Recognition: 2 theorem links
· Lean TheoremBelief Memory: Agent Memory Under Partial Observability
Pith reviewed 2026-05-11 00:43 UTC · model grok-4.3
The pith
BeliefMem stores multiple candidate conclusions with probabilities instead of single deterministic facts, preserving uncertainty for better agent decisions under partial observability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BeliefMem shifts the memory paradigm from committing to a single conclusion per observation to retaining multiple candidate conclusions with their probabilities. Each conclusion is stored as a separate memory entry whose probability is updated via Noisy-OR rules as new observations arrive. At retrieval, all candidates surface together with their probabilities, keeping alternatives visible to the agent. This preserves the uncertainty that deterministic methods discard, enabling the agent to act with high confidence on well-evidenced knowledge while retaining the capacity to update its confidence when new evidence arrives.
What carries the argument
BeliefMem, a memory store that keeps multiple candidate conclusions per observation as separate entries, each carrying an updatable probability, with all candidates returned together at retrieval time.
If this is right
- Agents can maintain high confidence on well-supported conclusions while still revising them when contradictory evidence appears.
- Error reinforcement loops are reduced because discarded alternatives remain accessible.
- Performance gains appear on LoCoMo and ALFWorld even with limited training data.
- The approach opens a direction for memory designs that treat uncertainty as first-class rather than something to be resolved at storage time.
Where Pith is reading between the lines
- The same multi-candidate structure could be applied to memory modules that use retrieval-augmented generation, letting the retriever return ranked alternatives instead of a single top hit.
- If the probability values are surfaced in a way the LLM can parse reliably, downstream planning modules could explicitly reason about expected value under different memory states.
- The method might be combined with active sensing policies that deliberately seek observations likely to differentiate among the top remaining candidates.
Load-bearing premise
That presenting multiple probabilistic candidates to the LLM at retrieval time will improve downstream decision quality without overwhelming the model's context or causing it to ignore high-probability options.
What would settle it
A controlled test in which BeliefMem is run on the same observation sequences as a deterministic baseline but the LLM is forced to ignore or down-weight all but the single highest-probability candidate; if performance then drops to baseline levels, the benefit is shown to depend on the model actually using the probability information.
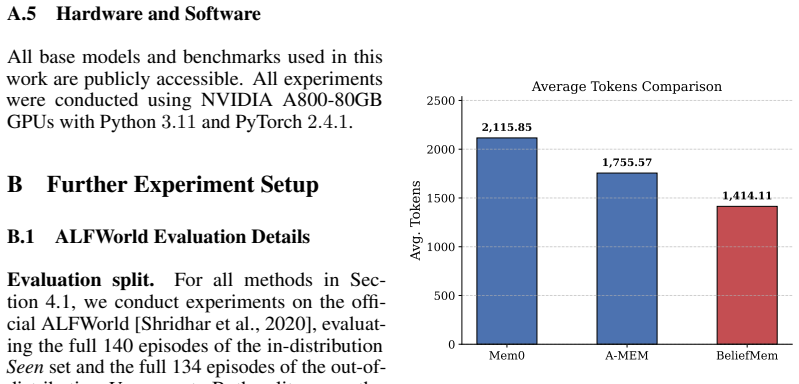
Figures





read the original abstract
LLM agents that operate over long context depend on external memory to accumulate knowledge over time. However, existing methods typically store each observation as a single deterministic conclusion (e.g., inferring "API~X failed" from temporary errors), even though such observations are inherently partial and potentially ambiguous. By committing to one conclusion and discarding uncertainty, these methods introduce self-reinforcing error: the agent acts on the stored conclusion, never revisits alternatives, and reinforces the conclusion over time. To address this issue, we propose BeliefMem, which shifts the memory paradigm from committing to a single conclusion per observation to retaining multiple candidate conclusions with their probabilities. Concretely, BeliefMem stores the candidate conclusions as separate memory entries, each carrying a probability that is updated via Noisy-OR rules as new observations arrive. At retrieval, all candidates surface together with their probabilities, keeping alternatives visible to the agent. Since each conclusion in memory retains its probability, BeliefMem preserves the uncertainty that the deterministic paradigm discards, enabling the agent to act with high confidence on well-evidenced knowledge while retaining the capacity to update its confidence when new evidence arrives. Empirical evaluations on LoCoMo and ALFWorld benchmarks show that, even with limited data, BeliefMem achieves the best average performance, remarkably outperforming well-known baselines. More broadly, such probabilistic memory produces substantial gains and explores a new direction for agent memory in partially observable environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BeliefMem, a memory architecture for LLM agents in partially observable environments. Rather than committing each observation to a single deterministic conclusion (which can propagate errors), BeliefMem maintains multiple candidate conclusions per observation, each with an associated probability that is updated via Noisy-OR rules upon new evidence. At retrieval time, all candidates and their probabilities are surfaced together to the agent. The central empirical claim is that this probabilistic approach yields the best average performance on the LoCoMo and ALFWorld benchmarks, outperforming standard baselines even with limited data.
Significance. If the reported gains are robust, BeliefMem offers a concrete mechanism for preserving and exploiting uncertainty in agent memory, addressing a recurring failure mode in long-horizon POMDP-style tasks. The work is notable for shifting the memory paradigm explicitly toward probabilistic representations rather than post-hoc prompting tricks; this could influence future designs of retrieval-augmented agents. No machine-checked proofs or parameter-free derivations are present, but the core idea is falsifiable via the stated benchmarks.
major comments (2)
- [Experimental Evaluation] Experimental section (and abstract): the claim that BeliefMem 'achieves the best average performance, remarkably outperforming well-known baselines' is not supported by any quantitative scores, named baselines, statistical tests, error bars, or ablation isolating the Noisy-OR / multi-candidate component from retrieval formatting or prompt choices. Without these data the central empirical assertion cannot be evaluated.
- [Method] Method section: the precise implementation of the Noisy-OR update rule, the representation of probability values in memory entries, and the exact formatting used when surfacing multiple candidates to the LLM are not specified in sufficient detail for reproducibility or to diagnose why the probabilistic approach succeeds (or fails) on particular tasks.
minor comments (2)
- [Abstract] Abstract: 'well-known baselines' should be named explicitly.
- [Method] Notation: the probability update rule would benefit from a compact equation or pseudocode block rather than prose description only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that both the experimental claims and methodological details require substantial clarification and expansion to support the central assertions and ensure reproducibility. We outline our responses below and will incorporate all suggested improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section (and abstract): the claim that BeliefMem 'achieves the best average performance, remarkably outperforming well-known baselines' is not supported by any quantitative scores, named baselines, statistical tests, error bars, or ablation isolating the Noisy-OR / multi-candidate component from retrieval formatting or prompt choices. Without these data the central empirical assertion cannot be evaluated.
Authors: We acknowledge that the current version of the manuscript does not present the supporting quantitative data in sufficient detail within the abstract or experimental section. In the revision we will add a dedicated results section containing: (1) explicit performance tables with average scores on LoCoMo and ALFWorld, (2) named baselines including deterministic memory, standard RAG, and other retrieval-augmented agents, (3) error bars or standard deviations from repeated runs, (4) statistical significance tests (e.g., paired t-tests or Wilcoxon), and (5) an ablation study that isolates the contribution of the Noisy-OR update and multi-candidate retention from prompt formatting and retrieval choices. These additions will directly substantiate the claim of superior average performance. revision: yes
-
Referee: [Method] Method section: the precise implementation of the Noisy-OR update rule, the representation of probability values in memory entries, and the exact formatting used when surfacing multiple candidates to the LLM are not specified in sufficient detail for reproducibility or to diagnose why the probabilistic approach succeeds (or fails) on particular tasks.
Authors: We agree that the method section lacks the required implementation specifics. In the revised manuscript we will: (1) provide the exact mathematical formulation of the Noisy-OR update rule applied to candidate probabilities, (2) describe the internal representation of probability values (stored as normalized floats in [0,1] per memory entry), and (3) include the precise prompt templates and formatting used to surface multiple candidates together with their probabilities to the LLM. These additions will enable full reproducibility and allow readers to analyze task-specific behavior. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces BeliefMem as a new paradigm for handling partial observability in LLM agent memory by retaining probabilistic candidate conclusions updated via Noisy-OR rules, rather than deriving performance claims from equations or prior self-referential results. No load-bearing derivations, fitted predictions, uniqueness theorems, or ansatzes are presented that reduce the method or its empirical gains to inputs by construction. Central claims rest on benchmark evaluations (LoCoMo, ALFWorld) and the conceptual shift from deterministic to probabilistic storage, which is self-contained and externally falsifiable via the reported experiments. No self-citation chains or renamings of known results appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Noisy-OR rules provide a suitable mechanism for updating probabilities of multiple candidate conclusions as new observations arrive
invented entities (1)
-
BeliefMem
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBeliefMem maintains active candidate conclusions for each piece of stored knowledge, assigning each conclusion a probability updated via noisy-OR evidence merge
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearreplaces the deterministic paradigm with an attribute-level belief representation that approximates the belief state b(c)_t
Reference graph
Works this paper leans on
-
[1]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2603.07670 (2026) arXiv:2603.07670
Pengfei Du. Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers. arXiv preprint arXiv:2603.07670,
-
[3]
arXiv preprint arXiv:2511.01805 , year=
Jiayi Geng, Howard Chen, Ryan Liu, Manoel Horta Ribeiro, Robb Willer, Graham Neubig, and Thomas L Griffiths. Accumulating context changes the beliefs of language models.arXiv preprint arXiv:2511.01805,
-
[4]
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025a. Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025b. Aa...
-
[5]
Pabu: Progress-aware belief update for efficient llm agents.arXiv preprint arXiv:2602.09138,
Haitao Jiang, Lin Ge, Hengrui Cai, and Rui Song. Pabu: Progress-aware belief update for efficient llm agents.arXiv preprint arXiv:2602.09138,
-
[6]
Memory os of ai agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972–25981,
2025
-
[7]
Chingkwun Lam, Jiaxin Li, Lingfei Zhang, and Kuo Zhao. Governing evolving memory in llm agents: Risks, mechanisms, and the stability and safety governed memory (ssgm) framework. arXiv preprint arXiv:2603.11768,
-
[8]
arXiv preprint arXiv:2402.09727 , year=
GitHub reposi- tory. Kuang-Huei Lee, Xinyun Chen, Hiroki Furuta, John Canny, and Ian Fischer. A human-inspired reading agent with gist memory of very long contexts.arXiv preprint arXiv:2402.09727,
-
[9]
Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724, 2025
Zhiyu Li, Chenyang Xi, Chunyu Li, Ding Chen, Boyu Chen, Shichao Song, Simin Niu, Hanyu Wang, Jiawei Yang, Chen Tang, et al. Memos: A memory os for ai system.arXiv preprint arXiv:2507.03724,
-
[10]
Aly Lidayan, Jakob Bjorner, Satvik Golechha, Kartik Goyal, and Alane Suhr. Abbel: Llm agents acting through belief bottlenecks expressed in language.arXiv preprint arXiv:2512.20111,
-
[11]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956,
work page internal anchor Pith review arXiv
-
[12]
Shuai Shao, Qihan Ren, Chen Qian, Boyi Wei, Dadi Guo, Jingyi Yang, Xinhao Song, Linfeng Zhang, Weinan Zhang, Dongrui Liu, et al. Your agent may misevolve: Emergent risks in self-evolving llm agents.arXiv preprint arXiv:2509.26354,
-
[13]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review arXiv 2010
-
[14]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Zhimin Wang, Shaokang He, Duo Wu, Jinghe Wang, Linjia Kang, Jing Yu, and Zhi Wang. Cobel- world: Harnessing llm reasoning to build a collaborative belief world for optimizing embodied multi-agent collaboration.arXiv preprint arXiv:2509.21981,
-
[16]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828,
work page internal anchor Pith review arXiv
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Joshua C Yang, Damian Dailisan, and Maurice Flechtner. Belief engine: Bayesian memory for configurable opinion dynamics in llm agents. InICLR 2026 Workshop on Memory for LLM-Based Agentic Systems. Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026a. Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving...
work page internal anchor Pith review arXiv
-
[21]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841,
-
[22]
And the previous value is retained as a historical version
A.2 Contradictory Memory For any candidate conclusion h, if the observation ot+1 provides evidence to support a contradictory conclusion, the current belief of h is reduced to 0.25, calledVersion. And the previous value is retained as a historical version. Specifically, we use a rule-based criterion to identify contradictory conclusions: Formally, let (c,...
2000
-
[23]
memories
As detailed, we observe a generalization trade-off related to memory corpus size. Specifically, BeliefMem achieves its highest out-of-distribution (ALF-Unseen) success rate of 61.19% and optimal average performance of 59.88% using only 1,500 samples, representing exactly 50% of the sampled memory corpus. Additionally, the agent also exhibits maximum behav...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.