Recognition: unknown
In-Context Positive-Unlabeled Learning
Pith reviewed 2026-05-08 05:51 UTC · model grok-4.3
The pith
A pretrained transformer performs positive-unlabeled classification in one forward pass by receiving labeled positives and unlabeled samples together as input.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
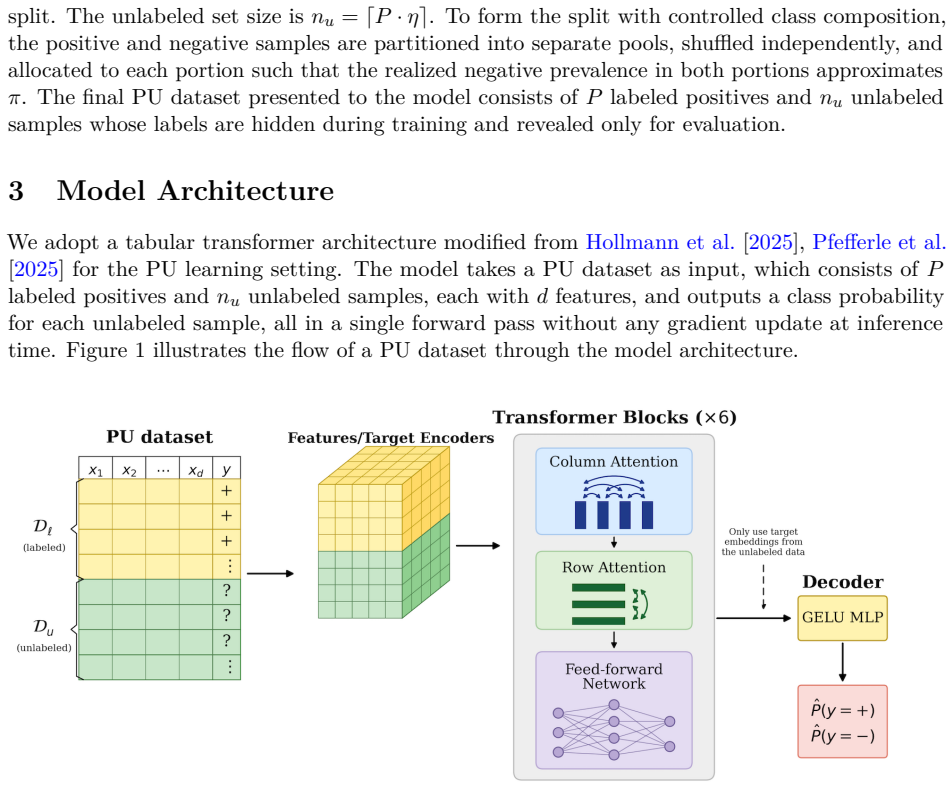
PUICL is a pretrained transformer that solves PU classification entirely through in-context learning. It is pretrained on synthetic PU datasets generated from randomly instantiated structural causal models, exposing it to a wide range of feature-label relationships and class-prior configurations. At inference time, PUICL receives the labeled positives and the unlabeled samples as a single input and returns class probabilities for the unlabeled rows in one forward pass, with no gradient updates or per-task fitting. On 20 semi-synthetic PU benchmarks derived from the UCI Machine Learning Repository, OpenML, and scikit-learn, PUICL outperforms four standard PU learning baselines in average AUC
What carries the argument
The PUICL transformer that ingests a concatenated sequence of labeled positives and unlabeled rows and directly emits label probabilities for the unlabeled rows via in-context learning.
If this is right
- PU classification tasks can be solved without gradient updates or iterative optimization on each new dataset.
- A single pretrained model can handle many different class-prior and feature-label configurations after exposure only to synthetic causal data.
- The in-context learning paradigm extends from fully supervised tabular prediction to the positive-unlabeled semi-supervised setting.
- Deployment across numerous PU problems becomes feasible with only one inference pass per task.
Where Pith is reading between the lines
- Domains such as medical screening or fraud detection, where confirmed negatives are scarce, could apply the same model to new data streams without retraining.
- The method implies that explicit modeling of label noise or class priors can be replaced by implicit learning from synthetic causal examples presented in context.
- Further scaling the diversity of the synthetic pretraining distribution could increase robustness when real data deviates from the causal-model assumptions.
Load-bearing premise
Pretraining on synthetic PU datasets generated from randomly instantiated structural causal models exposes the model to a sufficiently wide range of feature-label relationships and class-prior configurations that it generalizes to real-world PU problems without any dataset-specific adaptation.
What would settle it
On a held-out real-world PU dataset drawn from a domain absent from the pretraining distribution, if PUICL achieves lower average AUC than the best baseline method that performs dataset-specific fitting, the claim that one forward pass suffices without adaptation would be refuted.
Figures
read the original abstract
Positive-unlabeled (PU) learning addresses binary classification when only a set of labeled positives is available alongside a pool of unlabeled samples drawn from a mixture of positives and negatives. Existing PU methods typically require dataset-specific training or iterative optimization, which limits their applicability when many tasks must be solved quickly or with little tuning. We introduce PUICL, a pretrained transformer that solves PU classification entirely through in-context learning. PUICL is pretrained on synthetic PU datasets generated from randomly instantiated structural causal models, exposing it to a wide range of feature-label relationships and class-prior configurations. At inference time, PUICL receives the labeled positives and the unlabeled samples as a single input and returns class probabilities for the unlabeled rows in one forward pass, with no gradient updates or per-task fitting. On 20 semi-synthetic PU benchmarks derived from the UCI Machine Learning Repository, OpenML, and scikit-learn, PUICL outperforms four standard PU learning baselines in average AUC and accuracy, and is competitive on F1-score. These results show that the in-context learning paradigm extends naturally beyond fully supervised tabular prediction to the semi-supervised PU setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PUICL, a transformer pretrained on synthetic positive-unlabeled (PU) datasets generated from randomly instantiated structural causal models. At inference, it performs PU classification entirely via in-context learning by taking labeled positives and unlabeled samples as input and outputting class probabilities for the unlabeled rows in a single forward pass, without gradient updates or per-task fitting. The central empirical claim is that on 20 semi-synthetic PU benchmarks derived from UCI, OpenML, and scikit-learn datasets, PUICL outperforms four standard PU baselines in average AUC and accuracy while remaining competitive on F1-score.
Significance. If the results hold under rigorous validation, the work would demonstrate that in-context learning can be successfully extended to the PU setting, providing a training-free method for solving multiple PU tasks rapidly. This could be impactful for tabular semi-supervised problems where dataset-specific optimization is costly. The pretraining strategy on diverse synthetic SCMs is a notable strength for exposing the model to varied class priors and feature-label relationships.
major comments (3)
- [Experimental Results] Experimental Results section: The abstract and results claim outperformance on 20 benchmarks in AUC and accuracy, but provide no details on benchmark construction (e.g., how positives are selected from the original datasets, how class priors are set in the semi-synthetic versions, or the exact mixture ratios for unlabeled data). This information is load-bearing for assessing whether the gains reflect genuine in-context PU inference rather than artifacts of benchmark design.
- [Methods and Pretraining] Methods and Pretraining section: No analysis or ablation is presented on the distribution shift between the pretraining distribution (randomly instantiated SCMs, typically yielding continuous variables with known causal structure) and the evaluation distribution (semi-synthetic versions of real tabular UCI/OpenML data, which may contain discrete features, domain artifacts, or different dependence structures). This is central to the claim that the model generalizes without adaptation.
- [Results] Results section, performance tables: The reported average AUC/accuracy gains lack accompanying statistical significance tests, standard errors, or per-benchmark breakdowns with error bars. Without these, it is impossible to determine whether the outperformance is robust or driven by a few datasets, undermining the cross-benchmark superiority claim.
minor comments (2)
- [Abstract] Abstract: The four standard PU learning baselines are not named; listing them (e.g., nnPU, PUbN, etc.) would improve clarity for readers unfamiliar with the PU literature.
- [Methods] Notation: The description of the input format for in-context learning (how positives and unlabeled samples are concatenated or prompted) could be made more precise with an explicit example or pseudocode.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Experimental Results section: The abstract and results claim outperformance on 20 benchmarks in AUC and accuracy, but provide no details on benchmark construction (e.g., how positives are selected from the original datasets, how class priors are set in the semi-synthetic versions, or the exact mixture ratios for unlabeled data). This information is load-bearing for assessing whether the gains reflect genuine in-context PU inference rather than artifacts of benchmark design.
Authors: We agree that the current manuscript provides insufficient detail on benchmark construction. In the revised version we will add a dedicated subsection under Experimental Results that specifies: (i) positives are obtained by randomly subsampling a fraction of the original positive instances according to the source dataset labels; (ii) class priors are set either to the empirical positive rate of the source data or to controlled values (0.2–0.5) for semi-synthetic variants; and (iii) unlabeled sets are formed by mixing the remaining positives and negatives at explicit ratios (e.g., 30 % positive). These additions will make the evaluation protocol fully reproducible and allow readers to judge whether the reported gains arise from genuine in-context PU inference. revision: yes
-
Referee: Methods and Pretraining section: No analysis or ablation is presented on the distribution shift between the pretraining distribution (randomly instantiated SCMs, typically yielding continuous variables with known causal structure) and the evaluation distribution (semi-synthetic versions of real tabular UCI/OpenML data, which may contain discrete features, domain artifacts, or different dependence structures). This is central to the claim that the model generalizes without adaptation.
Authors: The referee rightly notes the absence of explicit distribution-shift analysis. While our pretraining deliberately samples SCMs with varied causal structures and includes both continuous and discretized variables, we did not quantify the shift to the UCI/OpenML evaluation sets. In the revision we will insert a discussion paragraph in the Methods section explaining how in-context learning enables adaptation to new distributions at inference time, and we will add a limited ablation on a subset of benchmarks comparing performance before and after feature discretization. A full-scale ablation across all 20 benchmarks is computationally intensive and will be noted as future work; the current revision therefore provides a targeted rather than exhaustive treatment. revision: partial
-
Referee: Results section, performance tables: The reported average AUC/accuracy gains lack accompanying statistical significance tests, standard errors, or per-benchmark breakdowns with error bars. Without these, it is impossible to determine whether the outperformance is robust or driven by a few datasets, undermining the cross-benchmark superiority claim.
Authors: We accept this criticism. The revised manuscript will expand the Results section to include: paired Wilcoxon signed-rank tests comparing PUICL against each baseline across the 20 benchmarks for AUC, accuracy, and F1; standard errors computed over multiple random seeds where applicable; and an appendix table with per-benchmark scores together with error bars. These additions will allow readers to assess both average performance and variability, thereby strengthening the cross-benchmark superiority claim. revision: yes
Circularity Check
No circularity: pretraining distribution independent of evaluation benchmarks; results not reduced to fitted inputs by construction.
full rationale
The paper pretrains a transformer on synthetic PU datasets generated from randomly instantiated structural causal models, then applies it via in-context learning (one forward pass, no per-task updates) to separate semi-synthetic benchmarks derived from UCI, OpenML, and scikit-learn repositories. Performance metrics (AUC, accuracy, F1) are reported on these held-out benchmarks without any equation or procedure that fits parameters to the evaluation data and then renames the fit as a prediction. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core method; the derivation chain from pretraining to inference remains self-contained against external data sources.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic PU datasets generated from randomly instantiated structural causal models cover a sufficiently broad range of feature-label relationships and class priors to enable generalization to real PU problems.
invented entities (1)
-
PUICL pretrained transformer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
and Niu, Gang and Sugiyama, Masashi , journal=
du Plessis, Marthinus C. and Niu, Gang and Sugiyama, Masashi , journal=. Analysis of Learning from Positive and Unlabeled Data , volume =
-
[2]
Duan, Rui and Ning, Yang and Wang, Shuang and Lindsay, Bruce G. and Carroll, Raymond J. and Chen, Yong , title =. Biometrics , volume =. 2019 , month =. doi:10.1111/biom.13204 , eprint =
-
[3]
and Escobar, Luis A
Meeker, William Q. and Escobar, Luis A. , year =. Statistical methods for reliability data , isbn =
-
[4]
Double/debiased machine learning for treatment and structural parameters , volume =. The Econometrics Journal , author =. 2018 , pages =. doi:10.1111/ectj.12097 , language =
-
[5]
Mathematics for
Deisenroth, Marc Peter and Faisal, A Aldo and Ong, Cheng Soon , pages =. Mathematics for
-
[6]
, year =
Bishop, Christopher M. , year =. Pattern recognition and machine learning , isbn =
-
[7]
All of nonparametric statistics , isbn =
Wasserman, Larry , year =. All of nonparametric statistics , isbn =
-
[8]
Understanding
Shalev-Shwartz, Shai and Ben-David, Shai , pages =. Understanding
-
[9]
Predicting good probabilities with supervised learning , isbn =
Niculescu-Mizil, Alexandru and Caruana, Rich , month = aug, year =. Predicting good probabilities with supervised learning , isbn =. Proceedings of the 22nd international conference on. doi:10.1145/1102351.1102430 , abstract =
-
[10]
Qiu, Hongxiang and Dobriban, Edgar and Tchetgen, Eric Tchetgen , month = may, year =. Distribution-free. doi:10.48550/arXiv.2203.06126 , abstract =
-
[11]
arXiv preprint arXiv:2106.09848 , year=
Park, Sangdon and Dobriban, Edgar and Lee, Insup and Bastani, Osbert , month = mar, year =. doi:10.48550/arXiv.2106.09848 , abstract =
-
[12]
Ma, Wenao and Chen, Cheng and Zheng, Shuang and Qin, Jing and Zhang, Huimao and Dou, Qi , month = jul, year =. Test-time. doi:10.48550/arXiv.2207.00769 , abstract =
-
[13]
Adaptive
Gibbs, Isaac and Candes, Emmanuel , year =. Adaptive. Advances in
-
[14]
Yang, Yachong and Kuchibhotla, Arun Kumar and Tchetgen, Eric Tchetgen , month = may, year =. Doubly. doi:10.48550/arXiv.2203.01761 , abstract =
-
[15]
He, Yue and Wang, Zimu and Cui, Peng and Zou, Hao and Zhang, Yafeng and Cui, Qiang and Jiang, Yong , month = apr, year =. Proceedings of the. doi:10.1145/3485447.3511969 , abstract =
-
[16]
Sahoo, Roshni and Lei, Lihua and Wager, Stefan , month = jan, year =. Learning from a. doi:10.48550/arXiv.2209.01754 , abstract =
-
[17]
40 puzzles and problems in probability and mathematical statistics , isbn =
Schwarz, Wolfgang , year =. 40 puzzles and problems in probability and mathematical statistics , isbn =
-
[18]
The Econometrics Journal , author =
The practice of non-parametric estimation by solving inverse problems: the example of transformation models , volume =. The Econometrics Journal , author =. 2010 , note =
2010
-
[19]
Yu, Xiyu and Liu, Tongliang and Gong, Mingming and Zhang, Kun and Batmanghelich, Kayhan and Tao, Dacheng , month = nov, year =. Label-. Proceedings of the 37th
-
[20]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Angelopoulos, Anastasios N. and Bates, Stephen , month = dec, year =. A. doi:10.48550/arXiv.2107.07511 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2107.07511
-
[21]
and Ravikumar, Pradeep , month = feb, year =
Aragam, Bryon and Dan, Chen and Xing, Eric P. and Ravikumar, Pradeep , month = feb, year =. Identifiability of
-
[22]
Journal of Machine Learning Research , volume=
Semi-supervised novelty detection , author=. Journal of Machine Learning Research , volume=
-
[23]
Detecting and
Lipton, Zachary and Wang, Yu-Xiang and Smola, Alexander , month = jul, year =. Detecting and. Proceedings of the 35th
-
[24]
doi:10.1198/jcgs.2009.07175 , file =
An. doi:10.1198/jcgs.2009.07175 , file =
-
[25]
Practical identifiability of finite mixtures of multivariate bernoulli distributions , volume =. Neural Computation , author =. 2000 , pmid =. doi:10.1162/089976600300015925 , abstract =
-
[26]
, month = oct, year =
Zhu, Zheqi and Fan, Pingyi and Peng, Chenghui and Letaief, Khaled B. , month = oct, year =
-
[27]
Zecchin, Matteo and Kountouris, Marios and Gesbert, David , month = oct, year =. Communication-. doi:10.48550/arXiv.2205.15614 , abstract =
-
[28]
The Annals of Statistics , author =
Identifiability of. The Annals of Statistics , author =. 2009 , pages =
2009
-
[29]
Yu, Shuang and Li, Chunping , editor =. Machine. 2007 , keywords =. doi:10.1007/978-3-540-73499-4_43 , abstract =
-
[30]
and Tao, Dacheng , month = mar, year =
He, Fengxiang and Liu, Tongliang and Webb, Geoffrey I. and Tao, Dacheng , month = mar, year =. Instance-
-
[31]
Estimating the class prior and posterior from noisy positives and unlabeled data , url =
Jain, Shantanu and White, Martha and Radivojac, Predrag , month = jan, year =. Estimating the class prior and posterior from noisy positives and unlabeled data , url =
-
[32]
Alexandari, Amr and Kundaje, Anshul and Shrikumar, Avanti , month = nov, year =. Maximum. Proceedings of the 37th
-
[33]
Journal of the Royal Statistical Society
Prediction and outlier detection in classification problems , volume =. Journal of the Royal Statistical Society. Series B, Statistical Methodology , author =. 2022 , pmid =. doi:10.1111/rssb.12443 , abstract =
-
[34]
A general theory of identification , url =
Basse, Guillaume and Bojinov, Iavor , month = feb, year =. A general theory of identification , url =
-
[35]
Handbook of
Cure. Handbook of. 2013 , note =
2013
-
[36]
Annual Review of Statistics and Its Application , author =
Cure. Annual Review of Statistics and Its Application , author =. 2018 , note =. doi:10.1146/annurev-statistics-031017-100101 , abstract =
-
[37]
Recommendations as
Schnabel, Tobias and Swaminathan, Adith and Singh, Ashudeep and Chandak, Navin and Joachims, Thorsten , pages =. Recommendations as
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
Modelling. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2015 , note =. doi:10.1609/aaai.v29i1.9612 , abstract =
-
[39]
A generalised label noise model for classification in the presence of annotation errors , volume =. Neurocomputing , author =. 2016 , keywords =. doi:10.1016/j.neucom.2015.12.106 , abstract =
-
[40]
Covariate shift adaptation on learning from positive and unlabeled data
-
[41]
Zhang, Xin and Fang, Minghong and Liu, Zhuqing and Yang, Haibo and Liu, Jia and Zhu, Zhengyuan , month = oct, year =. Proceedings of the. doi:10.1145/3492866.3549723 , abstract =
-
[42]
Modeling delayed feedback in display advertising , isbn =
Chapelle, Olivier , month = aug, year =. Modeling delayed feedback in display advertising , isbn =. Proceedings of the 20th. doi:10.1145/2623330.2623634 , abstract =
-
[43]
Yasui, Shota and Morishita, Gota and Fujita, Komei and Shibata, Masashi , month = apr, year =. A. Proceedings of. doi:10.1145/3366423.3380032 , abstract =
-
[44]
Garg, Saurabh and Wu, Yifan and Balakrishnan, Sivaraman and Lipton, Zachary , year =. A. Advances in
-
[45]
Courty, Nicolas and Flamary, Rémi and Tuia, Devis and Rakotomamonjy, Alain , month = jun, year =. Optimal
-
[46]
Le, Trung and Do, Dat and Nguyen, Tuan and Nguyen, Huy and Bui, Hung and Ho, Nhat and Phung, Dinh , month = mar, year =. On
-
[47]
Deng, Songgaojun and Wang, Shusen and Rangwala, Huzefa and Wang, Lijing and Ning, Yue , month = oct, year =. Cola-. Proceedings of the 29th. doi:10.1145/3340531.3411975 , abstract =
-
[48]
Wilson, Tyler and McDonald, Andrew and Galib, Asadullah Hill and Tan, Pang-Ning and Luo, Lifeng , month = aug, year =. Beyond. Proceedings of the 28th. doi:10.1145/3534678.3539464 , abstract =
-
[49]
Time. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , author =. 2021 , note =. doi:10.1098/rsta.2020.0209 , abstract =
-
[50]
A review of novelty detection , volume =. Signal Processing , author =. 2014 , pages =. doi:10.1016/j.sigpro.2013.12.026 , abstract =
-
[51]
Garg, Saurabh and Wu, Yifan and Smola, Alexander J and Balakrishnan, Sivaraman and Lipton, Zachary , journal =. Mixture. 2021 , pages =
2021
-
[52]
Na, Byeonghu and Kim, Hyemi and Song, Kyungwoo and Joo, Weonyoung and Kim, Yoon-Yeong and Moon, Il-Chul , month = oct, year =. Deep. Proceedings of the 29th. doi:10.1145/3340531.3411971 , abstract =
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Instance-. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2021 , keywords =. doi:10.1109/TPAMI.2021.3061456 , language =
-
[54]
Joint estimation of posterior probability and propensity score function for positive and unlabelled data , url =
Furmańczyk, Konrad and Mielniczuk, Jan and Rejchel, Wojciech and Teisseyre, Paweł , month = sep, year =. Joint estimation of posterior probability and propensity score function for positive and unlabelled data , url =
-
[55]
Learning from positive and unlabeled data: a survey
Learning from positive and unlabeled data: a survey , volume =. Machine Learning , author =. 2020 , keywords =. doi:10.1007/s10994-020-05877-5 , abstract =
-
[56]
Bekker, Jessa and Robberechts, Pieter and Davis, Jesse , editor =. Beyond the. 2020 , note =. doi:10.1007/978-3-030-46147-8_5 , abstract =
-
[57]
Smola, Alex and Gretton, Arthur and Song, Le and Scholkopf, Bernhard , pages =. A
-
[58]
Gretton, Arthur and Borgwardt, Karsten and Rasch, Malte and Schölkopf, Bernhard and Smola, Alex , year =. A. Advances in
-
[59]
Efficient error models for fault-tolerant architectures and the Pauli twirling approximation
Demystifying. The American Statistician , author =. 2022 , pages =. doi:10.1080/00031305.2021.2021984 , abstract =
work page Pith review doi:10.1080/00031305.2021.2021984 2022
-
[60]
Journal of Statistical Planning and Inference , volume = 90, number = 2, pages =
Improving predictive inference under covariate shift by weighting the log-likelihood function , volume =. Journal of Statistical Planning and Inference , author =. 2000 , keywords =. doi:10.1016/S0378-3758(00)00115-4 , abstract =
-
[61]
, year =
Tsiatis, Anastasios A. , year =. Semiparametric theory and missing data , isbn =
-
[62]
and MacKay, R
Steiner, Stefan H. and MacKay, R. Jock , year =. Statistical engineering: an algorithm for reducing variation in manufacturing processes , isbn =
-
[63]
, year =
McLachlan, Geoffrey J. , year =. Discriminant analysis and statistical pattern recognition , isbn =
-
[64]
Sun, Baochen and Saenko, Kate , editor =. Deep. Computer. 2016 , keywords =. doi:10.1007/978-3-319-49409-8_35 , abstract =
-
[65]
Zhang, Weichen and Ouyang, Wanli and Li, Wen and Xu, Dong , month = jun, year =. Collaborative and. 2018. doi:10.1109/CVPR.2018.00400 , abstract =
-
[66]
Optimal transport for conditional domain matching and label shift , volume =. Machine Learning , author =. 2022 , keywords =. doi:10.1007/s10994-021-06088-2 , abstract =
-
[67]
Discriminative
Bickel, Steffen and De, Cs Uni-Potsdam and De, Cs Uni-Potsdam and De, Cs Uni-Potsdam , keywords =. Discriminative
-
[68]
Zhang, Kun and Scholkopf, Bernhard and Muandet, Krikamol and Wang, Zhikun , keywords =. Domain
-
[69]
Garg, Saurabh and Balakrishnan, Sivaraman and Lipton, Zachary C. , month = jul, year =. Domain. doi:10.48550/arXiv.2207.13048 , abstract =
-
[70]
Flexible
Wang, Xuezhi and Schneider, Jeff , year =. Flexible. Advances in
-
[71]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
Importance. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2021 , note =. doi:10.1109/TPAMI.2021.3086060 , abstract =
-
[72]
Minimax optimal approaches to the label shift problem , url =
Maity, Subha and Sun, Yuekai and Banerjee, Moulinath , month = apr, year =. Minimax optimal approaches to the label shift problem , url =. doi:10.48550/arXiv.2003.10443 , abstract =
-
[73]
Moreno-Torres and Troy Raeder and Roc
A unifying view on dataset shift in classification , volume =. Pattern Recognition , author =. 2012 , keywords =. doi:10.1016/j.patcog.2011.06.019 , abstract =
-
[74]
Covariate
Gretton, Arthur and Smola, Alex and Huang, Jiayuan and Schmittfull, Marcel and Borgwardt, Karsten and Schölkopf, Bernhard , editor =. Covariate. Dataset. 2008 , doi =
2008
-
[75]
Bridging
Zhang, Yuchen and Liu, Tianle and Long, Mingsheng and Jordan, Michael , month = may, year =. Bridging. Proceedings of the 36th
-
[76]
Covariate
Sugiyama, Masashi and Krauledat, Matthias , keywords =. Covariate
-
[77]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =
A review of domain adaptation without target labels , volume =. IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2021 , note =. doi:10.1109/TPAMI.2019.2945942 , abstract =
-
[78]
Rabanser, Stephan and Günnemann, Stephan and Lipton, Zachary , year =. Failing. Advances in
-
[79]
Advances in
Sohn, Kihyuk and Berthelot, David and Carlini, Nicholas and Zhang, Zizhao and Zhang, Han and Raffel, Colin A and Cubuk, Ekin Dogus and Kurakin, Alexey and Li, Chun-Liang , year =. Advances in
-
[80]
Domain Adaptation in Computer Vision Applications , author =
Domain-. Domain Adaptation in Computer Vision Applications , author =. 2017 , pages =. doi:10.1007/978-3-319-58347-1_10 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.