Recognition: unknown
SPARK: Self-Play with Asymmetric Reward from Knowledge Graphs
Pith reviewed 2026-05-08 12:08 UTC · model grok-4.3
The pith
Knowledge graphs from scientific papers enable self-play reinforcement learning that improves multi-hop relational reasoning in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPARK automatically builds a unified knowledge graph from multi-document, multi-modal scientific literature and uses paths over its nodes both to generate relational reasoning questions and to compute reliable rewards. A single small vision-language model then plays proposer and solver roles against this fixed graph under information asymmetry, producing stronger performance on multi-hop question answering than self-play grounded only in unstructured text.
What carries the argument
The unified knowledge graph that supplies both question-generation paths and verifiable reward signals for asymmetric self-play between proposer and solver roles.
If this is right
- SPARK produces higher accuracy than flat-corpus self-play on both public benchmarks and a newly constructed cross-document multi-hop QA dataset.
- The accuracy advantage of the knowledge-graph version increases as the hop count of the required reasoning grows.
- Structured grounding from the graph supports relational multi-hop reasoning that unstructured corpus grounding alone does not achieve.
- The same small vision-language model can serve in both proposer and solver roles without additional training data or external supervision.
Where Pith is reading between the lines
- The asymmetric self-play design could support continuous online adaptation if the knowledge graph is allowed to update as new literature arrives.
- The same KG-grounded reward mechanism might transfer to other domains whose documents contain implicit cross-references, such as legal or medical collections.
- Removing the need for human-curated rewards could make scalable self-improvement feasible for models that must reason over large, multi-modal scientific corpora.
Load-bearing premise
The automatically built knowledge graph correctly records the true relational facts present in the source scientific literature without major errors, omissions, or fabricated connections.
What would settle it
A direct comparison in which the same self-play loop is run once with the knowledge graph and once with only flat text, checking whether the performance gap disappears or fails to widen on questions that require three or more hops.
Figures

read the original abstract
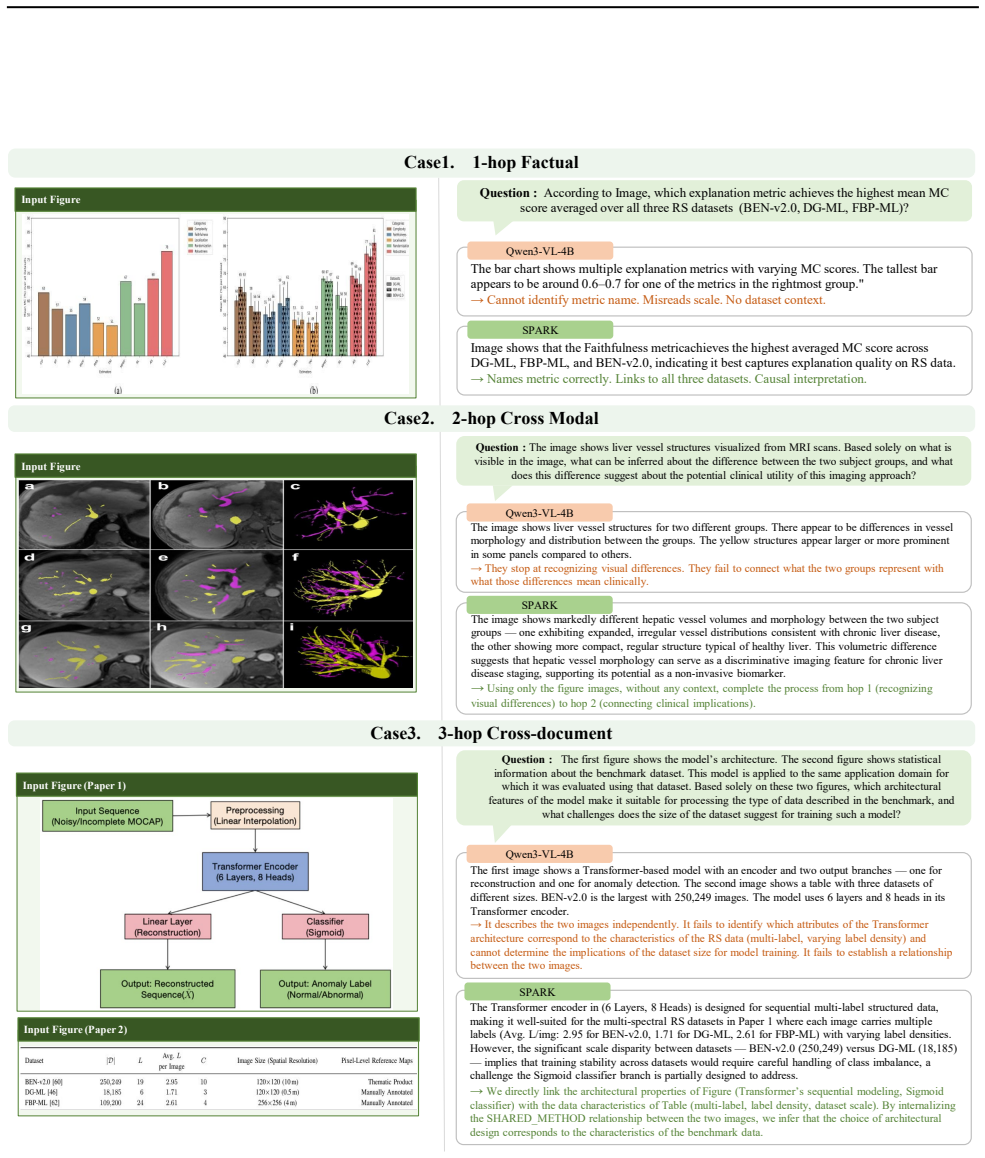
Self-play reinforcement learning has shown strong performance in domains with formally verifiable structure, such as mathematics and coding, where both problem generation and reward computation can be grounded in explicit rules. Extending this paradigm to scientific literature is more challenging: the relationships among multi-modal elements within and across documents are rarely made explicit in text, which makes automatic generation of relational reasoning questions difficult and weakens the reliability of reward signals. We propose SPARK (Self-Play with Asymmetric Reward from Knowledge Graphs), a framework that automatically constructs a unified knowledge graph (KG) from multi-document scientific literature and uses it as the structural basis for self-play. KG paths over multimodal nodes serve as a source for generating relational reasoning questions, and structured facts stored in the KG provide a basis for verifiable reward computation. A single small vision-language model (sVLM) alternates between Proposer and Solver roles under information asymmetry against a fixed KG, a design that we believe can be naturally extended toward online adaptation in future work. We evaluate SPARK on public benchmarks and a self-constructed cross-document multi-hop QA dataset. Results show that SPARK consistently outperforms flat-corpus-based self-play baselines, and the performance gap widens as hop count increases, suggesting that KG-structure grounding contributes to relational multi-hop reasoning beyond what unstructured corpus grounding can provide.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPARK, a self-play RL framework that automatically builds a unified knowledge graph from multi-modal scientific literature. KG paths over multimodal nodes generate relational reasoning questions while stored facts enable verifiable reward computation. A single small vision-language model alternates between Proposer and Solver roles under information asymmetry. Evaluation on public benchmarks and a self-constructed cross-document multi-hop QA dataset shows consistent outperformance over flat-corpus self-play baselines, with the gap widening as hop count increases.
Significance. If the results hold after addressing dataset alignment, SPARK offers a concrete route to extend verifiable self-play beyond formally structured domains like mathematics into scientific literature by using KGs for both question generation and reward. The hop-stratified gains provide a falsifiable signature that structural grounding can improve relational multi-hop reasoning beyond unstructured corpus baselines.
major comments (2)
- [Abstract] Abstract: the claim that 'the performance gap widens as hop count increases, suggesting that KG-structure grounding contributes to relational multi-hop reasoning' rests on the self-constructed cross-document multi-hop QA dataset. Because questions are generated from KG paths, the test distribution is aligned with the relational structure SPARK exploits for both generation and reward; flat-corpus baselines therefore face an information disadvantage by construction. The hop-stratified analysis supporting the causal interpretation is performed on this custom set, so an independent multi-hop test set or ablation that removes KG-derived questions is required to rule out dataset bias.
- [Evaluation] Evaluation section: the abstract reports consistent outperformance but provides no details on KG construction accuracy, error rates, statistical significance tests, or the precise metrics and hop-count stratification procedure. Without these, the reliability of the verifiable reward signal and the widening-gap result cannot be assessed.
minor comments (1)
- [Abstract] Abstract: specify the exact public benchmarks used and the size, construction pipeline, and hop distribution of the self-constructed dataset.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concerns about potential dataset bias in the hop-stratified analysis and the need for additional evaluation details. We propose targeted revisions to clarify these points while maintaining the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'the performance gap widens as hop count increases, suggesting that KG-structure grounding contributes to relational multi-hop reasoning' rests on the self-constructed cross-document multi-hop QA dataset. Because questions are generated from KG paths, the test distribution is aligned with the relational structure SPARK exploits for both generation and reward; flat-corpus baselines therefore face an information disadvantage by construction. The hop-stratified analysis supporting the causal interpretation is performed on this custom set, so an independent multi-hop test set or ablation that removes KG-derived questions is required to rule out dataset bias.
Authors: We acknowledge the referee's concern regarding alignment between the custom dataset and SPARK's KG-based mechanisms. The self-constructed cross-document multi-hop QA dataset is generated from KG paths precisely to evaluate relational reasoning grounded in structured knowledge, which is central to the framework. SPARK is also evaluated on independent public benchmarks, where it demonstrates consistent outperformance over flat-corpus baselines. However, the hop-stratified widening gap is reported on the custom set. We will revise the abstract to qualify the claim as applying to the KG-derived dataset and add a dedicated limitations paragraph discussing this alignment and its implications for causal interpretation. We will further include an ablation comparing performance on KG-path-derived questions versus a held-out subset of questions constructed without direct KG path guidance, to help isolate the effect. revision: partial
-
Referee: [Evaluation] Evaluation section: the abstract reports consistent outperformance but provides no details on KG construction accuracy, error rates, statistical significance tests, or the precise metrics and hop-count stratification procedure. Without these, the reliability of the verifiable reward signal and the widening-gap result cannot be assessed.
Authors: We agree that these details are essential for evaluating the reliability of the results. In the revised manuscript, we will expand the Evaluation section to report: (i) accuracy metrics and error rates for the automated KG construction process from multi-document scientific literature, including any manual validation steps; (ii) statistical significance tests (e.g., paired t-tests with p-values) for performance differences between SPARK and baselines; (iii) precise definitions of all metrics used; and (iv) a step-by-step description of the hop-count stratification procedure, including how hops are counted along KG paths over multimodal nodes. These additions will strengthen the assessment of the verifiable reward signal. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical self-play framework without any equations, derivations, or mathematical claims. Central results consist of performance comparisons against baselines on public benchmarks plus a self-constructed dataset; these are observational outcomes rather than quantities that reduce by construction to fitted parameters, self-definitions, or prior self-citations. The hop-count gap is presented as an empirical observation, not a definitional or fitted tautology. No load-bearing step matches any enumerated circularity pattern, so the reported chain remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge graphs can be automatically constructed from multi-modal scientific literature to accurately represent relational facts across documents.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review arXiv
-
[2]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y ., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKin- non, C., et al. Constitutional ai: Harmlessness from ai feedback, 2022.arXiv preprint arXiv:2212.08073, 2212,
work page internal anchor Pith review arXiv 2022
-
[3]
SciBERT: A pretrained language model for scientific text
Beltagy, I., Lo, K., and Cohan, A. SciBERT: A pretrained language model for scientific text. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Con- ference on Natural Language Processing, pp. 3615–3620. Association for Computational Linguistics,
2019
-
[4]
S ci BERT : A pretrained language model for scientific text
doi: 10.18653/v1/D19-1371. Blecher, L., Cucurull, G., Scialom, T., and Stojnic, R. Nougat: Neural optical understanding for academic docu- ments.arXiv preprint arXiv:2308.13418,
-
[5]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Chen, Z., Deng, Y ., Yuan, H., Ji, K., and Gu, Q. Self-play fine-tuning converts weak language models to strong lan- guage models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofPro- ceedings of Machine Learning Research, pp. 6621–6642. PMLR, 2024a. Chen, Z., Wang, W., Tian, H., Ye, S., Gao, Z., Cui, E., Tong, W., Hu,...
work page internal anchor Pith review arXiv
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review arXiv
-
[7]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Huang, C., Yu, W., Wang, X., Zhang, H., Li, Z., Li, R., Huang, J., Mi, H., and Yu, D. R-zero: Self- evolving reasoning llm from zero data.arXiv preprint arXiv:2508.05004,
work page internal anchor Pith review arXiv
-
[8]
doi: 10.1145/3503161.3548112. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
-
[9]
Spice: Self-play in corpus environments improves reasoning.arXiv, 2025
Liu, B., Jin, C., Kim, S., Yuan, W., Zhao, W., Kulikov, I., Li, X., Sukhbaatar, S., Lanchantin, J., and Weston, J. Spice: Self-play in corpus environments improves reasoning. arXiv preprint arXiv:2510.24684,
-
[10]
X., Tan, J
Masry, A., Long, D. X., Tan, J. Q., Joty, S., and Hoque, E. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pp. 2263–2279. Association for Computational Linguistics,
2022
-
[11]
URL https://arxiv.org/abs/ 2511.16301. Sun, J., Xu, C., Tang, L., Wang, S., Lin, C., Gong, Y ., Shum, H.-Y ., and Guo, J. Think-on-graph: Deep and responsible reasoning of large language model on knowledge graph. InThe Twelfth International Conference on Learning Representations,
-
[12]
Tang, Y ., Huang, C., Huang, J., and Yeoh, W. UniRel-R1: RL-tuned LLM reasoning for knowledge graph relational question answering.arXiv preprint arXiv:2512.17043,
-
[13]
Galactica: A Large Language Model for Science
Taylor, R., Kardas, M., Cucurull, G., Scialom, T., Hartshorn, A., Saravia, E., Poulton, A., Kerkez, V ., and Stojnic, R. Galactica: A large language model for science.arXiv preprint arXiv:2211.09085,
work page internal anchor Pith review arXiv
-
[14]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Zhao, A., Wu, Y ., Yue, Y ., Wu, T., Xu, Q., Lin, M., Wang, S., Wu, Q., Zheng, Z., and Huang, G. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335,
work page internal anchor Pith review arXiv
-
[15]
Detailed Training Configuration Base Model and Training Framework.We use Qwen3-VL-4B-Instruct as the base model
11 A. Detailed Training Configuration Base Model and Training Framework.We use Qwen3-VL-4B-Instruct as the base model. Fine-tuning is performed with LoRA (Hu et al., 2022), configured with rank r= 16 , scaling factor α= 32 , and dropout p= 0.05 . LoRA adapters are applied to the query projection (qproj) and value projection (vproj) layers of the attention...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.