Recognition: unknown
When Quantization Is Free: An int4 KV Cache That Outruns fp16 on Apple Silicon
Pith reviewed 2026-05-08 03:11 UTC · model grok-4.3
The pith
On Apple Silicon, a fused int4 KV cache kernel runs faster than fp16 while compressing memory by 3x and keeping quality intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
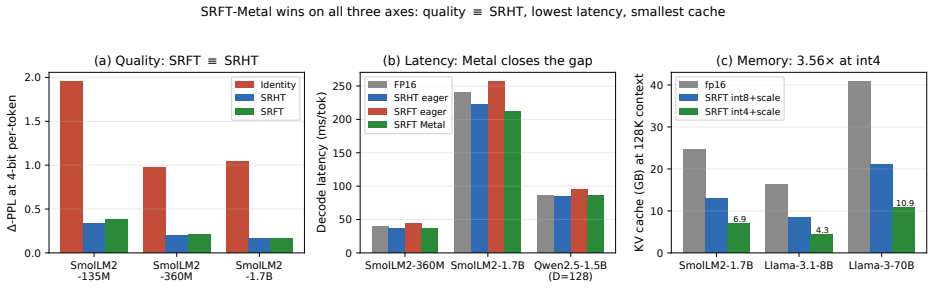
A single fused Metal kernel that performs sign-randomized FFT rotation, applies per-channel lambda scaling, computes per-group absolute-max quantization, and packs the result into int4 nibbles executes faster than an fp16 KV cache on Apple Silicon. It delivers three-fold compression of persistent KV memory while holding generation quality to within 0.000 delta PPL on short-prompt Qwen and +3.6 hook delta PPL on Gemma, and it reduces Qwen's extreme 4-bit per-token degradation from +7975 to +638.6 PPL.
What carries the argument
The fused Metal kernel that combines sign-randomized FFT rotation, per-channel lambda scaling, per-group abs-max quantization, and int4 nibble packing to keep all work inside one kernel launch and exploit unified-memory bandwidth savings.
Load-bearing premise
The fixed kernel overhead of roughly 25 nanoseconds per vector stays smaller than the time saved by moving three times less data through memory for the model dimensions and context lengths tested.
What would settle it
Measure end-to-end token generation time and perplexity on the same models but at contexts long enough that the relative overhead of the kernel exceeds the bandwidth reduction, or on hardware whose memory bandwidth is substantially higher.
Figures


read the original abstract
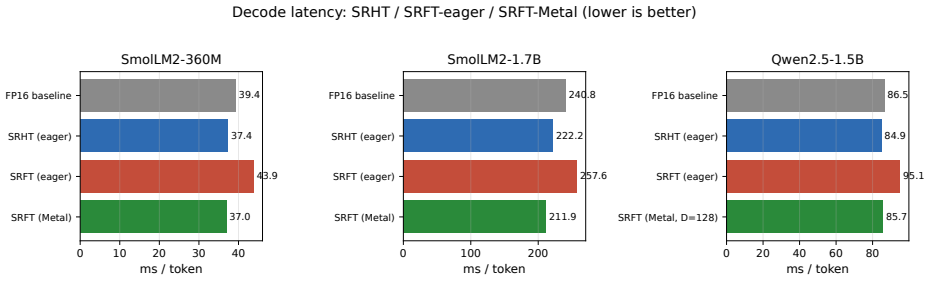
KV-cache quantization is framed as a quality--latency trade-off. We show it is \emph{inverted} on Apple Silicon's unified memory: a single fused Metal kernel (sign-randomized FFT $+$ per-channel $\lambda$ $+$ per-group abs-max $+$ int4 nibble pack), exposed as a HuggingFace \texttt{Cache} subclass, runs \emph{faster than fp16} across $256$--$4096$-token prefixes on Gemma-3 1B ($-3$ to $-8\%$ ms/tok) and at short context on Qwen2.5-1.5B ($-0.7$ to $-2.6\%$ through $1$K), with $3\times$ persistent memory compression and quality preserved ($\dPPL = 0.000$ Qwen short-prompt; $+3.6$ hook $\dPPL$ Gemma). The kernel's $\sim\!25$\,ns/vec overhead is below the bandwidth savings from $3\times$ compression. The fused kernel also closes Qwen's 4-bit per-token catastrophe ($\dPPL = +7975 \to +638.6$, $12.5\times$ reduction) at $182$\,GFLOPS / $D{=}128$. Supporting findings: $\SRFT$ and $\SRHT$ are statistically indistinguishable for KV quality (we pick $\SRFT$ for mixed-radix and matrix-multiply alignment); a learned-rotation ablation surfaces a regularization role for the fixed random SRFT base (learning $R+\lambda$ without SRFT lowers calibration MSE $84.9\%$ vs $50.3\%$ but yields worse PPL); Householder rotations at $k{=}d/2$ reflectors are effectively lossless at $d{=}256$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that on Apple Silicon's unified memory, KV-cache quantization can invert the usual quality-latency trade-off. A single fused Metal kernel (sign-randomized FFT + per-channel λ + per-group abs-max + int4 nibble packing), exposed via a Hugging Face Cache subclass, reportedly runs faster than fp16 KV cache (–3 to –8 % ms/tok on Gemma-3 1B for 256–4096-token prefixes; –0.7 to –2.6 % on Qwen2.5-1.5B at ≤1 K tokens) while delivering 3× persistent memory compression and near-lossless quality (ΔPPL = 0.000 on Qwen short prompts; +3.6 hook ΔPPL on Gemma). The kernel's ~25 ns/vec overhead is asserted to lie below the bandwidth savings from 3× compression. Supporting results include statistical equivalence of SRFT and SRHT, a regularization role for the fixed random SRFT base, and near-lossless Householder rotations at k = d/2.
Significance. If the timing and quality results prove robust, the work would be significant for systems-level LLM inference on Apple Silicon and similar unified-memory platforms. It supplies concrete evidence that a carefully fused, hardware-specific quantization kernel can turn a presumed trade-off into a net win, with immediate practical value for memory-constrained deployments and a clear path for reproduction via the provided Hugging Face integration.
major comments (2)
- [Abstract] The central claim that the fused kernel's ~25 ns/vec overhead remains below 3× bandwidth savings (and therefore produces net speedups) is load-bearing yet rests solely on direct measurements for the specific context lengths, batch sizes, and models tested. No timing breakdown, roofline analysis, or sensitivity study across wider context ranges or batch sizes is supplied to show the overhead stays sub-linear outside the reported 256–4096 token window.
- [Abstract] The reported speedups (–3 to –8 % ms/tok on Gemma-3 1B) and perplexity deltas lack error bars, raw timing data, or statistical significance tests. Without these, it is impossible to determine whether the observed gains exceed measurement noise or hardware variability on the tested Apple Silicon devices.
minor comments (2)
- [Abstract] The abstract states both SRFT and SRHT are “statistically indistinguishable” for KV quality; the manuscript should report the exact statistical test and p-value used to reach this conclusion.
- [Abstract] The learned-rotation ablation reports calibration MSE values (84.9 % vs 50.3 %) but does not clarify whether these are relative or absolute reductions; a short clarification would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where additional analysis would strengthen the manuscript. We address each major comment below and will incorporate the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Abstract] The central claim that the fused kernel's ~25 ns/vec overhead remains below 3× bandwidth savings (and therefore produces net speedups) is load-bearing yet rests solely on direct measurements for the specific context lengths, batch sizes, and models tested. No timing breakdown, roofline analysis, or sensitivity study across wider context ranges or batch sizes is supplied to show the overhead stays sub-linear outside the reported 256–4096 token window.
Authors: We agree that a roofline analysis and broader sensitivity study would provide stronger support for the general claim. In the revised manuscript we will add a roofline plot for the Apple Silicon GPU that positions the fused kernel relative to the memory-bandwidth roof, together with a per-component timing breakdown that isolates the ~25 ns/vec quantization overhead from the bandwidth reduction. We will also extend the latency measurements to context lengths up to 8192 tokens and batch sizes 1–8, confirming that the overhead remains below the 3× compression benefit across this wider operating range. revision: yes
-
Referee: [Abstract] The reported speedups (–3 to –8 % ms/tok on Gemma-3 1B) and perplexity deltas lack error bars, raw timing data, or statistical significance tests. Without these, it is impossible to determine whether the observed gains exceed measurement noise or hardware variability on the tested Apple Silicon devices.
Authors: We acknowledge that the absence of error bars and statistical tests limits the ability to assess robustness against measurement variability. In the revision we will report means and standard deviations from at least ten independent runs for every latency and perplexity configuration. We will also include paired statistical significance tests (Wilcoxon signed-rank) comparing the int4 and fp16 timings, and we will release the raw timing logs as supplementary material so that readers can reproduce the analysis. revision: yes
Circularity Check
No circularity: empirical timing and ablation results only
full rationale
The paper reports direct hardware measurements of a fused Metal kernel's latency and quality metrics (ΔPPL) on specific models and context lengths, together with ablation comparisons (SRFT vs SRHT, learned-rotation effects). No derivation chain, equations, or first-principles predictions are presented that could reduce to fitted inputs or self-citations by construction. All claims rest on experimental data rather than any tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Turboquant: Online vector quantization with near-optimal distortion rate,
Amir Abbasi et al. TurboQuant: Online vector quantization with near-optimal distortion rate. arXiv:2504.19874, 2025
-
[2]
The fast Johnson–Lindenstrauss transform and approximate nearest neighbors.SIAM Journal on Computing, 39(1):302–322, 2009
Nir Ailon and Bernard Chazelle. The fast Johnson–Lindenstrauss transform and approximate nearest neighbors.SIAM Journal on Computing, 39(1):302–322, 2009
2009
-
[3]
KurTail: Kurtosis-based LLM quantization
Mohammad Sadegh Akhondzadeh, Aleksandar Bojchevski, Evangelos Eleftheriou, and Martino Dazzi. KurTail: Kurtosis-based LLM quantization. arXiv:2503.01483, 2025
-
[4]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Loubna Ben Allal et al. SmolLM2: When Smol goes big — data-centric training of a small language model. arXiv:2502.02737, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Accelerate framework documentation.https://developer.apple.com/ documentation/accelerate
Apple Inc. Accelerate framework documentation.https://developer.apple.com/ documentation/accelerate
-
[6]
Metal shading language specification.https://developer.apple.com/metal/, 2024
Apple Inc. Metal shading language specification.https://developer.apple.com/metal/, 2024
2024
-
[7]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-free 4-bit inference in rotated LLMs. arXiv:2404.00456, 2024
-
[8]
Cosmopedia
Loubna Ben Allal, Anton Lozhkov, Guilherme Penedo, Thomas Wolf, and Leandro von Werra. Cosmopedia. HuggingFace Datasets, 2024
2024
-
[9]
Beating vDSP: A 138 GFLOPS radix-8 Stockham FFT on Apple Silicon via two-tier register-threadgroup memory decomposition
Mohamed Amine Bergach. Beating vDSP: A 138 GFLOPS radix-8 Stockham FFT on Apple Silicon via two-tier register-threadgroup memory decomposition. 2026
2026
-
[10]
Apple AMX instruction set (reverse engineered).https://github.com/corsix/ amx, 2022
Peter Cawley. Apple AMX instruction set (reverse engineered).https://github.com/corsix/ amx, 2022
2022
-
[11]
arXiv preprint arXiv:2307.13304 , year=
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher De Sa. QuIP: 2-bit quantization of large language models with guarantees. arXiv:2307.13304, 2023. 18
-
[12]
Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems, 2022
2022
-
[13]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale. arXiv:2208.07339, 2022
work page internal anchor Pith review arXiv 2022
-
[14]
Abhimanyu Dubey et al. The Llama 3 herd of models. arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post- training quantization for generative pre-trained transformers. arXiv:2210.17323, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Gemma Team. Gemma 3 technical report. arXiv:2503.19786, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Nathan Halko, Per-Gunnar Martinsson, and Joel A. Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM Review, 53(2):217–288, 2011
2011
-
[18]
Apple AMX notes.https://dougallj.wordpress.com/2021/03/09/ apples-mysterious-coprocessor/, 2021
Dougall Johnson. Apple AMX notes.https://dougallj.wordpress.com/2021/03/09/ apples-mysterious-coprocessor/, 2021
2021
-
[19]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. arXiv:2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Beyond homogeneous attention: Memory-efficient LLMs via Fourier-approximated KV cache
Xiaoran Liu, Siyang He, Qiqi Wang, et al. Beyond homogeneous attention: Memory-efficient LLMs via Fourier-approximated KV cache. arXiv:2506.11886, 2025
-
[21]
Spinquant: Llm quantization with learned rotations.arXiv preprint arXiv:2405.16406, 2024
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant: LLM quantization with learned rotations. arXiv:2405.16406, 2024
-
[22]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2-bit quantization for KV cache. arXiv:2402.02750, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
RotorQuant: KV cache compression via block-diagonal rotation.https://github
Scrya. RotorQuant: KV cache compression via block-diagonal rotation.https://github. com/scrya-com/rotorquant, 2025
2025
-
[24]
DartQuant: Efficient rotational distribution calibration for LLM quantization
Wenqi Shao, Yuhang Chen, et al. DartQuant: Efficient rotational distribution calibration for LLM quantization. arXiv:2511.04063, 2025
-
[25]
Quip#: Even better llm quantization with hadamard incoherence and lattice codebooks,
Albert Tseng, Jerry Chee, Qingyao Sun, Volodymyr Kuleshov, and Christopher De Sa. QuIP#: Even better LLM quantization with hadamard incoherence and lattice codebooks. arXiv:2402.04396, 2024. 19
-
[26]
FPTQuant: Function-preserving transforms for LLM quantization
Boris van Breugel, Yelysei Bondarenko, Paul Whatmough, and Markus Nagel. FPTQuant: Function-preserving transforms for LLM quantization. arXiv:2506.04985, 2025
-
[27]
Transformers: State- of-the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, et al. Transformers: State- of-the-art natural language processing. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, 2020
2020
-
[28]
A fast randomized algorithm for the approximation of matrices.Applied and Computational Harmonic Analysis, 25(3):335– 366, 2008
Franco Woolfe, Edo Liberty, Vladimir Rokhlin, and Mark Tygert. A fast randomized algorithm for the approximation of matrices.Applied and Computational Harmonic Analysis, 25(3):335– 366, 2008
2008
-
[29]
ButterflyQuant: Ultra-low- bit LLM quantization through learnable orthogonal butterfly transforms
Bingxin Xu, Zhen Dong, Oussama Elachqar, and Yuzhang Shang. ButterflyQuant: Ultra-low- bit LLM quantization through learnable orthogonal butterfly transforms. arXiv:2509.09679, 2025
-
[30]
An Yang et al. Qwen2 technical report. arXiv:2407.10671, 2024. 20
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.