Recognition: unknown
HyperLens: Quantifying Cognitive Effort in LLMs with Fine-grained Confidence Trajectory
Pith reviewed 2026-05-08 11:34 UTC · model grok-4.3
The pith
Deeper layers in LLMs magnify small layer-wise confidence changes into fine-grained trajectories that quantify higher cognitive effort for complex tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
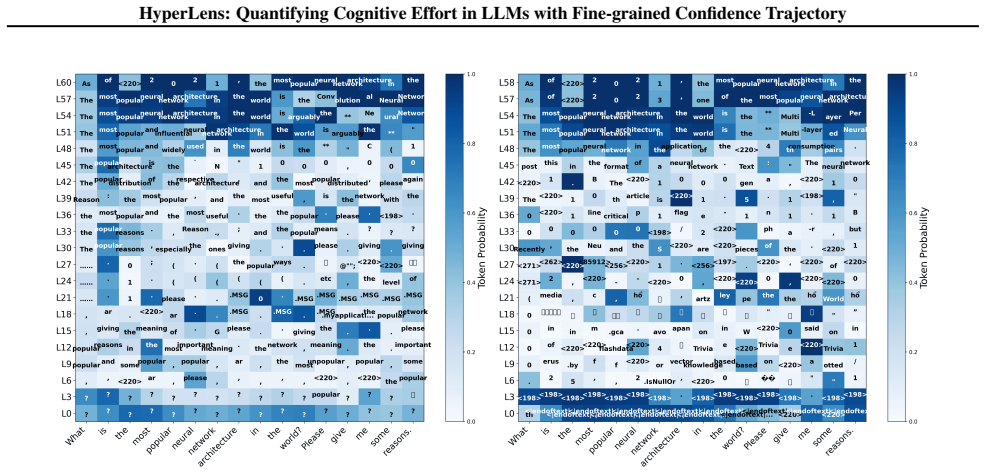
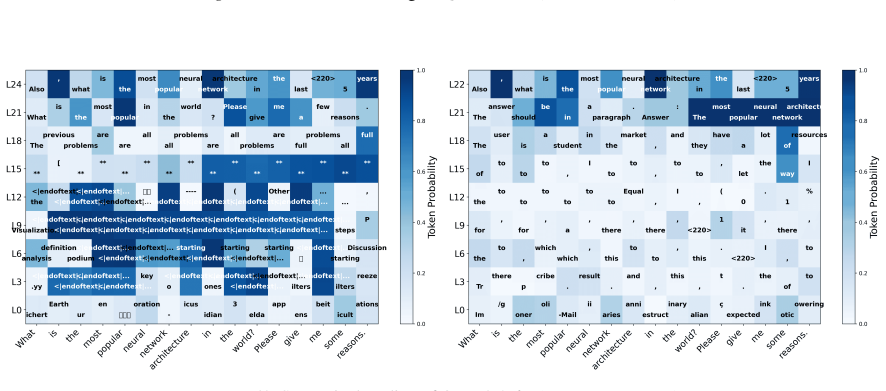
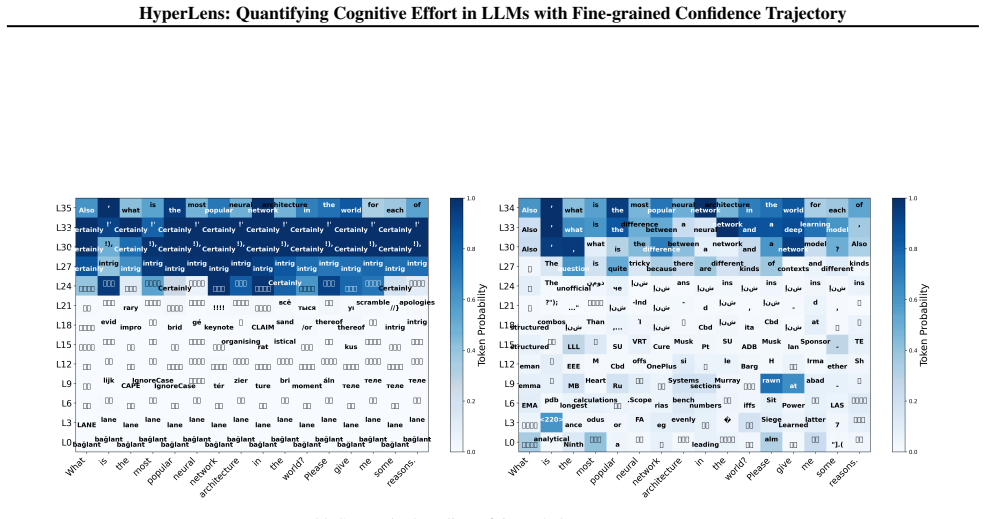
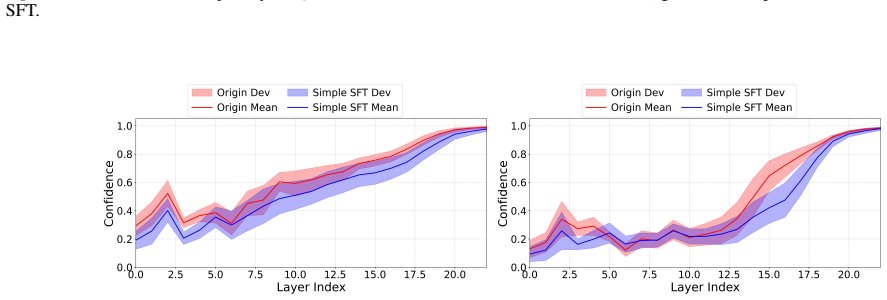
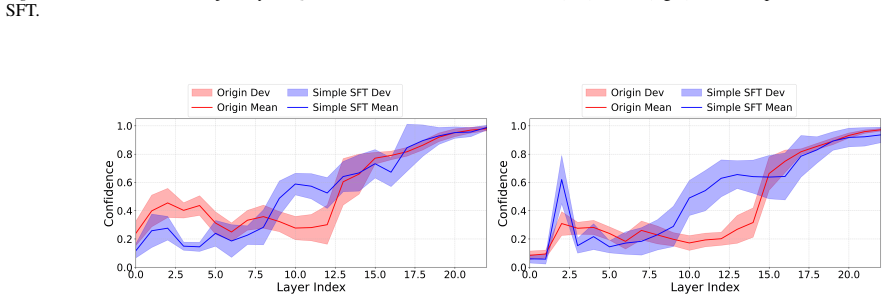
Deeper layers inherently magnify the small changes of layer-wise confidence, providing a fine-grained confidence trajectory. HyperLens traces these trajectories to quantify cognitive effort, revealing that complex tasks consistently require higher cognitive effort and that standard SFT can reduce cognitive effort thereby degrading in-domain performance.
What carries the argument
The intrinsic magnification mechanism in deeper transformer layers that amplifies layer-wise confidence changes into fine-grained trajectories.
If this is right
- Complex tasks can be identified by their elevated cognitive effort metrics from confidence trajectories.
- Standard SFT reduces cognitive effort, leading to performance degradation on in-domain tasks.
- Confidence trajectories offer a high-resolution view of inference dynamics separating task difficulties.
- The pattern holds consistently across different LLMs and datasets.
Where Pith is reading between the lines
- This mechanism could inform training techniques that maintain or increase cognitive effort to support better reasoning.
- Extending the probe to non-transformer architectures might test whether the magnification depends on depth in general.
- Real-time trajectory monitoring during inference could support dynamic adjustments for handling complex inputs.
Load-bearing premise
The observed differences in confidence trajectories reflect an intrinsic cognitive effort rather than being artifacts of how confidence is calculated or which tasks are selected.
What would settle it
Applying HyperLens across new LLMs and task sets and finding no consistent divergence separating complex from simple tasks by effort level, or controlled SFT experiments showing no performance degradation on in-domain tasks.
Figures



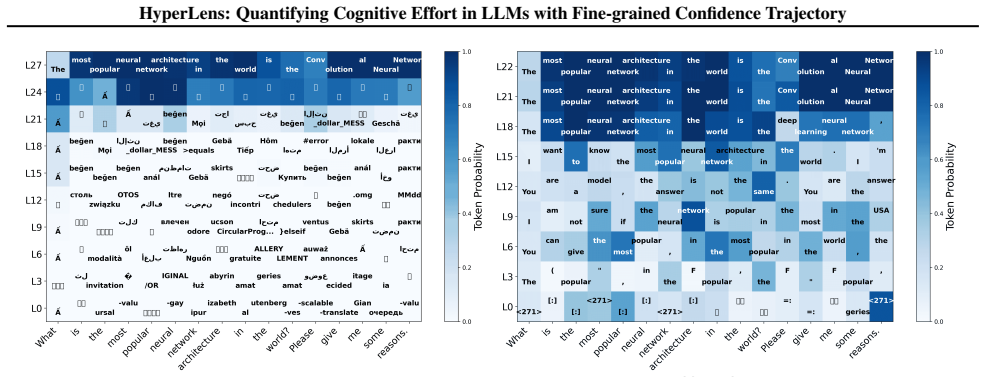

























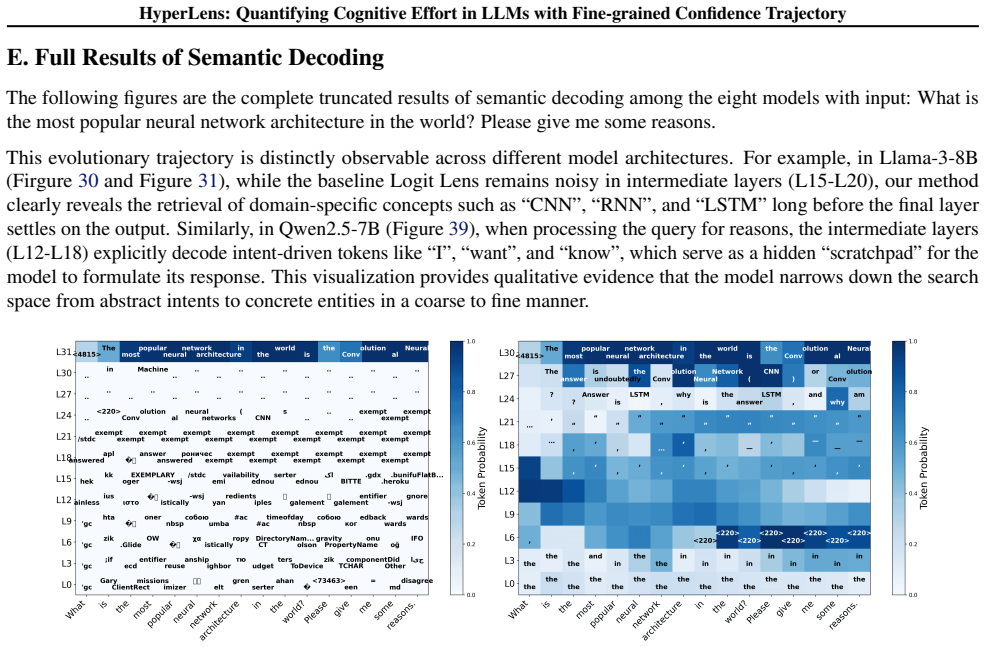
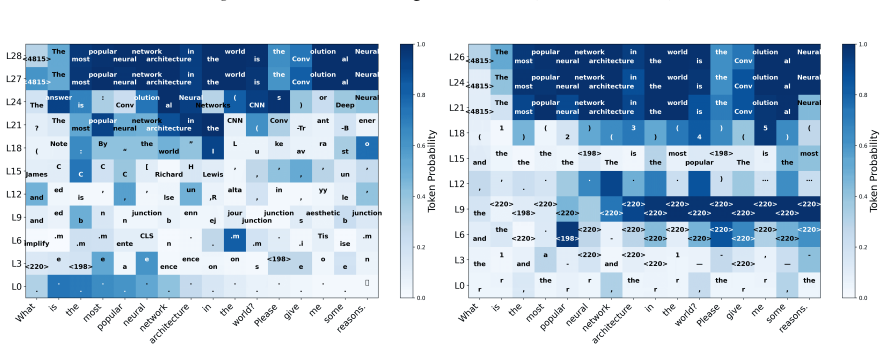






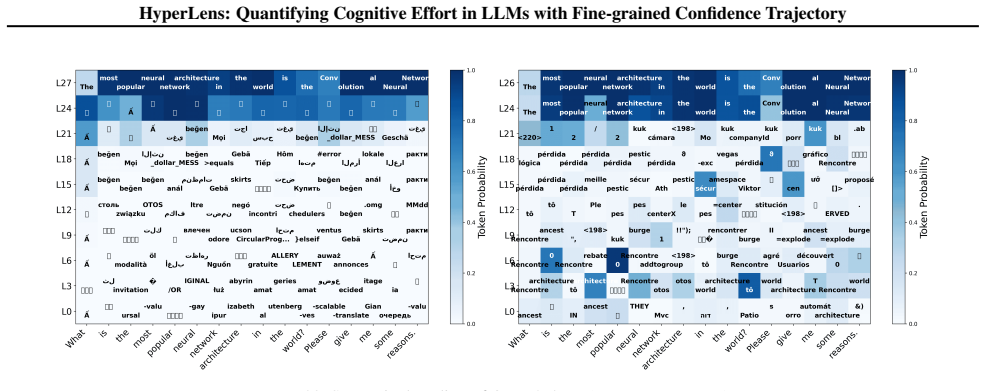















read the original abstract
While Large Language Models (LLMs) achieve strong performance across diverse tasks, their inference dynamics remain poorly understood because of the limited resolution of existing analysis tools. In this work, we identify an intrinsic magnification mechanism in transformer architectures: deeper layers inherently magnify the small changes of layer-wise confidence, providing a fine-grained confidence trajectory. Building on this insight, we introduce HyperLens, a high-resolution probe designed to trace confidence trajectories and quantify the cognitive effort during inference. Across LLMs and datasets, HyperLens reveals a consistent divergence in confidence trajectories that separates complex from simple tasks. We abstract this pattern into a quantitative cognitive effort metric. Our analysis reveals a fundamental principle: complex tasks consistently require higher cognitive effort. Finally, we provide a mechanistic diagnosis of a common side effect of standard Supervised Fine-Tuning (SFT): it can reduce cognitive effort and consequently degrade performance on in-domain tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperLens, a probe that traces layer-wise confidence trajectories in transformer-based LLMs. It claims an intrinsic magnification effect in deeper layers that amplifies small confidence changes into a fine-grained signal, from which a quantitative 'cognitive effort' metric is derived. Experiments across models and datasets reportedly show that complex tasks produce higher effort trajectories than simple ones, and that standard SFT reduces cognitive effort, thereby degrading in-domain performance.
Significance. If the confidence-trajectory metric can be shown to be robust and externally anchored, the work would supply a new mechanistic lens on inference dynamics and a concrete explanation for SFT side-effects. The absence of any reported quantitative results, controls, or robustness checks in the provided abstract, however, leaves the practical significance difficult to assess at present.
major comments (3)
- [Abstract] Abstract: the central claims of 'consistent divergence' separating complex from simple tasks and of a 'quantitative cognitive effort metric' are asserted without any numerical results, error bars, dataset sizes, or statistical controls. This directly undermines evaluation of the soundness of the magnification mechanism and the effort abstraction.
- [Abstract] The mapping of observed trajectory divergence to an intrinsic 'cognitive effort' quantity lacks the required external anchoring. No evidence is supplied that the metric (a) is stable under alternative layer-wise confidence definitions, (b) correlates with independent task-difficulty proxies, or (c) causally predicts the claimed performance degradation after SFT.
- [Abstract] The mechanistic diagnosis that SFT 'can reduce cognitive effort and consequently degrade performance on in-domain tasks' rests on the unvalidated effort metric. Without a controlled before/after comparison that isolates the effort reduction from other SFT effects (e.g., distribution shift or capacity changes), the causal link remains interpretive.
minor comments (1)
- [Abstract] The abstract repeatedly uses the phrase 'across LLMs and datasets' without specifying which models, datasets, or task categories were examined; this should be made concrete in the introduction or experimental section.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We have carefully considered each of the major comments regarding the abstract and will revise it to include quantitative results and clarify supporting evidence. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'consistent divergence' separating complex from simple tasks and of a 'quantitative cognitive effort metric' are asserted without any numerical results, error bars, dataset sizes, or statistical controls. This directly undermines evaluation of the soundness of the magnification mechanism and the effort abstraction.
Authors: We agree that the abstract would be strengthened by including key quantitative results. The full manuscript reports these details, including trajectory divergence metrics, dataset sizes, error bars, and statistical tests across models and tasks in Sections 4 and 5. In the revised version, we will update the abstract to incorporate specific numerical examples and controls to better substantiate the claims. revision: yes
-
Referee: [Abstract] The mapping of observed trajectory divergence to an intrinsic 'cognitive effort' quantity lacks the required external anchoring. No evidence is supplied that the metric (a) is stable under alternative layer-wise confidence definitions, (b) correlates with independent task-difficulty proxies, or (c) causally predicts the claimed performance degradation after SFT.
Authors: The manuscript includes ablations on alternative confidence definitions and correlations with task-difficulty proxies in the experimental sections and appendices. We acknowledge that the abstract does not explicitly reference this anchoring. We will revise the abstract to summarize these validations, including stability checks and correlations, to make the external support clearer. revision: yes
-
Referee: [Abstract] The mechanistic diagnosis that SFT 'can reduce cognitive effort and consequently degrade performance on in-domain tasks' rests on the unvalidated effort metric. Without a controlled before/after comparison that isolates the effort reduction from other SFT effects (e.g., distribution shift or capacity changes), the causal link remains interpretive.
Authors: We agree that the causal claim requires qualification. The paper presents before-and-after SFT comparisons showing effort reduction alongside performance changes. However, these do not fully isolate effort from other factors such as distribution shift. In the revision, we will add explicit discussion of this limitation and rephrase the claim to emphasize observed correlations rather than definitive causation. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents HyperLens and the cognitive effort metric as abstractions derived from empirical observations of layer-wise confidence trajectories and their divergence between task types. No equations, fitted parameters, self-citations, uniqueness theorems, or ansatzes are described in the abstract or summary that would reduce any claimed result to its own inputs by construction. The magnification mechanism is stated as an identified architectural property, and the final principle is framed as a revealed pattern rather than a tautological restatement enforced by definition. The derivation remains self-contained against external task benchmarks without internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Understanding intermediate layers using linear classifier probes
Understanding intermediate layers using linear classifier probes , author=. arXiv preprint arXiv:1610.01644 , year=
work page internal anchor Pith review arXiv
-
[2]
Computational Linguistics , volume=
Probing classifiers: Promises, shortcomings, and advances , author=. Computational Linguistics , volume=
-
[3]
2020 , howpublished =
Interpreting GPT: the logit lens , author =. 2020 , howpublished =
2020
-
[4]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review arXiv
-
[5]
ArXiv , author=
LogitLens4LLMs: Extending Logit Lens Analysis to Modern Large Language Models. ArXiv , author=
-
[6]
2016 23rd international conference on pattern recognition (ICPR) , pages=
Branchynet: Fast inference via early exiting from deep neural networks , author=. 2016 23rd international conference on pattern recognition (ICPR) , pages=. 2016 , organization=
2016
-
[7]
DeeBERT: dynamic early exiting for accelerating BERT inference.arXiv preprint arXiv:2004.12993, 2020
DeeBERT: Dynamic early exiting for accelerating BERT inference , author=. arXiv preprint arXiv:2004.12993 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Confident adaptive language modeling , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Unsupervised real-time hallucination detection based on the internal states of large language models , author=. arXiv preprint arXiv:2403.06448 , year=
-
[10]
arXiv preprint arXiv:2406.15765 (2024)
Unveiling and harnessing hidden attention sinks: Enhancing large language models without training through attention calibration , author=. arXiv preprint arXiv:2406.15765 , year=
-
[11]
BERT Rediscovers the Classical NLP Pipeline , publisher =
BERT rediscovers the classical NLP pipeline , author=. arXiv preprint arXiv:1905.05950 , year=
-
[12]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[13]
The bottom-up evolution of representations in the transformer: A study with machine translation and language modeling objectives , author=. arXiv preprint arXiv:1909.01380 , year=
-
[14]
arXiv preprint arXiv:2507.02199 , year=
Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer , author=. arXiv preprint arXiv:2507.02199 , year=
-
[15]
The geometry of truth: Emergent linear structure in large language model representations of true/false datasets , author=. arXiv preprint arXiv:2310.06824 , year=
work page internal anchor Pith review arXiv
-
[16]
Dola: Decoding by contrasting layers improves factuality in large language models
Dola: Decoding by contrasting layers improves factuality in large language models , author=. arXiv preprint arXiv:2309.03883 , year=
-
[17]
Efficient Streaming Language Models with Attention Sinks
Efficient streaming language models with attention sinks , author=. arXiv preprint arXiv:2309.17453 , year=
work page internal anchor Pith review arXiv
-
[18]
In-context Learning and Induction Heads
In-context learning and induction heads , author=. arXiv preprint arXiv:2209.11895 , year=
work page internal anchor Pith review arXiv
-
[19]
Bottom-up policy optimization: Your language model policy secretly contains internal policies
Bottom-up Policy Optimization: Your Language Model Policy Secretly Contains Internal Policies , author=. arXiv preprint arXiv:2512.19673 , year=
-
[20]
2023 ieee conference on secure and trustworthy machine learning (satml) , pages=
Toward transparent ai: A survey on interpreting the inner structures of deep neural networks , author=. 2023 ieee conference on secure and trustworthy machine learning (satml) , pages=. 2023 , organization=
2023
-
[21]
Distill , volume=
Zoom in: An introduction to circuits , author=. Distill , volume=
-
[22]
Exploiting Contextual Knowledge in LLMs through
Yuan, Xiaowei and Yang, Zhao and Huang, Ziyang and Wang, Yequan and Fan, Siqi and Ju, Yiming and Zhao, Jun and Liu, Kang , booktitle=. Exploiting Contextual Knowledge in LLMs through
-
[23]
arXiv preprint arXiv:2601.03600 , year=
ALERT: Zero-shot LLM Jailbreak Detection via Internal Discrepancy Amplification , author=. arXiv preprint arXiv:2601.03600 , year=
-
[24]
arXiv preprint arXiv:2506.13901 , year=
Alignment Quality Index (AQI): Beyond Refusals: AQI as an Intrinsic Alignment Diagnostic via Latent Geometry, Cluster Divergence, and Layer wise Pooled Representations , author=. arXiv preprint arXiv:2506.13901 , year=
-
[25]
arXiv preprint arXiv:2503.09066 , year=
Probing latent subspaces in llm for ai security: Identifying and manipulating adversarial states , author=. arXiv preprint arXiv:2503.09066 , year=
-
[26]
Ee-llm: Large-scale training and inference of early-exit large language models with 3d parallelism , author=. arXiv preprint arXiv:2312.04916 , year=
-
[27]
arXiv preprint arXiv:2311.04897 , year=
Future lens: Anticipating subsequent tokens from a single hidden state , author=. arXiv preprint arXiv:2311.04897 , year=
-
[28]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings , author=. arXiv preprint arXiv:1909.00512 , year=
-
[29]
All bark and no bite: Rogue dimensions in transformer language models obscure representational quality , author=. arXiv preprint arXiv:2109.04404 , year=
-
[30]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned , author=. arXiv preprint arXiv:1905.09418 , year=
work page Pith review arXiv 1905
-
[31]
arXiv preprint arXiv:1909.03368 , year=
Designing and interpreting probes with control tasks , author=. arXiv preprint arXiv:1909.03368 , year=
-
[32]
arXiv preprint arXiv:2003.12298 , year=
Information-theoretic probing with minimum description length , author=. arXiv preprint arXiv:2003.12298 , year=
-
[33]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review arXiv
-
[34]
Representation degeneration problem in training natural language generation models , author=. arXiv preprint arXiv:1907.12009 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
Signal propagation in transformers: Theoretical perspectives and the role of rank collapse , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Massive activations in large language models , author=. arXiv preprint arXiv:2402.17762 , year=
-
[37]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review arXiv
-
[38]
Proceedings of the 15th international conference on mining software repositories , pages=
Learning to mine aligned code and natural language pairs from stack overflow , author=. Proceedings of the 15th international conference on mining software repositories , pages=
-
[39]
Measuring Coding Challenge Competence With APPS
Measuring coding challenge competence with apps , author=. arXiv preprint arXiv:2105.09938 , year=
work page internal anchor Pith review arXiv
-
[40]
arXiv preprint arXiv:2002.05867 , year=
Transformers as soft reasoners over language , author=. arXiv preprint arXiv:2002.05867 , year=
-
[41]
arXiv preprint arXiv:2404.15522 , year=
Logicbench: Towards systematic evaluation of logical reasoning ability of large language models , author=. arXiv preprint arXiv:2404.15522 , year=
-
[42]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
work page internal anchor Pith review arXiv
-
[43]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[44]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review arXiv
-
[45]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review arXiv
-
[46]
Towards ai-complete question answering: A set of prerequisite toy tasks
Towards ai-complete question answering: A set of prerequisite toy tasks , author=. arXiv preprint arXiv:1502.05698 , year=
-
[47]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Can a suit of armor conduct electricity? a new dataset for open book question answering , author=. arXiv preprint arXiv:1809.02789 , year=
work page internal anchor Pith review arXiv
-
[48]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[49]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[50]
Qwen2.5-Coder Technical Report
Qwen2. 5-coder technical report , author=. arXiv preprint arXiv:2409.12186 , year=
work page internal anchor Pith review arXiv
-
[51]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review arXiv
-
[52]
Zebralogic: On the scaling limits of llms for logical reasoning
Zebralogic: On the scaling limits of llms for logical reasoning , author=. arXiv preprint arXiv:2502.01100 , year=
-
[53]
Transformer Circuits Thread , volume=
A mathematical framework for transformer circuits , author=. Transformer Circuits Thread , volume=
-
[54]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation engineering: A top-down approach to ai transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[55]
arXiv preprint arXiv:2304.13734 , year=
The internal state of an LLM knows when it's lying , author=. arXiv preprint arXiv:2304.13734 , year=
-
[56]
Advances in Neural Information Processing Systems , volume=
Inference-time intervention: Eliciting truthful answers from a language model , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
American Invitational Mathematics Examination ---
Wikipedia contributors. American Invitational Mathematics Examination ---. 2025 , howpublished =
2025
-
[58]
Advances in Neural Information Processing Systems , volume=
Transformers represent belief state geometry in their residual stream , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Dissecting the interplay of attention paths in a statistical mechanics theory of transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Advances in Neural Information Processing Systems , volume=
Improving sparse decomposition of language model activations with gated sparse autoencoders , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
Advances in Neural Information Processing Systems , volume=
Knowledge circuits in pretrained transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
How do Transformers Learn Implicit Reasoning? , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[63]
International Conference on Machine Learning , pages=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[64]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Llamafactory: Unified efficient fine-tuning of 100+ language models , author=. arXiv preprint arXiv:2403.13372 , year=
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.