Recognition: unknown
Spectral Lens: Activation and Gradient Spectra as Diagnostics of LLM Optimization
Pith reviewed 2026-05-08 05:37 UTC · model grok-4.3
The pith
Early activation covariance spectra forecast token efficiency in language model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
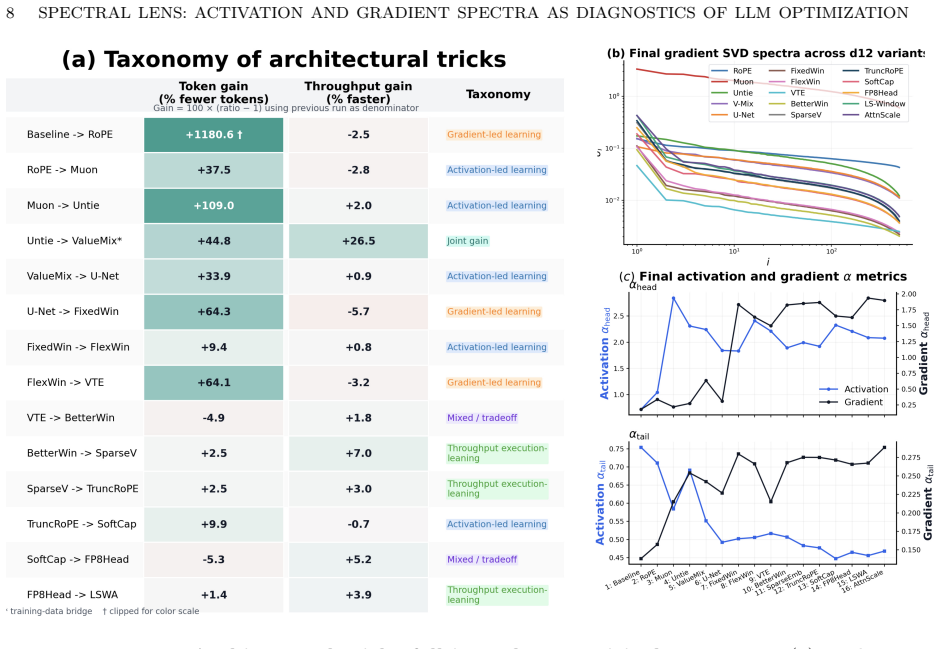
Using activation covariance and per-sample gradient SVD spectra as diagnostics on decoder-only models, the work finds that batch size shapes representation geometry at equal loss, that early activation tails forecast token efficiency, and that spectral head movement separates learning dynamics. A mechanistic model explains the correlation between activation spectra and task-aligned feature learning.
What carries the argument
Activation covariance spectra and per-sample gradient SVD spectra, which diagnose representation geometry and learning dynamics.
If this is right
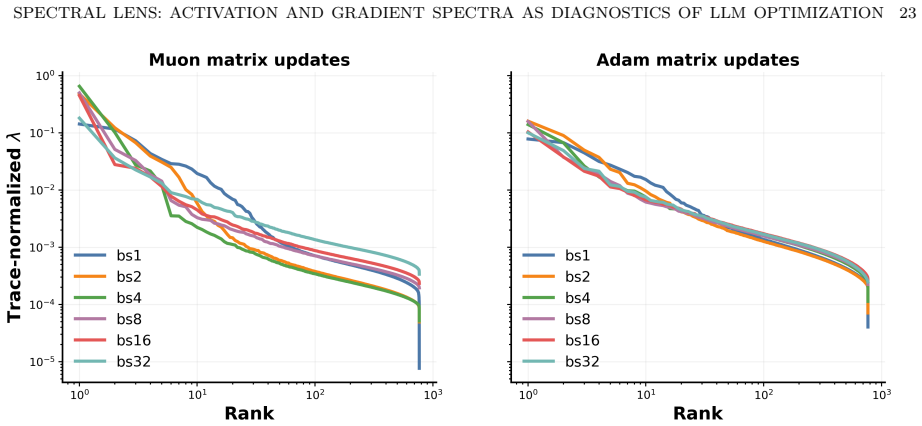
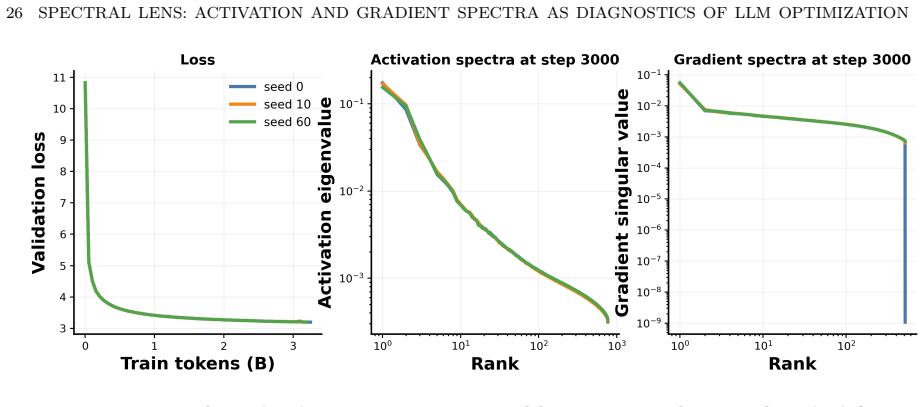
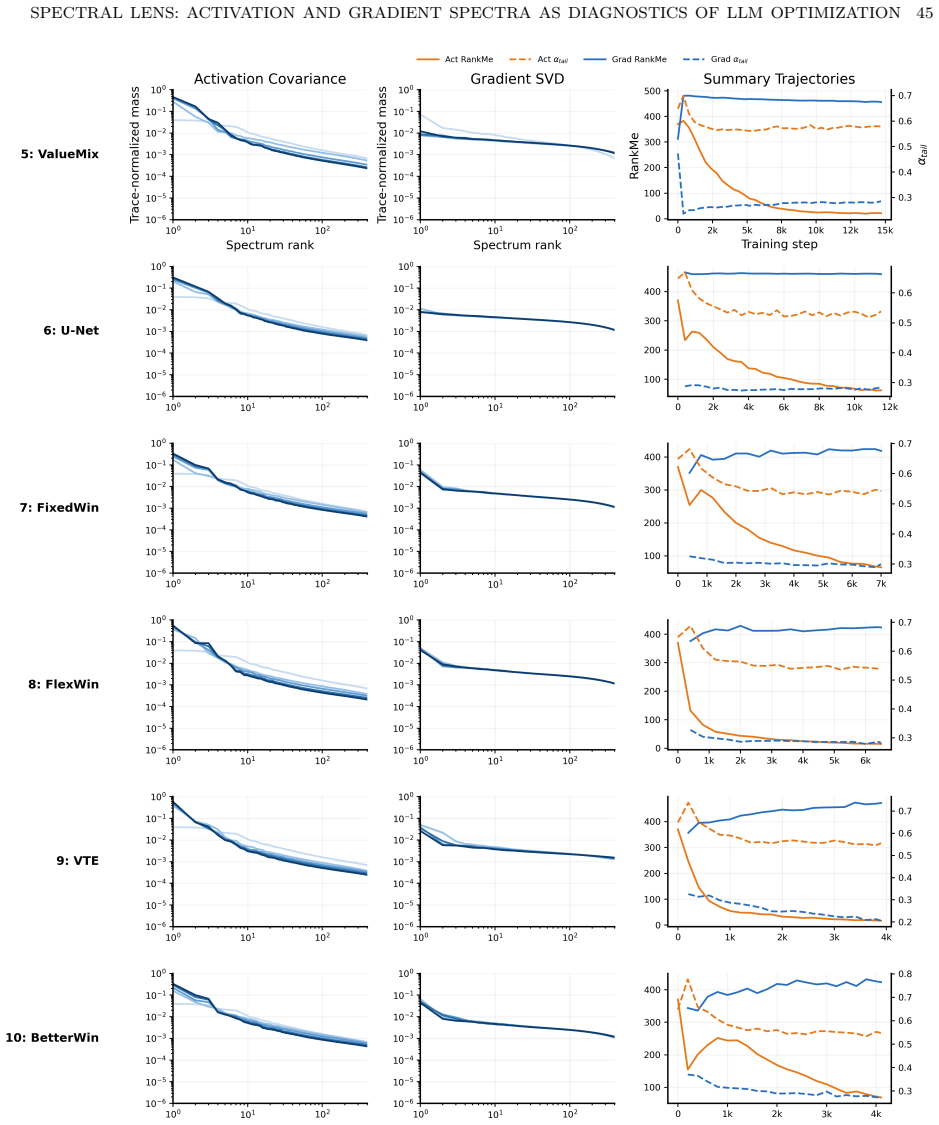
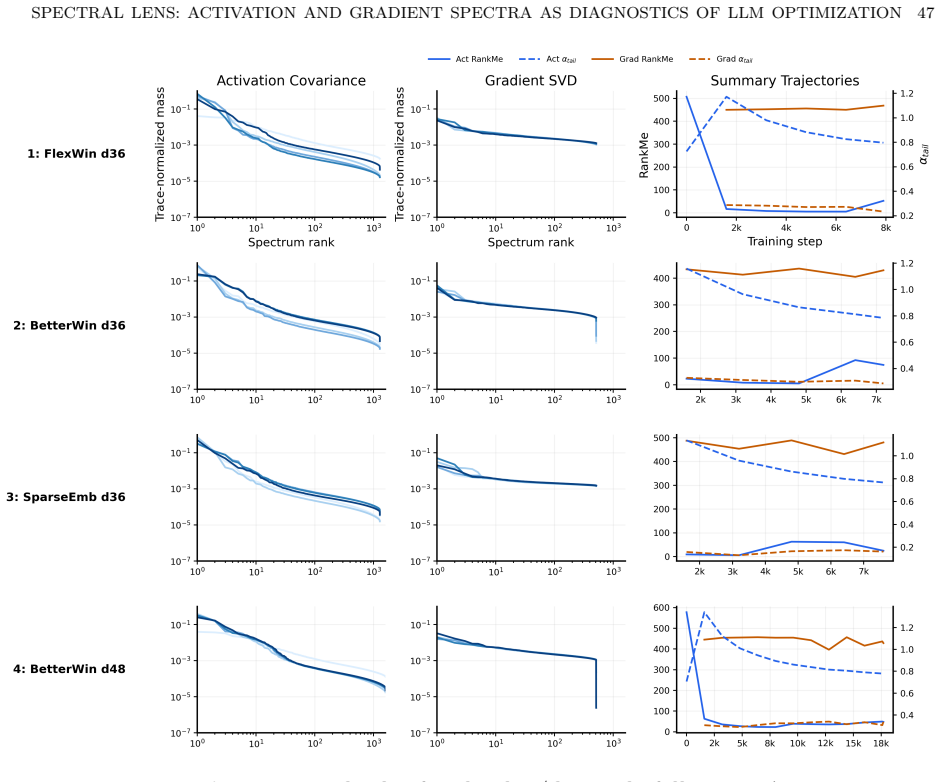
- Runs reaching the same loss can have different activation spectra depending on batch size.
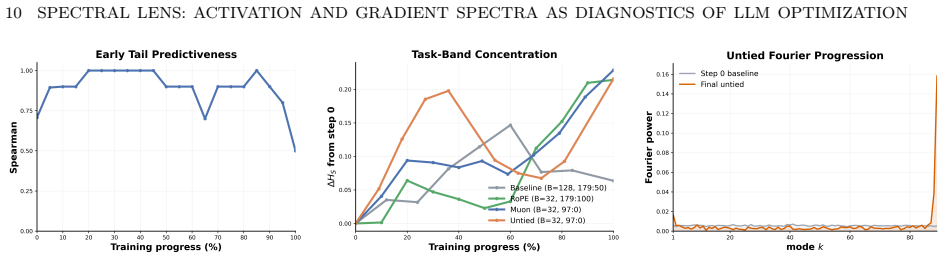
- Early activation covariance tail predicts downstream token efficiency.
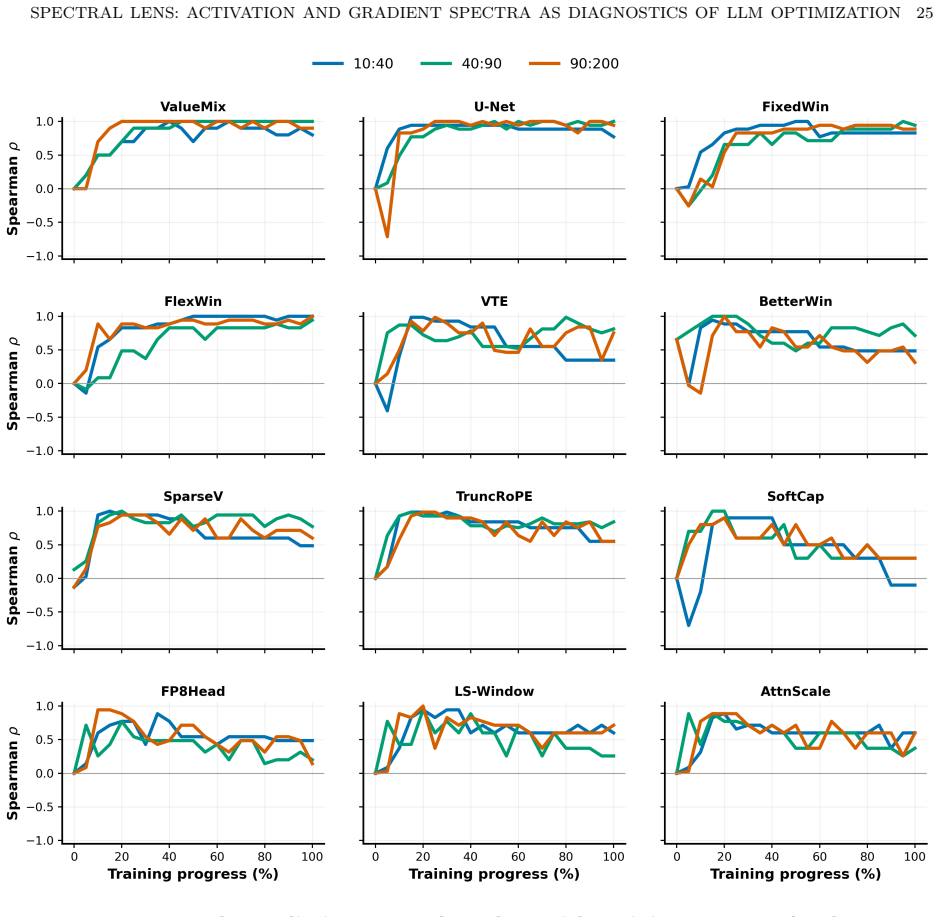
- Spectral changes characterize shifts in learning dynamics, distinguishing architectural from execution improvements.
- These patterns persist in 12-, 36-, and 48-layer models.
Where Pith is reading between the lines
- Monitoring these spectra could allow early intervention in training to improve efficiency without completing full runs.
- The mechanistic model might extend to other architectures if the correlation with feature learning generalizes beyond the tested scales.
- Spectral diagnostics could inform hyperparameter choices like batch size to optimize representation learning directly.
Load-bearing premise
The spectral patterns observed in this family of decoder-only models reflect general properties of language model optimization rather than being specific to the chosen implementation or scales.
What would settle it
A new experiment where the early activation covariance tail does not correlate with final token efficiency on a different model family or larger scale would falsify the predictive claim.
Figures











read the original abstract
Training loss and throughput can hide distinct internal representation in language-model training. To examine these hidden mechanics, we use spectral measurements as practical and operational diagnostics. Using a controlled family of decoder-only models adapted from the modded NanoGPT codebase, we introduce an empirical protocol based on activation covariance and per-sample gradient SVD spectra. This dual-view reveals three empirical findings and one mechanistic explanation. First, batch size acts as a latent determinant of representation geometry: runs that reach equal loss settle into systematically distinct activation spectra. Second, the activation covariance tail measured early in training reliably forecasts downstream token efficiency. Third, movement of the activation spectrum head (leading modes), together with gradient spectra, characterizes underlying learning-dynamics changes, separating learning-side architectural improvements from primarily execution-side gains. These predictive and diagnostic signals persist across the 12-, 36-, and 48-layer model tiers. Finally, a mechanistic model proves the main observations and explains how activation covariance spectra correlate with task-aligned feature learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes spectral diagnostics based on activation covariance spectra and per-sample gradient SVD spectra to probe internal representation geometry and learning dynamics during LLM training, beyond what loss and throughput reveal. Using a controlled family of decoder-only transformer models (12-48 layers) adapted from the modded NanoGPT codebase, it reports three empirical findings: (1) batch size systematically shapes activation spectra even among runs that reach identical final loss; (2) the tail of the early-training activation covariance spectrum reliably predicts downstream token efficiency; (3) movement of the leading spectral modes together with gradient spectra distinguishes learning-side architectural gains from execution-side improvements. A mechanistic model is presented as proving these observations by linking activation covariance spectra to task-aligned feature learning. The signals are claimed to hold across the tested model depths.
Significance. If the empirical patterns and the mechanistic account are robust, the work supplies concrete, low-overhead diagnostics that could guide hyperparameter selection and architecture decisions earlier in training. The forecasting claim for token efficiency and the separation of learning versus execution dynamics would be practically valuable for large-scale training. The paper's use of a single controlled model family allows clean isolation of batch-size and depth effects, which is a methodological strength.
major comments (3)
- [Abstract] Abstract: the claim that 'a mechanistic model proves the main observations' is load-bearing for the paper's explanatory contribution, yet the abstract (and the provided manuscript excerpt) supplies no equations, assumptions, or derivation steps for this model. Without these details it is impossible to assess whether the model supplies independent grounding or merely restates the observed spectral correlations.
- [Abstract] Abstract and experimental description: all reported results, including the forecasting reliability of the activation covariance tail and the persistence across depths, are obtained exclusively on decoder-only models adapted from a single NanoGPT codebase variant. The central claim that these spectral behaviors diagnose general LLM optimization dynamics therefore rests on an untested assumption of transferability; no replication on other architectures, optimizers, or codebases is described.
- [Abstract] Abstract: the three empirical findings are stated without reference to controls, error bars, or statistical tests. For the forecasting claim in particular, it is unclear whether the reported reliability survives multiple-testing correction, different random seeds, or alternative spectral truncation choices.
minor comments (2)
- [Abstract] The abstract refers to 'activation covariance and per-sample gradient SVD spectra' without defining the precise matrix construction or normalization used; this notation should be introduced explicitly in the methods section.
- The manuscript excerpt provides no figure or table captions, making it difficult to judge how the spectra are visualized or how quantitative thresholds (e.g., 'tail') are operationalized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We respond point by point below, indicating revisions where appropriate to improve clarity and address concerns about scope and statistical rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'a mechanistic model proves the main observations' is load-bearing for the paper's explanatory contribution, yet the abstract (and the provided manuscript excerpt) supplies no equations, assumptions, or derivation steps for this model. Without these details it is impossible to assess whether the model supplies independent grounding or merely restates the observed spectral correlations.
Authors: We agree that the abstract is too terse on the mechanistic model. The full manuscript (Section 4) derives the model from a simplified feature-learning dynamics with explicit assumptions of linear task alignment and covariance-driven updates, showing how the leading spectral modes predict token efficiency. We will revise the abstract to include a concise statement of the core assumptions and the key derivation linking spectral tails to aligned feature learning, allowing independent evaluation of whether the model provides explanatory power beyond correlation. revision: yes
-
Referee: [Abstract] Abstract and experimental description: all reported results, including the forecasting reliability of the activation covariance tail and the persistence across depths, are obtained exclusively on decoder-only models adapted from a single NanoGPT codebase variant. The central claim that these spectral behaviors diagnose general LLM optimization dynamics therefore rests on an untested assumption of transferability; no replication on other architectures, optimizers, or codebases is described.
Authors: The single controlled family was selected precisely to isolate batch-size and depth effects on representation geometry without implementation confounds, strengthening internal validity. We acknowledge that this precludes strong claims of universality across all LLMs. We will revise the abstract and add an explicit limitations paragraph noting the decoder-only NanoGPT scope and the need for future replication on other architectures and optimizers. The mechanistic model is formulated at a level that does not depend on specific codebases, but empirical breadth remains limited. revision: partial
-
Referee: [Abstract] Abstract: the three empirical findings are stated without reference to controls, error bars, or statistical tests. For the forecasting claim in particular, it is unclear whether the reported reliability survives multiple-testing correction, different random seeds, or alternative spectral truncation choices.
Authors: The full manuscript reports all main results as averages over multiple random seeds with error bars, and the appendix contains robustness checks across spectral truncation thresholds. We will update the abstract to reference these controls and the multi-seed validation. For the forecasting claim we will add a statement confirming that the predictive correlation remains significant after FDR correction for multiple comparisons and holds under varied truncation choices. revision: yes
- Replication of the reported spectral patterns and forecasting reliability on architectures other than the tested decoder-only family or with different optimizers and codebases.
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical spectral measurements on a controlled NanoGPT-derived decoder-only family, identifies three patterns (batch-size geometry effects, early-tail forecasting of token efficiency, and head-movement diagnostics), and states that a mechanistic model explains the correlation with task-aligned features. No equations, fitted-parameter renamings, or self-citation chains are supplied that would reduce any claimed prediction or proof to the input spectra by construction. The forecasting relation uses temporally separated measurements (early activation covariance versus later efficiency), which is statistically independent of the later data. The mechanistic model is asserted to prove the observations but is not shown to be a re-expression of the same fitted quantities. All load-bearing claims therefore remain externally falsifiable and non-tautological on the supplied text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling laws for neural language models, 2020
Kaplan et al. Scaling laws for neural language models, 2020. URLhttps://arxiv.org/abs/20 01.08361
2020
-
[2]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022. doi: 10.48550/arXiv.2203.15556. URLhttps://arxiv.org/abs/2203.15556
work page internal anchor Pith review doi:10.48550/arxiv.2203.15556 2022
-
[3]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64 a-Ab...
1901
-
[4]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Jack W Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher.arXiv preprint arXiv:2112.11446,
work page internal anchor Pith review arXiv
-
[5]
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
doi: 10.48550/arXiv.2112.11446. URLhttps://arxiv.org/abs/2112.11446
work page internal anchor Pith review doi:10.48550/arxiv.2112.11446
-
[6]
Predictability and surprise in large generative models
Deep Ganguli, Danny Hernandez, Liane Lovitt, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova Dassarma, Dawn Drain, Nelson Elhage, et al. Predictability and surprise in large generative models. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 1747–1764, 2022. doi: 10.1145/3531146.3533229. URL https: //do...
-
[7]
Melody Zixuan Li, Kumar Krishna Agrawal, Arna Ghosh, Komal Kumar Teru, Adam Santoro, Guillaume Lajoie, and Blake A. Richards. Tracing the representation geometry of language models from pretraining to post-training, 2025. URLhttps://arxiv.org/abs/2509.23024
-
[8]
Superposition Yields Robust Neural Scaling
Yizhou Liu, Ziming Liu, and Jeff Gore. Superposition yields robust neural scaling.arXiv preprint arXiv:2505.10465, 2025. doi: 10.48550/arXiv.2505.10465. URLhttps://arxiv.org/ abs/2505.10465
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.10465 2025
-
[9]
Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121,
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, and Utkarsh Sharma. Explaining neural scaling laws.Proceedings of the National Academy of Sciences, 121(27):e2311878121,
-
[10]
Explaining neural scaling laws , volume=
doi: 10.1073/pnas.2311878121. URLhttps://doi.org/10.1073/pnas.2311878121
-
[11]
Martin and Michael W
Charles H. Martin and Michael W. Mahoney. Implicit self-regularization in deep neural networks: Evidence from random matrix theory and implications for learning.Journal of Machine Learning Research, 22(165):1–73, 2021. URLhttps://www.jmlr.org/papers/v22/20-410.html
2021
-
[12]
modded-nanogpt: Speedrunning the nanogpt baseline, 2024
Jordan et al. modded-nanogpt: Speedrunning the nanogpt baseline, 2024. URL https: //github.com/KellerJordan/modded-nanogpt
2024
-
[13]
Tyler Chang, Zhuowen Tu, and Benjamin K. Bergen. The geometry of multilingual language model representations. InProceedings of EMNLP, 2022. doi: 10.18653/v1/2022.emnlp-main.9. URLhttps://aclanthology.org/2022.emnlp-main.9/
-
[14]
Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank
Quentin Garrido, Randall Balestriero, Laurent Najman, and Yann LeCun. Rankme: Assessing the downstream performance of pretrained self-supervised representations by their rank. In Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 10929–10974. PMLR, 2023. URLhttps://proceedings...
2023
-
[15]
Roberts, and Ethan Dyer
Guy Gur-Ari, Daniel A. Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace,
-
[16]
URLhttps://arxiv.org/abs/1812.04754
-
[17]
An investigation into neural net optimization via hessian eigenvalue density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density. InProceedings of ICML, 2019. URL https: //proceedings.mlr.press/v97/ghorbani19b.html. SPECTRAL LENS: ACTIVATION AND GRADIENT SPECTRA AS DIAGNOSTICS OF LLM OPTIMIZATION 13
2019
-
[18]
Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians
Vardan Papyan. Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians. InProceedings of ICML, 2019. URLhttps://proceedings.mlr.press/ v97/papyan19a.html
2019
-
[19]
Mahoney and Charles H
Michael W. Mahoney and Charles H. Martin. Traditional and heavy tailed self regularization in neural network models. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4284–4293. PMLR,
-
[20]
URLhttps://proceedings.mlr.press/v97/mahoney19a.html
-
[21]
On the overlooked structure of stochastic gradients
Zeke Xie, Qian-Yuan Tang, Mingming Sun, and Ping Li. On the overlooked structure of stochastic gradients. InProceedings of NeurIPS, 2023. URLhttps://proceedings.neurips.cc/paper_f iles/paper/2023/hash/d0b2eda0386f477ab14d7e181e16c899-Abstract-Conference.html
2023
-
[22]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. InInternational Conference on Learning Representations, 2017. URLhttps://arxiv. org/abs/1609.04836
work page internal anchor Pith review arXiv 2017
-
[23]
An Empirical Model of Large-Batch Training
Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. An empirical model of large-batch training.arXiv preprint arXiv:1812.06162, 2018. URLhttps://arxiv.org/ab s/1812.06162
work page Pith review arXiv 2018
-
[24]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, 2017. URLhttps://papers.neurips.cc/paper_files/paper/2017/has h/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html
2017
-
[25]
arXiv preprint arXiv:2210.16859 (2022)
Alexander Maloney, Daniel A. Roberts, and James Sully. A solvable model of neural scaling laws, 2022. URLhttps://arxiv.org/abs/2210.16859
-
[26]
Spectrum dependent learning curves in kernel regression and wide neural networks
Blake Bordelon, Abdulkadir Canatar, and Cengiz Pehlevan. Spectrum dependent learning curves in kernel regression and wide neural networks. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1024–1034. PMLR, 2020
2020
-
[27]
Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks.Nature Communications, 12(2914), 2021
Abdulkadir Canatar, Blake Bordelon, and Cengiz Pehlevan. Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks.Nature Communications, 12(2914), 2021
2021
-
[28]
Asymptotic learning curves of kernel methods: Empirical data versus teacher–student paradigm, 2019
Stefano Spigler, Mario Geiger, and Matthieu Wyart. Asymptotic learning curves of kernel methods: Empirical data versus teacher–student paradigm, 2019
2019
-
[29]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Guilherme Penedo, Hynek Kydlicek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale.arXiv preprint arXiv:2406.17557, 2024. doi: 10.48550/arXiv.2406.17557. URLhttps://arxiv.org/abs/2406.17557
work page internal anchor Pith review doi:10.48550/arxiv.2406.17557 2024
-
[30]
A system for massively parallel hyperparameter tuning
Liam Li, Kevin Jamieson, Afshin Rostamizadeh, Ekaterina Gonina, Jonathan Ben-tzur, Moritz Hardt, Benjamin Recht, and Ameet Talwalkar. A system for massively parallel hyperparameter tuning. InProceedings of Machine Learning and Systems, volume 2, pages 230–246, 2020. URL https://proceedings.mlsys.org/paper_files/paper/2020/hash/a06f20b349c6cf09a6b1 71c71b8...
2020
-
[31]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. InInternational Conference on Learning Representations, 2023. doi: 10.48550/arXiv.2301.05217. URLhttps://arxiv.org/abs/2301.0 5217
work page internal anchor Pith review doi:10.48550/arxiv.2301.05217 2023
-
[32]
Nolte, Eric J
Ziming Liu, Ouail Kitouni, Niklas S. Nolte, Eric J. Michaud, Max Tegmark, and Mike Williams. Towards understanding grokking: An effective theory of representation learning. InAdvances in Neural Information Processing Systems, volume 35, pages 34651–34663, 2022. URLhttps: //proceedings.neurips.cc/paper_files/paper/2022/hash/dfc310e81992d2e4cedc09ac4 7eff13...
2022
-
[33]
Grokking modular arithmetic, 2023
Andrey Gromov. Grokking modular arithmetic, 2023. URLhttps://arxiv.org/abs/2301.0 2679
2023
-
[34]
Richards.α-ReQ: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay
Kumar Krishna Agrawal, Arnab Kumar Mondal, Arna Ghosh, and Blake A. Richards.α-ReQ: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay. InAdvances in Neural Information Processing Systems, 2022. URLhttps://proceedings.ne urips.cc/paper_files/paper/2022/hash/70596d70542c51c8d9b4e423f4bf2736-Abstrac t-Conference.html
2022
-
[35]
Barlow twins: Self- supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stephane Deny. Barlow twins: Self- supervised learning via redundancy reduction. InProceedings of ICML, 2021. URLhttps: //proceedings.mlr.press/v139/zbontar21a.html
2021
-
[36]
Vicreg: Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regularization for self-supervised learning. InProceedings of ICLR, 2022. URL https: //openreview.net/forum?id=xm6YD62D1Ub
2022
-
[37]
Kawin Ethayarajh. How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 55–65, 2019. doi: 10.18653/v1/D19-1006. URL https://a...
-
[38]
William Timkey and Marten van Schijndel. All bark and no bite: Rogue dimensions in transformer language models obscure representational quality. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 4527–4546, 2021. doi: 10.18653/v1/2021.emnlp-main.372. URL https://aclanthology.org/2021.emnlp-main.37 2/
-
[39]
Evolution of the spectral dimension of transformer activations
Andy Zeyi Liu, Elliot Paquette, and John Sous. Evolution of the spectral dimension of transformer activations. InOPT 2025: Optimization for Machine Learning, 2025. URL https://openreview.net/forum?id=Va5is76bTP
2025
-
[40]
Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022
Utkarsh Sharma and Jared Kaplan. Scaling laws from the data manifold dimension.Journal of Machine Learning Research, 23(9):1–34, 2022. URLhttps://www.jmlr.org/papers/v23/20-1 111.html
2022
-
[41]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. InAdvances in Neural Information Processing Systems, 2007. URLhttps://papers.nips.cc/paper_fil es/paper/2007/hash/013a006f03dbc5392effeb8f18fda755-Abstract.html
2007
-
[42]
Nonlinear spiked covariance matrices and signal propagation in deep neural networks
Zhichao Wang, Denny Wu, and Zhou Fan. Nonlinear spiked covariance matrices and signal propagation in deep neural networks. InProceedings of COLT, 2024. URLhttps://proceedi ngs.mlr.press/v247/wang24b.html
2024
-
[43]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, and Vedant Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022. URLhttps://arxiv.or g/abs/2201.02177
work page internal anchor Pith review arXiv 2022
-
[44]
Jianliang He, Leda Wang, Siyu Chen, and Zhuoran Yang. On the mechanism and dynamics of modular addition: Fourier features, lottery ticket, and grokking, 2026. URLhttps://arxiv.or g/abs/2602.16849
-
[45]
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt
William Merrill, Nikolaos Tsilivis, and Aman Shukla. A tale of two circuits: Grokking as competition of sparse and dense subnetworks, 2023. URLhttps://arxiv.org/abs/2303.11873
-
[46]
Tikeng Notsawo, Hattie Zhou, Mohammad Pezeshki, Irina Rish, and Guillaume Dumas
Pascal Jr. Tikeng Notsawo, Hattie Zhou, Mohammad Pezeshki, Irina Rish, and Guillaume Dumas. Predicting grokking long before it happens: A look into the loss landscape of models which grok, 2023. URLhttps://arxiv.org/abs/2306.13253
-
[47]
Language models are unsupervised multitask learners, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners, 2019. URLhttps://cdn.openai.com/b etter-language-models/language_models_are_unsupervised_multitask_learners.pdf. SPECTRAL LENS: ACTIVATION AND GRADIENT SPECTRA AS DIAGNOSTICS OF LLM OPTIMIZATION 15
2019
-
[48]
modded-nanogpt record 1: llm.c baseline, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 1: llm.c baseline, 2024. URL https://github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1 _short/2024-10-13_llmc/main.log. Replacement link for the repository’s record-1 log; the originally uploaded 2024-05-28_llmc path did not resolve
2024
-
[49]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2021. URLhttps://arxiv.org/abs/ 2104.09864
work page internal anchor Pith review arXiv 2021
-
[50]
modded-nanogpt record 2: Tuned learning rate and rotary embeddings, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 2: Tuned learning rate and rotary embeddings, 2024. URLhttps://github.com/KellerJordan/modded-nanogpt/b lob/master/records/track_1_short/2024-06-06_AdamW/f66d43d7-e449-4029-8adf-e85 37bab49ea.log
2024
-
[51]
Muon: An optimizer for hidden layers in neural networks, 2024
Keller Jordan. Muon: An optimizer for hidden layers in neural networks, 2024. URLhttps: //kellerjordan.github.io/posts/muon/
2024
-
[52]
modded-nanogpt record 3: Introduced the muon optimizer, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 3: Introduced the muon optimizer, 2024. URL https://github.com/KellerJordan/modded-nanogpt#world-recor d-history. The repository’s world-record table lists record 3, but says no log is available; the originally uploaded 2024-10-04_Muon path did not resolve
2024
-
[53]
modded-nanogpt record 8: Untied embedding and head, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 8: Untied embedding and head, 2024. URL https://github.com/KellerJordan/modded-nanogpt/blob/master/recor ds/track_1_short/2024-11-03_UntieEmbed/d6b50d71-f419-4d26-bb39-a60d55ae7a04.tx t
2024
-
[54]
modded-nanogpt record 9: Value and embedding skip connections, momentum warmup, logit softcap, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 9: Value and embedding skip connections, momentum warmup, logit softcap, 2024. URLhttps://github.com/KellerJ ordan/modded-nanogpt/blob/master/records/track_1_short/2024-11-06_ShortcutsTwe aks/dd7304a6-cc43-4d5e-adb8-c070111464a1.txt
2024
-
[55]
U-Net: Convolutional Networks for Biomedical Image Segmentation, pp.\ 234–241
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Image Computing and Computer-Assisted Interven- tion, 2015. doi: 10.1007/978-3-319-24574-4_28. URL https://doi.org/10.1007/978-3-319 -24574-4_28
-
[56]
modded-nanogpt record 11: U-net pattern skip connections and double lr, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 11: U-net pattern skip connections and double lr, 2024. URLhttps://github.com/KellerJordan/modded-nanog pt/blob/master/records/track_1_short/2024-11-10_UNetDoubleLr/c87bb826-797b-4f3 7-98c7-d3a5dad2de74.txt
2024
-
[57]
modded-nanogpt record 12: 1024-ctx dense causal attention to 64k-ctx flexattention, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 12: 1024-ctx dense causal attention to 64k-ctx flexattention, 2024. URLhttps://github.com/KellerJordan/modded-n anogpt/blob/master/records/track_1_short/2024-11-19_FlexAttention/8384493d-dba 9-4991-b16b-8696953f5e6d.txt
-
[58]
modded-nanogpt record 13: Attention window warmup, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 13: Attention window warmup, 2024. URL https://github.com/KellerJordan/modded-nanogpt/blob/master/r ecords/track_1_short/2024-11-24_WindowWarmup/cf9e4571-c5fc-4323-abf3-a98d862ec 6c8.txt
2024
-
[59]
modded-nanogpt record 14: Value embeddings,
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 14: Value embeddings,
-
[60]
URL https://github.com/KellerJordan/modded-nanogpt/tree/master/records/t rack_1_short/2024-12-04_ValueEmbed
2024
-
[61]
modded-nanogpt record 16: Split value embeddings, block sliding window, separate block mask, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 16: Split value embeddings, block sliding window, separate block mask, 2024. URLhttps://github.com/KellerJordan/ modded-nanogpt/tree/master/records/track_1_short/2024-12-10_MFUTweaks
2024
-
[62]
modded-nanogpt record 17: Sparsify value embed- dings, improve rotary embeddings, drop an attn layer, 2024
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 17: Sparsify value embed- dings, improve rotary embeddings, drop an attn layer, 2024. URLhttps://github.com/Kelle rJordan/modded-nanogpt/tree/master/records/track_1_short/2024-12-17_SparsifyEm 16 SPECTRAL LENS: ACTIVATION AND GRADIENT SPECTRA AS DIAGNOSTICS OF LLM OPTIMIZATION beds
2024
-
[63]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size, 2024. URL https://arxiv.org/abs/2408.00118
work page internal anchor Pith review arXiv 2024
-
[64]
modded-nanogpt record 18: Lower logit softcap from 30 to 15, 2025
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 18: Lower logit softcap from 30 to 15, 2025. URLhttps://github.com/KellerJordan/modded-nanogpt/blob/mast er/records/track_1_short/2025-01-04_SoftCap/31d6c427-f1f7-4d8a-91be-a67b5dcd1 3fd.txt
2025
-
[65]
Fp8 formats for deep learning,
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, Naveen Mellem- pudi, Stuart Oberman, Mohammad Shoeybi, Michael Siu, and Hao Wu. FP8 formats for deep learning, 2022. URLhttps://arxiv.org/abs/2209.05433
-
[66]
modded-nanogpt record 19: Fp8 head, offset logits, lr decay to 0.1 instead of 0.0, 2025
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 19: Fp8 head, offset logits, lr decay to 0.1 instead of 0.0, 2025. URLhttps://github.com/KellerJordan/modded-nanog pt/blob/master/records/track_1_short/2025-01-13_Fp8LmHead/c51969c2-d04c-40a7-b cea-c092c3c2d11a.txt
2025
-
[67]
largest run
KellerJordan/modded-nanogpt contributors. modded-nanogpt record 20: Merged qkv weights, long-short attention, attention scale, lower adam epsilon, batched muon, 2025. URLhttps: //github.com/KellerJordan/modded-nanogpt/blob/master/records/track_1_short/202 5-01-16_Sub3Min/1d3bd93b-a69e-4118-aeb8-8184239d7566.txt. SPECTRAL LENS: ACTIVATION AND GRADIENT SPEC...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.