphasizes Pareto efficiency over per-instance coding-agent use and releases code for reproducibility.
Significance. If the central claims hold under more rigorous validation, this provides a concrete route to amortizing LLM reasoning into efficient, reusable symbolic solvers that reduce inference cost while maintaining or improving accuracy on combinatorial tasks. The empirical gains over test-time scaling baselines, the hybrid complementarity results, the zero-shot linguistics transfer, and the public code release are genuine strengths that could influence neuro-symbolic program synthesis research.
major comments (3)
- [Experimental setup and results] Experimental setup and results sections: The reported benchmark improvements (91.3% PBEBench-Lite, 84.7% Hard, +16.3 pp over LLM scaling) are presented without details on reasoning-trace selection criteria, the precise process for constructing or constraining the DSLs, error analysis of solver failures, or statistical significance testing across runs or random seeds. These omissions make it difficult to assess whether the gains are robust or sensitive to the specific traces and DSLs chosen.
- [Method and scalability discussion] Method and scalability discussion: The central claim that coding agents can induce correct, generalizable solvers from small traces rests on the assumption that appropriate constrained DSLs are available. No ablation is reported on DSL construction cost, on whether the same induction procedure succeeds when DSLs must be discovered automatically rather than supplied, or on solver generalization when traces are drawn from different distributions. This directly affects the scalability and domain-general arguments.
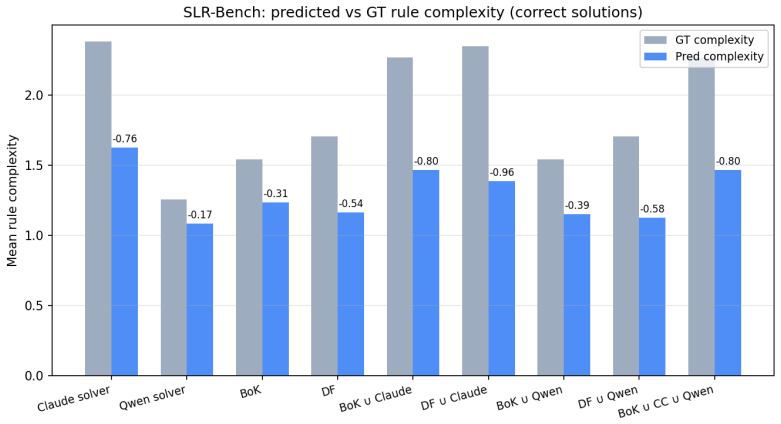
- [Transfer experiment] Transfer experiment: The 80.1% zero-shot accuracy on the historical linguistics task is presented as evidence of domain transfer, yet the paper does not clarify how the DSLs were defined or adapted for this domain, nor does it provide a breakdown of which linguistic rules were recovered versus memorized from the original traces. This weakens the claim that the approach yields domain-general solver induction.
minor comments (2)
- The abstract and main text use 'ensembling' and 'symbolic solver ensembles' without a precise description of the ensemble procedure (e.g., voting, union of solutions, or learned combination), which should be clarified for reproducibility.
- Notation for the distinction between raw LLM traces, the induced symbolic programs, and the final solvers could be made more consistent across sections to aid readability.
Simulated Author's Rebuttal
Thank you for your constructive feedback, which identifies key areas where additional details and analyses would strengthen the paper. We address each major comment point by point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental setup and results] Experimental setup and results sections: The reported benchmark improvements (91.3% PBEBench-Lite, 84.7% Hard, +16.3 pp over LLM scaling) are presented without details on reasoning-trace selection criteria, the precise process for constructing or constraining the DSLs, error analysis of solver failures, or statistical significance testing across runs or random seeds. These omissions make it difficult to assess whether the gains are robust or sensitive to the specific traces and DSLs chosen.
Authors: We agree that these details are essential for assessing robustness and reproducibility. In the revised manuscript, we will expand the Experimental Setup section to explicitly describe: (1) reasoning-trace selection criteria (filtering for successful, concise traces from the LLM); (2) the precise DSL construction and constraint process (deriving from domain specifications and pruning via traces); (3) error analysis of solver failures, categorizing cases such as DSL coverage gaps or induction errors with concrete examples; and (4) statistical results across multiple random seeds, including means, standard deviations, and significance testing against baselines. These additions will include new tables and an appendix section. revision: yes
-
Referee: [Method and scalability discussion] Method and scalability discussion: The central claim that coding agents can induce correct, generalizable solvers from small traces rests on the assumption that appropriate constrained DSLs are available. No ablation is reported on DSL construction cost, on whether the same induction procedure succeeds when DSLs must be discovered automatically rather than supplied, or on solver generalization when traces are drawn from different distributions. This directly affects the scalability and domain-general arguments.
Authors: This correctly highlights an implicit assumption in our framework. We will add a dedicated scalability subsection in the Discussion that: estimates DSL construction cost based on our process (typically requiring domain expertise for initial definition, amortized over many uses); acknowledges that automatic DSL discovery was not ablated and is left as future work with references to related neuro-symbolic literature; and provides analysis of solver generalization using existing traces drawn from mixed difficulty distributions. We will also note this as a limitation for fully domain-general claims while emphasizing that the core induction procedure remains applicable when DSLs can be supplied. revision: partial
-
Referee: [Transfer experiment] Transfer experiment: The 80.1% zero-shot accuracy on the historical linguistics task is presented as evidence of domain transfer, yet the paper does not clarify how the DSLs were defined or adapted for this domain, nor does it provide a breakdown of which linguistic rules were recovered versus memorized from the original traces. This weakens the claim that the approach yields domain-general solver induction.
Authors: We will revise the Transfer Experiment section for greater clarity. We will explain that the linguistics DSL was defined by adapting the same coding-agent induction procedure to a constrained set of sound-change primitives derived from the target domain data. We will also add a rule-recovery breakdown, analyzing each induced solver to distinguish rules directly traceable to patterns in the original program-synthesis traces (potential memorization) from those that are generalized or newly composed, supported by examples of recovered plausible linguistic rules. This analysis will be presented in the main text and appendix. revision: yes
Circularity Check
No circularity; empirical evaluation of trace-to-solver compilation
full rationale
The paper describes an empirical pipeline in which LLM-generated reasoning traces are fed to coding agents to induce symbolic solvers over supplied constrained DSLs, followed by direct accuracy measurements on public benchmarks (PBEBench-Lite/Hard, SLR-Bench) and a linguistics transfer task. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citations appear as load-bearing steps in the provided text. All reported gains (e.g., 91.3 % ensemble accuracy, 78 % token reduction) are obtained by running the induced solvers on held-out instances and comparing against LLM baselines; the central claim therefore rests on observable experimental outcomes rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can produce useful reasoning traces for program synthesis tasks
- ad hoc to paper Coding agents can reliably translate reasoning traces into correct and generalizable symbolic solvers over constrained DSLs
Reference graph
Works this paper leans on
-
[1]
Deepcoder: Learning to write programs.arXiv preprint arXiv:1611.01989,
Matej Balog, Alexander L Gaunt, Marc Brockschmidt, Sebastian Nowozin, and Daniel Tarlow. Deepcoder: Learning to write programs.arXiv preprint arXiv:1611.01989,
-
[2]
When do tools and planning help large language models think? a cost-and latency-aware benchmark
Subha Ghoshal and Ali Al-Bustami. When do tools and planning help large language models think? a cost-and latency-aware benchmark. InSoutheastCon 2026, pages 01–08. IEEE,
2026
-
[3]
Gabriel Grand, Lionel Wong, Maddy Bowers, Theo X Olausson, Muxin Liu, Joshua B Tenenbaum, and Jacob Andreas. Lilo: Learning interpretable libraries by compressing and documenting code. arXiv preprint arXiv:2310.19791,
-
[4]
doi: 10.1145/1926385.1926423. Lukas Helff, Ahmad Omar, Felix Friedrich, Antonia Wüst, Hikaru Shindo, Rupert Mitchell, Tim Woydt, Patrick Schramowski, Wolfgang Stammer, and Kristian Kersting. Slr: Automated synthesis for scalable logical reasoning.arXiv preprint arXiv:2506.15787,
-
[5]
Program-aided reasoners (better) know what they know
Anubha Kabra, Sanketh Rangreji, Yash Mathur, Aman Madaan, Emmy Liu, and Graham Neubig. Program-aided reasoners (better) know what they know. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2262–2278,
2024
-
[6]
Psychometrika12(2), 153–157 (1947)https://doi
ISSN 1860-0980. doi: 10.1007/ BF02295996. URLhttps://doi.org/10.1007/BF02295996. Atharva Naik, Darsh Agrawal, Hong Sng, Clayton Marr, Kexun Zhang, Nathaniel R Robinson, Kalvin Chang, Rebecca Byrnes, Aravind Mysore, Carolyn Rose, et al. Programming by examples meets historical linguistics: A large language model based approach to sound law induction.arXiv ...
-
[7]
A compute-matched re-evaluation of trove on math.arXiv preprint arXiv:2507.22069,
Tobias Sesterhenn, Ian Berlot-Attwell, Janis Zenkner, and Christian Bartelt. A compute-matched re-evaluation of trove on math.arXiv preprint arXiv:2507.22069,
-
[8]
Llm-erm: Sample-efficient program learning via llm-guided search.arXiv preprint arXiv:2510.14331,
Shivam Singhal, Eran Malach, Tomaso Poggio, and Tomer Galanti. Llm-erm: Sample-efficient program learning via llm-guided search.arXiv preprint arXiv:2510.14331,
-
[9]
Regal: Refactoring programs to discover generalizable abstractions.arXiv preprint arXiv:2401.16467,
Elias Stengel-Eskin, Archiki Prasad, and Mohit Bansal. Regal: Refactoring programs to discover generalizable abstractions.arXiv preprint arXiv:2401.16467,
-
[10]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review arXiv
-
[11]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better llm agents. InForty-first International Conference on Machine Learning, 2024a. Zhiruo Wang, Daniel Fried, and Graham Neubig. Trove: Inducing verifiable and efficient toolboxes for solving programmatic tasks.arXiv preprint arXiv:2401....
-
[12]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review arXiv
-
[13]
Murong Yue, Zhiwei Liu, Liangwei Yang, Jianguo Zhang, Zuxin Liu, Haolin Chen, Ziyu Yao, Silvio Savarese, Caiming Xiong, Shelby Heinecke, et al. Toollibgen: Scalable automatic tool creation and aggregation for llm reasoning.arXiv preprint arXiv:2510.07768,
-
[14]
Pbe meets llm: When few examples aren’t few-shot enough.arXiv preprint arXiv:2507.05403,
Shuning Zhang and Yongjoo Park. Pbe meets llm: When few examples aren’t few-shot enough.arXiv preprint arXiv:2507.05403,
-
[15]
arXiv preprint arXiv:2508.15754 , year=
Yufeng Zhao, Junnan Liu, Hongwei Liu, Dongsheng Zhu, Yuan Shen, Songyang Zhang, and Kai Chen. Dissecting tool-integrated reasoning: An empirical study and analysis.arXiv preprint arXiv:2508.15754,
-
[16]
•replace(’#?’, ’#h’)+replace(’aw#’, ’au#’)(→Banjarese): word-initial /?/→/h/ and diphthong shift — classic Banjarese
69.9 26.35 ratio = 1.0 43.8 10.47 ratio = 2.0 31.9 6.49 ratio = 3.0 30.5 4.82 ratio = 5.029.6 3.62 •replace(’?#’, ’h#’)+replace(’wi’, ’i’)(→Bahasa Indonesia): word-final glot- tal→/h/ and /wi/→/i/ glide deletion — both documented Indonesian changes. •replace(’#?’, ’#h’)+replace(’aw#’, ’au#’)(→Banjarese): word-initial /?/→/h/ and diphthong shift — classic ...
1947
-
[17]
The BoK+QO vs
System A System B∆Accp(Mc)∆Rewp(Wi) All Symbolic BoK + QO+2.58 0.001 ∗∗ +0.0036 0.303 All Symbolic BoK + CC+2.68<0.001 ∗∗∗ +0.0038 0.271 All Symbolic BoK + All Sym+2.68<0.001 ∗∗∗ +0.0038 0.271 All Symbolic DF + QO+1.59 0.064+0.0038 0.289 All Symbolic DF + CC+1.79 0.033 ∗ +0.0044 0.179 All Symbolic DF + All Sym+1.88 0.023 ∗ +0.0046 0.155 BoK + QO BoK + CC+...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.