Recognition: no theorem link
Active Learning for Communication Structure Optimization in LLM-Based Multi-Agent Systems
Pith reviewed 2026-05-11 01:42 UTC · model grok-4.3
The pith
Task selection by expected shifts in graph parameter distributions optimizes communication structures in LLM multi-agent systems more reliably than random sampling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that task informativeness equals the expected change a task induces in the posterior distribution over communication-graph parameters; ensemble Kalman inversion supplies an efficient, derivative-free approximation to this quantity, and selecting tasks according to the resulting scores yields more effective communication-structure optimization than random sampling, both in standard settings and when some agents are attacked.
What carries the argument
ensemble Kalman inversion approximation to the Bayesian update that quantifies how much a candidate task shifts the distribution over communication-graph parameters
If this is right
- Active task selection reduces sensitivity of the final communication graph to the particular training set chosen.
- The same framework remains effective when some agents behave adversarially.
- Embedding-based candidate-pool construction plus surrogate modeling and batch Thompson sampling together keep the method computationally tractable.
- The approach applies under constrained training budgets where exhaustive evaluation of all tasks is impossible.
Where Pith is reading between the lines
- If the approximation holds, the same selection principle could be used to optimize other black-box structural choices such as agent role assignments or shared prompt templates.
- The method points toward derivative-free active-learning techniques for any multi-agent system whose performance is measured only through noisy end-to-end evaluations.
- Extending the candidate pool construction beyond embeddings to include domain-specific similarity metrics might further improve selection quality in specialized task domains.
Load-bearing premise
That ensemble Kalman inversion supplies a sufficiently accurate approximation to the true Bayesian update for measuring task informativeness in noisy black-box multi-agent LLM systems, and that the embedding-based candidate pool remains representative of the full task distribution.
What would settle it
A controlled experiment in which tasks ranked highest by the informativeness estimator produce no greater improvement in final system performance than randomly chosen tasks of equal number would directly falsify the claim that the estimator selects valuable tasks.
Figures









read the original abstract
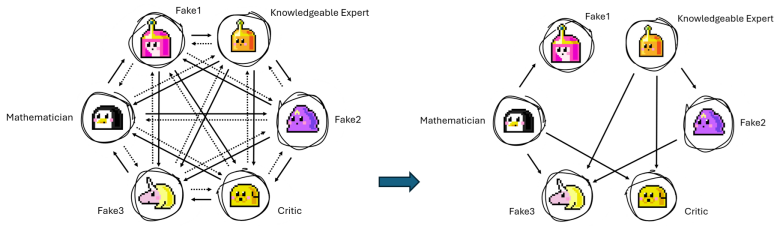
Optimizing the communication structure of large language model based multi-agent systems (LLM-MAS) has been shown to improve downstream performance and reduce token usage. Existing methods typically rely on randomly sampled training tasks. However, tasks may differ substantially in difficulty and domain, and thus they are not equally informative for updating communication structure, making optimization under limited training budgets often unstable and highly sensitive to the particular training set. To actively identify the most valuable tasks for communication-structure optimization, we propose an ensemble-based information-theoretic task selection framework. The proposed method estimates task informativeness by how much a candidate task changes the distribution over graph parameters, using ensemble Kalman inversion as an efficient and derivative-free approximation of the corresponding Bayesian update. The resulting estimator is especially suitable for black-box and noisy multi-agent systems. To enhance scalability, we construct a compact candidate pool through embedding-based representative selection and combine the informative selection with surrogate modeling and batch Thompson sampling. We validate our method in both benign settings and settings with agent attacks, demonstrating its effectiveness for communication-structure optimization under constrained computational budgets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an ensemble-based information-theoretic active learning framework for selecting training tasks to optimize communication structures in LLM-based multi-agent systems. Task informativeness is quantified by the shift it induces in the posterior over graph parameters, with ensemble Kalman inversion (EnKI) used as a derivative-free approximation to the Bayesian update. The approach augments this with embedding-based candidate pool construction, surrogate modeling, and batch Thompson sampling, and reports validation in both benign and agent-attack settings under constrained computational budgets.
Significance. If the empirical claims hold, the work provides a targeted method to reduce the instability of communication-structure optimization that arises from random task sampling, which is especially relevant for black-box, noisy LLM-MAS under tight token or compute limits. The use of EnKI to handle derivative-free, stochastic forward models is a pragmatic adaptation, and the explicit treatment of agent-attack scenarios adds practical value. Credit is due for framing the problem around information gain on graph parameters rather than downstream task performance alone.
major comments (2)
- [§3.2] §3.2 (EnKI approximation): The central claim that the ensemble shift under EnKI accurately ranks tasks by true information gain for communication-graph parameters rests on the assumption that the Gaussian ensemble update sufficiently approximates the posterior change. In LLM-MAS the forward model is highly non-linear, stochastic, and the graph parameters are typically discrete (adjacency or topology choices), so the ensemble can collapse or bias the estimated informativeness. A load-bearing validation—e.g., a controlled comparison of EnKI scores against exact posterior shifts on a small discrete graph model—is required before the superiority over random sampling can be accepted.
- [Experimental section] Experimental section (results tables): The abstract asserts effectiveness under constrained budgets in both benign and attack settings, yet the provided text contains no quantitative metrics, error bars, ablation on the EnKI component, or protocol details (number of runs, budget levels, graph sizes). Without these, the data support for the claim that the method outperforms random sampling cannot be assessed, undermining the central empirical contribution.
minor comments (2)
- [§2] Notation: The mapping from communication structure to the parameter vector θ is introduced without an explicit equation or example in the early sections; a small illustrative diagram or definition would improve readability.
- [§3.3] Candidate pool construction: The embedding-based representative selection is described at a high level; the precise embedding model, distance metric, and selection algorithm (k-means, greedy, etc.) should be stated explicitly with a reference or pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and describe the revisions we will incorporate to address the concerns raised.
read point-by-point responses
-
Referee: [§3.2] §3.2 (EnKI approximation): The central claim that the ensemble shift under EnKI accurately ranks tasks by true information gain for communication-graph parameters rests on the assumption that the Gaussian ensemble update sufficiently approximates the posterior change. In LLM-MAS the forward model is highly non-linear, stochastic, and the graph parameters are typically discrete (adjacency or topology choices), so the ensemble can collapse or bias the estimated informativeness. A load-bearing validation—e.g., a controlled comparison of EnKI scores against exact posterior shifts on a small discrete graph model—is required before the superiority over random sampling can be accepted.
Authors: We acknowledge that the reliability of the EnKI-based informativeness ranking depends on how well the Gaussian ensemble update approximates the true posterior shift, especially given the non-linear, stochastic forward models and discrete graph parameters in LLM-MAS. While EnKI is a standard derivative-free technique for such intractable settings and has been validated in other non-linear domains, we agree that a direct comparison to exact posterior shifts would strengthen the central claim. In the revised manuscript, we will add a controlled validation study on a small-scale discrete graph model (e.g., using exact enumeration or MCMC on toy instances) to compare EnKI scores against ground-truth information gain. This will be included in an expanded §3.2 or a new appendix. revision: yes
-
Referee: [Experimental section] Experimental section (results tables): The abstract asserts effectiveness under constrained budgets in both benign and attack settings, yet the provided text contains no quantitative metrics, error bars, ablation on the EnKI component, or protocol details (number of runs, budget levels, graph sizes). Without these, the data support for the claim that the method outperforms random sampling cannot be assessed, undermining the central empirical contribution.
Authors: We appreciate the referee highlighting this gap in the submitted version. The experimental section will be substantially expanded in the revision to include full quantitative results: performance metrics (e.g., communication-structure stability, downstream accuracy, token savings) with error bars from multiple runs (we will specify 5–10 random seeds), ablation studies isolating the EnKI component, and complete protocol details (budget levels, graph sizes, number of tasks, statistical tests). These additions will be presented in revised tables and text to rigorously support the superiority over random sampling in both benign and agent-attack scenarios. revision: yes
Circularity Check
No circularity: framework combines external approximation techniques without self-referential reduction
full rationale
The abstract and described framework present an active learning procedure that estimates task informativeness via the change in graph-parameter distribution, approximated by ensemble Kalman inversion (EnKI) as a derivative-free Bayesian update. This is combined with embedding-based candidate selection, surrogate modeling, and batch Thompson sampling. No equations or claims reduce the informativeness score, the selection criterion, or the final optimization result to a fitted parameter, self-definition, or load-bearing self-citation by construction. EnKI is invoked as an established external method suitable for black-box systems rather than derived from the paper's own inputs. The central claim therefore remains independent of tautological re-labeling or circular fitting, consistent with the reader's assessment of score 2.0 (minor at most).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ensemble Kalman inversion provides a usable derivative-free approximation to the Bayesian posterior update for graph-parameter distributions
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2405.02957 , year =
Junkai Li, Yunghwei Lai, Weitao Li, Jingyi Ren, Meng Zhang, Xinhui Kang, Siyu Wang, Peng Li, Ya-Qin Zhang, Weizhi Ma, et al. Agent hospital: A simulacrum of hospital with evolvable medical agents.arXiv preprint arXiv:2405.02957, 2024
-
[2]
Wenxuan Wang, Zizhan Ma, Zheng Wang, Chenghan Wu, Jiaming Ji, Wenting Chen, Xiang Li, and Yixuan Yuan. A survey of llm-based agents in medicine: How far are we from baymax? Findings of the Association for Computational Linguistics: ACL 2025, pages 10345–10359, 2025
work page 2025
-
[3]
Jingquan Wang, Harry Zhang, Khailanii Slaton, Shu Wang, Radu Serban, Jinlong Wu, and Dan Negrut. Chronollm: a framework for customizing large language model for digital twins generalization based on pychrono.arXiv preprint arXiv:2501.04062, 2025
-
[4]
SciML Agents: Write the Solver, Not the Solution
Saarth Gaonkar, Xiang Zheng, Haocheng Xi, Rishabh Tiwari, Kurt Keutzer, Dmitriy Morozov, Michael W Mahoney, and Amir Gholami. SciML agents: Write the solver, not the solution. arXiv preprint arXiv:2509.09936, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Xinyi Li, Sai Wang, Siqi Zeng, Yu Wu, and Yi Yang. A survey on LLM-based multi-agent systems: workflow, infrastructure, and challenges.Vicinagearth, 1(1):9, 2024
work page 2024
-
[6]
Junda He, Christoph Treude, and David Lo. LLM-based multi-agent systems for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology, 34(5):1–30, 2025
work page 2025
-
[7]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. MetaGPT: Meta programming for a multi-agent collaborative framework. InThe twelfth international conference on learning representations, 2024
work page 2024
-
[8]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174–15186, 2024
work page 2024
-
[9]
S2-mad: Breaking the token barrier to enhance multi-agent debate efficiency
Yuting Zeng, Weizhe Huang, Lei Jiang, Tongxuan Liu, Xitai Jin, Chen Tianying Tiana, Jing Li, and Xiaohua Xu. S2-mad: Breaking the token barrier to enhance multi-agent debate efficiency. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
work page 2025
-
[10]
Xu Shen, Yixin Liu, Yiwei Dai, Yili Wang, Rui Miao, Yue Tan, Shirui Pan, and Xin Wang. Understanding the information propagation effects of communication topologies in LLM-based multi-agent systems. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12347–12361, 2025
work page 2025
-
[11]
AFlow: Automating Agentic Workflow Generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Automating agentic workflow generation.arXiv preprint arXiv:2410.10762, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Jiaxi Yang, Mengqi Zhang, Yiqiao Jin, Hao Chen, Qingsong Wen, Lu Lin, Yi He, Srijan Kumar, Weijie Xu, James Evans, et al. Topological structure learning should be a research priority for LLM-based multi-agent systems.arXiv preprint arXiv:2505.22467, 2025. 10
-
[13]
Shiyuan Li, Yixin Liu, Qingsong Wen, Chengqi Zhang, and Shirui Pan. Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23142–23150, 2026
work page 2026
-
[14]
Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
Guibin Zhang, Luyang Niu, Junfeng Fang, Kun Wang, Lei Bai, and Xiang Wang. Multi-agent architecture search via agentic supernet.arXiv preprint arXiv:2502.04180, 2025
-
[15]
Cut the crap: An economical communication pipeline for LLM-based multi-agent systems
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for LLM-based multi-agent systems. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=LkzuPorQ5L
work page 2025
-
[16]
Amas: Adaptively determining communication topology for LLM-based multi-agent system
Hui Yi Leong, Yuheng Li, Yuqing Wu, Wenwen Ouyang, Wei Zhu, Jiechao Gao, and Wei Han. Amas: Adaptively determining communication topology for LLM-based multi-agent system. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 2061–2070, 2025
work page 2025
-
[17]
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G-designer: Architecting multi-agent communication topologies via graph neural networks.arXiv preprint arXiv:2410.11782, 2024
-
[18]
Zhexuan Wang, Yutong Wang, Xuebo Liu, Liang Ding, Miao Zhang, Jie Liu, and Min Zhang. Agentdropout: Dynamic agent elimination for token-efficient and high-performance LLM-based multi-agent collaboration. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 24013–24035, 2025
work page 2025
-
[19]
Zhenyu Bi, Meng Lu, Yang Li, Swastik Roy, Weijie Guan, Morteza Ziyadi, and Xuan Wang. OPTAGENT: Optimizing multi-agent LLM interactions through verbal reinforcement learning for enhanced reasoning. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association f...
work page 2025
-
[20]
Ensemble Kalman methods for inverse problems.Inverse Problems, 29(4):045001, 2013
Marco A Iglesias, Kody JH Law, and Andrew M Stuart. Ensemble Kalman methods for inverse problems.Inverse Problems, 29(4):045001, 2013
work page 2013
-
[21]
Nikola B Kovachki and Andrew M Stuart. Ensemble Kalman inversion: a derivative-free technique for machine learning tasks.Inverse Problems, 35(9):095005, 2019
work page 2019
-
[22]
Active learning literature survey
Burr Settles. Active learning literature survey. 2009
work page 2009
-
[23]
Alaa Tharwat and Wolfram Schenck. A survey on active learning: State-of-the-art, practical challenges and research directions.Mathematics, 11(4):820, 2023
work page 2023
-
[24]
Bayesian approaches to associative learning: From passive to active learning
John K Kruschke. Bayesian approaches to associative learning: From passive to active learning. Learning & behavior, 36(3):210–226, 2008
work page 2008
-
[25]
Andreas Kirsch, Joost Van Amersfoort, and Yarin Gal. Batchbald: Efficient and diverse batch acquisition for deep Bayesian active learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[26]
A survey of deep active learning.ACM computing surveys (CSUR), 54 (9):1–40, 2021
Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B Gupta, Xiaojiang Chen, and Xin Wang. A survey of deep active learning.ACM computing surveys (CSUR), 54 (9):1–40, 2021
work page 2021
-
[27]
Active learning with real annotation costs
Burr Settles, Mark Craven, and Lewis Friedland. Active learning with real annotation costs. In Proceedings of the NIPS workshop on cost-sensitive learning, volume 1. Vancouver, CA:, 2008
work page 2008
-
[28]
Aditya Siddhant and Zachary C Lipton. Deep Bayesian active learning for natural language processing: Results of a large-scale empirical study. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2904–2909, 2018
work page 2018
-
[29]
Bayesian active learning for classification and preferenc e learning,
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745, 2011. 11
-
[30]
Deep Bayesian active learning with image data
Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep Bayesian active learning with image data. InInternational conference on machine learning, pages 1183–1192. PMLR, 2017
work page 2017
-
[31]
Improving generalization with active learning
David Cohn, Les Atlas, and Richard Ladner. Improving generalization with active learning. Machine learning, 15(2):201–221, 1994
work page 1994
-
[32]
Maximizing expected model change for active learning in regression
Wenbin Cai, Ya Zhang, and Jun Zhou. Maximizing expected model change for active learning in regression. In2013 IEEE 13th international conference on data mining, pages 51–60. IEEE, 2013
work page 2013
-
[33]
Tapio Helin, Youssef Marzouk, and Jose Rodrigo Rojo-Garcia. Bayesian optimal experimental design with Wasserstein information criteria.arXiv preprint arXiv:2504.10092, 2025
-
[34]
Huchen Yang, Xinghao Dong, and Jin-Long Wu. Bayesian experimental design for model discrepancy calibration: A rivalry between Kullback–Leibler divergence and Wasserstein distance.arXiv preprint arXiv:2601.16425, 2026
-
[35]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[36]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffu- sion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review arXiv 2022
-
[37]
Exponential convergence of Langevin distributions and their discrete approximations
Gareth O Roberts and Richard L Tweedie. Exponential convergence of Langevin distributions and their discrete approximations. 1996
work page 1996
-
[38]
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
work page 2019
-
[39]
Huchen Yang, Xinghao Dong, and Jin-Long Wu. Bayesian experimental design for model discrepancy calibration: An auto-differentiable ensemble Kalman inversion approach.Journal of Computational Physics, 545:114469, 2026
work page 2026
-
[40]
Reverse-annealed sequential Monte Carlo for efficient Bayesian optimal experiment design
Jake Callahan, Andrew Chin, Jason Pacheco, and Tommie Catanach. Reverse-annealed sequential Monte Carlo for efficient Bayesian optimal experiment design. InThe Thirty- ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=jut5q3UYRz
work page 2025
-
[41]
Sentence-BERT: Sentence embeddings using siamese BERT- networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT- networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 3982–3992. Association for Computational Linguistics, 11 2019
work page 2019
-
[42]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. MiniLM: Deep self-attention distillation for task-agnostic compression of pre-trained transformers.Advances in neural information processing systems, 33:5776–5788, 2020
work page 2020
-
[43]
Yiwei Li, Jiayi Shi, Shaoxiong Feng, Peiwen Yuan, Xinglin Wang, Boyuan Pan, Heda Wang, Yao Hu, and Kan Li. Instruction embedding: Latent representations of instructions towards task identification.Advances in Neural Information Processing Systems, 37:87683–87711, 2024
work page 2024
-
[44]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[45]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021. 12 A Methodology details and extensions A.1 EKI and score-based posterior sampling...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[46]
(23) Similarly, it can be shown that C ll ≈G qC zz G⊤ q
Justification of the first approximation Consider C zl = 1 J−1 JX j=1 (z(j) − ¯z)(l(j) − ¯l)⊤ ≈ 1 J−1 JX j=1 (z(j) − ¯z) h Gq(z(j) − ¯z) i⊤ = 1 J−1 JX j=1 (z(j) − ¯z)(z(j) − ¯z)⊤G⊤ q =C zz G⊤ q . (23) Similarly, it can be shown that C ll ≈G qC zz G⊤ q . Therefore, the first approximation holds, and the approximation will be exact when the forward model is linear
-
[47]
Proof of the final equality Here we show C zz G⊤ q GqC zz G⊤ q + Γ −1 =C locG⊤ q Γ−1.(24) We first defineS=G qC zz G⊤ q + Γfor notational simplicity. Starting from the right-hand side, ClocG⊤ q Γ−1 =C locG⊤ q Γ−1SS −1 =C locG⊤ q Γ−1(GqC zz G⊤ q + Γ)S−1 =C loc G⊤ q Γ−1GqC zz G⊤ q S−1 +G ⊤ q Γ−1ΓS−1 =C loc G⊤ q Γ−1GqC zz G⊤ q S−1 +G ⊤ q S−1 =C loc G⊤ q Γ−1G...
-
[48]
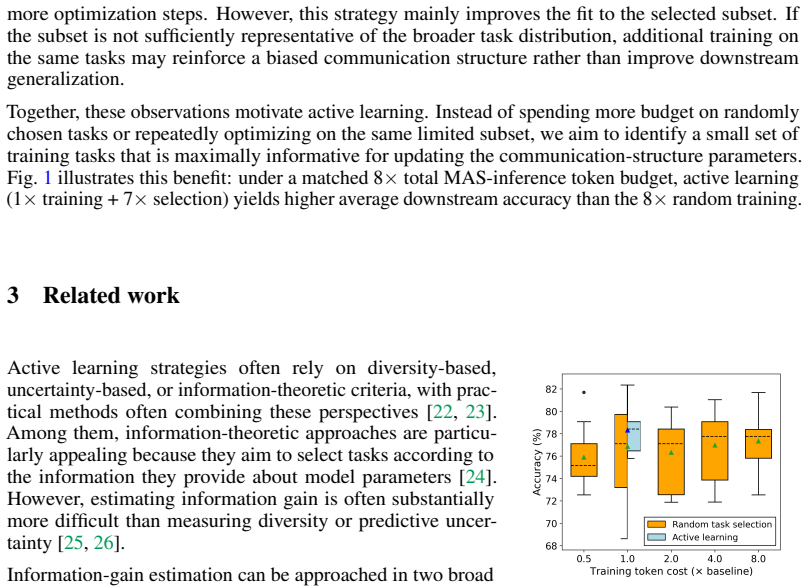
Overall, across the two commonly used ways to allocate an equal training budget, we consistently observe that active learning outperforms random task training. In addition, on MMLU we performed a sanity check by swapping the random-training repetition schedule from 20 tasks × 1 to 10 tasks × 2 while keeping the total task usages fixed. The random baseline...
work page 1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.