Recognition: unknown
Towards Compute-Aware In-Switch Computing for LLMs Tensor-Parallelism on Multi-GPU Systems
Pith reviewed 2026-05-08 04:37 UTC · model grok-4.3
The pith
CAIS aligns in-switch communication with LLM computation memory needs to accelerate tensor parallelism on multi-GPU systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
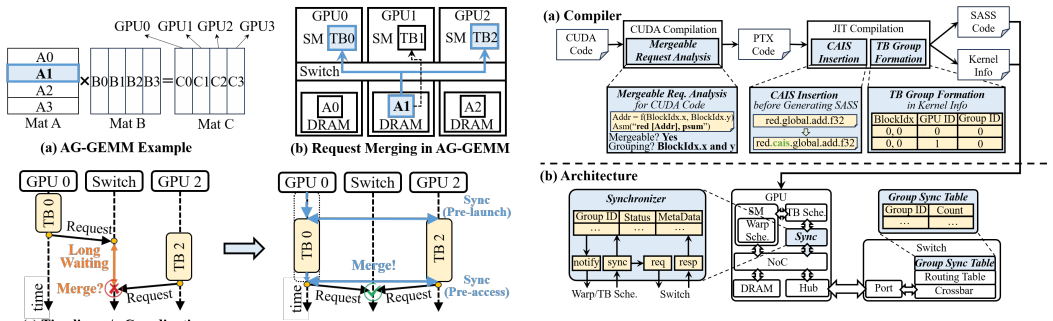
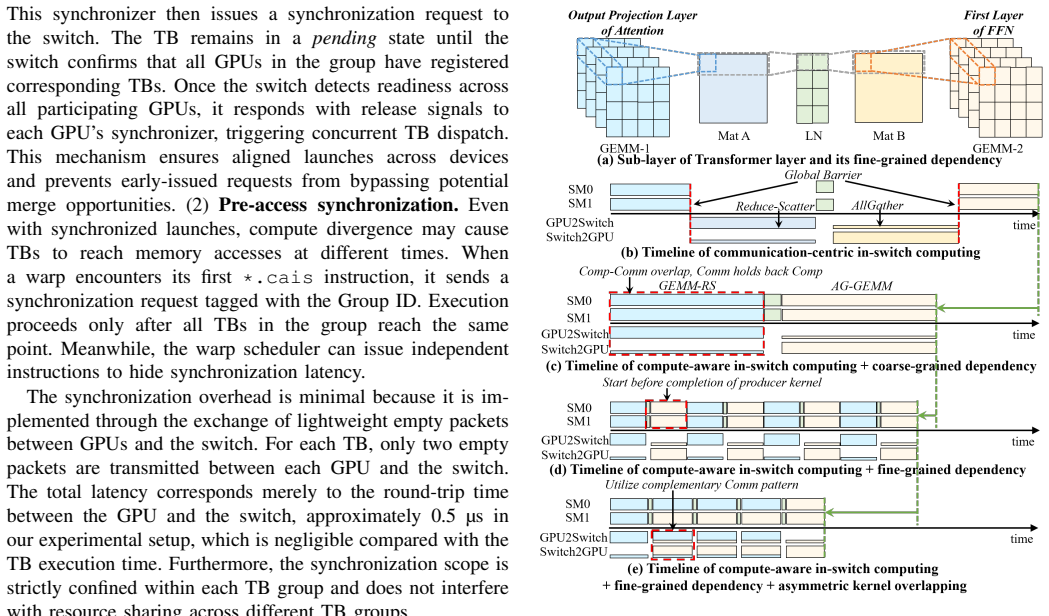
CAIS is the first compute-aware in-switch computing framework for tensor-parallel LLM workloads. It consists of a compute-aware ISA and microarchitecture to match communication modes to computation memory semantics, merging-aware thread block coordination to improve temporal alignment, and a graph-level dataflow optimizer for cross-kernel overlap. This design overcomes the phase isolation in prior approaches and yields the reported performance improvements on multi-GPU systems.
What carries the argument
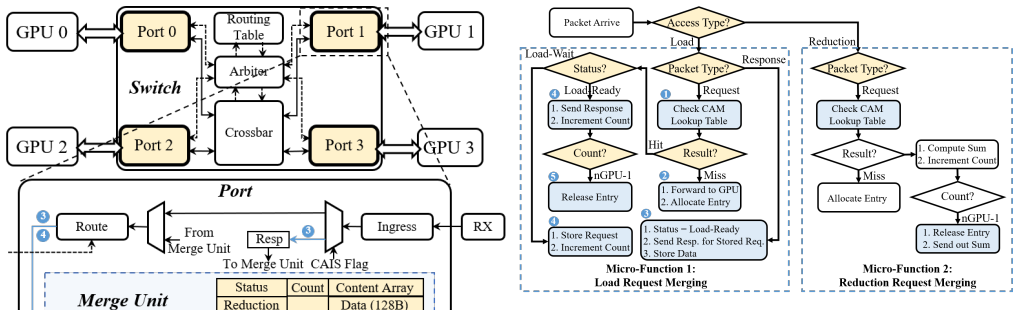
Compute-aware ISA and microarchitecture extension that allows the switch to perform operations aligned with the memory semantics of LLM computation kernels rather than pure communication reduction.
If this is right
- Tensor parallel training on multi-GPU systems can overlap compute and communication phases more effectively, reducing overall execution time.
- Collective operations in LLM workloads benefit from reduced redundant transfers while maintaining compatibility with computation requirements.
- End-to-end training throughput increases without requiring changes to the underlying LLM model structure.
Where Pith is reading between the lines
- Hardware vendors could incorporate similar compute extensions into future network switches to support emerging AI workloads better.
- The merging-aware coordination technique might apply to other distributed computing scenarios beyond LLMs.
- Further optimizations could explore dynamic adaptation of the dataflow based on workload characteristics.
Load-bearing premise
The compute-aware ISA and microarchitecture extensions can be implemented in production switches while keeping area, power, and compatibility costs acceptable and without introducing new performance bottlenecks.
What would settle it
Implementation measurements on actual or simulated switch hardware showing that the area or power overhead of the extensions exceeds practical limits for commercial deployment, or that the end-to-end speedups are not realized due to introduced bottlenecks.
Figures












read the original abstract
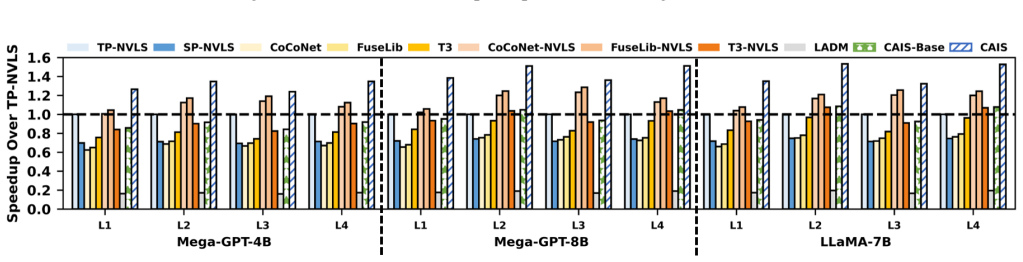
Tensor parallelism (TP) in large-scale LLM inference and training introduces frequent collective operations that dominate inter-GPU communication. While in-switch computing, exemplified by NVLink SHARP (NVLS), accelerates collective operations by reducing redundant data transfer, its communication-centric design philosophy introduces the mismatch between its communication mode and the memory semantic requirement of LLM's computation kernel. Such a mismatch isolates the compute and communication phases, resulting in underutilized resources and limited overlap in multi-GPU systems. To address the limitation, we propose CAIS, the first Compute-Aware In-Switch computing framework that aligns communication modes with computation's memory semantics requirement. CAIS consists of three integral techniques: (1) compute-aware ISA and microarchitecture extension to enable compute-aware in-switch computing. (2) merging-aware TB (Thread Block) coordination to improve the temporal alignment for efficient request merging. (3) graph-level dataflow optimizer to achieve a tight cross-kernel overlap. Evaluations on LLM workloads show that CAIS achieves 1.38$\times$ average end-to-end training speedup over the SOTA NVLS-enabled solution, and 1.61$\times$ over T3, the SOTA compute-communicate overlap solutions but do not leverage NVLS, demonstrating its effectiveness in accelerating TP on multi-GPU systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAIS, the first Compute-Aware In-Switch computing framework for tensor parallelism (TP) in LLM training/inference on multi-GPU systems. It identifies a mismatch between communication-centric in-switch designs like NVLink SHARP (NVLS) and LLM kernel memory semantics, which limits compute-communicate overlap. CAIS introduces three techniques: (1) compute-aware ISA and microarchitecture extensions, (2) merging-aware thread-block coordination for request merging, and (3) a graph-level dataflow optimizer for cross-kernel overlap. Evaluations claim 1.38× average end-to-end training speedup over SOTA NVLS-enabled solutions and 1.61× over T3 (SOTA overlap without NVLS).
Significance. If the hardware extensions prove feasible without eroding gains, CAIS could meaningfully improve TP efficiency in large-scale LLM systems by enabling tighter compute-communicate alignment beyond current NVLS capabilities. The work provides a concrete hardware-software co-design path that builds directly on deployed in-switch fabrics, with potential for broader impact on distributed training throughput if the reported speedups hold under realistic constraints.
major comments (2)
- [Proposed Techniques / Microarchitecture Extensions] The central speedup claims (1.38× over NVLS, 1.61× over T3) rest on the assumption that the compute-aware ISA and microarchitecture extensions can be realized in production switches without unacceptable area, power, or per-packet latency overhead. No synthesis results, power estimates, or compatibility analysis with NVLink/NVLS fabrics are provided to quantify this; any added latency would directly undermine the overlap benefits asserted in the abstract and evaluation.
- [Evaluation] The evaluation section reports end-to-end speedups but supplies no details on experimental methodology, including LLM model sizes, number of GPUs, exact baseline implementations (e.g., how NVLS and T3 were configured), error bars, or ablation studies isolating each of the three techniques. This makes it impossible to assess whether the measurements support the central claim.
minor comments (2)
- [§3.1] Notation for the compute-aware ISA instructions is introduced without a clear table or diagram showing opcode semantics and how they map to existing NVLS collectives.
- [Abstract / Introduction] The abstract and introduction use 'SOTA' without citing the specific prior works for T3 and NVLS-enabled baselines in the first paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Proposed Techniques / Microarchitecture Extensions] The central speedup claims (1.38× over NVLS, 1.61× over T3) rest on the assumption that the compute-aware ISA and microarchitecture extensions can be realized in production switches without unacceptable area, power, or per-packet latency overhead. No synthesis results, power estimates, or compatibility analysis with NVLink/NVLS fabrics are provided to quantify this; any added latency would directly undermine the overlap benefits asserted in the abstract and evaluation.
Authors: We agree that the manuscript currently lacks quantitative hardware overhead analysis for the proposed compute-aware ISA and microarchitecture extensions. The design philosophy extends the programmable in-switch capabilities already deployed in NVLS rather than introducing entirely new hardware blocks, with the goal of preserving low per-packet latency through the merging-aware thread-block coordination. However, without explicit synthesis or power data, the overhead claims remain unquantified. In the revised manuscript we will add a new subsection presenting preliminary RTL synthesis results, area and power estimates, and a compatibility discussion with NVLink/NVLS fabrics. This addition will directly address whether any incremental latency could offset the reported overlap gains. revision: yes
-
Referee: [Evaluation] The evaluation section reports end-to-end speedups but supplies no details on experimental methodology, including LLM model sizes, number of GPUs, exact baseline implementations (e.g., how NVLS and T3 were configured), error bars, or ablation studies isolating each of the three techniques. This makes it impossible to assess whether the measurements support the central claim.
Authors: The referee correctly identifies that the evaluation section omits key methodological details. The reported speedups were obtained on standard LLM training workloads using multiple GPU counts, with NVLS enabled via the latest vendor libraries and T3 re-implemented from its original description. Nevertheless, these specifics, along with error bars and per-technique ablations, are not adequately documented. We will revise the evaluation section to include model sizes and configurations, exact GPU counts, baseline implementation details, standard-deviation error bars across repeated runs, and ablation studies that isolate the contribution of the ISA extensions, thread-block coordination, and graph-level optimizer. These additions will allow readers to evaluate the strength of the 1.38× and 1.61× claims. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external baselines
full rationale
The paper proposes CAIS with three techniques (compute-aware ISA/microarchitecture, merging-aware TB coordination, graph-level dataflow optimizer) and reports speedups from direct end-to-end evaluations on LLM workloads against external SOTA systems (NVLS-enabled solution and T3). No equations, parameter fittings, or derivations are shown that reduce to the paper's own inputs by construction. No load-bearing self-citations or uniqueness theorems imported from prior author work appear in the derivation chain. The performance numbers are presented as measured outcomes rather than tautological predictions, making the analysis self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Collective operations dominate inter-GPU communication time in tensor-parallel LLM training and inference.
invented entities (1)
-
CAIS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Blockmaestro: Enabling programmer- transparent task-based execution in gpu systems,
A. Abdolrashidi, H. A. Esfeden, A. Jahanshahi, K. Singh, N. Abu- Ghazaleh, and D. Wong, “Blockmaestro: Enabling programmer- transparent task-based execution in gpu systems,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 333–346
2021
-
[2]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Mcm-gpu: Multi-chip-module gpus for continued performance scalability,
A. Arunkumar, E. Bolotin, B. Cho, U. Milic, E. Ebrahimi, O. Villa, A. Jaleel, C.-J. Wu, and D. Nellans, “Mcm-gpu: Multi-chip-module gpus for continued performance scalability,”ACM SIGARCH Computer Architecture News, vol. 45, no. 2, pp. 320–332, 2017
2017
-
[4]
Cen- tauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning,
C. Chen, X. Li, Q. Zhu, J. Duan, P. Sun, X. Zhang, and C. Yang, “Cen- tauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning,” in Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2024, pp. 178–191
2024
-
[5]
Flare: Flexible in-network allreduce,
D. De Sensi, S. Di Girolamo, S. Ashkboos, S. Li, and T. Hoefler, “Flare: Flexible in-network allreduce,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–16
2021
-
[6]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[7]
The llama 3 herd of models,
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fanet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[8]
Efficient sparse collective communication and its application to accelerate distributed deep learning,
J. Fei, C.-Y . Ho, A. N. Sahu, M. Canini, and A. Sapio, “Efficient sparse collective communication and its application to accelerate distributed deep learning,” inProceedings of the 2021 ACM SIGCOMM 2021 Conference, 2021, pp. 676–691
2021
-
[9]
Ultra-performance pascal gpu and nvlink interconnect,
D. Foley and J. Danskin, “Ultra-performance pascal gpu and nvlink interconnect,”IEEE Micro, vol. 37, no. 2, pp. 7–17, 2017
2017
-
[10]
In-network aggregation for shared machine learning clus- ters,
N. Gebara, “In-network aggregation for shared machine learning clus- ters,”Proceedings of Machine Learning and Systems (MLSys), 2021
2021
-
[11]
Scal- able hierarchical aggregation protocol (sharp): A hardware architecture for efficient data reduction,
R. L. Graham, D. Bureddy, P. Lui, H. Rosenstock, G. Shainer, G. Bloch, D. Goldenerg, M. Dubman, S. Kotchubievsky, V . Koushniret al., “Scal- able hierarchical aggregation protocol (sharp): A hardware architecture for efficient data reduction,” in2016 First International Workshop on Communication Optimizations in HPC (COMHPC). IEEE, 2016, pp. 1–10
2016
-
[12]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Flash: Fpga-accelerated smart switches with gcn case study,
P. Haghi, W. Krska, C. Tan, T. Geng, P. H. Chen, C. Greenwood, A. Guo, T. Hines, C. Wu, A. Liet al., “Flash: Fpga-accelerated smart switches with gcn case study,” inProceedings of the 37th International Conference on Supercomputing, 2023, pp. 450–462
2023
-
[14]
Smartfuse: Reconfigurable smart switches to accelerate fused collectives in hpc applications,
P. Haghi, C. Tan, A. Guo, C. Wu, D. Liu, A. Li, A. Skjellum, T. Geng, and M. Herbordt, “Smartfuse: Reconfigurable smart switches to accelerate fused collectives in hpc applications,” inProceedings of the 38th ACM International Conference on Supercomputing, 2024, pp. 413–425
2024
-
[15]
A generic service to provide in-network aggregation for key-value streams,
Y . He, W. Wu, Y . Le, M. Liu, and C. Lao, “A generic service to provide in-network aggregation for key-value streams,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2023, pp. 33–47
2023
-
[16]
Gpipe: Efficient training of giant neu- ral networks using pipeline parallelism,
Y . Huang, Y . Cheng, A. Bapna, O. Firat, D. Chen, M. Chen, H. Lee, J. Ngiam, Q. V . Le, Y . Wuet al., “Gpipe: Efficient training of giant neu- ral networks using pipeline parallelism,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[17]
Nvswitch and dgx-2,
A. Ishii, D. Foley, E. Anderson, B. Dally, G. Dearth, L. Dennison, M. Hummel, and J. Schafer, “Nvswitch and dgx-2,” inHot Chips, 2018
2018
-
[18]
Pal: A variability-aware policy for scheduling ml workloads in gpu clusters,
R. Jain, B. Tran, K. Chen, M. D. Sinclair, and S. Venkataraman, “Pal: A variability-aware policy for scheduling ml workloads in gpu clusters,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–18
2024
-
[19]
Breaking the com- putation and communication abstraction barrier in distributed machine learning workloads,
A. Jangda, J. Huang, G. Liu, A. H. N. Sabet, S. Maleki, Y . Miao, M. Musuvathi, T. Mytkowicz, and O. Saarikivi, “Breaking the com- putation and communication abstraction barrier in distributed machine learning workloads,” inProceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, 2022, ...
2022
-
[20]
A detailed and flexible cycle-accurate network-on-chip simulator,
N. Jiang, D. U. Becker, G. Michelogiannakis, J. Balfour, B. Towles, D. E. Shaw, J. Kim, and W. J. Dally, “A detailed and flexible cycle-accurate network-on-chip simulator,” in2013 IEEE international symposium on performance analysis of systems and software (ISPASS). IEEE, 2013, pp. 86–96
2013
-
[21]
Netcache: Balancing key-value stores with fast in-network caching,
X. Jin, X. Li, H. Zhang, R. Soul ´e, J. Lee, N. Foster, C. Kim, and I. Stoica, “Netcache: Balancing key-value stores with fast in-network caching,” in Proceedings of the 26th Symposium on Operating Systems Principles, 2017, pp. 121–136
2017
-
[22]
Locality- centric data and threadblock management for massive gpus,
M. Khairy, V . Nikiforov, D. Nellans, and T. G. Rogers, “Locality- centric data and threadblock management for massive gpus,” in2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2020, pp. 1022–1036
2020
-
[23]
Accel-sim: An extensible simulation framework for validated gpu modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-sim: An extensible simulation framework for validated gpu modeling,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 473–486
2020
-
[24]
An in-network architecture for accelerating shared-memory multiprocessor collectives,
B. Klenk, N. Jiang, G. Thorson, and L. Dennison, “An in-network architecture for accelerating shared-memory multiprocessor collectives,” in2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020, pp. 996–1009
2020
-
[25]
Reducing activation recomputation in large transformer models,
V . A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,”Proceedings of Machine Learning and Systems, vol. 5, pp. 341–353, 2023
2023
-
[26]
{ATP}: In-network aggregation for multi-tenant learning,
C. Lao, Y . Le, K. Mahajan, Y . Chen, W. Wu, A. Akella, and M. Swift, “{ATP}: In-network aggregation for multi-tenant learning,” in18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), 2021, pp. 741–761
2021
-
[27]
Sequence paral- lelism: Long sequence training from system perspective
S. Li, F. Xue, C. Baranwal, Y . Li, and Y . You, “Sequence paral- lelism: Long sequence training from system perspective,”arXiv preprint arXiv:2105.13120, 2021
-
[28]
Chimera: efficiently training large-scale neural net- works with bidirectional pipelines,
S. Li and T. Hoefler, “Chimera: efficiently training large-scale neural net- works with bidirectional pipelines,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–14
2021
-
[29]
Accel- erating distributed reinforcement learning with in-switch computing,
Y . Li, I.-J. Liu, Y . Yuan, D. Chen, A. Schwing, and J. Huang, “Accel- erating distributed reinforcement learning with in-switch computing,” inProceedings of the 46th International Symposium on Computer Architecture, 2019, pp. 279–291
2019
-
[30]
Ub-mesh: An new interconnection technology for large ai supernode,
H. Liao, “Ub-mesh: An new interconnection technology for large ai supernode,” in2025 IEEE Hot Chips 37 Symposium (HCS). IEEE Computer Society, 2025, pp. 1–13
2025
-
[31]
Incbricks: Toward in-network computation with an in-network cache,
M. Liu, L. Luo, J. Nelson, L. Ceze, A. Krishnamurthy, and K. Atreya, “Incbricks: Toward in-network computation with an in-network cache,” inProceedings of the Twenty-Second International Conference on Archi- tectural Support for Programming Languages and Operating Systems, 2017, pp. 795–809
2017
-
[32]
In-network aggregation with transport transparency for distributed training,
S. Liu, Q. Wang, J. Zhang, W. Wu, Q. Lin, Y . Liu, M. Xu, M. Canini, R. C. Cheung, and J. He, “In-network aggregation with transport transparency for distributed training,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, 2023, pp. 376–391
2023
-
[33]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022
2021
-
[34]
Beyond the socket: Numa-aware gpus,
U. Milic, O. Villa, E. Bolotin, A. Arunkumar, E. Ebrahimi, A. Jaleel, A. Ramirez, and D. Nellans, “Beyond the socket: Numa-aware gpus,” inProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, 2017, pp. 123–135
2017
-
[35]
Efficient large-scale language model training on gpu clusters using megatron-lm,
D. Narayanan, M. Shoeybi, J. Casper, P. LeGresley, M. Patwary, V . Korthikanti, D. Vainbrand, P. Kashinkunti, J. Bernauer, B. Catanzaro et al., “Efficient large-scale language model training on gpu clusters using megatron-lm,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2021, pp. 1–15
2021
-
[36]
Nvidia h100 tensor core gpu
NVIDIA, “Nvidia h100 tensor core gpu.”https://www.nvidia.com/en- us/data-center/h100, 2022
2022
-
[37]
Upgrading multi-gpu interconnectiv- ity with the third-generation nvidia nvswitch
NVIDIA, “Upgrading multi-gpu interconnectiv- ity with the third-generation nvidia nvswitch.” https://developer.nvidia.com/blog/upgrading-multi-gpu- interconnectivity-with-the-third-generation-nvidia-nvswitch/?ncid=so- nvsh-708451, 2022
2022
-
[38]
Cuda templates for linear algebra subroutines
NVIDIA, “Cuda templates for linear algebra subroutines.” https://github.com/NVIDIA/cutlass, 2024
2024
-
[39]
Introduction to nvidia dgx h100/h200 systems
NVIDIA, “Introduction to nvidia dgx h100/h200 systems.” https://docs.nvidia.com/dgx/dgxh100-user-guide/introduction-to- dgxh100.html, 2024
2024
-
[40]
Nvidia collective communication library (nccl) documentation
NVIDIA, “Nvidia collective communication library (nccl) documentation.”https://docs.nvidia.com/deeplearning/nccl/user- guide/docs/index.html, 2024
2024
-
[41]
Nvidia gb200 nvl72
NVIDIA, “Nvidia gb200 nvl72.”https://www.nvidia.com/en-us/data- center/gb200-nvl72/, 2024
2024
-
[42]
Cuda: New features and beyond
NVIDIA, “Cuda: New features and beyond.”https://www.nvidia.com/en- us/on-demand/session/gtc25-s72383/, 2025
2025
-
[43]
T3: Transparent tracking & triggering for fine-grained overlap of compute & collectives,
S. Pati, S. Aga, M. Islam, N. Jayasena, and M. D. Sinclair, “T3: Transparent tracking & triggering for fine-grained overlap of compute & collectives,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2024, pp. 1146–1164
2024
-
[44]
Optimiz- ing distributed ml communication with fused computation-collective operations,
K. Punniyamurthy, K. Hamidouche, and B. M. Beckmann, “Optimiz- ing distributed ml communication with fused computation-collective operations,” inSC24: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2024, pp. 1–17
2024
-
[45]
Zero: Memory optimizations toward training trillion parameter models,
S. Rajbhandari, J. Rasley, O. Ruwase, and Y . He, “Zero: Memory optimizations toward training trillion parameter models,” inSC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020, pp. 1–16
2020
-
[46]
Enabling compute-communication overlap in distributed deep learning training platforms,
S. Rashidi, M. Denton, S. Sridharan, S. Srinivasan, A. Suresh, J. Nie, and T. Krishna, “Enabling compute-communication overlap in distributed deep learning training platforms,” in2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 540–553
2021
-
[47]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,
J. Rasley, S. Rajbhandari, O. Ruwase, and Y . He, “Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters,” inProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining, 2020, pp. 3505– 3506
2020
-
[48]
Scaling distributed machine learning with{In-Network}aggregation,
A. Sapio, M. Canini, C.-Y . Ho, J. Nelson, P. Kalnis, C. Kim, A. Krish- namurthy, M. Moshref, D. Ports, and P. Richt ´arik, “Scaling distributed machine learning with{In-Network}aggregation,” in18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), 2021, pp. 785–808
2021
-
[49]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catan- zaro, “Megatron-lm: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[50]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[51]
Roar: A router microarchitecture for in-network allreduce,
R. Wang, D. Dong, F. Lei, J. Ma, K. Wu, and K. Lu, “Roar: A router microarchitecture for in-network allreduce,” inProceedings of the 37th International Conference on Supercomputing, 2023, pp. 423–436
2023
-
[52]
Overlap communication with dependent computation via decomposition in large deep learning models,
S. Wang, J. Wei, A. Sabne, A. Davis, B. Ilbeyi, B. Hechtman, D. Chen, K. S. Murthy, M. Maggioni, Q. Zhanget al., “Overlap communication with dependent computation via decomposition in large deep learning models,” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, 2022,...
2022
-
[53]
Using trio: juniper networks’ programmable chipset-for emerging in-network applications,
M. Yang, A. Baban, V . Kugel, J. Libby, S. Mackie, S. S. R. Kananda, C.- H. Wu, and M. Ghobadi, “Using trio: juniper networks’ programmable chipset-for emerging in-network applications,” inProceedings of the ACM SIGCOMM 2022 Conference, 2022, pp. 633–648
2022
-
[54]
Unlocking the power of inline{Floating-Point} operations on programmable switches,
Y . Yuan, O. Alama, J. Fei, J. Nelson, D. R. Ports, A. Sapio, M. Canini, and N. S. Kim, “Unlocking the power of inline{Floating-Point} operations on programmable switches,” in19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), 2022, pp. 683–700
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.