Recognition: unknown
A Few Good Clauses: Comparing LLMs vs Domain-Trained Small Language Models on Structured Contract Extraction
Pith reviewed 2026-05-08 11:18 UTC · model grok-4.3
The pith
A domain-trained small language model outperforms frontier LLMs on structured contract extraction at 78 to 97 percent lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
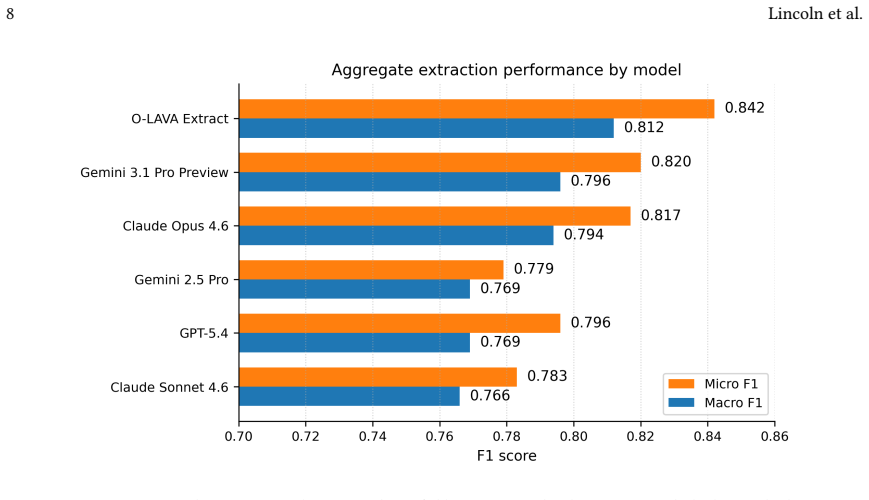
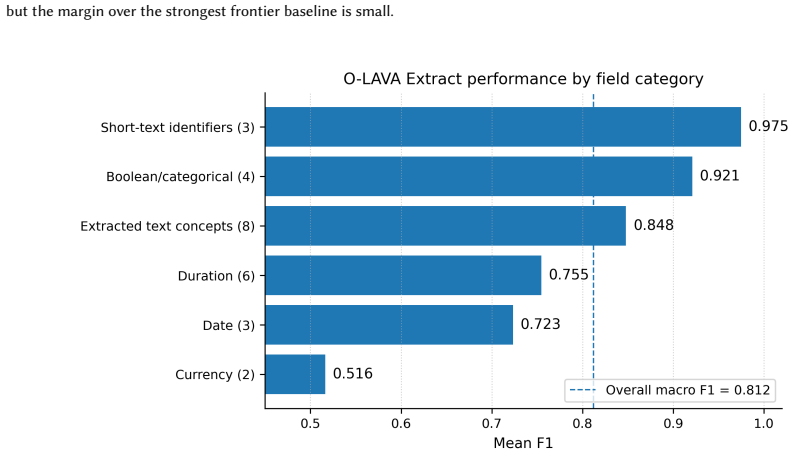
Olava Extract, a self-hosted legal domain Mixture of Experts model, achieved the strongest aggregate performance with a macro F1 of 0.812 and micro F1 of 0.842, exceeded the precision of five frontier models, generated fewer hallucinated or unsupported extractions, and lowered inference cost by 78 to 97 percent.
What carries the argument
Olava Extract, the domain-trained small language model, which carries the argument by delivering higher aggregate F1 scores, top precision, and major cost savings in a head-to-head comparison against frontier models on structured contract extraction.
If this is right
- High-performing legal extraction becomes feasible without relying on the largest models or external hosting.
- Lower inference costs allow wider deployment of automated contract review inside organizations.
- Reduced hallucination rates lower operational risk and review burden in legal workflows.
- Enterprise capability in this domain can be decoupled from ever-larger model sizes and central infrastructure.
Where Pith is reading between the lines
- Domain-specific training may let smaller models close the gap with general models on narrow, high-stakes tasks.
- Similar cost and accuracy gains could appear in other regulated fields that need precise document structuring.
- Organizations might build internal models tuned to their own contract templates rather than depending on public providers.
Load-bearing premise
The evaluation dataset and extraction task accurately represent real-world legal contract workflows, and the comparisons with frontier models used equivalent conditions without differences in prompting or post-processing.
What would settle it
A follow-up test on a larger and more varied collection of real contracts that shows one or more frontier models achieving higher accuracy, better precision, or fewer unsupported extractions than Olava Extract would disprove the performance advantage.
Figures
read the original abstract
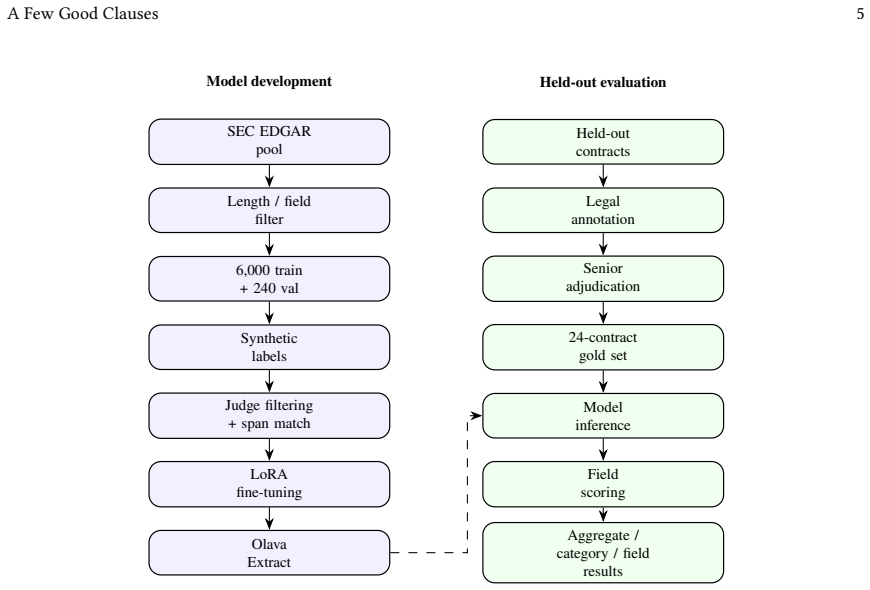
This paper evaluates whether a domain trained Small Language Model (SLM) can outperform frontier Large Language Models on structured contract extraction at radically lower cost. We test Olava Extract, a self hosted legal domain Mixture of Experts model, against five frontier models. Olava Extract achieved the strongest aggregate performance in the study, with a macro F1 of 0.812 and a micro F1 of 0.842, while reducing inference cost by 78% to 97% compared with the frontier models tested. It also achieved the highest precision scores, producing fewer hallucinated and unsupported extractions, an important distinction in legal workflows where hallucinations create operational risk and downstream review burden. The findings shows that high performing, human comparable legal AI no longer requires the largest externally hosted models. More broadly, they challenge the assumption that commercially valuable enterprise AI capability must remain tied to ever larger models, massive infrastructure expenditure, and centrally hosted providers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates whether a domain-trained small language model (Olava Extract, a self-hosted legal-domain Mixture of Experts model) can outperform five frontier large language models on structured contract extraction. It reports that Olava Extract achieves the strongest results with macro F1 of 0.812, micro F1 of 0.842, highest precision (fewer hallucinations), and 78-97% lower inference cost, concluding that high-performing legal AI no longer requires the largest externally hosted models.
Significance. If the results are robust and generalizable, the work is significant for demonstrating that domain-specific SLMs can deliver superior precision and cost efficiency on specialized enterprise tasks like contract extraction, with direct implications for reducing operational risk and infrastructure costs in legal AI workflows.
major comments (2)
- [Abstract] Abstract: The reported macro/micro F1 scores, precision advantages, and cost reductions are presented without any accompanying dataset size, composition, source, prompting details, post-processing steps, or statistical significance tests. This omission is load-bearing because the central claim of superiority over frontier models cannot be verified or replicated without these elements.
- [Evaluation methodology] Evaluation methodology (assumed §4 or equivalent): The comparison assumes equivalent task framing and conditions across models, but no explicit confirmation is given that prompting, output formatting, or post-processing were held constant; any undisclosed differences would undermine the cost and performance claims.
minor comments (1)
- [Abstract] Abstract: Grammatical error in 'The findings shows' (should be 'show').
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation methodology. These points highlight opportunities to improve the clarity and replicability of our central claims. We address each comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported macro/micro F1 scores, precision advantages, and cost reductions are presented without any accompanying dataset size, composition, source, prompting details, post-processing steps, or statistical significance tests. This omission is load-bearing because the central claim of superiority over frontier models cannot be verified or replicated without these elements.
Authors: We agree that the abstract would benefit from including key high-level details to support immediate verification of the claims. The full manuscript provides the dataset size and composition (Section 3), source (a curated legal contract corpus), prompting templates and post-processing steps (Section 4), and reports statistical significance tests on the F1 differences (results section). We will revise the abstract to concisely reference the dataset scale, note the consistent evaluation protocol, and indicate that performance differences are supported by statistical testing. revision: yes
-
Referee: [Evaluation methodology] Evaluation methodology (assumed §4 or equivalent): The comparison assumes equivalent task framing and conditions across models, but no explicit confirmation is given that prompting, output formatting, or post-processing were held constant; any undisclosed differences would undermine the cost and performance claims.
Authors: All models were evaluated under identical task framing, with the same prompting strategy, output formatting constraints, and post-processing pipeline applied uniformly to Olava Extract and the five frontier models. This setup is described in the evaluation methodology section. To address the lack of explicit confirmation, we will add a direct statement in the revised manuscript clarifying that these elements were held constant across all models to ensure a fair comparison. revision: yes
Circularity Check
No significant circularity
full rationale
This is a pure empirical benchmarking study that directly measures and compares model performance (F1 scores, precision, inference cost) on a contract extraction task. No equations, derivations, fitted parameters, predictions, or ansatzes appear in the reported results or abstract. The central claims rest on observed experimental outcomes rather than any self-referential reduction or load-bearing self-citation chain. The argument structure is self-contained against external benchmarks and contains no detectable circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The evaluation dataset and task definition are representative of real-world legal contract extraction needs.
Reference graph
Works this paper leans on
-
[1]
Marah Abdin et al. 2024. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219 [cs.CL] doi:10.48550/ arXiv.2404.14219
work page internal anchor Pith review arXiv 2024
-
[2]
Ilias Chalkidis, Manos Fergadiotis, Prodromos Malakasiotis, Nikolaos Aletras, and Ion Androutsopoulos. 2020. LEGAL-BERT: The Muppets Straight out of Law School. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, Online, 2898–2904. doi:10.18653/v1/2020.findings-emnlp.261
-
[3]
Pierre Colombo, Telmo Pessoa Pires, Malik Boudiaf, Dominic Culver, Rui Melo, Caio Corro, Andre F. T. Martins, Fabrizio Esposito, Vera Lúcia Raposo, Sofia Morgado, and Michael Desa. 2024. SaulLM-7B: A pioneering Large Language Model for Law. arXiv:2403.03883 [cs.CL] doi:10.48550/ arXiv.2404.14219
-
[4]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. Journal of Machine Learning Research23, 120 (2022), 1–39. http://jmlr.org/papers/v23/21-0998.html
2022
-
[5]
Dan Hendrycks, Collin Burns, Anya Chen, and Spencer Ball. 2021. CUAD: An Expert-Annotated NLP Dataset for Legal Contract Review. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks. arXiv:2103.06268 [cs.CL] https://datasets-benchmarks- proceedings.neurips.cc/paper/2021/hash/6ea9ab1baa0efb9e19094440c317e21b-Abstract...
-
[6]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations. arXiv:2106.09685 [cs.CL] https://openreview.net/ forum?id=nZeVKeeFYf9
work page internal anchor Pith review arXiv 2022
-
[7]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
-
[8]
Yuta Koreeda and Christopher D. Manning. 2021. ContractNLI: A Dataset for Document-level Natural Language Inference for Contracts. InFindings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics, Punta Cana, Dominican Republic, 1907–1919. doi:10.18653/v1/2021.findings-emnlp.164
-
[9]
Lauren Martin, Nick Whitehouse, Stephanie Yiu, Lizzie Catterson, and Rivindu Perera. 2024. Better Call GPT, Comparing Large Language Models Against Lawyers. arXiv:2401.16212 [cs.CY] doi:10.48550/arXiv.2401.16212
-
[10]
Nick Whitehouse, Nicole Lincoln, Stephanie Yiu, Lizzie Catterson, and Rivindu Perera. 2025. Better Bill GPT: Comparing Large Language Models against Legal Invoice Reviewers. arXiv:2504.02881 [cs.CL] doi:10.48550/arXiv.2504.02881 A Appendix A.1 Per-Field F1 Across All Models Table 7 reports per-field F1 for Olava Extract and the five frontier baselines acr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.