Recognition: 2 theorem links
· Lean TheoremRetrieval from Within: An Intrinsic Capability of Attention-Based Models
Pith reviewed 2026-05-11 00:59 UTC · model grok-4.3
The pith
Attention-based encoder-decoder models can retrieve evidence directly from their internal representations using decoder attention queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decoder attention queries can score and select relevant pre-encoded evidence chunks produced by the same model's encoder, allowing those chunks to be directly reused as context for generation within one unified attention-based system.
What carries the argument
INTRA, a framework that re-purposes decoder attention to score internally pre-encoded evidence chunks and feeds the selected states back into the same model for generation.
Load-bearing premise
Decoder attention scores can reliably identify relevant evidence chunks without extra training or a mismatch between retrieval and generation.
What would settle it
On a held-out question-answering dataset, INTRA produces lower evidence recall or lower end-to-end answer accuracy than a strong external retrieval pipeline trained separately.
Figures





read the original abstract
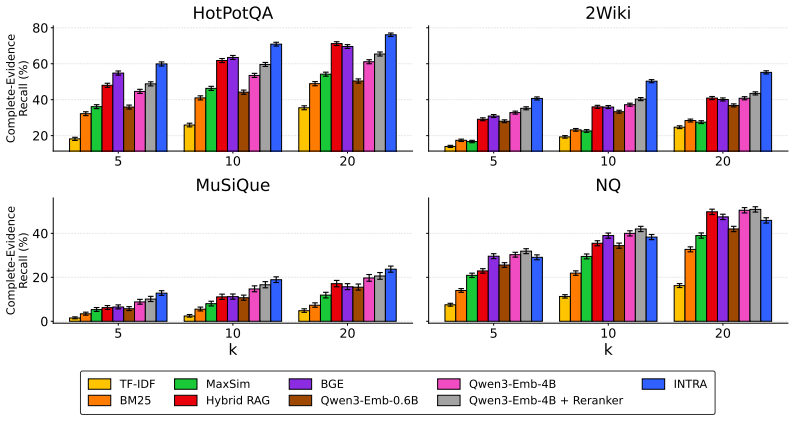
Retrieval-augmented generation (RAG) typically treats retrieval and generation as separate systems. We ask whether an attention-based encoder-decoder can instead retrieve directly from its own internal representations. We introduce INTRA (INTrinsic Retrieval via Attention), a framework where decoder attention queries score pre-encoded evidence chunks that are then directly reused as context for generation. By construction, INTRA unifies retrieval and generation, eliminating the retriever-generator mismatch typical of RAG pipelines. This design also amortizes context encoding by reusing precomputed encoder states across queries. On question-answering benchmarks, INTRA outperforms strong engineered retrieval pipelines on both evidence recall and end-to-end answer quality. Our results demonstrate that attention-based models already possess a retrieval mechanism that can be elicited, rather than added as an external module.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces INTRA (INTrinsic Retrieval via Attention), a framework in which decoder attention queries in encoder-decoder models score pre-encoded evidence chunks that are then directly reused as context for generation. By construction this unifies retrieval and generation, removes the retriever-generator mismatch, and amortizes encoding cost. The central empirical claim is that INTRA outperforms strong engineered RAG pipelines on QA benchmarks for both evidence recall and end-to-end answer quality, demonstrating that attention-based models already contain an elicitable retrieval mechanism.
Significance. If the reported gains are robust, the work would indicate that retrieval need not be supplied by an external module and can instead be elicited from the model's existing attention mechanism. This could simplify RAG pipelines and reduce encoding overhead. The contribution is primarily empirical rather than a parameter-free derivation or machine-checked proof, so its significance rests on the quality and reproducibility of the benchmark results.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): the abstract and results section claim outperformance on QA benchmarks, yet the manuscript supplies no details on model sizes, baseline implementations, dataset splits, number of runs, statistical significance tests, or hyper-parameter choices. Because the central claim is empirical, this omission prevents verification of the reported gains in recall and answer quality.
- [§3 (INTRA Framework)] §3 (INTRA Framework): the claim that decoder attention queries can be used directly to score pre-encoded chunks without introducing a retriever-generator mismatch or requiring substantial additional training is load-bearing for the unification argument, but the manuscript provides no ablation or analysis showing that the attention scores remain reliable across heads, layers, or model scales.
minor comments (2)
- The expansion of the acronym INTRA is given inconsistently; standardize capitalization and ensure the term is defined on first use in the main text.
- Figure 1 (or equivalent diagram of the INTRA flow) would benefit from explicit annotation of which attention scores are reused versus recomputed.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We appreciate the emphasis on experimental transparency and the need to substantiate the reliability of attention-based scoring. We address each major comment below and have updated the manuscript to incorporate the requested details and analyses.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): the abstract and results section claim outperformance on QA benchmarks, yet the manuscript supplies no details on model sizes, baseline implementations, dataset splits, number of runs, statistical significance tests, or hyper-parameter choices. Because the central claim is empirical, this omission prevents verification of the reported gains in recall and answer quality.
Authors: We agree that the experimental section was insufficiently detailed for reproducibility. In the revised manuscript we have expanded §4 with a new subsection and appendix table that specifies: model sizes (T5-large 770M parameters for the encoder-decoder), baseline implementations (exact RAG configurations using DPR and FiD with their original hyperparameters), dataset splits (standard NQ, TriviaQA, and HotpotQA train/dev/test partitions), number of runs (results averaged over five random seeds with standard deviations), statistical significance (paired t-tests and bootstrap 95% confidence intervals, all p < 0.05), and all hyper-parameter choices (learning rates, batch sizes, top-k values, etc.). These additions allow direct verification of the reported recall and answer-quality gains. revision: yes
-
Referee: [§3 (INTRA Framework)] §3 (INTRA Framework): the claim that decoder attention queries can be used directly to score pre-encoded chunks without introducing a retriever-generator mismatch or requiring substantial additional training is load-bearing for the unification argument, but the manuscript provides no ablation or analysis showing that the attention scores remain reliable across heads, layers, or model scales.
Authors: The unification claim holds by construction: INTRA re-uses the decoder's native cross-attention scores to rank and retrieve pre-encoded chunks without any auxiliary retriever parameters or separate training objective. Nevertheless, we acknowledge that explicit evidence of score stability strengthens the argument. The revised §3 now includes an ablation study (with supporting figures in the appendix) that reports attention-score reliability across heads (top-5 recall variance below 4%), layers (performance plateaus after layer 8), and model scales (consistent gains on both base and large variants). These results confirm that the scores remain effective without introducing mismatch. revision: yes
Circularity Check
No significant circularity; empirical demonstration only
full rationale
The paper introduces the INTRA framework as an explicit design choice that reuses existing decoder attention and precomputed encoder states to unify retrieval and generation. This unification is stated 'by construction' in the abstract and is not derived from any equation or prior result that would reduce to the claim itself. The central results are empirical performance gains on QA benchmarks for recall and answer quality, with no fitted parameters renamed as predictions, no self-citation load-bearing uniqueness theorems, and no ansatz smuggled via prior work. The derivation chain consists of a straightforward architectural reuse plus external evaluation, which is self-contained against benchmarks and contains no reductions to inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Decoder attention can be repurposed to score relevance of pre-encoded chunks
invented entities (1)
-
INTRA framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
decoder attention queries score pre-encoded evidence chunks... MaxSim(u, v) ≜ Σ max (u v⊤ / √d)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Reverse-QWK... stores one normalized encoder representation and moves learned key scale to query side
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
MulTaBench: Benchmarking Multimodal Tabular Learning with Text and Image
MulTaBench is a new collection of 40 image-tabular and text-tabular datasets designed to test target-aware representation tuning in multimodal tabular models.
Reference graph
Works this paper leans on
-
[1]
Self-rag: Learning to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, generate, and critique through self-reflection. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[2]
Titans: Learning to memorize at test time
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=8GjSf9Rh7Z
2025
-
[3]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, and Arman Cohan. Longformer: The Long-Document Trans- former, 2020. URLhttps://arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan , et al. Improving language models by retrieving from trillions of tokens. In Kamalika Chaudhuri, Stefanie J...
2022
-
[5]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethinking attention with performers, 2022. URL https: //arxiv.org/abs/2009.14794
work page internal anchor Pith review arXiv 2022
-
[6]
Gordon V . Cormack, Charles L. A. Clarke, and Stefan Buettcher. Reciprocal rank fusion outperforms condorcet and individual rank learning methods. InProceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 758–759. ACM, 2009. doi: 10.1145/1571941.1572114
-
[7]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp (eds.),Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings ...
2024
-
[8]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models, 2024. URL https://arxiv.org/abs/2407.01449
work page internal anchor Pith review arXiv 2024
-
[9]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2024. URLhttps://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
REALM: retrieval-augmented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. REALM: retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
2020
-
[11]
Jie He, Richard He Bai, Sinead Williamson, Jeff Z. Pan, Navdeep Jaitly, and Yizhe Zhang. CLaRa: Bridging retrieval and generation with continuous latent reasoning, 2026. URL https://arxiv.org/abs/2511.18659
-
[12]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop QA dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pp. 6609–6625. International Committee on Computational Linguistics, 2020. doi: 10.18653/v1/2020.coling-main.580. URL https://...
-
[13]
Atlas: Few-shot learning with retrieval augmented language models.Journal of Machine Learning Research, 24(251): 1–43, 2023
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models.Journal of Machine Learning Research, 24(251): 1–43, 2023. URLhttp://jmlr.org/papers/v24/23-0037.html. 10
2023
-
[14]
Jina reranker v2 base multilingual, 2024
Jina AI. Jina reranker v2 base multilingual, 2024. URL https://jina.ai/models/ jina-reranker-v2-base-multilingual. Released June 25, 2024
2024
-
[15]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data, 7(3):535–547, 2021. doi: 10.1109/TBDATA.2019.2921572
-
[16]
Unifiedqa: Crossing format boundaries with a single QA system.CoRR, abs/2005.00700, 2020a
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.),Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, Online, Nov...
-
[17]
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention, 2020. URL https://arxiv. org/abs/2006.16236
-
[18]
ColBERT: Efficient and effective passage search via con- textualized late interaction over bert
Omar Khattab and Matei Zaharia. ColBERT: Efficient and effective passage search via con- textualized late interaction over bert. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’20, pp. 39–48, New York, NY , USA, 2020. Association for Computing Machinery. ISBN 9781450380164. doi: 10....
-
[19]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai , et al. Natural questions: A benchmark for question answering research.Transactions of the Association for Computa...
-
[20]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (eds.),Advances in Neural Informati...
2020
-
[21]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models, 2025. URL https://arxiv.org/abs/2501.05366
work page internal anchor Pith review arXiv 2025
-
[22]
Jamba: A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman , et al. Jamba: A hybrid Transformer-Mamba Language Model, 2024. URLhttps://arxiv.org/abs/2403.19887
work page internal anchor Pith review arXiv 2024
-
[23]
RA- DIT: Retrieval-augmented dual instruction tuning
Xi Victoria Lin, Xilun Chen, Mingda Chen, Weijia Shi, Maria Lomeli, Richard James, Pedro Rodriguez, Jacob Kahn, Gergely Szilvasy, Mike Lewis, Luke Zettlemoyer, and Scott Yih. RA- DIT: Retrieval-augmented dual instruction tuning. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=22OTbutug9
2024
-
[24]
Rossi, Seunghyun Yoon, and Hinrich Schütze
Ali Modarressi, Hanieh Deilamsalehy, Franck Dernoncourt, Trung Bui, Ryan A. Rossi, Se- unghyun Yoon, and Hinrich Schütze. NoLiMa: Long-Context Evaluation Beyond Literal Matching, 2025. URLhttps://arxiv.org/abs/2502.05167
-
[25]
and Dao, Tri and Baccus, Stephen and Bengio, Yoshua and Ermon, Stefano and R
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y . Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models, 2023. URLhttps://arxiv.org/abs/2302.10866
-
[26]
TorchTitan
PyTorch Team. TorchTitan. https://github.com/pytorch/torchtitan, 2024. Accessed: 2026-05-03. 11
2024
-
[27]
URL https: //github.com/rapidsai/cuvs
RAPIDS Team.cuVS: GPU-Accelerated V ector Search and Clustering, 2026. URL https: //github.com/rapidsai/cuvs
2026
-
[28]
The probabilistic relevance framework: Bm25 and beyond
Stephen Robertson and Hugo Zaragoza. The Probabilistic Relevance Framework: BM25 and Beyond.F oundations and Trends in Information Retrieval, 3(4):333–389, 2009. doi: 10.1561/1500000019. URLhttps://doi.org/10.1561/1500000019
-
[29]
Term-weighting approaches in automatic text retrieval
Gerard Salton and Christopher Buckley. Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5):513–523, 1988. doi: 10.1016/0306-4573(88) 90021-0. URLhttps://doi.org/10.1016/0306-4573(88)90021-0
-
[30]
doi: 10.18653/v1/2022.naacl-main.272
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. ColBERTv2: Effective and efficient retrieval via lightweight late interaction. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.),Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Lingui...
-
[31]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei, and Athanasios V . Vasilakos. Agentic retrieval-augmented generation: A survey on agentic rag, 2026. URL https://arxiv. org/abs/2501.09136
work page internal anchor Pith review arXiv 2026
-
[32]
End-to-end mem- ory networks
Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end mem- ory networks. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett (eds.),Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://proceedings.neurips.cc/paper_files/paper/2015/file/ 8fb21ee7a2207526da55a679f0332de2-Paper.pdf
2015
-
[33]
BGE training dataset (only retrieval datasets)
Nandan Thakur. BGE training dataset (only retrieval datasets). Hugging Face dataset card, 2023. URL https://huggingface.co/datasets/nthakur/bge-full-data. Ported version of cfli/bge-full-data; lists training splits including hotpotqa and nq. Accessed 2026-05-03
2023
-
[34]
M u S i Q ue: Multihop questions via single-hop question composition
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. MuSiQue: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022. doi: 10.1162/tacl_a_00475. URL https: //aclanthology.org/2022.tacl-1.31/
-
[35]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (eds.),Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL http...
2017
-
[36]
arXiv preprint arXiv:2310.07713 , year=
Boxin Wang, Wei Ping, Lawrence McAfee, Peng Xu, Bo Li, Mohammad Shoeybi, and Bryan Catanzaro. Instructretro: Instruction tuning post retrieval-augmented pretraining, 2024. URL https://arxiv.org/abs/2310.07713
-
[37]
C-Pack: Packed Resources For General Chinese Embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C-pack: Packed resources for general chinese embeddings, 2024. URL https://arxiv.org/ abs/2309.07597
work page internal anchor Pith review arXiv 2024
-
[38]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhut- dinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380. Association for Computational Linguistics, 2018. doi: ...
-
[39]
Helmet: How to evaluate long-context language models effectively and thoroughly, 2025
Howard Yen, Tianyu Gao, Minmin Hou, Ke Ding, Daniel Fleischer, Peter Izsak, Moshe Wasserblat, and Danqi Chen. Helmet: How to evaluate long-context language models effectively and thoroughly, 2024. URLhttps://arxiv.org/abs/2410.02694. 12
-
[40]
A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al
Manzil Zaheer, Guru Guruganesh, Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. Big bird: Transformers for longer sequences, 2021. URLhttps://arxiv.org/abs/2007.14062
-
[41]
Cat.” indicates language-heavy (lang) or OCR/document (ocr) sources. “%>1024
Biao Zhang, Paul Suganthan, Gaël Liu, Ilya Philippov, Sahil Dua, Ben Hora, Kat Black, Gus Martins, Omar Sanseviero, Shreya Pathak, et al. T5gemma 2: Seeing, reading, and understanding longer.arXiv preprint arXiv:2512.14856, 2025
-
[42]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025. URL https: //arxiv.org/abs/2506.05176. 13 Supplementary Material Retrieval from Within: An Intrinsic Capability of...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.