Recognition: unknown
Non-Myopic Active Feature Acquisition via Pathwise Policy Gradients
Pith reviewed 2026-05-08 16:28 UTC · model grok-4.3
The pith
A continuous relaxation of feature choices lets policies optimize entire acquisition sequences for lower total cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Non-myopic pathwise policy gradients (NM-PPG) replace high-variance score-function estimators with pathwise gradients obtained from a continuous relaxation of the acquisition process; a straight-through rollout executes hard discrete acquisitions in the forward pass while routing gradients through the soft relaxation in the backward pass, and training is stabilized by entropy regularization together with staged temperature sharpening.
What carries the argument
The continuous relaxation of the discrete acquisition decisions, which turns the sequence of feature requests and stopping choices into a differentiable trajectory so that gradients can be computed directly through the entire policy rollout.
If this is right
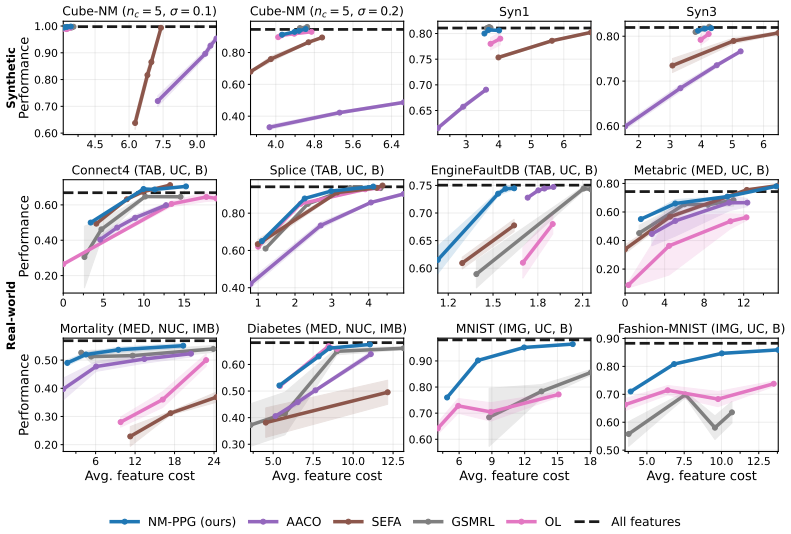
- Policies can be trained end-to-end to minimize the expected sum of all future acquisition costs plus final prediction loss rather than myopic one-step rewards.
- Gradient variance drops because pathwise derivatives avoid the score-function term, allowing stable optimization of longer-horizon policies.
- The same relaxation-plus-straight-through pattern applies to any POMDP whose actions consist of costly discrete selections followed by a terminal prediction.
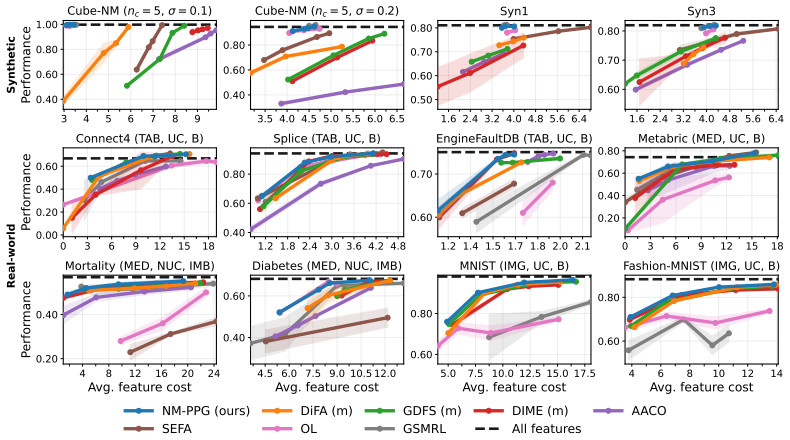
- Empirical gains appear consistently across both synthetic control problems and real-world data sets against prior state-of-the-art AFA methods.
Where Pith is reading between the lines
- The same machinery could be tested on sensor-selection tasks in robotics where each measurement consumes battery life and the agent must decide when to act on partial observations.
- If the temperature schedule is made adaptive rather than staged, the method might reduce the number of training epochs needed to reach a sharp discrete policy.
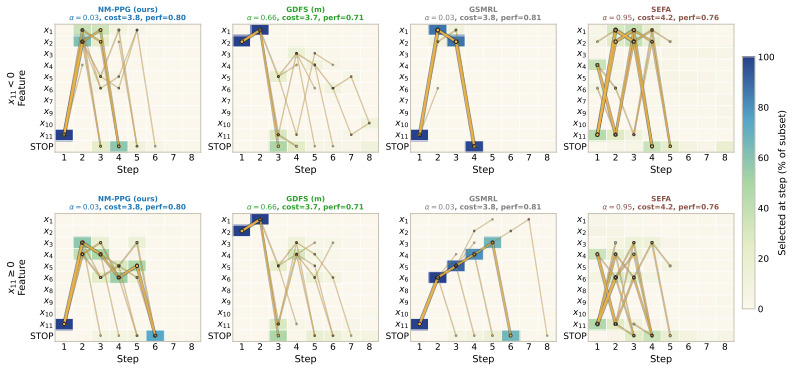
- Because the relaxation is differentiable, one could add auxiliary losses that encourage the policy to produce human-interpretable acquisition orders without changing the core training loop.
Load-bearing premise
The smooth relaxation plus straight-through estimator must preserve enough of the original discrete dynamics that the policy learned under soft decisions still performs well when only hard decisions are allowed at test time.
What would settle it
On a standard AFA benchmark, replace the learned policy with its myopic counterpart and measure whether total cost (feature acquisition expense plus prediction error) rises; if the gap disappears or reverses, the non-myopic advantage claimed for the relaxation does not hold.
Figures






read the original abstract
Active feature acquisition (AFA) considers prediction problems in which features are costly to obtain and the learner adaptively decides which feature values to acquire for each instance and when to stop and predict. AFA can be formulated as a partially observable Markov decision process (POMDP), which naturally admits a sequential decision-making perspective. In this paper, we present non-myopic pathwise policy gradients (NM-PPG), a new AFA method built around this formulation. We introduce a continuous relaxation of the acquisition process that enables pathwise gradients through the full acquisition trajectory, avoiding the high variance of standard score-function policy gradients while allowing end-to-end optimization of a non-myopic acquisition policy. To better align training with deployment, we further develop a straight-through rollout scheme that follows hard feature acquisitions in the forward pass while backpropagating through the corresponding soft relaxation in the backward pass. We stabilize optimization with entropy regularization and staged temperature sharpening. Experiments on both synthetic and real-world datasets demonstrate that NM-PPG yields superior performance relative to state-of-the-art AFA baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates active feature acquisition (AFA) as a POMDP and proposes non-myopic pathwise policy gradients (NM-PPG). It introduces a continuous relaxation of the discrete acquisition decisions to enable low-variance pathwise gradients over full trajectories, a straight-through rollout that uses hard acquisitions forward and soft gradients backward, plus entropy regularization and staged temperature sharpening for stable optimization. Experiments on synthetic and real-world datasets are reported to show superior performance versus state-of-the-art AFA baselines.
Significance. If the relaxation and estimator are shown to produce low-bias gradients for non-myopic policies, the approach could meaningfully improve end-to-end optimization of long-horizon acquisition strategies that trade off immediate cost against future information value. The pathwise gradient technique directly addresses a known limitation of score-function estimators in POMDPs, and the inclusion of both synthetic and real-world experiments provides a reasonable starting point for empirical validation.
major comments (2)
- [§3] §3 (Method), continuous relaxation and straight-through rollout: the manuscript provides no formal bias or approximation-error analysis for the relaxed objective relative to the true discrete POMDP dynamics over variable-length trajectories. Because the central claim of superior non-myopic policy optimization rests on these gradients being faithful, the absence of such analysis (or even a simple Monte-Carlo bias diagnostic) is load-bearing.
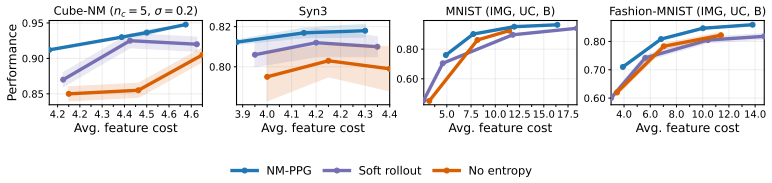
- [§4] §4 (Experiments): the reported gains versus baselines are not accompanied by an ablation that isolates the non-myopic component (e.g., a myopic variant of the same pathwise estimator) or quantifies sensitivity to the temperature schedule. Without these controls it is difficult to attribute performance improvements specifically to the non-myopic pathwise formulation rather than implementation details or regularization.
minor comments (1)
- [§3] The POMDP state and observation definitions are introduced in prose but would benefit from an explicit tabular summary of symbols, especially the relaxation function and entropy term.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [§3] §3 (Method), continuous relaxation and straight-through rollout: the manuscript provides no formal bias or approximation-error analysis for the relaxed objective relative to the true discrete POMDP dynamics over variable-length trajectories. Because the central claim of superior non-myopic policy optimization rests on these gradients being faithful, the absence of such analysis (or even a simple Monte-Carlo bias diagnostic) is load-bearing.
Authors: We agree that the absence of a bias or approximation-error analysis for the continuous relaxation and straight-through rollout constitutes a substantive gap, especially for variable-length trajectories. While the straight-through estimator draws from established discrete optimization methods, we will add a dedicated subsection in the revised manuscript containing a Monte-Carlo bias diagnostic. On small synthetic POMDPs with short, enumerable horizons we will compute exact pathwise gradients via enumeration and compare them to the relaxed estimator outputs, reporting empirical bias and variance across trajectory lengths. This will provide concrete evidence on the estimator's fidelity. revision: yes
-
Referee: [§4] §4 (Experiments): the reported gains versus baselines are not accompanied by an ablation that isolates the non-myopic component (e.g., a myopic variant of the same pathwise estimator) or quantifies sensitivity to the temperature schedule. Without these controls it is difficult to attribute performance improvements specifically to the non-myopic pathwise formulation rather than implementation details or regularization.
Authors: We concur that isolating the non-myopic contribution and assessing hyperparameter sensitivity is necessary for clear attribution. In the revision we will add an ablation study that applies the identical pathwise estimator to a myopic (one-step) policy and compares it directly to the full non-myopic NM-PPG on all reported datasets. We will also include sensitivity plots for the staged temperature schedule and entropy regularization coefficient, showing how performance and acquisition behavior vary with these choices. revision: yes
Circularity Check
No circularity in the NM-PPG derivation chain
full rationale
The paper formulates active feature acquisition as a POMDP and introduces a continuous relaxation of the acquisition process together with a straight-through rollout to enable pathwise policy gradients. These are standard differentiable optimization techniques drawn from reinforcement learning literature rather than self-referential definitions or fitted parameters renamed as predictions. The non-myopic policy is optimized end-to-end with entropy regularization and temperature sharpening, and performance claims rest on external comparisons to baselines on synthetic and real datasets. No load-bearing step reduces by construction to the paper's own inputs or prior self-citations; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Active feature acquisition problems can be formulated as POMDPs which naturally admit a sequential decision-making perspective
Reference graph
Works this paper leans on
-
[1]
G. A. Gorry and G. O. Barnett. Experience with a model of sequential diagnosis.Computers and Biomedical Research, 1(5):490–507, 1968
1968
-
[2]
Arjan J. P. Jeckmans, Michael Beye, Zekeriya Erkin, Pieter Hartel, Reginald L. Lagendijk, and Qiang Tang.Privacy in Recommender Systems. Springer London, 2013
2013
-
[3]
Breese, and Koos Rommelse
David Heckerman, John S. Breese, and Koos Rommelse. Decision-theoretic troubleshooting. Commun. ACM, 38(3):49–57, 1995
1995
-
[4]
Efficient online learning for optimizing value of information: Theory and application to interactive troubleshooting
Yuxin Chen, Jean-Michel Renders, Morteza Haghir Chehreghani, and Andreas Krause. Efficient online learning for optimizing value of information: Theory and application to interactive troubleshooting. InProceedings of the Thirty-Third Conference on Uncertainty in Artificial Intelligence, 2017
2017
-
[5]
Information gain-based exploration using rao-blackwellized particle filters
Cyrill Stachniss, Giorgio Grisetti, and Wolfram Burgard. Information gain-based exploration using rao-blackwellized particle filters. InProceedings of Robotics: Science and Systems (RSS), 2005
2005
-
[6]
Optimal value of information in graphical models.J
Andreas Krause and Carlos Guestrin. Optimal value of information in graphical models.J. Artif. Int. Res., 35:557–591, 2009
2009
-
[7]
Partially observable markov decision processes in robotics: A survey.IEEE Transactions on Robotics, 39(1):21–40, 2023
Mikko Lauri, David Hsu, and Joni Pajarinen. Partially observable markov decision processes in robotics: A survey.IEEE Transactions on Robotics, 39(1):21–40, 2023
2023
-
[8]
The curious language model: Strategic test-time information acquisition
Michael Cooper, Rohan Wadhawan, John Michael Giorgi, Chenhao Tan, and Davis Liang. The curious language model: Strategic test-time information acquisition. InSecond Workshop on Test-Time Adaptation: Putting Updates to the Test! at ICML 2025, 2025
2025
-
[9]
Datum-wise classification: A sequential approach to sparsity
Gabriel Dulac-Arnold, Ludovic Denoyer, Philippe Preux, and Patrick Gallinari. Datum-wise classification: A sequential approach to sparsity. InMachine Learning and Knowledge Discovery in Databases, 2011
2011
-
[10]
A survey on active feature acquisition strategies
Linus Aronsson, Arman Rahbar, and Morteza Haghir Chehreghani. A survey on active feature acquisition strategies.arXiv preprint arXiv:2502.11067, 2026. 10
-
[11]
An introduction to variable and feature selection.J
Isabelle Guyon and André Elisseeff. An introduction to variable and feature selection.J. Mach. Learn. Res., 3:1157–1182, 2003. URLhttps://jmlr.org/papers/v3/guyon03a.html
2003
-
[12]
Michael Valancius, Maxwell Lennon, and Junier B. Oliva. Acquisition conditioned oracle for nongreedy active feature acquisition. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[13]
Optimal control of markov processes with incomplete state information.Journal of Mathematical Analysis and Applications, 10(1):174–205, 1965
K.J Åström. Optimal control of markov processes with incomplete state information.Journal of Mathematical Analysis and Applications, 10(1):174–205, 1965
1965
-
[14]
Online planning algorithms for pomdps.J
Stéphane Ross, Joelle Pineau, Sébastien Paquet, and Brahim Chaib-draa. Online planning algorithms for pomdps.J. Artif. Int. Res., 32:663–704, 2008
2008
-
[15]
Monte-carlo planning in large pomdps
David Silver and Joel Veness. Monte-carlo planning in large pomdps. InAdvances in Neural Information Processing Systems, 2010
2010
-
[16]
An active testing model for tracking roads in satellite images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(1):1–14, 1996
Donald Geman and Bruno Jedynak. An active testing model for tracking roads in satellite images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(1):1–14, 1996
1996
-
[17]
Test-cost sensitive naive bayes classification
Xiaoyong Chai, Lin Deng, Qiang Yang, and Charles X Ling. Test-cost sensitive naive bayes classification. InFourth IEEE International Conference on Data Mining (ICDM’04), 2004
2004
-
[18]
V oila: efficient feature-value acquisition for classification
Mustafa Bilgic and Lise Getoor. V oila: efficient feature-value acquisition for classification. In Proceedings of the 22nd National Conference on Artificial Intelligence, 2007
2007
-
[19]
Eddi: Efficient dynamic discovery of high-value information with partial V AE
Chao Ma, Sebastian Tschiatschek, Konstantina Palla, Jose Miguel Hernandez-Lobato, Sebastian Nowozin, and Cheng Zhang. Eddi: Efficient dynamic discovery of high-value information with partial V AE. InInternational Conference on Machine Learning. PMLR, 2019
2019
-
[20]
Imitation learning by coaching
He He, Jason Eisner, and Hal Daume. Imitation learning by coaching. InAdvances in Neural Information Processing Systems, 2012
2012
-
[21]
Classification with costly features as a sequential decision-making problem.Mach
Jaromír Janisch, Tomás Pevný, and Viliam Lisý. Classification with costly features as a sequential decision-making problem.Mach. Learn., 109(8):1587–1615, 2020
2020
-
[22]
Learning to maximize mutual information for dynamic feature selection
Ian Covert, Wei Qiu, Mingyu Lu, Nayoon Kim, Nathan White, and Su-In Lee. Learning to maximize mutual information for dynamic feature selection. InProceedings of the 40th International Conference on Machine Learning, 2023
2023
-
[23]
Difa: Differentiable feature acquisition.Proceedings of the AAAI Conference on Artificial Intelligence, 2023
Aritra Ghosh and Andrew Lan. Difa: Differentiable feature acquisition.Proceedings of the AAAI Conference on Artificial Intelligence, 2023
2023
-
[24]
Estimating conditional mutual infor- mation for dynamic feature selection
Soham Gadgil, Ian Connick Covert, and Su-In Lee. Estimating conditional mutual infor- mation for dynamic feature selection. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=Oju2Qu9jvn
2024
-
[25]
Odin: Optimal discovery of high-value information using model-based deep reinforcement learning
Sara Zannone, Jose Miguel Hernandez Lobato, Cheng Zhang, and Konstantina Palla. Odin: Optimal discovery of high-value information using model-based deep reinforcement learning. InReal-world Sequential Decision Making Workshop, ICML, 2019
2019
-
[26]
Active feature acquisition with generative surrogate models
Yang Li and Junier Oliva. Active feature acquisition with generative surrogate models. In Proceedings of the 38th International Conference on Machine Learning, 2021
2021
-
[27]
Distribution guided active feature acquisition.arXiv preprint arXiv:2410.03915, 2024
Yang Li and Junier Oliva. Distribution guided active feature acquisition.arXiv preprint arXiv:2410.03915, 2024
-
[28]
Active feature acquisition via explainability-driven ranking
Osman Berke Guney, Ketan Suhaas Saichandran, Karim Elzokm, Ziming Zhang, and Vijaya B Kolachalama. Active feature acquisition via explainability-driven ranking. InForty-second International Conference on Machine Learning, 2025
2025
-
[29]
Joint active feature acquisition and classification with variable-size set encoding
Hajin Shim, Sung Ju Hwang, and Eunho Yang. Joint active feature acquisition and classification with variable-size set encoding. InAdvances in Neural Information Processing Systems, 2018. 11
2018
-
[30]
Op- portunistic learning: Budgeted cost-sensitive learning from data streams
Mohammad Kachuee, Orpaz Goldstein, Kimmo Kärkkäinen, and Majid Sarrafzadeh. Op- portunistic learning: Budgeted cost-sensitive learning from data streams. InInternational Conference on Learning Representations, 2019
2019
-
[31]
Valter Schütz, Han Wu, Reza Rezvan, Linus Aronsson, and Morteza Haghir Chehreghani. Afabench: A generic framework for benchmarking active feature acquisition.arXiv preprint arXiv:2508.14734, 2026
-
[32]
Stochastic encodings for active feature acquisition
Alexander Luke Ian Norcliffe, Changhee Lee, Fergus Imrie, Mihaela van der Schaar, and Pietro Lio. Stochastic encodings for active feature acquisition. InForty-second International Conference on Machine Learning, 2025
2025
-
[33]
Variational information pursuit for interpretable predictions
Aditya Chattopadhyay, Kwan Ho Ryan Chan, Benjamin David Haeffele, Donald Geman, and Rene Vidal. Variational information pursuit for interpretable predictions. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=77lSWa-Tm3Z
2023
-
[34]
Rückstieß, C
T. Rückstieß, C. Osendorfer, and P. van der Smagt. Minimizing data consumption with sequential online feature selection.International Journal of Machine Learning and Cybernetics, 4:235–243, 2013
2013
-
[35]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. Adaptive Computation and Machine Learning series. The MIT Press, 2 edition, 2018
2018
-
[36]
Monte carlo gradient estimation in machine learning.Journal of Machine Learning Research, 2020
Shakir Mohamed, Mihaela Rosca, Michael Figurnov, and Andriy Mnih. Monte carlo gradient estimation in machine learning.Journal of Machine Learning Research, 2020
2020
-
[37]
Relative entropy pathwise policy optimization
Claas A V oelcker, Axel Brunnbauer, Marcel Hussing, Michal Nauman, Pieter Abbeel, Radu Grosu, Eric Eaton, Amir massoud Farahmand, and Igor Gilitschenski. Relative entropy pathwise policy optimization. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. InInternational Conference on Learning Representations, 2017
2017
-
[39]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous re- laxation of discrete random variables. InInternational Conference on Learning Representations, 2017
2017
-
[40]
Deterministic policy gradient algorithms
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, and Martin Riedmiller. Deterministic policy gradient algorithms. InProceedings of the 31st International Conference on Machine Learning, 2014
2014
-
[41]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InProceedings of the 35th International Conference on Machine Learning, 2018
2018
-
[42]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review arXiv 2013
-
[43]
Ziebart, Andrew Maas, J
Brian D. Ziebart, Andrew Maas, J. Andrew Bagnell, and Anind Dey. Maximum entropy inverse reinforcement learning. InProceedings of the 23rd AAAI Conference on Artificial Intelligence, pages 1433–1438, 2008
2008
-
[44]
John Tromp. Connect-4. UCI Machine Learning Repository, 1995. DOI: https://doi.org/10.24432/C59P43
-
[45]
UCI Machine Learning Repository, 1991
Molecular Biology (Splice-junction Gene Sequences). UCI Machine Learning Repository, 1991. DOI: https://doi.org/10.24432/C5M888
-
[46]
Enginefaultdb: A novel dataset for automotive engine fault classification and baseline results
Mary Vergara, Leo Ramos, Néstor Diego Rivera-Campoverde, and Francklin Rivas-Echeverría. Enginefaultdb: A novel dataset for automotive engine fault classification and baseline results. IEEE Access, 11:126155–126171, 2023. doi: 10.1109/ACCESS.2023.3331316. 12
-
[47]
Shah, Suet-Feung Chin, et al
Christina Curtis, Sohrab P. Shah, Suet-Feung Chin, et al. The genomic and transcriptomic architecture of 2,000 breast tumours reveals novel subgroups.Nature, 486(7403):346–352,
-
[48]
doi: 10.1038/nature10983
-
[49]
Bernard Pereira, Suet-Feung Chin, Oscar M. Rueda, et al. The somatic mutation profiles of 2,433 breast cancers refine their genomic and transcriptomic landscapes.Nature Communications, 7: 11479, 2016. doi: 10.1038/ncomms11479
-
[50]
National health and nutrition examination survey (nhanes).https://www.cdc.gov/nchs/nhanes/, 2026
Centers for Disease Control and Prevention. National health and nutrition examination survey (nhanes).https://www.cdc.gov/nchs/nhanes/, 2026. Accessed: 2026-04-08
2026
-
[51]
Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[52]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Han Xiao, Kashif Rasul, and Roland V ollgraf. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.arXiv preprint arXiv:1708.07747, 2017
work page internal anchor Pith review arXiv 2017
-
[53]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[54]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
2015
-
[55]
Janizek, Carly Hudelson, Richard B
Gabriel Erion, Joseph D. Janizek, Carly Hudelson, Richard B. Utarnachitt, Andrew M. McCoy, Michael R. Sayre, Nathan J. White, and Su-In Lee. A cost-aware framework for the development of ai models for healthcare applications.Nature Biomedical Engineering, 6:1384–1398, 2022. doi: 10.1038/s41551-022-00872-8
-
[56]
Paul Viola and Michael J. Jones. Robust real-time face detection.International Journal of Computer Vision, 57(2):137–154, 2004
2004
-
[57]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations (ICLR), 2015
2015
-
[58]
Neumiss networks: differentiable programming for supervised learning with missing values
Marine Le Morvan, Julie Josse, Thomas Moreau, Erwan Scornet, and Gael Varoquaux. Neumiss networks: differentiable programming for supervised learning with missing values. InAdvances in Neural Information Processing Systems, volume 33, 2020. A Proofs A.1 Proof of Theorem 1 By construction of the AFA-POMDP in Section 3.1, the one-step cost is C((m t, x, y),...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.