Recognition: no theorem link
Long-Horizon Q-Learning: Accurate Value Learning via n-Step Inequalities
Pith reviewed 2026-05-12 05:00 UTC · model grok-4.3
The pith
Long-horizon Q-learning stabilizes value estimates by penalizing violations of n-step optimality lower bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
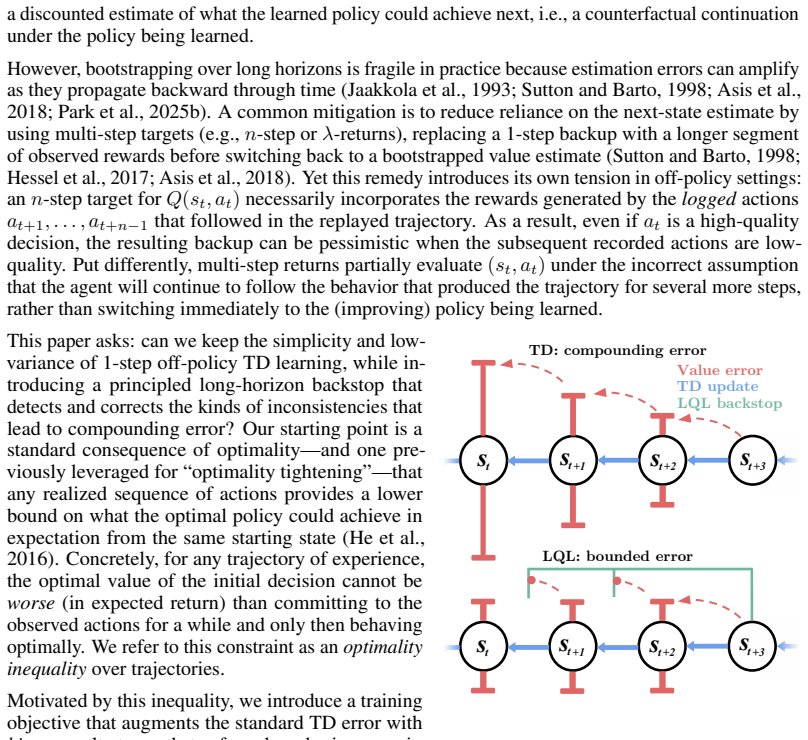
LQL introduces a stabilization mechanism for Q-learning by enforcing that any realized action sequence provides a lower bound on the value achievable by the optimal policy. Violations of this n-step inequality are penalized with a hinge loss computed directly from the outputs already generated for the temporal-difference update, requiring no additional networks or passes. When integrated with existing methods, this leads to more accurate value learning in both online and offline-to-online settings.
What carries the argument
The n-step optimality tightening inequality, converted into a practical hinge-loss penalty on the Q-network outputs.
If this is right
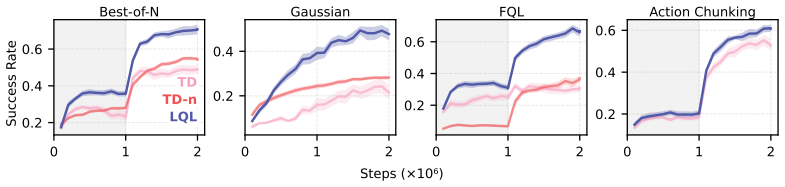
- Consistent outperformance over 1-step TD and n-step TD learning across multiple benchmarks at similar runtime.
- Effective combination with state-of-the-art online and offline-to-online reinforcement learning algorithms.
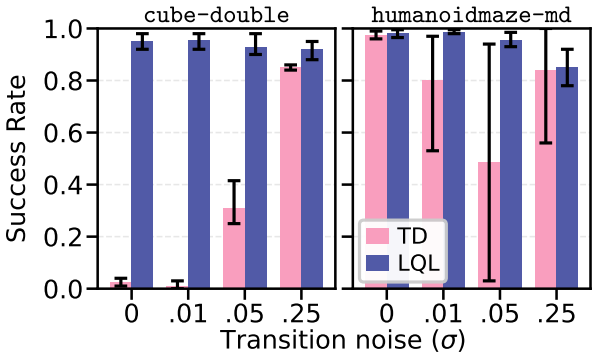
- Stabilization of long-horizon value learning without introducing auxiliary models or extra computation.
- Reduced propagation of estimation errors in off-policy settings using arbitrary experience data.
Where Pith is reading between the lines
- The hinge penalty approach could be adapted to other value-based methods to handle extended horizons.
- Future work might explore how the tightness of these bounds varies with different data collection strategies.
- Applying LQL in domains with very sparse feedback could test whether the lower bounds provide sufficient guidance for learning.
Load-bearing premise
The n-step optimality tightening inequality supplies a useful, low-bias backstop against compounding TD error without needing extra assumptions on the data or policy.
What would settle it
Running an ablation study that disables the hinge loss and measures whether value estimation errors or final policy performance degrade substantially in long-horizon tasks.
Figures

















read the original abstract
Off-policy, value-based reinforcement learning methods such as Q-learning are appealing because they can learn from arbitrary experience, including data collected by older policies or other agents. In practice, however, bootstrapping makes long-horizon learning brittle: estimation errors at later states propagate backward through temporal-difference (TD) updates and can compound over time. We propose long-horizon Q-learning (LQL), which introduces a principled backstop against compounding error when learning the optimal action-value function. LQL builds on a prior optimality tightening observation: any realized action sequence lower-bounds what the optimal policy can achieve in expectation, so acting optimally earlier should not be worse than following the observed actions for several steps before switching to optimal behavior. Our contribution is to turn this inequality into a practical stabilization mechanism for Q-learning by using a hinge loss to penalize violations of these bounds. Importantly, LQL computes these penalties using network outputs already produced for the TD error, requiring no auxiliary networks and no additional forward passes relative to Q-learning. When combined with multiple state-of-the-art methods on a range of online and offline-to-online benchmarks, LQL consistently outperforms both 1-step TD and n-step TD learning at similar runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Long-Horizon Q-Learning (LQL), which augments off-policy Q-learning with a hinge loss enforcing n-step optimality-tightening inequalities. These inequalities follow from the observation that any realized action sequence lower-bounds the return achievable by the optimal policy; the hinge penalizes Q(s,a) falling below the n-step return (observed actions followed by max Q at horizon n). The penalties reuse Q-network outputs already computed for the TD target, incurring no extra networks or forward passes. Empirical claims state that LQL, when combined with multiple SOTA methods, consistently outperforms both 1-step TD and n-step TD on online and offline-to-online benchmarks at comparable runtime.
Significance. If the central claim holds, LQL would supply a lightweight, assumption-light stabilization mechanism for long-horizon value learning that preserves the computational profile of standard Q-learning. The explicit reuse of existing network outputs for both TD and the hinge penalty is a concrete engineering strength that avoids the overhead of auxiliary critics or additional rollouts.
major comments (2)
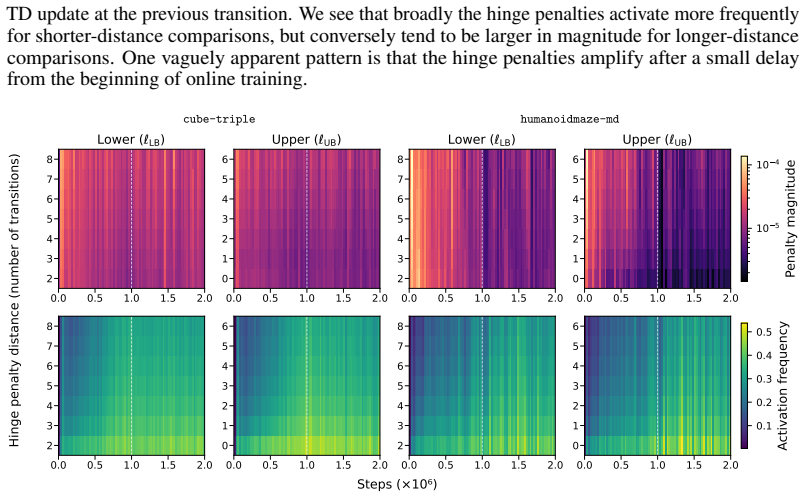
- [§3] §3 (optimality tightening and hinge loss): The n-step lower bound is formed by taking the max Q at the horizon from the identical network whose outputs already define the TD target. When function-approximation or off-policy bias causes systematic underestimation, the bound itself is lowered, so the hinge exerts little corrective force precisely where compounding error is largest. The manuscript must supply either a theoretical argument showing the bound remains useful under the method’s stated assumptions or an empirical ablation (e.g., oracle bounds or controlled bias injection) demonstrating that the claimed “low-bias backstop without additional assumptions” is not undermined by this dependence.
- [Experiments] Experimental section: The abstract asserts “consistent outperformance” across benchmarks, yet no details are given on number of independent runs, statistical significance tests, hyper-parameter sensitivity, or ablation isolating the hinge-loss term from other algorithmic choices. These controls are load-bearing for the central empirical claim and must be added.
minor comments (1)
- [Abstract] Abstract: the phrase “a range of online and offline-to-online benchmarks” would be more informative if the specific environments or suites were named.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The comments highlight important aspects of both the theoretical grounding and empirical validation of Long-Horizon Q-Learning (LQL). We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3] §3 (optimality tightening and hinge loss): The n-step lower bound is formed by taking the max Q at the horizon from the identical network whose outputs already define the TD target. When function-approximation or off-policy bias causes systematic underestimation, the bound itself is lowered, so the hinge exerts little corrective force precisely where compounding error is largest. The manuscript must supply either a theoretical argument showing the bound remains useful under the method’s stated assumptions or an empirical ablation (e.g., oracle bounds or controlled bias injection) demonstrating that the claimed “low-bias backstop without additional assumptions” is not undermined by this dependence.
Authors: We agree that the n-step bound is computed from the same network and can therefore be affected by underestimation bias. Nevertheless, the hinge still provides a useful stabilization mechanism because it enforces consistency between the current Q(s,a) and the realized n-step return (observed actions plus the network’s own estimate at the horizon). This prevents Q-values from falling below trajectory returns even when future estimates are conservative, which is precisely the regime where compounding TD errors are most damaging. To strengthen the presentation, we will add a short theoretical paragraph in §3 clarifying that the bound remains a valid (if possibly loose) lower bound under the paper’s assumptions of non-negative rewards and the optimality inequality, and we will include an empirical ablation that replaces the horizon max-Q with an oracle value to quantify the contribution of the hinge under reduced bias. revision: yes
-
Referee: [Experiments] Experimental section: The abstract asserts “consistent outperformance” across benchmarks, yet no details are given on number of independent runs, statistical significance tests, hyper-parameter sensitivity, or ablation isolating the hinge-loss term from other algorithmic choices. These controls are load-bearing for the central empirical claim and must be added.
Authors: We acknowledge that the current experimental reporting is insufficient to fully substantiate the “consistent outperformance” claim. In the revised manuscript we will expand the Experiments section and Appendix to report: (i) all results averaged over at least five independent random seeds with standard deviations; (ii) statistical significance tests (paired t-tests or Wilcoxon signed-rank tests with p-values) comparing LQL against 1-step and n-step baselines; (iii) a sensitivity analysis for the horizon length n and the hinge-loss coefficient; and (iv) an explicit ablation that removes the hinge term while keeping all other algorithmic choices fixed. These additions will be placed in the main text and supplementary material. revision: yes
Circularity Check
No significant circularity; derivation adds independent loss term to external inequality
full rationale
The paper introduces LQL by applying a hinge loss to enforce a cited optimality-tightening inequality using Q-network outputs already computed for standard TD targets. This does not reduce any claimed prediction or result to a fitted quantity defined by the method itself, nor does it rely on self-citation chains, ansatzes smuggled via prior work, or renaming of known results. The central stabilization mechanism is a standard loss applied to bootstrapped estimates, which is self-contained against external benchmarks and does not force the improvement by construction. Minor self-reference in reusing the same network is standard in Q-learning and not load-bearing for circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any realized action sequence lower-bounds what the optimal policy can achieve in expectation.
Reference graph
Works this paper leans on
- [1]
-
[2]
Joint Distillation for Fast Likelihood Evaluation and Sampling in Flow-based Models
Xinyue Ai, Yutong He, Albert Gu, Ruslan Salakhutdinov, J. Zico Kolter, Nicholas Matthew Boffi, and Max Simchowitz. Joint Distillation for Fast Likelihood Evaluation and Sampling in Flow -based Models , January 2026. URL http://arxiv.org/abs/2512.02636. arXiv:2512.02636 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Ali Amin, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, Michael Equi, Adnan Esmail, Yunhao Fang, Chelsea Finn, Catherine Glossop, Thomas Godden, Ivan Goryachev, Lachy Groom, Hunter Hancock, Karol Hausman, Gashon Hussein, Brian Ichter, Szymon Jakubczak, Rowan Jen, Tim Jones, Ben Ka...
work page Pith review arXiv 2025
-
[4]
Kristopher De Asis, J. Fernando Hernandez-Garcia, G. Zacharias Holland, and Richard S. Sutton. Multi-step Reinforcement Learning : A Unifying Algorithm , June 2018. URL http://arxiv.org/abs/1703.01327. arXiv:1703.01327 [cs]
-
[5]
Leemon C. Baird. Residual algorithms: reinforcement learning with function approximation. In Proceedings of the Twelfth International Conference on International Conference on Machine Learning, ICML'95, page 30–37, San Francisco, CA, USA, 1995. Morgan Kaufmann Publishers Inc. ISBN 1558603778
work page 1995
-
[6]
Efficient online reinforcement learning with offline data
Philip J. Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient Online Reinforcement Learning with Offline Data , May 2023. URL http://arxiv.org/abs/2302.02948. arXiv:2302.02948 [cs]
-
[7]
Dynamic programming and stochastic control processes
Richard Bellman. Dynamic programming and stochastic control processes. Information and Control, 1 0 (3): 0 228--239, 1958. ISSN 0019-9958. doi:https://doi.org/10.1016/S0019-9958(58)80003-0. URL https://www.sciencedirect.com/science/article/pii/S0019995858800030
-
[8]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren, Lucy Xi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
F. P. Cantelli. Sui confini della probabilita. In Atti del Congresso Internazional del Matematici, 1928
work page 1928
-
[10]
Yevgen Chebotar, Quan Vuong, Alex Irpan, Karol Hausman, Fei Xia, Yao Lu, Aviral Kumar, Tianhe Yu, Alexander Herzog, Karl Pertsch, Keerthana Gopalakrishnan, Julian Ibarz, Ofir Nachum, Sumedh Sontakke, Grecia Salazar, Huong T. Tran, Jodilyn Peralta, Clayton Tan, Deeksha Manjunath, Jaspiar Singht, Brianna Zitkovich, Tomas Jackson, Kanishka Rao, Chelsea Finn,...
-
[11]
Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, B
Cheng Chi, S. Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, B. Burchfiel, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. Robotics: Science and Systems, 2023. doi:10.1177/02783649241273668
- [12]
-
[13]
IMPALA : Scalable distributed deep- RL with importance weighted actor-learner architectures
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, Shane Legg, and Koray Kavukcuoglu. IMPALA : Scalable distributed deep- RL with importance weighted actor-learner architectures. In Jennifer Dy and Andreas Krause, editors, Proceedings of the 35th International Conference on Ma...
work page 2018
-
[14]
Compute-optimal scaling for value-based deep rl, 2025
Preston Fu, Oleh Rybkin, Zhiyuan Zhou, Michal Nauman, Pieter Abbeel, Sergey Levine, and Aviral Kumar. Compute- Optimal Scaling for Value - Based Deep RL , August 2025. URL http://arxiv.org/abs/2508.14881. arXiv:2508.14881 [cs]
-
[15]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor, 2018. URL https://arxiv.org/abs/1801.01290
work page internal anchor Pith review arXiv 2018
-
[16]
Frank S. He, Yang Liu, Alexander G. Schwing, and Jian Peng. Learning to Play in a Day : Faster Deep Reinforcement Learning by Optimality Tightening , November 2016. URL http://arxiv.org/abs/1611.01606. arXiv:1611.01606 [cs]
-
[17]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units ( GELUs ), June 2023. URL http://arxiv.org/abs/1606.08415. arXiv:1606.08415 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Fernando Hernandez-Garcia and Richard S
J. Fernando Hernandez-Garcia and Richard S. Sutton. Understanding Multi - Step Deep Reinforcement Learning : A Systematic Study of the DQN Target , 2019. URL https://arxiv.org/abs/1901.07510
-
[19]
Rainbow: Combining Improvements in Deep Reinforcement Learning , October 2017
Matteo Hessel, Joseph Modayil, Hado van Hasselt, Tom Schaul, Georg Ostrovski, Will Dabney, Dan Horgan, Bilal Piot, Mohammad Azar, and David Silver. Rainbow: Combining Improvements in Deep Reinforcement Learning , October 2017. URL http://arxiv.org/abs/1710.02298. arXiv:1710.02298 [cs]
-
[20]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020. URL https://arxiv.org/abs/2006.11239
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Convergence of Stochastic Iterative Dynamic Programming Algorithms
Tommi Jaakkola, Michael Jordan, and Satinder Singh. Convergence of Stochastic Iterative Dynamic Programming Algorithms . In J. Cowan, G. Tesauro, and J. Alspector, editors, Advances in Neural Information Processing Systems , volume 6. Morgan-Kaufmann, 1993. URL https://proceedings.neurips.cc/paper_files/paper/1993/file/5807a685d1a9ab3b599035bc566ce2b9-Paper.pdf
work page 1993
-
[22]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization , January 2017. URL http://arxiv.org/abs/1412.6980. arXiv:1412.6980 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline Reinforcement Learning with Implicit Q - Learning , October 2021. URL http://arxiv.org/abs/2110.06169. arXiv:2110.06169 [cs]
work page internal anchor Pith review arXiv 2021
-
[24]
Sample- Efficient Deep Reinforcement Learning via Episodic Backward Update , November 2019
Su Young Lee, Sungik Choi, and Sae-Young Chung. Sample- Efficient Deep Reinforcement Learning via Episodic Backward Update , November 2019. URL http://arxiv.org/abs/1805.12375. arXiv:1805.12375 [cs]
-
[25]
Reinforcement Learning with Action Chunking
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. Reinforcement Learning with Action Chunking , October 2025. URL http://arxiv.org/abs/2507.07969. arXiv:2507.07969 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
What Matters in Learning from Offline Human Demonstrations for Robot Manipulation
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation . In arXiv preprint arXiv :2108.03298 , 2021
work page internal anchor Pith review arXiv 2021
-
[27]
URL http://dx.doi.org/10.1038/nature14236
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement l...
-
[28]
Asynchronous methods for deep reinforcement learning.arXiv preprint arXiv:1602.01783,
Volodymyr Mnih, Adrià Puigdomènech Badia, Mehdi Mirza, Alex Graves, Timothy P. Lillicrap, Tim Harley, David Silver, and Koray Kavukcuoglu. Asynchronous Methods for Deep Reinforcement Learning , June 2016. URL http://arxiv.org/abs/1602.01783. arXiv:1602.01783 [cs]
- [29]
-
[30]
Ogbench: Benchmarking offline goal-conditioned rl.arXiv preprint arXiv:2410.20092,
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench : Benchmarking Offline Goal - Conditioned RL , February 2025 a . URL http://arxiv.org/abs/2410.20092. arXiv:2410.20092 [cs]
-
[31]
Horizon Reduction Makes RL Scalable , October 2025 b
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. Horizon Reduction Makes RL Scalable , October 2025 b . URL http://arxiv.org/abs/2506.04168. arXiv:2506.04168 [cs]
-
[32]
Flow Q - Learning , May 2025 c
Seohong Park, Qiyang Li, and Sergey Levine. Flow Q - Learning , May 2025 c . URL http://arxiv.org/abs/2502.02538. arXiv:2502.02538 [cs]
-
[33]
Jing Peng and Ronald J. Williams. Incremental multi-step q-learning. Mach. Learn., 22 0 (1–3): 0 283–290, January 1996. ISSN 0885-6125. doi:10.1007/BF00114731. URL https://doi.org/10.1007/BF00114731
-
[34]
Eligibility Traces for Off - Policy Policy Evaluation
Doina Precup, Richard Sutton, and Satinder Singh. Eligibility Traces for Off - Policy Policy Evaluation . Computer Science Department Faculty Publication Series, June 2000
work page 2000
-
[35]
Wiley Series in Probability and Statistics, Wiley (1994)
Martin L. Puterman. Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley Series in Probability and Statistics. Wiley, 1994. ISBN 978-0-47161977-2. doi:10.1002/9780470316887. URL https://doi.org/10.1002/9780470316887
-
[36]
Diffusion policy policy optimization
Allen Z. Ren, Justin Lidard, Lars L. Ankile, Anthony Simeonov, Pulkit Agrawal, Anirudha Majumdar, Benjamin Burchfiel, Hongkai Dai, and Max Simchowitz. Diffusion Policy Policy Optimization , December 2024. URL http://arxiv.org/abs/2409.00588. arXiv:2409.00588 [cs]
-
[37]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- Dimensional Continuous Control Using Generalized Advantage Estimation , October 2018. URL http://arxiv.org/abs/1506.02438. arXiv:1506.02438 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
Bigger, Better , Faster : Human -level Atari with human-level efficiency, November 2023
Max Schwarzer, Johan Obando-Ceron, Aaron Courville, Marc Bellemare, Rishabh Agarwal, and Pablo Samuel Castro. Bigger, Better , Faster : Human -level Atari with human-level efficiency, November 2023. URL http://arxiv.org/abs/2305.19452. arXiv:2305.19452 [cs]
-
[39]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- Based Generative Modeling through Stochastic Differential Equations , February 2021. URL http://arxiv.org/abs/2011.13456. arXiv:2011.13456 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback, February 2022. URL http://arxiv.org/abs/2009.01325. arXiv:2009.01325 [cs]
-
[41]
Richard S. Sutton. Learning to predict by the methods of temporal differences. Mach. Learn., 3 0 (1): 0 9–44, August 1988. ISSN 0885-6125. doi:10.1023/A:1022633531479. URL https://doi.org/10.1023/A:1022633531479
-
[42]
Richard S. Sutton and Andrew G. Barto. Reinforcement learning: An introduction , volume 1. MIT press Cambridge, 1998
work page 1998
-
[43]
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the Minimalist Approach to Offline Reinforcement Learning , October 2023. URL http://arxiv.org/abs/2305.09836. arXiv:2305.09836 [cs]
-
[44]
Analysis of temporal-diffference learning with function approximation
John Tsitsiklis and Benjamin Van Roy. Analysis of temporal-diffference learning with function approximation. In M.C. Mozer, M. Jordan, and T. Petsche, editors, Advances in Neural Information Processing Systems, volume 9. MIT Press, 1996. URL https://proceedings.neurips.cc/paper_files/paper/1996/file/e00406144c1e7e35240afed70f34166a-Paper.pdf
work page 1996
-
[45]
Deep reinforcement learning and the deadly triad
Hado van Hasselt, Yotam Doron, Florian Strub, Matteo Hessel, Nicolas Sonnerat, and Joseph Modayil. Deep reinforcement learning and the deadly triad, 2018. URL https://arxiv.org/abs/1812.02648
-
[46]
Andrew Wagenmaker, Mitsuhiko Nakamoto, Yunchu Zhang, Seohong Park, Waleed Yagoub, Anusha Nagabandi, Abhishek Gupta, and Sergey Levine. Steering Your Diffusion Policy with Latent Space Reinforcement Learning , June 2025. URL http://arxiv.org/abs/2506.15799. arXiv:2506.15799 [cs]
-
[47]
Christopher Watkins. Learning from delayed rewards. 01 1989
work page 1989
-
[48]
Christopher J. C. H. Watkins and Peter Dayan. Q-learning. Machine Learning, 8 0 (3-4): 0 279--292, May 1992. ISSN 0885-6125. doi:10.1007/BF00992698. URL http://link.springer.com/10.1007/BF00992698
-
[49]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning Fine - Grained Bimanual Manipulation with Low - Cost Hardware , April 2023. URL http://arxiv.org/abs/2304.13705. arXiv:2304.13705 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.