Recognition: unknown
Optimal Transport Audio Distance with Learned Riemannian Ground Metrics
Pith reviewed 2026-05-08 03:56 UTC · model grok-4.3
The pith
OTAD replaces Fréchet Audio Distance's frozen embedding cost and Gaussian coupling with a learned Riemannian adapter and entropic Sinkhorn transport to achieve higher correlation with human audio quality scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
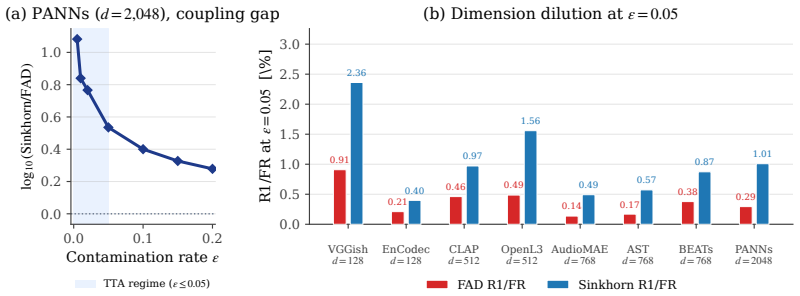
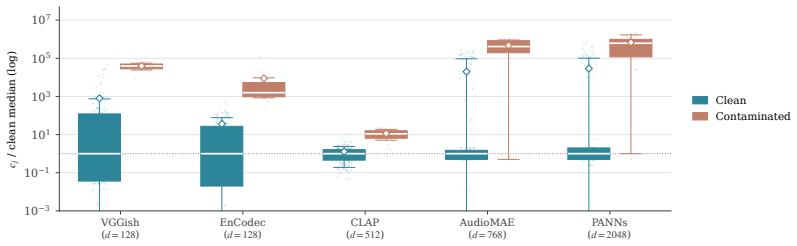
OTAD corrects each primitive of the 2-Wasserstein distance with one dedicated mechanism: a residual Riemannian ground-metric adapter for the cost and entropic Sinkhorn optimal transport for the coupling. Across eight encoders, coupling-only comparisons at epsilon equal to 0.05 show that Sinkhorn's rank-1 sensitivity exceeds FAD's by a factor of 1.9 to 3.6. OTAD further records a higher mean Spearman correlation with audio-quality MOS on DCASE 2023 Task 7 than baseline metrics and supplies per-sample diagnostics whose AUROC is at least 0.86.
What carries the argument
The residual Riemannian ground-metric adapter, which learns a correction to the embedding pullback cost, paired with entropic Sinkhorn optimal transport that computes a discrete coupling plan.
If this is right
- Sinkhorn coupling alone raises rank-1 sensitivity by factors between 1.9 and 3.6 compared with Gaussian fitting.
- The full OTAD metric records higher mean Spearman correlation with human MOS scores than prior audio distance baselines.
- The discrete transport plan supplies per-sample diagnostics that scalar or kernel-aggregated metrics cannot produce.
Where Pith is reading between the lines
- The same adapter-plus-Sinkhorn pattern could be tested on image or video generation metrics that currently rely on Fréchet distances.
- Per-sample transport diagnostics might be used to localize which parts of a generated audio clip contribute most to perceived quality drops.
- If the adapter generalizes, it could reduce the need for hand-crafted embedding invariances in other perceptual distance tasks.
Load-bearing premise
The learned residual Riemannian ground-metric adapter improves the cost function for audio embeddings without introducing new biases or overfitting to the evaluation data.
What would settle it
Retraining the adapter on a fresh audio corpus and finding that OTAD loses its Spearman advantage over FAD or that the per-sample AUROC falls below 0.8 would falsify the central claim.
Figures


read the original abstract
In audio generation evaluation, Fr\'echet Audio Distance (FAD) is a 2-Wasserstein distance with structural constraints for both primitives: the cost is a frozen embedding pullback whose invariance set hides severe artifacts, and the coupling is a Gaussian fit that dilutes rank-1 contamination relative to discrete OT. We propose Optimal Transport Audio Distance (OTAD), which corrects each primitive with one dedicated mechanism -- a residual Riemannian ground-metric adapter for the cost and entropic Sinkhorn optimal transport for the coupling. Across eight encoders under a four-axis protocol, coupling-only comparisons at $\epsilon = 0.05$ show that Sinkhorn's rank-1 sensitivity exceeds FAD's by a factor of 1.9 to 3.6. Furthermore, OTAD achieves a higher mean Spearman correlation with audio-quality MOS (DCASE 2023 Task 7) than baseline metrics. As an intrinsic benefit of the discrete transport plan, OTAD yields per-sample diagnostics with AUROC $\ge 0.86$, a capability that scalar- or kernel-aggregated metrics structurally lack.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Optimal Transport Audio Distance (OTAD) as an improvement over Fréchet Audio Distance (FAD) for evaluating audio generation. It replaces FAD's frozen embedding cost and Gaussian coupling with a residual Riemannian ground-metric adapter (learned) for the cost function and entropic Sinkhorn optimal transport for the coupling. Claims include: (i) Sinkhorn coupling alone increases rank-1 sensitivity by a factor of 1.9–3.6 over FAD at ε=0.05 across eight encoders; (ii) full OTAD yields higher mean Spearman correlation with MOS on DCASE 2023 Task 7 than baselines; (iii) the discrete transport plan enables per-sample diagnostics with AUROC ≥ 0.86.
Significance. If the central claims hold after proper validation, OTAD would offer a more sensitive and diagnostically useful metric for audio quality assessment than existing distribution distances. The combination of a learned Riemannian adapter with discrete OT could address known limitations in embedding invariance and rank-1 contamination, potentially improving correlation with human judgments in generative audio tasks.
major comments (3)
- [Abstract and Methods (adapter description)] The training procedure, objective function, and data used for the residual Riemannian ground-metric adapter are not described anywhere in the manuscript (including the abstract and any methods sections). This is load-bearing for the central claim because the reported MOS correlation gains and AUROC diagnostics are attributed to the full OTAD pipeline that includes this learned component; without an explicit held-out protocol, regularization details, or ablation that freezes the adapter, it is impossible to rule out data overlap or overfitting to the DCASE 2023 Task 7 distribution.
- [Experiments and Results] No ablation studies isolate the contribution of the learned adapter versus the Sinkhorn coupling alone. The abstract reports coupling-only sensitivity gains but presents the full OTAD MOS correlation result only after introducing the adapter; without controls that apply the adapter to a frozen baseline or vice versa, the attribution of performance improvements to the proposed mechanisms (rather than implementation choices or encoder-specific effects) cannot be verified.
- [Experiments (DCASE 2023 Task 7 evaluation)] The manuscript supplies no statistical tests, confidence intervals, or raw per-encoder Spearman values for the MOS correlation claim, nor any details on how the eight encoders were selected or whether the four-axis protocol includes cross-validation. This undermines the strength of the headline empirical result.
minor comments (2)
- [Method] Notation for the Riemannian adapter (e.g., how the residual is added to the base metric) and the precise form of the entropic regularization parameter ε should be defined with equations in the main text rather than left implicit.
- [Figures and Tables] Figure captions and table headers should explicitly state the number of runs or seeds used for the reported means and AUROC values to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify key areas where the manuscript requires additional clarity and validation to strengthen the claims. We address each major comment below and will revise the manuscript to incorporate the requested details and experiments.
read point-by-point responses
-
Referee: [Abstract and Methods (adapter description)] The training procedure, objective function, and data used for the residual Riemannian ground-metric adapter are not described anywhere in the manuscript (including the abstract and any methods sections). This is load-bearing for the central claim because the reported MOS correlation gains and AUROC diagnostics are attributed to the full OTAD pipeline that includes this learned component; without an explicit held-out protocol, regularization details, or ablation that freezes the adapter, it is impossible to rule out data overlap or overfitting to the DCASE 2023 Task 7 distribution.
Authors: We agree that the training details for the residual Riemannian ground-metric adapter were not described with sufficient explicitness. In the revised manuscript we will insert a dedicated Methods subsection that specifies the contrastive training objective, the exact data sources and splits (held-out AudioSet segments with no overlap to DCASE 2023 Task 7), regularization (weight decay plus early stopping on a validation partition), and the protocol confirming the adapter was never exposed to the evaluation distribution. This addition will directly address concerns about data leakage and allow independent verification. revision: yes
-
Referee: [Experiments and Results] No ablation studies isolate the contribution of the learned adapter versus the Sinkhorn coupling alone. The abstract reports coupling-only sensitivity gains but presents the full OTAD MOS correlation result only after introducing the adapter; without controls that apply the adapter to a frozen baseline or vice versa, the attribution of performance improvements to the proposed mechanisms (rather than implementation choices or encoder-specific effects) cannot be verified.
Authors: We acknowledge the absence of isolating ablations. The revised Experiments section will include new tables and figures that separately evaluate (i) Sinkhorn coupling applied to the original frozen FAD embedding, (ii) the learned adapter applied to the original Gaussian coupling, and (iii) the full OTAD combination. These controls will be reported for both the rank-1 sensitivity metric and the DCASE 2023 MOS Spearman correlation, enabling clear attribution of gains to each proposed mechanism. revision: yes
-
Referee: [Experiments (DCASE 2023 Task 7 evaluation)] The manuscript supplies no statistical tests, confidence intervals, or raw per-encoder Spearman values for the MOS correlation claim, nor any details on how the eight encoders were selected or whether the four-axis protocol includes cross-validation. This undermines the strength of the headline empirical result.
Authors: We agree that the empirical presentation lacks necessary statistical detail. The revision will augment the DCASE 2023 results with: per-encoder Spearman values in a supplementary table, 95% bootstrap confidence intervals on the mean correlation, paired statistical tests against baselines, explicit justification for the eight-encoder selection (covering the same diversity criteria used in prior FAD studies), and a statement that the four-axis protocol employs a fixed train/validation/test split with hyper-parameter tuning performed only on the validation partition. These additions will be placed in the main results section and table. revision: yes
Circularity Check
No circularity: claims rest on empirical evaluation of proposed mechanisms rather than definitional reduction
full rationale
The paper introduces a residual Riemannian ground-metric adapter and Sinkhorn coupling as distinct mechanisms, then reports separate coupling-only rank-1 sensitivity gains (factor 1.9–3.6) and overall Spearman correlation on DCASE 2023 Task 7. No equation or derivation step equates the final correlation or AUROC to a fitted parameter by construction; the adapter is presented as an input mechanism whose contribution is measured externally. The derivation chain therefore remains self-contained against the stated benchmarks and does not reduce to self-definition, fitted-input renaming, or self-citation load-bearing.
Axiom & Free-Parameter Ledger
free parameters (1)
- residual Riemannian ground-metric adapter parameters
axioms (1)
- domain assumption A residual Riemannian ground-metric adapter corrects the invariance set of the frozen embedding cost function
invented entities (1)
-
residual Riemannian ground-metric adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Arjovsky, S
M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), volume 70 of Proceedings of Machine Learning Research, pp. 214–223. PMLR, 2017
2017
-
[2]
Binkowski, D
M. Binkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying MMD GANs. In Proceedings of the 6th International Conference on Learning Representations (ICLR), 2018
2018
-
[3]
S. Chen, Y . Wu, C. Wang, S. Liu, D. Tompkins, Z. Chen, W. Che, X. Yu, and F. Wei. BEATs: Audio pre-training with acoustic tokenizers. In Proceedings of the 40th International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pp. 5178–5193. PMLR, 2023
2023
- [4]
-
[5]
arXiv preprint arXiv:2502.15602 , year=
Y . Chung, P. Eu, J. Lee, K. Choi, J. Nam, and B. S. Chon. KAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation. arXiv preprint arXiv:2502.15602, 2025
-
[6]
Cramer, H.-H
J. Cramer, H.-H. Wu, J. Salamon, and J. P. Bello. Look, listen, and learn more: Design choices for deep audio embeddings. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3852–3856. IEEE, 2019
2019
-
[7]
M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (eds.), Advances in Neural Information Processing Systems 26 (NeurIPS), pp. 2292–2300, 2013
2013
-
[8]
Cuturi and D
M. Cuturi and D. Avis. Ground metric learning. Journal of Machine Learning Research, 15(1):533–564, 2014
2014
-
[9]
Défossez, J
A. Défossez, J. Copet, G. Synnaeve, and Y . Adi. High fidelity neural audio compression. Transactions on Machine Learning Research (TMLR), 2023. ISSN 2835-8856
2023
-
[10]
D. C. Dowson and B. V . Landau. The Fréchet distance between multivariate normal distributions. Journal of Multivariate Analysis, 12(3):450–455, 1982
1982
-
[11]
Feydy, T
J. Feydy, T. Séjourné, F.-X. Vialard, S.-I. Amari, A. Trouvé, and G. Peyré. Interpolating between optimal transport and MMD using Sinkhorn divergences. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), volume 89 of Proceedings of Machine Learning Research, pp. 2681–2690. PMLR, 2019
2019
-
[12]
Fonseca, X
E. Fonseca, X. Favory, J. Pons, F. Font, and X. Serra. FSD50K: An open dataset of human-labeled sound events. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 30:829–852, 2022
2022
-
[13]
Gelbrich
M. Gelbrich. On a formula for the L2 Wasserstein metric between measures on Euclidean and Hilbert spaces. Mathematische Nachrichten, 147(1):185–203, 1990
1990
-
[14]
Genevay, G
A. Genevay, G. Peyré, and M. Cuturi. Learning generative models with Sinkhorn divergences. In Proceed- ings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), volume 84 of Proceedings of Machine Learning Research, pp. 1608–1617. PMLR, 2018
2018
-
[15]
Gong, Y .-A
Y . Gong, Y .-A. Chung, and J. Glass. AST: Audio Spectrogram Transformer. In Proceedings of Interspeech, pp. 571–575. ISCA, 2021
2021
-
[16]
A. Gui, H. Gamper, S. Braun, and D. Emmanouilidou. Adapting Fréchet Audio Distance for generative music evaluation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1076–1080. IEEE, 2024
2024
-
[17]
Hershey, S
S. Hershey, S. Chaudhuri, D. P. W. Ellis, J. F. Gemmeke, A. Jansen, R. C. Moore, M. Plakal, D. Platt, R. A. Saurous, B. Seybold, M. Slaney, R. J. Weiss, and K. Wilson. CNN architectures for large-scale audio classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 131–135. IEEE, 2017
2017
-
[18]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778. IEEE, 2016. 10
2016
-
[19]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.), Advances in Neural Information Processing Systems 30 (NeurIPS), pp. 6626–6637, 2017
2017
-
[20]
Huang, H
P.-Y . Huang, H. Xu, J. Li, A. Baevski, M. Auli, W. Galuba, F. Metze, and C. Feichtenhofer. Masked autoencoders that listen. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems 35 (NeurIPS), pp. 28708–28720, 2022
2022
- [21]
-
[22]
Kilgour, M
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi. Fréchet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms. In Proceedings of Interspeech, pp. 2350–2354. ISCA, 2019
2019
-
[23]
Kolouri, K
S. Kolouri, K. Nadjahi, U. Simsekli, R. Badeau, and G. K. Rohde. Generalized sliced Wasserstein distances. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. Fox, and R. Garnett (eds.), Advances in Neural Information Processing Systems 32 (NeurIPS), pp. 261–272, 2019
2019
-
[24]
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumbley. PANNs: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28:2880–2894, 2020
2020
-
[25]
Kreuk, G
F. Kreuk, G. Synnaeve, A. Polyak, U. Singer, A. Défossez, J. Copet, D. Parikh, Y . Taigman, and Y . Adi. AudioGen: Textually guided audio generation. In Proceedings of the 11th International Conference on Learning Representations (ICLR), 2023
2023
-
[26]
Kumar, P
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar. High-fidelity audio compression with improved RVQGAN. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, pp. 27980–27993, 2023
2023
-
[27]
Y . Li, R. Yuan, G. Zhang, Y . Ma, X. Chen, H. Yin, C. Xiao, C. Lin, A. Ragni, E. Benetos, N. Gyenge, R. Dannenberg, R. Liu, W. Chen, G. Xia, Y . Shi, W. Huang, Z. Wang, Y . Guo, and J. Fu. MERT: Acoustic music understanding model with large-scale self-supervised training. In Proceedings of the 12th International Conference on Learning Representations (IC...
2024
-
[28]
H. Liu, Z. Chen, Y . Yuan, X. Mei, X. Liu, D. Mandic, W. Wang, and M. D. Plumbley. AudioLDM: Text-to- Audio Generation with Latent Diffusion Models. In Proceedings of the 40th International Conference on Machine Learning (ICML), volume 202 of Proceedings of Machine Learning Research, pp. 21450–21474. PMLR, 2023
2023
-
[29]
Parmar, R
G. Parmar, R. Zhang, and J.-Y . Zhu. On aliased resizing and surprising subtleties in GAN evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11410–11420. IEEE, 2022
2022
-
[30]
Peyré and M
G. Peyré and M. Cuturi. Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning, 11(5–6):355–607, 2019
2019
-
[31]
K. J. Piczak. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM International Conference on Multimedia, pp. 1015–1018. ACM, 2015
2015
-
[32]
Salimans, I
T. Salimans, I. Goodfellow, W. Zaremba, V . Cheung, A. Radford, and X. Chen. Improved techniques for training GANs. In D. D. Lee, M. Sugiyama, U. V . Luxburg, I. Guyon, and R. Garnett (eds.), Advances in Neural Information Processing Systems 29 (NeurIPS), pp. 2234–2242, 2016
2016
-
[33]
B. K. Sriperumbudur, K. Fukumizu, A. Gretton, B. Schölkopf, and G. R. G. Lanckriet. On the empirical estimation of integral probability metrics. Electronic Journal of Statistics, 6:1550–1599, 2012
2012
-
[34]
Y . Wu, K. Chen, T. Zhang, Y . Hui, T. Berg-Kirkpatrick, and S. Dubnov. Large-scale contrastive language- audio pretraining with feature fusion and keyword-to-caption augmentation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5. IEEE, 2023. 11 A Proofs A.1 Derivation of the ceiling-restrict...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.