Recognition: unknown
Priming, Path-dependence, and Plasticity: Understanding the molding of user-LLM interaction and its implications from (many) chat logs in the wild
Pith reviewed 2026-05-08 07:29 UTC · model grok-4.3
The pith
LLM users quickly lock in interaction patterns from their first few sessions rather than adapting continuously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through analysis of 140K sessions, interaction patterns form and stabilize rapidly through individual early trajectories. Longitudinal outcomes such as recurring text patterns and retention rates are strongly correlated with early exploration. Parallel dynamics appear, including organization by task types such as emotional support and adjustments to model-version updates. Despite unconstrained input spaces, users exhibit less exploration, creating an agency paradox that calls for design attention to the molding process.
What carries the argument
The molding procedure, in which early user trajectories rapidly prime and path-dependently stabilize interaction patterns that persist across later sessions.
If this is right
- Early exploration levels can forecast recurring prompt styles and user retention over longer periods.
- Interaction patterns organize around task categories such as emotional support and shift when models update.
- The observed rapid stabilization implies that the first few sessions exert outsized influence on ongoing use.
- Designers should incorporate awareness of the molding process when building or iterating on LLM interfaces.
Where Pith is reading between the lines
- Interfaces could deliberately guide or vary early sessions to steer long-term patterns toward desired behaviors.
- The stabilization dynamic may resemble habit formation seen in other digital tools and could be tested by measuring prompt similarity metrics across sessions.
- Future work might examine whether targeted early interventions reduce the agency paradox by increasing sustained exploration.
Load-bearing premise
Correlations between early exploration and later outcomes are caused by initial trajectories shaping behavior rather than by stable user traits, fixed task types, or selection effects in the data.
What would settle it
A randomized trial that assigns different early interaction prompts to new users and tracks whether their later exploration volume, pattern stability, and retention rates diverge as the early-trajectory hypothesis predicts.
Figures


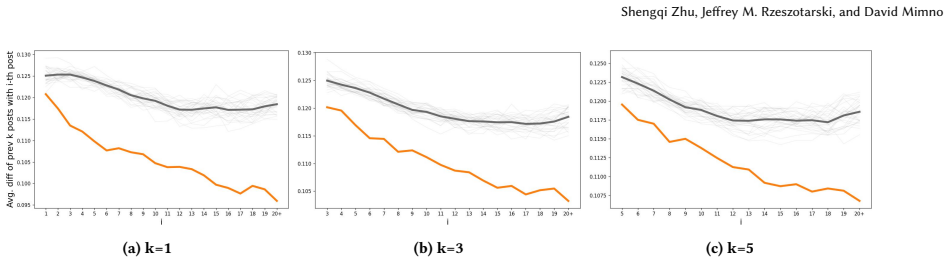
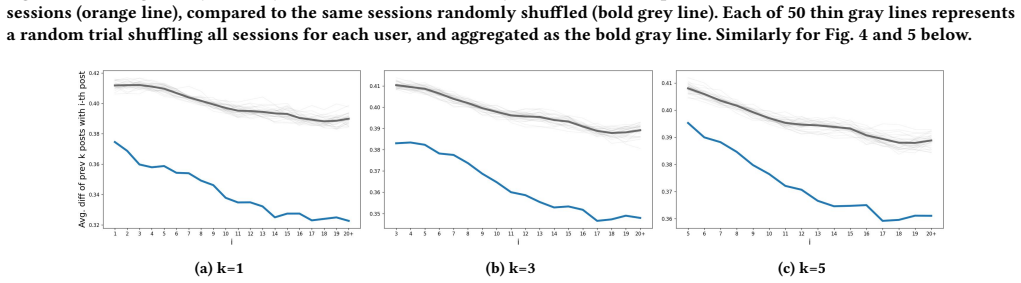








read the original abstract
User interactions with LLMs are shaped by prior experiences and individual exploration, but in-lab studies do not provide system designers with visibility into these in-the-wild factors. This work explores a new approach to studying real-world user-LLM interactions through large-scale chat logs from the wild. Through analysis of 140K chatbot sessions from 7,955 anonymized global users over time, we demonstrate key patterns in user expressions despite varied tasks: (1) LLM users are not tabula rasa, nor are they constantly adapting; rather, interaction patterns form and stabilize rapidly through individual early trajectories; (2) Longitudinal outcomes, such as recurring text patterns and retention rates, are strongly correlated with early exploration; (3) Parallel dynamics are present, including organizing expressions by task types such as emotional support, or in response to model-version updates. These results present an ``agency paradox'': despite LLM input spaces being unconstrained and user-driven, we in fact see less user exploration. We call for design consideration surrounding the molding procedure and its incorporation in future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 140K chatbot sessions from 7,955 anonymized global users to argue that LLM interaction patterns form and stabilize rapidly via individual early trajectories rather than constant adaptation or tabula rasa starting points. It reports strong correlations between early exploration levels and longitudinal outcomes including recurring text patterns and retention rates, identifies parallel dynamics by task type and model version, and highlights an 'agency paradox' of reduced exploration despite unconstrained input spaces, calling for design attention to the molding process.
Significance. The scale of the in-the-wild chat-log dataset is a clear strength and offers a valuable complement to lab studies for understanding real user-LLM dynamics in HCI. If the reported correlations can be shown to survive appropriate controls, the path-dependence and plasticity findings would have direct implications for interface design and retention strategies. The work also surfaces an interesting tension between user agency and observed stabilization that merits further investigation.
major comments (2)
- [Results and longitudinal analysis] The central claim that early trajectories causally mold later patterns (recurring text, retention) rests on observational correlations without reported user-level fixed effects, propensity matching, or controls for time-invariant traits such as baseline verbosity or task-complexity preferences. The skeptic note correctly flags that stable user characteristics or selection effects could drive both early exploration and outcomes; this is load-bearing for the molding interpretation and must be addressed with explicit robustness checks or within-user analysis.
- [Methods and abstract] The abstract and main text provide no details on the operationalization of 'exploration,' the statistical models used, handling of confounders (e.g., session length, model-version effects already noted), or any robustness checks. Without these, it is impossible to evaluate whether the data rigorously support the stabilization and correlation claims as stated.
minor comments (2)
- [Introduction and discussion] The 'agency paradox' is introduced as a key framing but would benefit from a brief explicit definition and relation to existing HCI literature on user adaptation and path dependence.
- [Figures and tables] Figure and table captions should include sample sizes, time windows, and exact definitions of the plotted quantities to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key opportunities to improve methodological transparency and interpretive caution in our observational analysis of in-the-wild LLM chat logs. We respond point-by-point below and outline targeted revisions.
read point-by-point responses
-
Referee: The central claim that early trajectories causally mold later patterns (recurring text, retention) rests on observational correlations without reported user-level fixed effects, propensity matching, or controls for time-invariant traits such as baseline verbosity or task-complexity preferences. The skeptic note correctly flags that stable user characteristics or selection effects could drive both early exploration and outcomes; this is load-bearing for the molding interpretation and must be addressed with explicit robustness checks or within-user analysis.
Authors: We agree the analysis is observational and does not establish causality; the manuscript frames results as correlations and descriptive stabilization patterns rather than causal molding. To strengthen robustness, the revision will add user-level fixed effects for the subset of users with repeated sessions, controls for baseline verbosity and session length in all regression models, and sensitivity analyses for selection effects. Propensity matching is not feasible given the continuous exploration measures and lack of discrete treatment assignment in this dataset, but we will discuss this limitation explicitly and report alternative specifications. revision: partial
-
Referee: The abstract and main text provide no details on the operationalization of 'exploration,' the statistical models used, handling of confounders (e.g., session length, model-version effects already noted), or any robustness checks. Without these, it is impossible to evaluate whether the data rigorously support the stabilization and correlation claims as stated.
Authors: We acknowledge this omission limits evaluability. The revised manuscript will expand the abstract to summarize the exploration measure and core models, and will add a dedicated Methods subsection detailing: operationalization of exploration (topic entropy and lexical diversity in the first three sessions), statistical approaches (mixed-effects regressions and survival models for retention), confounder handling (session length, model version, and task type as covariates), and all robustness checks performed. These changes will enable full assessment of the claims. revision: yes
Circularity Check
No circularity: empirical observational analysis of chat logs with direct pattern extraction
full rationale
The paper conducts a descriptive empirical study of 140K sessions from 7,955 users, extracting patterns such as rapid stabilization of interaction trajectories and correlations with longitudinal outcomes like text recurrence and retention. No equations, fitted parameters, predictions derived from models, or self-citations appear as load-bearing elements in the derivation chain. All reported findings rest on direct measurement from anonymized logs without reduction to self-definitions, ansatzes, or renamed known results. The analysis is self-contained against external benchmarks as a straightforward observational report.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anonymized global chat logs accurately reflect authentic user interaction patterns without significant distortion from data collection or user awareness of logging.
invented entities (1)
-
agency paradox
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gardênia da Silva Abbad and Mary Sandra Carlotto. 2016. Analyzing challenges associated with the adoption of longitudinal studies in Work and Organizational Psychology.Revista Psicologia Organizações e Trabalho16, 4 (2016), 340–348
2016
-
[2]
2000.Illocutionary acts and sentence meaning
William P Alston. 2000.Illocutionary acts and sentence meaning. Cornell university press
2000
- [3]
-
[4]
John R Anderson. 1982. Acquisition of cognitive skill.Psychological review89, 4 (1982), 369
1982
-
[5]
Ian Arawjo, Chelse Swoopes, Priyan Vaithilingam, Martin Wattenberg, and Elena L. Glassman. 2024. ChainForge: A Visual Toolkit for Prompt Engineering and LLM Hypothesis Testing. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 304, 18 ...
-
[6]
W Brian Arthur. 1989. Competing technologies, increasing returns, and lock-in by historical events.The economic journal99, 394 (1989), 116–131
1989
-
[7]
1975.How to do things with words
John Langshaw Austin. 1975.How to do things with words. Harvard university press
1975
-
[8]
James, and Nadia Polikarpova
Shraddha Barke, Michael B. James, and Nadia Polikarpova. 2023. Grounded Copilot: How Programmers Interact with Code-Generating Models.Proc. ACM Program. Lang.7, OOPSLA1, Article 78 (April 2023), 27 pages. doi:10.1145/ 3586030
2023
-
[9]
Yasmine Belghith, Atefeh Mahdavi Goloujeh, Brian Magerko, Duri Long, Tom Mcklin, and Jessica Roberts. 2024. Testing, Socializing, Exploring: Characterizing Middle Schoolers’ Approaches to and Conceptions of ChatGPT. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machine...
-
[11]
1987.Politeness: Some universals in language usage
Penelope Brown and Stephen C Levinson. 1987.Politeness: Some universals in language usage. Vol. 4. Cambridge university press
1987
-
[12]
Card, Allen Newell, and Thomas P
Stuart K. Card, Allen Newell, and Thomas P. Moran. 1983.The Psychology of Human-Computer Interaction. L. Erlbaum Associates Inc., USA
1983
-
[13]
Carroll and Mary Beth Rosson
John M. Carroll and Mary Beth Rosson. 1987.Paradox of the active user. MIT Press, Cambridge, MA, USA, 80–111
1987
-
[14]
Alan Chamberlain, Andy Crabtree, Tom Rodden, Matt Jones, and Yvonne Rogers
-
[15]
Research in the wild: understanding ’in the wild’ approaches to design and development. InProceedings of the Designing Interactive Systems Conference (Newcastle Upon Tyne, United Kingdom)(DIS ’12). Association for Computing Machinery, New York, NY, USA, 795–796. doi:10.1145/2317956.2318078
-
[16]
John Chen, Xi Lu, Yuzhou Du, Michael Rejtig, Ruth Bagley, Mike Horn, and Uri Wilensky. 2024. Learning Agent-based Modeling with LLM Companions: Expe- riences of Novices and Experts Using ChatGPT & NetLogo Chat. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, N...
-
[17]
Ruijia Cheng, Alison Smith-Renner, Ke Zhang, Joel Tetreault, and Alejandro Jaimes-Larrarte. 2022. Mapping the Design Space of Human-AI Interaction in Text Summarization. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Marie-Catherine de Marnef...
-
[18]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. 2024. Chatbot arena: An open platform for evaluating llms by human preference. InForty-first International Conference on Machine Learning
2024
-
[19]
Michelle Cohn, Mahima Pushkarna, Gbolahan O. Olanubi, Joseph M. Moran, Daniel Padgett, Zion Mengesha, and Courtney Heldreth. 2024. Believing An- thropomorphism: Examining the Role of Anthropomorphic Cues on Trust in Large Language Models. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI EA ’24). Asso-...
-
[20]
Katherine M. Collins, Albert Q. Jiang, Simon Frieder, Lionel Wong, Miri Zilka, Umang Bhatt, Thomas Lukasiewicz, Yuhuai Wu, Joshua B. Tenen- baum, William Hart, Timothy Gowers, Wenda Li, Adrian Weller, and Mateja Jamnik. 2024. Evaluating language models for mathematics through inter- actions.Proceedings of the National Academy of Sciences121, 24 (2024), e2...
-
[21]
Ned Cooper and Alexandra Zafiroglu. 2025. Constraining Participation: Affor- dances of Feedback Features in Interfaces to Large Language Models.ACM J. Responsib. Comput.2, 4, Article 16 (Oct. 2025), 35 pages. doi:10.1145/3748516
-
[22]
Cristian Danescu-Niculescu-Mizil, Moritz Sudhof, Dan Jurafsky, Jure Leskovec, and Christopher Potts. 2013. A computational approach to politeness with application to social factors. InProceedings of the 51st Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), Hinrich Schuetze, Pascale Fung, and Massimo Poesio (Eds.)....
2013
-
[23]
Hai Dang, Karim Benharrak, Florian Lehmann, and Daniel Buschek. 2022. Be- yond Text Generation: Supporting Writers with Continuous Automatic Text Summaries. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technology(Bend, OR, USA)(UIST ’22). Association for Comput- ing Machinery, New York, NY, USA, Article 98, 13 pages. doi:1...
-
[24]
Paul A David. 1985. Clio and the Economics of QWERTY.The American Economic Review75, 2 (1985), 332–337
1985
-
[25]
2001.Where the action is: the foundations of embodied interaction
Paul Dourish. 2001.Where the action is: the foundations of embodied interaction. MIT press
2001
-
[26]
Émilie Fabre, Katie Seaborn, Shuta Koiwai, Mizuki Watanabe, and Paul Riesch
-
[27]
More-than-Human Storytelling: Designing Longitudinal Narrative En- gagements with Generative AI. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems(Tokyo, Japan)(CHI EA ’25). Association for Computing Machinery, New York, NY, USA, Article 405, 10 pages. doi:10.1145/3706599.3720135
-
[28]
Xueyang Feng, Zhi-Yuan Chen, Yujia Qin, Yankai Lin, Xu Chen, Zhiyuan Liu, and Ji-Rong Wen. 2024. Large Language Model-based Human-Agent Collaboration for Complex Task Solving. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, ...
2024
-
[29]
doi:10.18653/v1/2024.findings-emnlp.72
-
[30]
Paul M Fitts and Michael I Posner. 1967. Human performance. (1967)
1967
-
[31]
Dylan Freedman. 2025. The day ChatGPT went cold.The New York Times(Aug 2025). https://www.nytimes.com/2025/08/19/business/chatgpt-gpt-5-backlash- openai.html
2025
-
[32]
Yue Fu, Sami Foell, Xuhai Xu, and Alexis Hiniker. 2024. From Text to Self: Users’ Perception of AIMC Tools on Interpersonal Communication and Self. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 977, 17 pages. doi:10.1145/3613904.3641955
-
[33]
Jie Gao, Simret Araya Gebreegziabher, Kenny Tsu Wei Choo, Toby Jia-Jun Li, Simon Tangi Perrault, and Thomas W Malone. 2024. A Taxonomy for Human- LLM Interaction Modes: An Initial Exploration. InExtended Abstracts of the CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI Shengqi Zhu, Jeffrey M. Rzeszotarski, and David Mimno EA ’24...
-
[34]
Katy Ilonka Gero, Chelse Swoopes, Ziwei Gu, Jonathan K. Kummerfeld, and Elena L. Glassman. 2024. Supporting Sensemaking of Large Language Model Outputs at Scale. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 838, 21 pages. doi:10.1...
-
[35]
Kunal Handa, Alex Tamkin, Miles McCain, Saffron Huang, Esin Durmus, Sarah Heck, Jared Mueller, Jerry Hong, Stuart Ritchie, Tim Belonax, Kevin K. Troy, Dario Amodei, Jared Kaplan, Jack Clark, and Deep Ganguli. 2025. Which Economic Tasks are Performed with AI? Evidence from Millions of Claude Conversations. arXiv:2503.04761 [cs.CY] https://arxiv.org/abs/2503.04761
-
[36]
Yilun Hao, Yongchao Chen, Yang Zhang, and Chuchu Fan. 2025. Large Language Models Can Solve Real-World Planning Rigorously with Formal Verification Tools. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), Luis Chiruzzo, Alan Rit...
-
[37]
Zeyu He, Saniya Naphade, and Ting-Hao Kenneth Huang. 2025. Prompting in the Dark: Assessing Human Performance in Prompt Engineering for Data La- beling When Gold Labels Are Absent. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems(Tokyo, Japan)(CHI ’25). Associa- tion for Computing Machinery, New York, NY, USA, Article 1195, 3...
-
[38]
Grace Huckins. 2025. Why GPT-4O’s sudden shutdown left people grieving. MIT Technology Review(Aug 2025). https://www.technologyreview.com/2025/ 08/15/1121900/gpt4o-grief-ai-companion/
2025
-
[39]
Tingting Jiang, Zhumo Sun, Shiting Fu, and Yan Lv. 2024. Human-AI inter- action research agenda: A user-centered perspective.Data and Information Management8, 4 (2024), 100078
2024
-
[40]
Epstein, and Young-Ho Kim
Eunkyung Jo, Yuin Jeong, Sohyun Park, Daniel A. Epstein, and Young-Ho Kim
-
[41]
Understanding the Impact of Long-Term Memory on Self-Disclosure with Large Language Model-Driven Chatbots for Public Health Intervention. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 440, 21 pages. doi:10.1145/3613904.3642420
-
[42]
Kat Kampf. 2024. Compare Mode in Google AI Studio: Your Companion for Choosing the Right Gemini Model. Google Developers Blog. https://developers. googleblog.com/en/compare-mode-in-google-ai-studio/
2024
-
[43]
Le, Donghwi Kim, Mina Lee, and Sung-Ju Lee
Yewon Kim, Thanh-Long V. Le, Donghwi Kim, Mina Lee, and Sung-Ju Lee. 2025. Design Opportunities for Explainable AI Paraphrasing Tools: A User Study with Non-native English Speakers. InProceedings of the 2025 ACM Designing Interactive Systems Conference (DIS ’25). Association for Computing Machinery, New York, NY, USA, 1061–1083. doi:10.1145/3715336.3735740
-
[44]
Skov, Peter Axel Nielsen, Jesper Kjeldskov, Jens Gerken, and Harald Reiterer
Maria Kjærup, Mikael B. Skov, Peter Axel Nielsen, Jesper Kjeldskov, Jens Gerken, and Harald Reiterer. 2021.Longitudinal Studies in HCI Research: A Review of CHI Publications From 1982–2019. Springer International Publishing, Cham, 11–39. doi:10.1007/978-3-030-67322-2_2
-
[45]
Philippe Laban, Jesse Vig, Marti Hearst, Caiming Xiong, and Chien-Sheng Wu
-
[46]
Beyond the Chat: Executable and Verifiable Text-Editing with LLMs. InProceedings of the 37th Annual ACM Symposium on User Interface Software and Technology(Pittsburgh, PA, USA)(UIST ’24). Association for Computing Machinery, New York, NY, USA, Article 20, 23 pages. doi:10.1145/3654777. 3676419
-
[47]
Mina Lee, Percy Liang, and Qian Yang. 2022. CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (New Orleans, LA, USA)(CHI ’22). Association for Computing Machinery, New York, NY, USA, Article 388, 19 pages. doi:10.1145/34911...
-
[48]
Sitong Li, Stefano Padilla, Pierre Le Bras, Junyu Dong, and Mike Chantler
-
[49]
arXiv:2503.00946 [cs.HC] https: //arxiv.org/abs/2503.00946
A Review of LLM-Assisted Ideation. arXiv:2503.00946 [cs.HC] https: //arxiv.org/abs/2503.00946
-
[50]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards General Text Embeddings with Multi-stage Contrastive Learning. arXiv:2308.03281 [cs.CL] https://arxiv.org/abs/2308.03281
work page internal anchor Pith review arXiv 2023
-
[51]
Vera Liao and Jennifer Wortman Vaughan
Q. Vera Liao and Jennifer Wortman Vaughan. 2024. AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap.Harvard Data Science Review Special Issue 5 (May 31 2024). https://hdsr.mitpress.mit.edu/pub/aelql9qy
2024
-
[52]
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. 2025. Wild- Bench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild. InThe Thirteenth International Conference on Learning Representations
2025
-
[53]
Tao Long, Katy Ilonka Gero, and Lydia B Chilton. 2024. Not Just Novelty: A Longitudinal Study on Utility and Customization of an AI Workflow. InProceed- ings of the 2024 ACM Designing Interactive Systems Conference(Copenhagen, Denmark)(DIS ’24). Association for Computing Machinery, New York, NY, USA, 782–803. doi:10.1145/3643834.3661587
-
[54]
Tao Long, Sitong Wang, Émilie Fabre, Tony Wang, Anup Sathya, Jason Wu, Sav- vas Dimitrios Petridis, Ding Li, Tuhin Chakrabarty, Yue Jiang, Jingyi Li, Tiffany Tseng, Ken Nakagaki, Qian Yang, Nikolas Martelaro, Jeffrey V Nickerson, and Ly- dia B Chilton. 2025. Facilitating Longitudinal Interaction Studies of AI Systems. InAdjunct Proceedings of the 38th Ann...
-
[55]
Abraham S Luchins. 1942. Mechanization in problem solving: The effect of Einstellung.Psychological monographs54, 6 (1942), i
1942
-
[56]
Ewa Luger and Abigail Sellen. 2016. "Like Having a Really Bad PA": The Gulf between User Expectation and Experience of Conversational Agents. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems (San Jose, California, USA)(CHI ’16). Association for Computing Machinery, New York, NY, USA, 5286–5297. doi:10.1145/2858036.2858288
-
[57]
Bolei Ma, Yuting Li, Wei Zhou, Ziwei Gong, Yang Janet Liu, Katja Jasinskaja, Annemarie Friedrich, Julia Hirschberg, Frauke Kreuter, and Barbara Plank
-
[58]
Pragmatics in the Era of Large Language Models: A Survey on Datasets, Evaluation, Opportunities and Challenges. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vie...
-
[59]
Zilin Ma, Yiyang Mei, and Zhaoyuan Su. 2024. Understanding the benefits and challenges of using large language model-based conversational agents for mental well-being support. InAMIA Annual Symposium Proceedings, Vol. 2023. 1105
2024
-
[60]
Atefeh Mahdavi Goloujeh, Anne Sullivan, and Brian Magerko. 2024. Is It AI or Is It Me? Understanding Users’ Prompt Journey with Text-to-Image Generative AI Tools. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY, USA, Article 183, 13 pages. doi:10....
-
[61]
Mathewson, Jaylen Pittman, and Richard Evans
Piotr Mirowski, Kory W. Mathewson, Jaylen Pittman, and Richard Evans. 2023. Co-Writing Screenplays and Theatre Scripts with Language Models: Evaluation by Industry Professionals. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems(Hamburg, Germany)(CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 355, 34...
-
[62]
Luigi Mittone, Azzurra Morreale, and Paavo Ritala. 2024. Initial conditions and path dependence in explorative and exploitative learning: An experimental study.Technovation129 (2024), 102895
2024
-
[63]
Niklas Muennighoff, Nouamane Tazi, Loic Magne, and Nils Reimers. 2023. MTEB: Massive Text Embedding Benchmark. InProceedings of the 17th Confer- ence of the European Chapter of the Association for Computational Linguistics. 2014–2037
2023
-
[64]
Sheshera Mysore, Debarati Das, Hancheng Cao, and Bahareh Sarrafzadeh. 2025. Prototypical Human-AI Collaboration Behaviors from LLM-Assisted Writing in the Wild. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Car- olyn Rose, and Violet Peng (Eds.). Association for C...
-
[65]
1994.Usability engineering
Jakob Nielsen. 1994.Usability engineering. Morgan Kaufmann
1994
-
[66]
Donald A. Norman. 2002.The Design of Everyday Things. Basic Books, Inc., USA
2002
-
[67]
OpenAI. 2025. Expanding on what we missed with sycophancy. OpenAI Blog. https://openai.com/index/expanding-on-sycophancy/
2025
-
[68]
OpenAI. 2025. Introducing GPT-5. https://openai.com/index/introducing-gpt- 5/
2025
-
[69]
Frank Robert Palmer. 2001. Mood and modality.Cambridge University(2001)
2001
-
[70]
Shuyi Pan and Maartje M.A. de Graaf. 2025. Developing a Social Support Framework: Understanding the Reciprocity in Human-Chatbot Relationship. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 182, 13 pages. doi:10.1145/3706598.3713503
-
[71]
2021.Modality: Issues in the semantics-pragmatics interface
Anna Papafragou. 2021.Modality: Issues in the semantics-pragmatics interface. Vol. 6. Brill
2021
-
[72]
Fischer, Stuart Reeves, and Sarah Sharples
Martin Porcheron, Joel E. Fischer, Stuart Reeves, and Sarah Sharples. 2018. Voice Interfaces in Everyday Life. InProceedings of the 2018 CHI Conference on Human Factors in Computing Systems(Montreal QC, Canada)(CHI ’18). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3173574.3174214
-
[73]
Here the GPT made a choice, and every choice can be biased
Snehal Prabhudesai, Ananya Prashant Kasi, Anmol Mansingh, Anindya Das An- tar, Hua Shen, and Nikola Banovic. 2025. "Here the GPT made a choice, and every choice can be biased": How Students Critically Engage with LLMs through End-User Auditing Activity. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems(Tokyo, Japan)(CHI ’25). ...
-
[74]
It’s Weird That it Knows What I Want
James Prather, Brent N. Reeves, Paul Denny, Brett A. Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. “It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers.ACM Trans. Comput.-Hum. Interact.31, 1, Article 4 (Nov. 2023), 31 pages. doi:10.1145/3617367
-
[75]
Patrizia Ribino. 2023. The role of politeness in human–machine interactions: a systematic literature review and future perspectives.Artificial Intelligence Review56, Suppl 1 (2023), 445–482
2023
-
[76]
Ryoko AI. 2023. ShareGPT52K. https://huggingface.co/datasets/RyokoAI/ ShareGPT52K. https://huggingface.co/datasets/RyokoAI/ShareGPT52K
2023
-
[77]
Gordon, Carina Negreanu, Christian Poelitz, Sruti Srinivasa Ragavan, and Ben Zorn
Advait Sarkar, Andrew D. Gordon, Carina Negreanu, Christian Poelitz, Sruti Srinivasa Ragavan, and Ben Zorn. 2022. What is it like to program with ar- tificial intelligence? arXiv:2208.06213 [cs.HC] https://arxiv.org/abs/2208.06213
-
[78]
Johannes Schneider. 2025. Mental model shifts in human-LLM interactions. Journal of Intelligent Information Systems(2025), 1–16
2025
-
[79]
Hope Schroeder, Marianne Aubin Le Quéré, Casey Randazzo, David Mimno, and Sarita Schoenebeck. 2025. Large Language Models in Qualitative Research: Uses, Tensions, and Intentions. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 481, 17 pages. doi:10.11...
-
[80]
Barry Schwartz. 2015. The paradox of choice.Positive psychology in practice: Promoting human flourishing in work, health, education, and everyday life(2015), 121–138
2015
-
[81]
1969.Speech acts: An essay in the philosophy of language
John R Searle. 1969.Speech acts: An essay in the philosophy of language. Cam- bridge university press
1969
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.