Recognition: unknown
X-OmniClaw Technical Report: A Unified Mobile Agent for Multimodal Understanding and Interaction
Pith reviewed 2026-05-08 14:49 UTC · model grok-4.3
The pith
X-OmniClaw presents a unified architecture for mobile agents that combines multimodal perception, memory, and action to handle complex Android tasks with greater context awareness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The unified architecture of perception, memory, and action enables the agent to handle complex mobile tasks with high contextual awareness, as the temporal alignment of multimodal inputs, optimized personal memory, and hybrid grounding plus behavior cloning produce more efficient and reliable interactions.
What carries the argument
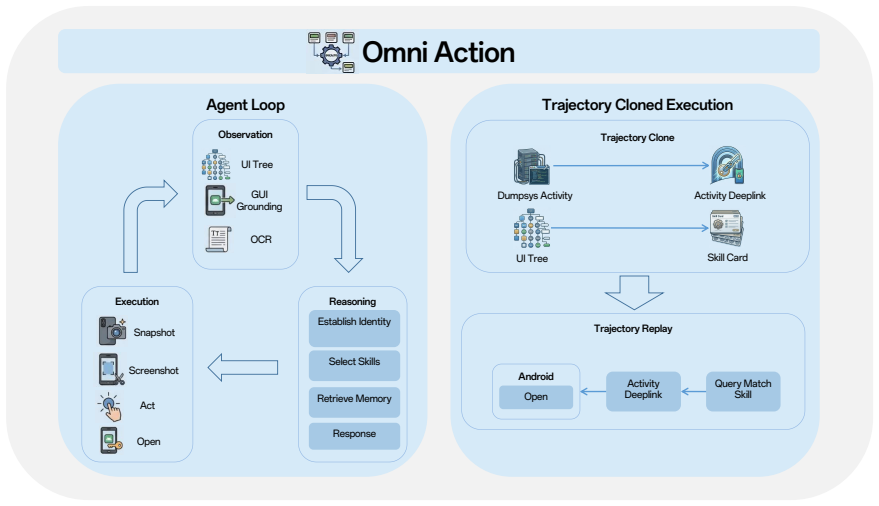
The Omni architecture with its perception pipeline (multimodal ingress and temporal alignment), memory system (runtime working memory fused with distilled long-term personal memory), and action layer (hybrid XML-visual grounding supported by behavior cloning and trajectory replay).
If this is right
- Navigation sequences can be recorded once and executed later as reusable direct-access skills without repeated manual steps.
- Interactions become more personalized because long-term memory distilled from local device data supplies context that persists across sessions.
- Command grounding stays robust by blending structural screen metadata with visual scene understanding when one source is incomplete.
- Raw sensor streams from UI, camera, and microphone are reduced to compact intent representations that preserve timing relationships.
Where Pith is reading between the lines
- The local-memory design could lower cloud dependency and therefore reduce data transmission costs, though it would require testing how much on-device compute the memory optimization actually consumes.
- Behavior cloning from individual users might create agents that adapt to personal habits more closely than generic assistants, opening the possibility of skill libraries shared across a household while keeping profiles separate.
- If the hybrid grounding proves stable, similar patterns could be applied to other platforms where apps expose both layout trees and visual content, such as desktop environments or automotive interfaces.
Load-bearing premise
The perception, memory, and action components will integrate and operate reliably under real-world mobile conditions.
What would settle it
A controlled test that measures task success rate and completion time for X-OmniClaw against standard Android assistants on a fixed set of multimodal tasks such as composing and sending a message while consulting calendar and map data.
Figures






read the original abstract
Inspired by the development of OpenClaw, there is a growing demand for mobile-based personal agents capable of handling complex and intuitive interactions. In this technical report, we introduce X-OmniClaw, a unified mobile agent designed for multimodal understanding and interaction in the Android ecosystem. This unified architecture of perception, memory, and action enables the agent to handle complex mobile tasks with high contextual awareness. Specifically, Omni Perception provides a unified multimodal ingress pipeline that integrates UI states, real-world visual contexts, and speech inputs, leveraging a temporal alignment module to decompose raw data into structured multimodal intent representations. Omni Memory leverages multimodal memory optimization to enhance personalized intelligence by integrating runtime working memory for task continuity with long-term personal memory distilled from local data, enabling highly context-aware and personalized interactions. Finally, Omni Action employs a hybrid grounding strategy that combines structural XML metadata with visual perception for robust interaction. Through Behavior Cloning and Trajectory Replay, the system captures user navigation as reusable skills, enabling precise direct-access execution. Demonstrations across diverse scenarios show that X-OmniClaw effectively enhances interaction efficiency and task reliability, providing a practical architectural blueprint for the next generation of mobile-native personal assistants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents X-OmniClaw as a unified mobile agent architecture for the Android ecosystem, consisting of Omni Perception (unified multimodal ingress with temporal alignment for UI states, visual contexts, and speech), Omni Memory (runtime working memory combined with long-term personal memory distilled from local data), and Omni Action (hybrid XML metadata plus visual grounding, augmented by Behavior Cloning and Trajectory Replay to capture reusable navigation skills). The central claim is that demonstrations across diverse scenarios show the system enhances interaction efficiency and task reliability, serving as a practical blueprint for mobile-native personal assistants.
Significance. The architectural description outlines a coherent multimodal integration strategy that could inform future mobile agent designs if the components prove robust. However, the absence of any quantitative evaluation, baselines, or failure analysis means the claimed benefits cannot be assessed against existing systems such as OpenClaw, limiting the work's immediate contribution to the field.
major comments (1)
- [Abstract] Abstract: The claim that 'Demonstrations across diverse scenarios show that X-OmniClaw effectively enhances interaction efficiency and task reliability' is unsupported by any reported metrics, success rates, latency figures, user-study results, comparisons to baselines, or error analysis. This assertion is load-bearing for the paper's contribution and cannot be evaluated from the provided architectural description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our technical report. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Demonstrations across diverse scenarios show that X-OmniClaw effectively enhances interaction efficiency and task reliability' is unsupported by any reported metrics, success rates, latency figures, user-study results, comparisons to baselines, or error analysis. This assertion is load-bearing for the paper's contribution and cannot be evaluated from the provided architectural description alone.
Authors: We agree that the abstract's phrasing asserts performance benefits without supporting quantitative evidence, which is a valid concern. As this is a technical report centered on architectural design rather than empirical benchmarking, the referenced demonstrations are qualitative illustrations of the Omni Perception, Memory, and Action modules operating in diverse Android scenarios. To address the issue directly, we will revise the abstract to remove the unsupported claim and instead state that the demonstrations illustrate the architecture's multimodal integration capabilities and potential for context-aware interactions. We will also add a brief clarification in the manuscript (e.g., in the introduction or a new limitations paragraph) noting that formal quantitative evaluations, baselines, and failure analyses are beyond the current scope and reserved for future work. This revision aligns the paper's claims with its content as an architectural blueprint. revision: yes
Circularity Check
No circularity: purely descriptive architecture report with no derivations or fitted predictions
full rationale
The paper is a high-level technical report describing an agent architecture (Omni Perception with temporal alignment, Omni Memory with multimodal optimization, Omni Action with hybrid grounding plus Behavior Cloning/Trajectory Replay). No equations, parameters, predictions, or quantitative claims appear that could reduce to inputs by construction. Effectiveness assertions rest on unspecified demonstrations, which is an evidence gap rather than circular reasoning. No self-citations, uniqueness theorems, or ansatzes are load-bearing. This is the expected non-finding for a descriptive systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hermes agent vs openclaw 2026: Memory, ecosystem, integrations & self-improvement
a2a mcp. Hermes agent vs openclaw 2026: Memory, ecosystem, integrations & self-improvement. https:// a2a-mcp.org/blog/hermes-agent-vs-openclaw, 2026. 2
2026
-
[2]
Wuying cloud phone
Alibaba Cloud. Wuying cloud phone. https://www.aliyun.com/product/cloud-phone, 2026. Retrieved from Alibaba Cloud Official Product Page. 2
2026
-
[3]
Hao Bai et al. Digirl: Training in-the-wild device-control agents with autonomous reinforcement learning.arXiv preprint arXiv:2406.11896, 2024. 2
-
[4]
Hermes agent: Persistent memory and emergent skills in an open-source ai agent framework
Evean66. Hermes agent: Persistent memory and emergent skills in an open-source ai agent framework. https: //pickaxe.co/post/hermes-agent-persistent-memory-and-emergent-skills, 2026. 2
2026
-
[5]
AppAgent: Multimodal agents as smartphone users,
Yucheng Han et al. Appagent: Multimodal agents as smartphone users.arXiv preprint arXiv:2312.13771, 2023. 2
-
[6]
Hermes agent architecture documentation
NousResearch. Hermes agent architecture documentation. https://hermes-agent.nousresearch.com/ docs/developer-guide/architecture/, 2026. 2
2026
-
[7]
Hermes agent: Persistent memory and emergent skills in an open-source ai agent framework
NousResearch. Hermes agent: Persistent memory and emergent skills in an open-source ai agent framework. https: //github.com/NousResearch/hermes-agent, 2026. Version v2026.3.23. 2
2026
-
[8]
Openclaw
OpenClaw. Openclaw. https://github.com/openclaw/openclaw, 2026. GitHub repository, accessed 2026-04-13. 1, 2
2026
-
[9]
Openclaw memory concept documentation
OpenClaw. Openclaw memory concept documentation. https://github.com/openclaw/openclaw/ blob/main/docs/concepts/memory.md, 2026. Project documentation, accessed 2026-04-13. 2
2026
-
[10]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326,
work page internal anchor Pith review arXiv
-
[11]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Christopher Rawles et al. Androidworld: A dynamic benchmarking environment for autonomous agents.arXiv preprint arXiv:2405.14573, 2025. 2
work page internal anchor Pith review arXiv 2025
-
[12]
Android in the wild: A large-scale dataset for android device control
Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy Lillicrap. Android in the wild: A large-scale dataset for android device control.arXiv preprint arXiv:2307.10088, 2023. 2
-
[13]
Redfinger cloud phone
RedFinger. Redfinger cloud phone. https://www.gc.com.cn/, 2026. Retrieved from RedFinger Official Website. 2
2026
-
[14]
Hermesapp
SelectXn00b. Hermesapp. https://github.com/SelectXn00b/HermesApp, 2026. GitHub repository, accessed 2026-04-23. 2
2026
-
[15]
Cloud virtual phone (cvp)
Tencent Cloud. Cloud virtual phone (cvp). https://cloud.tencent.cn/document/product/1801,
-
[16]
Retrieved from Tencent Cloud Official Document. 2
-
[17]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[18]
Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-agent: Autonomous multi-modal mobile device agent with visual perception.arXiv preprint arXiv:2401.16158, 2024. 2
-
[19]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. Os-atlas: A foundation action model for generalist gui agents.arXiv preprint arXiv:2410.23218, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[20]
OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. arXiv preprint arXiv:2...
work page internal anchor Pith review arXiv 2024
-
[21]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[22]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 2 12
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.