Recognition: unknown
Auto Research with Specialist Agents Develops Effective and Non-Trivial Training Recipes
Pith reviewed 2026-05-08 03:54 UTC · model grok-4.3
The pith
Specialist agents in a closed empirical loop use lineage feedback from evaluator outcomes to autonomously generate effective program-level edits that improve training recipes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that lineage feedback within a submitted-trial loop enables specialist agents to convert evaluator outcomes—including crashes, budget overruns, size failures, and accuracy misses—into later program-level recipe edits rather than isolated suggestions. Across 1,197 headline-run trials, the loop produces auditable trajectories of proposals, code diffs, and scores while applying and combining known techniques inside each environment. The same loop yields a 0.81% reduction in Parameter Golf validation bpb, a 38.7% rise in NanoChat-D12 CORE, and a 4.59% drop in CIFAR-10 Airbench96 wallclock time, all starting from public recipes and without human intervention during search.
What carries the argument
The submitted-trial loop, in which each trial carries a hypothesis, an executable code edit, an evaluator-owned outcome, and feedback that shapes the next proposal, with specialist agents partitioning recipe surfaces and sharing measured lineage across trials.
If this is right
- The loop autonomously writes code, submits experiments, absorbs feedback, and improves public starting recipes across distinct environments.
- The output is a complete auditable trajectory of proposals, diffs, scores, and failure labels rather than a single model checkpoint.
- The same submitted-trial structure handles architecture-domain changes such as attention-kernel path rewrites within a strict audit of 157 submissions.
- Each task is evaluated by its own external evaluator and legality checks with no human overrides after setup and launch.
Where Pith is reading between the lines
- The approach could be tested on larger-scale models or additional domains to determine whether the lineage mechanism continues to surface useful edits beyond the three reported tasks.
- If the pattern holds, the method might reduce reliance on manual hyperparameter and recipe tuning in routine machine-learning development.
- Combining the loop with broader search techniques could extend autonomous refinement from training recipes to other empirical research steps such as data selection or evaluation design.
Load-bearing premise
Specialist agents can reliably interpret diverse failure signals and lineage history to generate non-trivial, effective program-level code edits that produce generalizable improvements rather than overfitting to the specific trial set or evaluator quirks.
What would settle it
Re-running the identical loop on a fourth, previously unseen task or benchmark and checking whether the edited recipes deliver comparable gains or instead plateau or regress relative to the public starting points.
Figures













read the original abstract
We study auto research as a closed empirical loop driven by external measurement. Each submitted trial carries a hypothesis, an executable code edit, an evaluator-owned outcome, and feedback that shapes the next proposal. The output is not a generated paper or a single model checkpoint, but an auditable trajectory of proposals, code diffs, experiments, scores, and failure labels. We instantiate this loop with specialist agents that partition recipe surfaces and share measured lineage across trials. The central empirical finding is that lineage feedback lets agents turn evaluator outcomes, including crashes, budget overruns, size failures, and accuracy-gate misses, into later program-level recipe edits rather than one-shot suggestions. Across 1,197 headline-run trials plus 600 Parameter Golf control trials after one-time setup and launch, humans did not choose proposals, edit recipes, override scores, or repair failed trials during the search. In the three headline runs, the same submitted-trial loop reduces Parameter Golf validation bpb by $0.81\%$, raises NanoChat-D12 CORE by $38.7\%$, and reduces CIFAR-10 Airbench96 wallclock by $4.59\%$, with each task measured by its own external evaluator and legality checks. The trace includes a strict architecture-domain audit of 157 headline-run submissions and program rewrites such as a NanoChat attention-kernel path change. Within this scope the loop autonomously writes code, submits experiments, absorbs feedback, applies and combines known techniques inside each environment, and improves public starting recipes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes an auto-research framework in which specialist agents operate a closed empirical loop: each trial consists of a hypothesis, executable code edit, external-evaluator outcome, and lineage feedback that informs subsequent proposals. The central claim is that sharing measured lineage (including crashes, budget overruns, size failures, and accuracy misses) enables agents to produce non-trivial program-level recipe edits rather than one-shot suggestions. Across 1,197 headline trials plus 600 Parameter Golf controls, the loop is reported to improve three public starting recipes—reducing Parameter Golf validation bpb by 0.81 %, raising NanoChat-D12 CORE by 38.7 %, and cutting CIFAR-10 Airbench96 wall-clock by 4.59 %—with no human intervention in proposal selection, editing, or score repair, and with an auditable trace of 157 architecture-domain submissions.
Significance. If the central attribution holds, the work would constitute a concrete demonstration that multi-agent systems can autonomously discover and combine known techniques to improve training recipes on independent external benchmarks. Positive features include the use of external evaluators, the production of fully auditable trajectories of code diffs and failure labels, and the scale of experimentation (nearly 1,800 trials). These elements support reproducibility and transparency claims that are often missing from agentic-AI papers.
major comments (2)
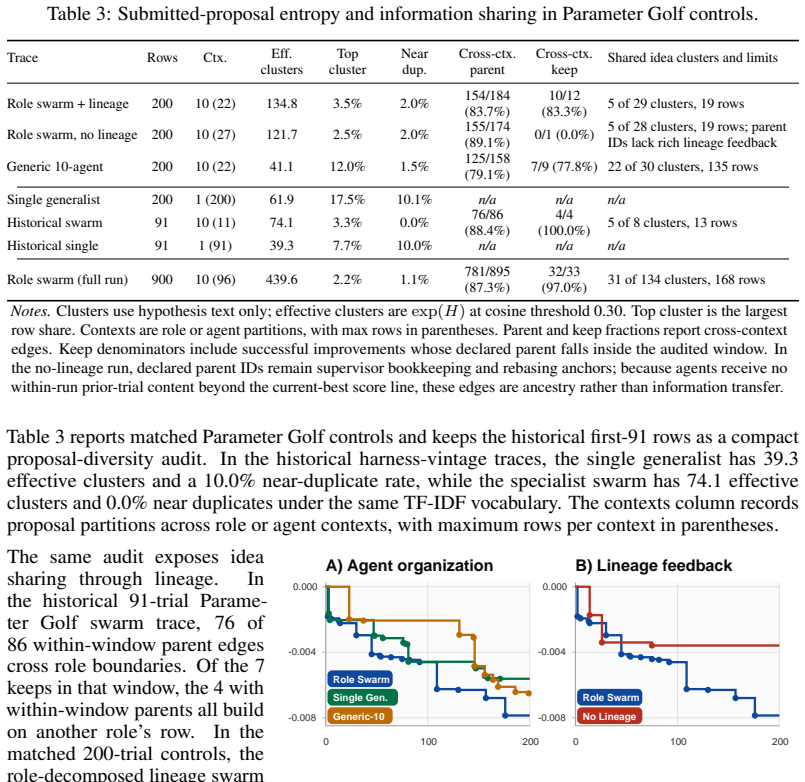
- The central empirical claim (Abstract) that lineage feedback enables agents to convert evaluator outcomes into effective program-level edits is not supported by an ablation that isolates history sharing from stateless independent proposals. The manuscript compares results only to the initial public recipes and does not describe a control arm in which the same specialist agents generate proposals without access to prior trial outcomes, failure labels, or shared lineage. Without this control, the reported deltas cannot be unambiguously attributed to lineage feedback rather than to repeated sampling or post-hoc selection of headline runs.
- Experimental Results section: the headline percentage improvements (0.81 % bpb, 38.7 % CORE, 4.59 % wall-clock) are presented without reported variance, statistical significance tests, or precise baseline definitions. The 600 Parameter Golf control trials are mentioned but their design (how they differ from the headline loop and whether they isolate the lineage variable) is not specified in sufficient detail to allow assessment of robustness.
minor comments (1)
- The abstract states that 'humans did not choose proposals, edit recipes, override scores, or repair failed trials' but does not clarify in the main text what the one-time setup and launch procedure entailed or how the specialist-agent partitioning of recipe surfaces was implemented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for clearer isolation of lineage feedback and improved statistical reporting. We address each major comment below and will revise the manuscript to strengthen these aspects while preserving the core claims supported by the existing experimental trace.
read point-by-point responses
-
Referee: The central empirical claim (Abstract) that lineage feedback enables agents to convert evaluator outcomes into effective program-level edits is not supported by an ablation that isolates history sharing from stateless independent proposals. The manuscript compares results only to the initial public recipes and does not describe a control arm in which the same specialist agents generate proposals without access to prior trial outcomes, failure labels, or shared lineage. Without this control, the reported deltas cannot be unambiguously attributed to lineage feedback rather than to repeated sampling or post-hoc selection of headline runs.
Authors: We acknowledge that a direct ablation isolating lineage sharing from stateless proposals would provide stronger causal attribution. The 600 Parameter Golf control trials were run with the same specialist agents but without persistent lineage access across trials (i.e., each proposal generated from the initial recipe only, with no failure labels or prior outcomes shared). However, we agree the manuscript does not describe this distinction with sufficient clarity. In revision we will expand the Experimental Results section with a dedicated subsection detailing the control design, including how stateless runs differ in prompt construction and memory. Given the scale (nearly 1800 total trials), we will also include a post-hoc analysis of proposal quality metrics (e.g., edit novelty and success rate) drawn from the existing logs to compare history-informed vs. stateless behavior, rather than re-running the full set. revision: partial
-
Referee: Experimental Results section: the headline percentage improvements (0.81 % bpb, 38.7 % CORE, 4.59 % wall-clock) are presented without reported variance, statistical significance tests, or precise baseline definitions. The 600 Parameter Golf control trials are mentioned but their design (how they differ from the headline loop and whether they isolate the lineage variable) is not specified in sufficient detail to allow assessment of robustness.
Authors: We will revise the Experimental Results section to report standard deviations and 95% confidence intervals for all headline deltas, computed across the multiple independent runs within each task. Statistical significance will be assessed via paired t-tests or bootstrap resampling against the initial public recipes, with exact p-values provided. Precise baseline definitions will be added, specifying the exact public starting recipes, evaluator versions, and hardware used for the 0.81%, 38.7%, and 4.59% figures. The 600 control trials will be described in detail, including their stateless design and how they serve as a repeated-sampling baseline. These additions will be placed in a new subsection on robustness and statistical analysis. revision: yes
Circularity Check
No circularity: empirical measurements on external benchmarks
full rationale
The paper reports direct experimental outcomes from 1,197 trials plus controls, using specialist agents in a closed loop with external evaluators on fixed benchmarks (Parameter Golf bpb, NanoChat CORE, CIFAR-10 wallclock). No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The central claim rests on measured deltas against public starting recipes and independent legality/accuracy checks, with no reduction of results to internal definitions or prior author work by construction. This is a standard non-circular empirical report.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption External evaluators supply reliable, unbiased outcomes including crashes, overruns, and performance metrics that can be directly used for recipe edits.
- domain assumption Specialist agents can partition recipe surfaces and combine techniques using shared lineage to produce non-trivial improvements.
Reference graph
Works this paper leans on
-
[1]
GitHub repository. Andrej Karpathy. nanoGPT. https://github.com/karpathy/nanoGPT , 2023. GitHub repository. Andrej Karpathy. nanochat: The best ChatGPT that $100 can buy. https://github.com/karpa thy/nanochat, 2025. GitHub repository. Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009. URL...
-
[2]
Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf
Online challenge description. Guilherme Penedo, Hynek Kydlíˇcek, Loubna Ben Allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro von Werra, and Thomas Wolf. The FineWeb datasets: Decanting the web for the finest text data at scale, 2024. Ben Rank, Hardik Bhatnagar, Ameya Prabhu, Shira Eisenberg, Karina Nguyen, Matthias Bethge, and Maksym Andrius...
2024
-
[3]
Esteban Real, Chen Liang, David R
doi: 10.1609/aaai.v33i01.33014780. Esteban Real, Chen Liang, David R. So, and Quoc V . Le. AutoML-zero: Evolving machine learning algorithms from scratch. InInternational Conference on Machine Learning, 2020. arXiv:2003.03384. Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R...
-
[4]
Read LEADERBOARD, KNOWLEDGE.md, and Recent Activity in the user message; identify the current best
-
[5]
Decide: mutate from the best, or rebase onto a non-best snapshot via rebase_to
-
[6]
Mutate train_gpt.py via Edit
-
[7]
Call syntax_check and size_project; fix and retry on failure
-
[8]
Call submit_trial with a one-sentence hypothesis and a signed expected_delta
-
[9]
One submit is a complete session; repeat from step 1 only if the returned row points to a specific next edit
Reflect on the result. One submit is a complete session; repeat from step 1 only if the returned row points to a specific next edit. Figure 4: Parameter Golf GLOBAL_RULES, abridged. The full source is in multi_agent_pg/agents/prompts.py. NanoChat-D12 and CIFAR have analogous global rules with task-specific limits (e.g. NC’s 90-minute pretraining cap, CIFA...
-
[10]
The set is task-specific and fixed before the reported run starts
Knowledge files.Static markdown documents under the task package’s knowledge/ directory, concatenated and pinned at the top of the system prompt so the Anthropic prompt cache can amortise them across sessions. The set is task-specific and fixed before the reported run starts
-
[11]
Defines hard limits, the tool protocol, and the per-session workflow
Global rules.A task-level protocol shared by every specialist on that task. Defines hard limits, the tool protocol, and the per-session workflow. Figure 4 reproduces the abridged Parameter Golf version
-
[12]
change one number
Domain preamble.A specialist-specific scope and edit-radius statement. Figures 5, 6, and 7 show three of the ten Parameter Golf preambles; the remaining seven and the NanoChat-D12 / CIFAR preambles follow the same structure (scope + non-scope + edit-radius guidance). The per-iterationuser messageis rendered fresh from the live blackboard at every session ...
2026
-
[13]
The current-best exp_id + score one-liner is preserved (the agent uses it to rootrebase_to)
Per-iteration prompt rendering.The user message rendered at every session start is short- circuited: the LEADERBOARD.md / KNOWLEDGE.md / Recent Activity / Saturation-warning sections are dropped. The current-best exp_id + score one-liner is preserved (the agent uses it to rootrebase_to). Figure 9 shows the resulting form. 21 Table 8: Full representative s...
-
[14]
read_snapshot and diff_snapshots are removed from allowed_tools andpreload_tools
Lineage-reading tools. read_snapshot and diff_snapshots are removed from allowed_tools andpreload_tools. rebase_to is preserved because it does not return prior-trialcontentto the agent — it copies code into the workdir using the already-known current-bestexp_id
-
[15]
Bash reads of blackboard files.The block_bash_blackboard PreToolUse hook (Section B) rejects Bash commands matching any of tree.tsv, results.tsv, lineage_snapshots/, events.jsonl, best.json, supervisor_audit.jsonl, or any path underblackboard/. This closes the in-practice dominant residual: an empirical audit of the lineage-on Parameter Golf run found tha...
work page doi:10.24432/c 2029
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.