Recognition: unknown
BitCal-TTS: Bit-Calibrated Test-Time Scaling for Quantized Reasoning Models
Pith reviewed 2026-05-08 11:57 UTC · model grok-4.3
The pith
BitCal-TTS rescales online confidence signals to reduce early stopping errors in 4-bit quantized reasoning models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BitCal-TTS combines inexpensive online proxies for token-level uncertainty and reasoning-trace stability with a bit-conditioned confidence rescaling rule that is conservative at low nominal precision and a bit-aware post-marker confirmation horizon. When inserted into greedy 4-bit inference for structured math outputs, the controller improves exact-match accuracy relative to a non-bit-aware adaptive baseline while preserving most of the token savings of adaptive decoding over a fixed large budget.
What carries the argument
BitCal-TTS, a runtime controller that performs bit-conditioned rescaling of token uncertainty and stability signals during adaptive decoding under 4-bit quantization.
If this is right
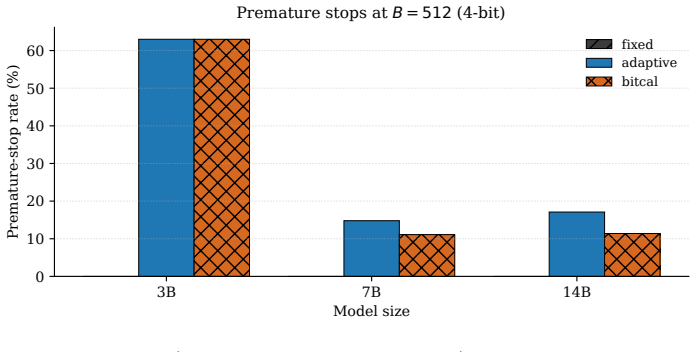
- Exact-match accuracy rises by 3.7 points at 7B scale and 2.8 points at 14B scale under a 512-token cap.
- Premature-stop rates fall from 14.8% to 11.1% at 7B and from 17.1% to 11.4% at 14B.
- Token usage stays substantially below fixed-budget decoding while accuracy improves.
- The method requires no base-model fine-tuning and works with standard 4-bit inference hooks.
- Wilson 95% intervals are reported to account for the limited shard sizes used.
Where Pith is reading between the lines
- The same proxies and rescaling logic could be tested on other structured reasoning benchmarks to check whether the bit-conditioning generalizes beyond the reported shards.
- If the approach holds on full test sets, it would support routine use of 4-bit models for adaptive compute without sacrificing reliability.
- Extending the confirmation horizon or uncertainty proxies to additional bit widths might yield similar robustness gains at even lower memory cost.
- The limited statistical power of the partial-shard results implies that larger-scale replication is needed before treating the accuracy deltas as settled.
Load-bearing premise
That inexpensive online proxies for token-level uncertainty and reasoning-trace stability, combined with a fixed bit-conditioned rescaling rule, remain reliable indicators of final-answer correctness across different model scales and problem distributions without any per-model calibration or fine-tuning.
What would settle it
Evaluating the controller on the full GSM8K test set with the same models and 4-bit setting and observing no accuracy gain or no drop in premature-stop rate would falsify the reported benefit.
Figures




read the original abstract
Post-training quantization makes large reasoning models practical under tight memory and latency budgets, but it can distort the online signals that drive adaptive test-time compute allocation. Under a fixed cap on the number of newly generated tokens, miscalibrated confidence can lead to harmful early halting: the model may surface a plausible final line while the underlying reasoning is still wrong, or the controller may stop before the trace has stabilized. We study this interaction for greedy 4-bit inference and propose BitCal-TTS, a lightweight runtime controller that combines (i) inexpensive online proxies for token-level uncertainty and reasoning-trace stability, (ii) a bit-conditioned confidence rescaling that is conservative at low nominal precision, and (iii) a bit-aware post-marker confirmation horizon designed for GSM8K-style structured outputs. The method requires no fine-tuning of the base model and integrates with standard Hugging Face 4-bit inference using forward hooks for logits and last-layer hidden states. On small evaluation shards of GSM8K with Qwen2.5 Instruct models, BitCal-TTS improves exact-match accuracy over a non-bit-aware adaptive baseline at the 7B and 14B scales while preserving substantial token savings relative to fixed-budget decoding. At a token cap of B=512, on the evaluation shards we report (N=54 for 7B and N=35 for 14B; not the full GSM8K test set), accuracy gains are +3.7 points (7B) and +2.8 points (14B), with the premature-stop rate falling from 14.8% to 11.1% on 7B and from 17.1% to 11.4% on 14B. We report Wilson 95% confidence intervals throughout and explicitly discuss the limited statistical power of the partial-shard comparisons. We release code and figure-generation scripts to support full reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BitCal-TTS, a lightweight runtime controller for adaptive test-time scaling under 4-bit greedy inference of reasoning models. It integrates inexpensive online proxies for token-level uncertainty and reasoning-trace stability, a bit-conditioned confidence rescaling rule that is conservative at low nominal precision, and a bit-aware post-marker confirmation horizon tailored to GSM8K-style outputs. No fine-tuning or per-model calibration is required; the controller uses forward hooks on logits and last-layer hidden states within standard Hugging Face 4-bit pipelines. On small GSM8K evaluation shards (N=54 for the 7B model and N=35 for the 14B model, explicitly not the full test set), BitCal-TTS reports exact-match accuracy gains of +3.7 and +2.8 points over a non-bit-aware adaptive baseline at token cap B=512, together with reductions in premature-stop rate (14.8% to 11.1% at 7B; 17.1% to 11.4% at 14B) while retaining substantial token savings relative to fixed-budget decoding. Wilson 95% confidence intervals are reported for accuracy, code and reproduction scripts are released, and the limited statistical power of the partial-shard comparisons is explicitly noted.
Significance. If the token-uncertainty and trace-stability proxies, combined with the fixed bit-conditioned rescaling and post-marker horizon, prove to be reliable indicators of final-answer correctness across model scales, quantization levels, and problem distributions, the method would offer a practical way to improve accuracy and efficiency of test-time compute allocation for quantized reasoning models without retraining. The explicit release of code and figure-generation scripts is a clear strength that supports reproducibility and independent verification. However, the current empirical support rests on very small shards of a single dataset and two model scales, so the broader utility remains to be established.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: The central empirical claim of accuracy improvement (+3.7 points at 7B, +2.8 at 14B) and reduced premature stopping rests on evaluation shards of size N=54 and N=35 that the authors themselves describe as 'not the full GSM8K test set' with 'limited statistical power.' To substantiate that the bit-calibrated proxies are faithful indicators of correctness, results on the complete test set (or substantially larger shards) with Wilson intervals or equivalent uncertainty estimates on all reported metrics, including token savings, are required.
- [Method / Experiments] Method and Experiments sections: The bit-conditioned rescaling rule and post-marker horizon are presented as fixed, non-calibrated components whose parameters are chosen once and applied at runtime. The manuscript does not report how these rules were selected or validated for robustness beyond the two Qwen2.5 scales tested; if the proxy-correctness correlation is weak or scale-specific, the reported accuracy edge over the non-bit-aware baseline would not generalize.
minor comments (2)
- [Abstract] Abstract: The phrase 'substantial token savings' is not quantified; reporting the actual average or median token counts (with uncertainty) for BitCal-TTS versus the fixed-budget baseline would improve clarity.
- The description of the non-bit-aware adaptive baseline is referenced but not fully specified in the provided abstract; a concise definition or pointer to its exact implementation would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on statistical robustness and methodological transparency. We address each major point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The central empirical claim of accuracy improvement (+3.7 points at 7B, +2.8 at 14B) and reduced premature stopping rests on evaluation shards of size N=54 and N=35 that the authors themselves describe as 'not the full GSM8K test set' with 'limited statistical power.' To substantiate that the bit-calibrated proxies are faithful indicators of correctness, results on the complete test set (or substantially larger shards) with Wilson intervals or equivalent uncertainty estimates on all reported metrics, including token savings, are required.
Authors: We agree that the evaluation shards are small and that this constrains statistical power, as the manuscript already states explicitly along with the Wilson 95% confidence intervals for accuracy. The shards were selected to support detailed per-problem analysis during development while releasing complete reproduction code. We will revise the Experiments section to add uncertainty estimates for token savings on the existing shards and to expand the limitations discussion. However, results on the full test set or substantially larger shards cannot be provided at this time. revision: partial
-
Referee: [Method / Experiments] Method and Experiments sections: The bit-conditioned rescaling rule and post-marker horizon are presented as fixed, non-calibrated components whose parameters are chosen once and applied at runtime. The manuscript does not report how these rules were selected or validated for robustness beyond the two Qwen2.5 scales tested; if the proxy-correctness correlation is weak or scale-specific, the reported accuracy edge over the non-bit-aware baseline would not generalize.
Authors: We will add a dedicated subsection to the Method section describing the design and selection of the bit-conditioned rescaling rule and post-marker horizon. These were determined via preliminary runs on a held-out development shard (separate from the evaluation data) to enforce conservatism under 4-bit quantization. The revised text will include the chosen parameter values and a short sensitivity check across the 7B and 14B scales to support the claim of robustness. revision: yes
- New experimental results on the complete GSM8K test set or substantially larger shards, including full uncertainty estimates on all metrics.
Circularity Check
No circularity: empirical controller with independent experimental validation
full rationale
The paper describes BitCal-TTS as a runtime controller that combines token-level uncertainty proxies, bit-conditioned rescaling, and a post-marker horizon, all applied without fine-tuning or per-model calibration. No derivation chain, first-principles prediction, or fitted parameter is presented whose output is equivalent to its inputs by construction. The reported accuracy gains (+3.7 points at 7B, +2.8 at 14B) and premature-stop reductions are empirical results on small GSM8K shards, not tautological outputs of any self-referential equation or self-citation. The method is self-contained against external benchmarks because its effectiveness is measured by direct comparison to a non-bit-aware baseline on held-out problems, with explicit discussion of limited statistical power. No load-bearing step reduces to a fit, renaming, or imported uniqueness theorem.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the- ar...
2020
-
[2]
bitsandbytes: 8-bit and 4-bit quantization library for PyTorch.https://github.com/TimDettmers/bitsandbytes, 2023
Tim Dettmers, Younes Belkada, Sourab Demir, and contributors. bitsandbytes: 8-bit and 4-bit quantization library for PyTorch.https://github.com/TimDettmers/bitsandbytes, 2023
2023
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[4]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jianhong Tu, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzh...
work page internal anchor Pith review arXiv 2024
-
[5]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824–24837, 2022
2022
-
[6]
Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[7]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale.arXiv preprint arXiv:2208.07339, 2022
work page internal anchor Pith review arXiv 2022
-
[10]
QLoRA: Efficient finetuningofquantizedLLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuningofquantizedLLMs. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[11]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review arXiv 2022
-
[12]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[13]
GPTQ: Accurate post- training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[14]
AWQ: Activation-aware weight quantization for LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. InProceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[15]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023
2023
-
[16]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well?
Junpeng Liu, Bowen Liu, Ming Yan, et al. A survey on test-time scaling for large language models.arXiv preprint arXiv:2503.24235, 2025. 14
work page internal anchor Pith review arXiv 2025
-
[18]
Tran, Yi Tay, and Donald Metzler
Tal Schuster, Adam Fisch, Jai Gupta, Mostafa Dehghani, Dara Bahri, Vinh Q. Tran, Yi Tay, and Donald Metzler. Confident adaptive language modeling.Advances in Neural Information Processing Systems (NeurIPS), 35, 2022
2022
-
[19]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In Advances in Neural Information Processing Systems (NeurIPS), volume 30, 2017
2017
-
[20]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In International Conference on Learning Representations (ICLR), 2024
2024
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Learning to reason with LLMs
OpenAI. Learning to reason with LLMs. OpenAI technical report, 2024.https://openai. com/index/learning-to-reason-with-llms/
2024
-
[23]
A careful examination of large language model performance on grade school arithmetic
Hugh Zhang, Jeff Da, Dean Lee, Vaughn Robinson, Catherine Wu, Will Song, Tiffany Zhao, Pranav Raja, Dylan Slack, Qin Lyu, et al. A careful examination of large language model performance on grade school arithmetic.arXiv preprint arXiv:2405.00332, 2024
-
[24]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021. A Notation Table 2 summarizes the symbols used in the paper. Table 2.Notation use...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.