Recognition: unknown
The Cost of Context: Mitigating Textual Bias in Multimodal Retrieval-Augmented Generation
Pith reviewed 2026-05-08 11:14 UTC · model grok-4.3
The pith
Even perfectly accurate context can make multimodal models abandon correct answers by suppressing image attention and fixating on text boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that recorruption arises even when the added context is perfectly accurate, because internal attention undergoes a two-fold collapse: visual blindness that reduces both the total mass and the sharpness of attention to image tokens, plus a structural positional bias that elevates boundary tokens over semantically relevant ones, creating an illusion of success whenever textual copying happens to match the ground-truth location.
What carries the argument
The two-fold attentional collapse, consisting of visual blindness (suppressed M_vis and S_vis) and structural positional bias in the attention matrices, which BAIR counters at inference time by restoring visual saliency and imposing position-aware penalties on textual distractors.
If this is right
- Adding external documents can reduce multimodal grounding even when those documents contain the correct information.
- Apparent correctness in RAG outputs often stems from coincidental alignment with the model's bias toward copying boundary tokens.
- A parameter-free attention intervention at inference time can recover visual focus and raise accuracy on factuality, fairness, and geospatial tasks.
- Textual bias in attention matrices creates a hidden cost that scales with the amount of retrieved context.
Where Pith is reading between the lines
- Similar attention patterns may appear in non-multimodal RAG systems when long contexts are introduced, suggesting the positional bias is not limited to images.
- The same intervention approach could be tested on other modalities such as audio or video to check whether boundary bias generalizes.
- If attention collapse is causal, then future model architectures might need explicit safeguards against context-induced visual suppression rather than relying on scale alone.
Load-bearing premise
Observed shifts in attention mass and sharpness are the direct cause of the model changing its output rather than a side effect that would persist even if attention were restored.
What would settle it
A controlled test in which the attention patterns are artificially restored to pre-context levels yet the model still switches away from its original correct answer would disprove the claimed causal role of the collapse.
Figures







read the original abstract
While Multimodal Large Language Models (MLLMs) are increasingly integrated with Retrieval-Augmented Generation (RAG) to mitigate hallucinations, the introduction of external documents can conceal severe failure modes at the instance level. We identify and formalize the phenomenon of recorruption, where the introduction of even perfectly accurate "oracle" context causes a capable model to abandon an initially correct prediction. Through a mechanistic diagnosis of internal attention matrices, we show that recorruption is driven by a two-fold attentional collapse: (1) visual blindness, characterized by the systemic suppression of visual attention mass ($M_{vis}$) and sharpness ($S_{vis}$), and (2) a structural positional bias that forces the model to prioritize boundary tokens over semantic relevance. Our analysis reveals an Illusion of Success, demonstrating that many seemingly correct RAG outcomes are merely positional coincidences where the model's textual copying bias happens to align with the ground-truth location. To address these vulnerabilities, we propose Bottleneck Attention Intervention for Recovery (BAIR), a parameter-free, inference-time framework that restores visual saliency and applies position-aware penalties to textual distractors. Across medical factuality, social fairness, and geospatial benchmarks, BAIR successfully restores multimodal grounding and improves diagnostic reliability without requiring model retraining or fine-tuning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimodal LLMs in RAG settings exhibit 'recorruption,' where even perfectly accurate oracle context causes abandonment of initially correct predictions. It attributes this via mechanistic attention analysis to a two-fold collapse—visual blindness (suppressed M_vis and S_vis) and structural positional bias—and identifies an 'Illusion of Success' where correct outputs arise from positional coincidence aligning with copying bias. It proposes BAIR, a parameter-free inference-time intervention restoring visual saliency and applying position penalties, reporting improvements on medical factuality, social fairness, and geospatial benchmarks.
Significance. If the mechanistic account and causal efficacy of BAIR hold, the work would highlight under-appreciated instance-level failure modes in MLLM-RAG that evade standard metrics, while offering a practical, training-free mitigation. The attention-based diagnosis and identification of positional biases contribute to understanding transformer pathologies in multimodal settings; the parameter-free design and cross-domain benchmarks strengthen applicability to reliability-critical domains.
major comments (3)
- [Mechanistic diagnosis section] Mechanistic diagnosis section: the central claim that recorruption is 'driven by' the two-fold attentional collapse (visual blindness via suppressed M_vis/S_vis and positional bias) is supported only by observational before/after attention matrix comparisons after oracle insertion. No controlled causal test—such as targeted attention editing, head ablation, or isolation from FFN/value vector shifts—is reported to rule out alternative mechanisms.
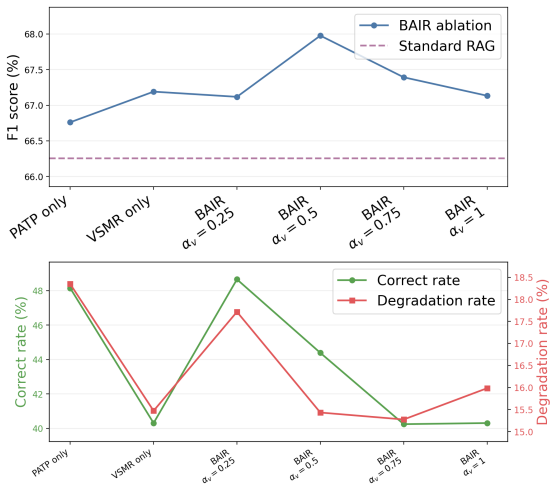
- [BAIR evaluation (Tables 1-3)] BAIR evaluation (Tables 1-3): while recovery is reported, the paper lacks a controlled ablation isolating the visual saliency restoration component from the position-penalty machinery, leaving open whether gains stem from the hypothesized mechanisms or unmeasured side effects on output distributions.
- [Benchmark results sections] Benchmark results sections: reported improvements lack error bars, number of runs, statistical significance tests, or explicit data exclusion rules, which is load-bearing for claims of diagnostic reliability gains across medical, fairness, and geospatial tasks.
minor comments (2)
- [Abstract and §1] Abstract and §1: the term 'recorruption' and 'BAIR' are used before full definition, which could be clarified with a brief inline gloss for accessibility.
- [Attention matrix figures] Attention matrix figures: axes, color scales for M_vis/S_vis, and token boundary annotations could be labeled more explicitly to aid interpretation of the collapse and bias effects.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important opportunities to strengthen the rigor of our mechanistic claims and experimental reporting. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Mechanistic diagnosis section] Mechanistic diagnosis section: the central claim that recorruption is 'driven by' the two-fold attentional collapse (visual blindness via suppressed M_vis/S_vis and positional bias) is supported only by observational before/after attention matrix comparisons after oracle insertion. No controlled causal test—such as targeted attention editing, head ablation, or isolation from FFN/value vector shifts—is reported to rule out alternative mechanisms.
Authors: We appreciate the referee's emphasis on establishing causality. Our current analysis is observational, relying on systematic before-and-after comparisons of attention matrices following oracle context insertion, which consistently reveal the described patterns of visual suppression and positional bias. While we did not include targeted interventions such as head ablation or attention editing in this work, the BAIR framework itself constitutes an inference-time intervention that directly modifies the identified attention components, with the resulting performance recovery providing indirect support for their causal role. In the revised manuscript, we will add an explicit limitations subsection acknowledging the observational nature of the diagnosis and outlining directions for future causal experiments (e.g., targeted editing) to further validate the mechanisms. revision: partial
-
Referee: [BAIR evaluation (Tables 1-3)] BAIR evaluation (Tables 1-3): while recovery is reported, the paper lacks a controlled ablation isolating the visual saliency restoration component from the position-penalty machinery, leaving open whether gains stem from the hypothesized mechanisms or unmeasured side effects on output distributions.
Authors: We agree that isolating the contributions of each BAIR component is essential for confirming the hypothesized mechanisms. In the revised manuscript, we will include a controlled ablation study that evaluates the visual saliency restoration and position-penalty components both separately and in combination. This will report their individual effects on the medical, fairness, and geospatial benchmarks, allowing readers to assess whether the observed gains derive from the intended attention interventions rather than unintended distributional shifts. revision: yes
-
Referee: [Benchmark results sections] Benchmark results sections: reported improvements lack error bars, number of runs, statistical significance tests, or explicit data exclusion rules, which is load-bearing for claims of diagnostic reliability gains across medical, fairness, and geospatial tasks.
Authors: We acknowledge the importance of statistical transparency for the reliability claims. We will revise the experimental sections to report error bars computed across multiple independent runs (specifying the exact number of runs and random seeds), include statistical significance tests (e.g., paired t-tests with p-values), and explicitly document all data exclusion criteria, preprocessing steps, and evaluation protocols. These additions will be integrated into Tables 1-3 and the corresponding result descriptions. revision: yes
Circularity Check
No circularity; empirical attention analysis and parameter-free intervention stand independent of inputs
full rationale
The paper identifies recorruption via direct mechanistic inspection of attention matrices before and after oracle context insertion, characterizing visual blindness and positional bias as observed patterns. BAIR is introduced as an inference-time, parameter-free intervention that restores saliency and applies penalties without any fitted parameters, self-citations, or derivations that reduce the claimed effects to the input observations by construction. No equations, uniqueness theorems, or ansatzes are invoked that would create self-definitional or load-bearing circular steps. The derivation chain remains self-contained empirical diagnosis plus independent mitigation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Changes in visual attention mass and sharpness directly cause the observed drop in prediction accuracy when context is added.
invented entities (2)
-
recorruption
no independent evidence
-
BAIR
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Z. Chen, M. Varma, J.-B. Delbrouck, M. Paschali, L. Blankemeier, D. Van Veen, J. M. J. Valanarasu, A. Youssef, J. P. Cohen, E. P. Reis, et al. Chexagent: Towards a foundation model for chest x-ray interpretation. InAAAI 2024 Spring Symposium on Clinical F oundation Models, 2024
2024
-
[3]
Cheng, J
G. Cheng, J. Han, and X. Lu. Remote sensing image scene classification: Benchmark and state of the art.Proceedings of the IEEE, 105(10):1865–1883, 2017
2017
-
[4]
Delbrouck, J
J.-B. Delbrouck, J. Xu, J. Moll, A. Thomas, Z. Chen, S. Ostmeier, A. Azhar, K. Z. Li, A. John- ston, C. Bluethgen, et al. Automated structured radiology report generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 26813–26829, 2025
2025
-
[5]
Demner-Fushman, M
D. Demner-Fushman, M. D. Kohli, M. B. Rosenman, S. E. Shooshan, L. Rodriguez, S. Antani, G. R. Thoma, and C. J. McDonald. Preparing a collection of radiology examinations for distribution and retrieval.Journal of the American Medical Informatics Association, 23(2): 304–310, 2015
2015
-
[6]
Elfwing, E
S. Elfwing, E. Uchibe, and K. Doya. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning.Neural networks, 107:3–11, 2018
2018
-
[7]
Gustafson, C
L. Gustafson, C. Rolland, N. Ravi, Q. Duval, A. Adcock, C.-Y . Fu, M. Hall, and C. Ross. Facet: Fairness in computer vision evaluation benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20370–20382, 2023
2023
-
[8]
Hsieh, Y .-S
C.-Y . Hsieh, Y .-S. Chuang, C.-L. Li, Z. Wang, L. Le, A. Kumar, J. Glass, A. Ratner, C.-Y . Lee, R. Krishna, et al. Found in the middle: Calibrating positional attention bias improves long context utilization. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14982–14995, 2024
2024
-
[9]
Jiang, Q
H. Jiang, Q. Wu, X. Luo, D. Li, C.-Y . Lin, Y . Yang, and L. Qiu. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1658–1677, 2024
2024
-
[10]
E. Kortukov, A. Rubinstein, E. Nguyen, and S. J. Oh. Studying large language model behaviors under context-memory conflicts with real documents.arXiv preprint arXiv:2404.16032, 2024
-
[11]
Lewis, E
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[12]
C.-Y . Lin. Rouge: A package for automatic evaluation of summaries. InText summarization branches out, pages 74–81, 2004
2004
-
[13]
F. Liu, D. Chen, Z. Guan, X. Zhou, J. Zhu, Q. Ye, L. Fu, and J. Zhou. Remoteclip: A vision language foundation model for remote sensing.IEEE Transactions on Geoscience and Remote Sensing, 62:1–16, 2024
2024
-
[14]
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024. 10
2024
-
[15]
H. Lu, W. Liu, B. Zhang, B. Wang, K. Dong, B. Liu, J. Sun, T. Ren, Z. Li, H. Yang, et al. Deepseek-vl: towards real-world vision-language understanding.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review arXiv 2024
- [16]
-
[17]
M. K. Mandanetwork, H. E. Rekik, and O. Bouaziz. Enhancing technical knowledge acquisition with rag systems: the tei use case. InTexts, Languages and Communities-TEI 2024, 2024
2024
-
[18]
Marino, M
K. Marino, M. Rastegari, A. Farhadi, and R. Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of the IEEE/cvf conference on computer vision and pattern recognition, pages 3195–3204, 2019
2019
-
[19]
M. Raja, E. Yuvaraajan, et al. A rag-based medical assistant especially for infectious diseases. In2024 International Conference on Inventive Computation Technologies (ICICT), pages 1128–1133. IEEE, 2024
2024
-
[20]
A. Sellergren, S. Kazemzadeh, T. Jaroensri, A. Kiraly, M. Traverse, T. Kohlberger, S. Xu, F. Jamil, C. Hughes, C. Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
S. Soni, A. Dudhane, H. Debary, M. Fiaz, M. A. Munir, M. S. Danish, P. Fraccaro, C. D. Watson, L. J. Klein, F. S. Khan, et al. Earthdial: Turning multi-sensory earth observations to interactive dialogues. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14303–14313, 2025
2025
-
[22]
H. Wadhwa, R. Seetharaman, S. Aggarwal, R. Ghosh, S. Basu, S. Srinivasan, W. Zhao, S. Chaudhari, and E. Aghazadeh. From rags to rich parameters: Probing how language models utilize external knowledge over parametric information for factual queries.arXiv preprint arXiv:2406.12824, 2024
-
[23]
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin. Qwen2-vl: En- hancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review arXiv 2024
-
[24]
Z. Wang, H. Zhang, X. Li, K.-H. Huang, C. Han, S. Ji, S. M. Kakade, H. Peng, and H. Ji. Eliminating position bias of language models: A mechanistic approach. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=fvkElsJOsN
2025
-
[25]
Wiratunga, R
N. Wiratunga, R. Abeyratne, L. Jayawardena, K. Martin, S. Massie, I. Nkisi-Orji, R. Weeras- inghe, A. Liret, and B. Fleisch. Cbr-rag: case-based reasoning for retrieval augmented generation in llms for legal question answering. InInternational Conference on Case-Based Reasoning, pages 445–460. Springer, 2024
2024
-
[26]
X. Wu, Y . Wang, S. Jegelka, and A. Jadbabaie. On the emergence of position bias in transformers. In A. Singh, M. Fazel, D. Hsu, S. Lacoste-Julien, F. Berkenkamp, T. Maharaj, K. Wagstaff, and J. Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 67756–67781. PMLR,...
2025
- [27]
-
[28]
Zhang, R
Z. Zhang, R. Chen, S. Liu, Z. Yao, O. Ruwase, B. Chen, X. Wu, and Z. Wang. Found in the middle: How language models use long contexts better via plug-and-play positional encoding. Advances in Neural Information Processing Systems, 37:60755–60775, 2024
2024
-
[29]
B. Zhao, W. Deng, X. Liao, Y . Li, N. Shaikh, Y . Nie, and X. Li. When rag hurts: Diagnosing and mitigating attention distraction in retrieval-augmented lvlms.arXiv preprint arXiv:2602.00344, 2026. 11 A Derivation of the Mass Restoration Shift We seek a global scalar shift α to be added to the sharpened visual logits ˜Ev ∈R Nv such that the post-softmax v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.