Recognition: no theorem link
VideoRouter: Query-Adaptive Dual Routing for Efficient Long-Video Understanding
Pith reviewed 2026-05-11 01:54 UTC · model grok-4.3
The pith
VideoRouter uses dual query-adaptive routers to allocate visual tokens efficiently in long videos, cutting usage by up to 67.9 percent while improving accuracy over the base model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
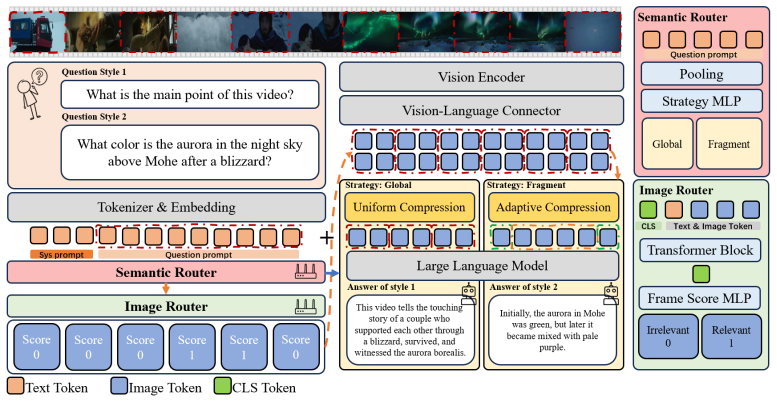
The central claim is that a query-adaptive dual-router framework, with the Semantic Router predicting the dominant allocation policy and the Image Router using early layers to score frame relevance, enables budgeted evidence allocation that preserves detail on critical frames and compresses the rest, producing up to 67.9 percent token reduction and higher accuracy than the InternVL baseline on standard long-video benchmarks.
What carries the argument
The query-adaptive dual-router framework: Semantic Router selects allocation policy between coverage and high-resolution modes, while Image Router scores frame relevance via early LLM layers.
If this is right
- Longer videos become feasible under fixed memory and latency limits by concentrating tokens on query-relevant segments.
- Aggressive compression can be applied to low-relevance frames without uniform quality loss across the entire video.
- Separate supervision of policy selection and frame scoring allows targeted training that improves both components.
- The method outperforms fixed-policy baselines on VideoMME, MLVU, and LongVideoBench under comparable budgets.
Where Pith is reading between the lines
- Similar dual-routing logic could be tested on other sequence-heavy inputs such as long audio or multi-page documents.
- Dynamic per-query token budgets might enable real-time video chat systems that scale detail according to question complexity.
- The routing pattern could be ported to other base multimodal models to measure whether the efficiency gains hold beyond InternVL.
Load-bearing premise
Routers trained on the Video-QTR-10K and Video-FLR-200K datasets generalize to arbitrary unseen queries and long videos without substantial performance degradation.
What would settle it
Running VideoRouter on a fresh long-video benchmark containing query types absent from the training sets and checking whether accuracy falls below the InternVL baseline at the same token budget.
Figures









read the original abstract
Video large multimodal models increasingly face a scalability bottleneck: long videos produce excessively long visual-token sequences, which sharply increase memory and latency during inference. While existing compression methods are effective in specific settings, most are either weakly query-aware or apply a fixed compression policy across frames, proving suboptimal when visual evidence is unevenly distributed over time. To address this, we present VideoRouter, a query-adaptive dual-router framework built on InternVL for budgeted evidence allocation. The Semantic Router predicts the dominant allocation policy, choosing between broad temporal coverage and adaptive high-resolution preservation, while the Image Router uses early LLM layers to score frame relevance. This enables aggressive compression on less relevant frames while preserving detail on critical evidence frames. To train both routers, we build Video-QTR-10K for allocation-policy supervision and Video-FLR-200K for frame-relevance supervision. Experiments on VideoMME, MLVU, and LongVideoBench show that VideoRouter consistently improves over the InternVL baseline under comparable or lower budgets, achieving up to a 67.9% token reduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VideoRouter, a query-adaptive dual-router framework built on InternVL for efficient long-video understanding. The Semantic Router selects between broad temporal coverage and adaptive high-resolution preservation policies, while the Image Router scores frame relevance using early LLM layers to enable aggressive compression on less relevant frames. Both routers are trained on newly introduced datasets Video-QTR-10K (for allocation-policy supervision) and Video-FLR-200K (for frame-relevance supervision). Experiments on VideoMME, MLVU, and LongVideoBench report consistent improvements over the InternVL baseline under comparable or lower token budgets, with up to 67.9% token reduction.
Significance. If the empirical results hold under rigorous validation, the work addresses a key scalability issue in video multimodal models by introducing query-dependent routing that avoids uniform compression policies. The dual-router design and creation of targeted supervision datasets for policy and relevance prediction represent a concrete step toward budgeted evidence allocation. Strengths include the explicit construction of Video-QTR-10K and Video-FLR-200K for reproducible router training and the reported token savings across three long-video benchmarks.
major comments (2)
- [§4] §4 (Experiments): The central performance claim of consistent gains and up to 67.9% token reduction over InternVL rests on the Semantic and Image Routers generalizing from Video-QTR-10K and Video-FLR-200K. No explicit out-of-distribution testing, dataset diversity statistics, or ablation on query/video distribution shift is provided, leaving open whether the adaptive allocation is robust or an artifact of in-distribution performance on the test benchmarks.
- [§3.2] §3.2 (Image Router): The description states that early LLM layers score frame relevance, but the precise layer selection, supervision signal from Video-FLR-200K, and how relevance scores translate into per-frame token budgets are not formalized with equations or pseudocode. This makes it difficult to assess whether the reported compression is parameter-free or depends on tuned thresholds.
minor comments (2)
- [Abstract] The abstract and §1 claim 'up to 67.9% token reduction' without specifying the exact configuration (e.g., which benchmark, budget level, or router setting) that achieves this maximum; a table or figure reference would improve clarity.
- [§2] Missing reference to prior query-aware compression methods (e.g., in related work) that also use early-layer features for relevance; adding 1-2 citations would better situate the Image Router contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central performance claim of consistent gains and up to 67.9% token reduction over InternVL rests on the Semantic and Image Routers generalizing from Video-QTR-10K and Video-FLR-200K. No explicit out-of-distribution testing, dataset diversity statistics, or ablation on query/video distribution shift is provided, leaving open whether the adaptive allocation is robust or an artifact of in-distribution performance on the test benchmarks.
Authors: We acknowledge the value of explicit OOD testing for robustness claims. Video-QTR-10K and Video-FLR-200K were constructed from diverse video sources and query types drawn from the same distribution families as the evaluation benchmarks to promote generalization. To directly address the concern, we will add dataset diversity statistics (e.g., distributions of video durations, query categories, and scene complexity) and a new ablation on controlled distribution shifts in the revised §4. The consistent gains across VideoMME, MLVU, and LongVideoBench already provide supporting evidence, but the additional analysis will clarify limitations and strengthen the results. revision: partial
-
Referee: [§3.2] §3.2 (Image Router): The description states that early LLM layers score frame relevance, but the precise layer selection, supervision signal from Video-FLR-200K, and how relevance scores translate into per-frame token budgets are not formalized with equations or pseudocode. This makes it difficult to assess whether the reported compression is parameter-free or depends on tuned thresholds.
Authors: We agree that greater formalization will improve reproducibility and clarity. In the revised manuscript, we will add equations in §3.2 specifying the exact early LLM layer used for scoring (the 5th transformer layer), the supervision signal (binary cross-entropy on frame-relevance labels from Video-FLR-200K), and the mapping of relevance scores to per-frame token budgets via an adaptive threshold function. We will also include pseudocode for the full routing procedure in the appendix. The approach is not parameter-free, as it relies on learned routers and a small set of allocation hyperparameters; these will be explicitly listed and justified. revision: yes
Circularity Check
No significant circularity in VideoRouter derivation or claims
full rationale
The paper presents VideoRouter as a new query-adaptive dual-router architecture built on InternVL, with routers trained on two newly introduced supervision datasets (Video-QTR-10K and Video-FLR-200K). Central performance claims rest on empirical results from independent external benchmarks (VideoMME, MLVU, LongVideoBench) that compare against the InternVL baseline under token budgets. No equations, derivations, or fitted parameters are shown to reduce by construction to the same inputs; no self-citation chains justify uniqueness or load-bearing premises; and no ansatz or renaming of known results is invoked. The method and evaluation are self-contained against external data, yielding no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024
work page 2024
-
[2]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5971–5984, 2024
work page 2024
-
[3]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700–13710, 2024
work page 2024
-
[4]
Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, and Chunyuan Li. Llava-next-video: Yielding zero-shot video understanding from image- language models.arXiv preprint arXiv:2404.08129, 2024
-
[5]
arXiv preprint arXiv:2404.16994 , year=
Lin Xu, Yilin Zhao, Daquan Zhou, Zhijie Lin, See Kiong Ng, and Jiashi Feng. Pllava: Parameter-free llava extension from images to videos for video dense captioning.arXiv preprint arXiv:2404.16994, 2024
-
[6]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Llava-prumerge: Adaptive token reduction for efficient large multimodal models
Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, and Yan Yan. Llava-prumerge: Adaptive token reduction for efficient large multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22857–22867, 2025
work page 2025
-
[8]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
work page 2025
-
[9]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[10]
Yuan Zhang, Chun-Kai Fan, Junpeng Ma, Wenzhao Zheng, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, et al. Sparsevlm: Visual token sparsification for efficient vision-language model inference.arXiv preprint arXiv:2410.04417, 2024
-
[11]
Metok: Multi- stage event-based token compression for efficient long video understanding
Mengyue Wang, Shuo Chen, Kristian Kersting, V olker Tresp, and Yunpu Ma. Metok: Multi- stage event-based token compression for efficient long video understanding. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18881– 18895, 2025
work page 2025
-
[12]
Dtoma: Training-free dynamic token manipulation for long video understanding
Bowen Yuan, Sisi You, and Bing-Kun Bao. Dtoma: Training-free dynamic token manipulation for long video understanding. InProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 2314–2322, 2025
work page 2025
-
[13]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[14]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022. 10
work page internal anchor Pith review arXiv 2022
-
[15]
Not all patches are what you need: Expediting vision transformers via token reorganizations
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations.arXiv preprint arXiv:2202.07800, 2022
-
[16]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in Neural Information Processing Systems, 34:13937–13949, 2021
work page 2021
-
[17]
Michael Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Tokenlearner: Adaptive space-time tokenization for videos.Advances in Neural Information Processing Systems, 34:12786–12797, 2021
work page 2021
-
[18]
Yulin Li, Haokun Gui, Ziyang Fan, Junjie Wang, Bin Kang, Bin Chen, and Zhuotao Tian. Less is more, but where? dynamic token compression via llm-guided keyframe prior.arXiv preprint arXiv:2512.06866, 2025
-
[19]
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Pyramiddrop: Accelerating your large vision-language models via pyramid visual redundancy reduction.arXiv preprint arXiv:2410.17247, 2024
-
[20]
Hao Wu, Yingqi Fan, Jinyang Dai, Junlong Tong, Yunpu Ma, and Xiaoyu Shen. Hidrop: Hierarchical vision token reduction in mllms via late injection, concave pyramid pruning, and early exit.arXiv preprint arXiv:2602.23699, 2026
-
[21]
Seeing more, saying more: Lightweight language experts are dynamic video token compressors
Xiangchen Wang, Jinrui Zhang, Teng Wang, Haigang Zhang, and Feng Zheng. Seeing more, saying more: Lightweight language experts are dynamic video token compressors. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 541–558, 2025
work page 2025
-
[22]
Long Cui, Weiyun Wang, Jie Shao, Zichen Wen, Gen Luo, Linfeng Zhang, Yanting Zhang, Yu Qiao, and Wenhai Wang. Vico: A training strategy towards semantic aware dynamic high-resolution.arXiv preprint arXiv:2510.12793, 2025
-
[23]
Dycoke: Dynamic compression of tokens for fast video large language models
Keda Tao, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Dycoke: Dynamic compression of tokens for fast video large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18992–19001, 2025
work page 2025
-
[24]
Flexible frame selection for efficient video reasoning
Shyamal Buch, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. Flexible frame selection for efficient video reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29071–29082, 2025
work page 2025
-
[25]
Jialuo Li, Bin Li, Jiahao Li, and Yan Lu. Divide, then ground: Adapting frame selection to query types for long-form video understanding.arXiv preprint arXiv:2512.04000, 2025
-
[26]
Crop: Contextual region-oriented visual token pruning
Jiawei Guo, Feifei Zhai, Pu Jian, Qianrun Wei, and Yu Zhou. Crop: Contextual region-oriented visual token pruning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9767–9783, 2025
work page 2025
-
[27]
Language-guided temporal token pruning for efficient videollm processing
Yogesh Kumar. Language-guided temporal token pruning for efficient videollm processing. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 8935–8942, 2025
work page 2025
-
[28]
Prunevid: Visual token pruning for efficient video large language models
Xiaohu Huang, Hao Zhou, and Kai Han. Prunevid: Visual token pruning for efficient video large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 19959–19973, 2025
work page 2025
-
[29]
Siyou Li, Huanan Wu, Juexi Shao, Yinghao Ma, Yujian Gan, Yihao Luo, Yuwei Wang, Dong Nie, Lu Wang, Wenqing Wu, et al. Seeing the forest and the trees: Query-aware tokenizer for long-video multimodal language models.arXiv preprint arXiv:2511.11910, 2025
-
[30]
Generative frame sampler for long video understanding
Linli Yao, Haoning Wu, Kun Ouyang, Yuanxing Zhang, Caiming Xiong, Bei Chen, Xu Sun, and Junnan Li. Generative frame sampler for long video understanding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 17900–17917, 2025. 11
work page 2025
-
[31]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3272–3283, 2025
work page 2025
-
[32]
Chaoxiang Cai, Longrong Yang, Minghe Weng, Xuewei Li, Zequn Qin, and Xi Li. Long-tailed distribution-aware router for mixture-of-experts in large vision-language model.arXiv preprint arXiv:2507.01351, 2025
-
[33]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24108–24118, 2025
work page 2025
-
[34]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
work page 2024
-
[35]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025
work page 2025
-
[36]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Zuyan Liu, Yuhao Dong, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Oryx mllm: On- demand spatial-temporal understanding at arbitrary resolution.arXiv preprint arXiv:2409.12961, 2024
-
[39]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024
-
[41]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4122–4134, 2025
work page 2025
-
[42]
Video-xl: Extra-long vision language model for hour-scale video understanding
Yan Shu, Zheng Liu, Peitian Zhang, Minghao Qin, Junjie Zhou, Zhengyang Liang, Tiejun Huang, and Bo Zhao. Video-xl: Extra-long vision language model for hour-scale video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26160–26169, 2025
work page 2025
-
[43]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review arXiv 2024
-
[44]
Jiajun Fei, Dian Li, Zhidong Deng, Zekun Wang, Gang Liu, and Hui Wang. Video-ccam: Enhancing video-language understanding with causal cross-attention masks for short and long videos.arXiv preprint arXiv:2408.14023, 2024
-
[45]
Jiajun Liu, Yibing Wang, Hanghang Ma, Xiaoping Wu, Xiaoqi Ma, Xiaoming Wei, Jianbin Jiao, Enhua Wu, and Jie Hu. Kangaroo: A powerful video-language model supporting long-context video input.International Journal of Computer Vision, 134(3):114, 2026. 12
work page 2026
-
[46]
Long Context Transfer from Language to Vision
Peiyuan Zhang, Kaichen Zhang, Bo Li, Guangtao Zeng, Jingkang Yang, Yuanhan Zhang, Ziyue Wang, Haoran Tan, Chunyuan Li, and Ziwei Liu. Long context transfer from language to vision. arXiv preprint arXiv:2406.16852, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
Yukang Chen, Fuzhao Xue, Dacheng Li, Qinghao Hu, Ligeng Zhu, Xiuyu Li, Yunhao Fang, Haotian Tang, Shang Yang, Zhijian Liu, et al. Longvila: Scaling long-context visual language models for long videos.arXiv preprint arXiv:2408.10188, 2024
-
[48]
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Balakrishnan Varadarajan, Florian Bordes, et al. Longvu: Spa- tiotemporal adaptive compression for long video-language understanding.arXiv preprint arXiv:2410.17434, 2024
-
[49]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
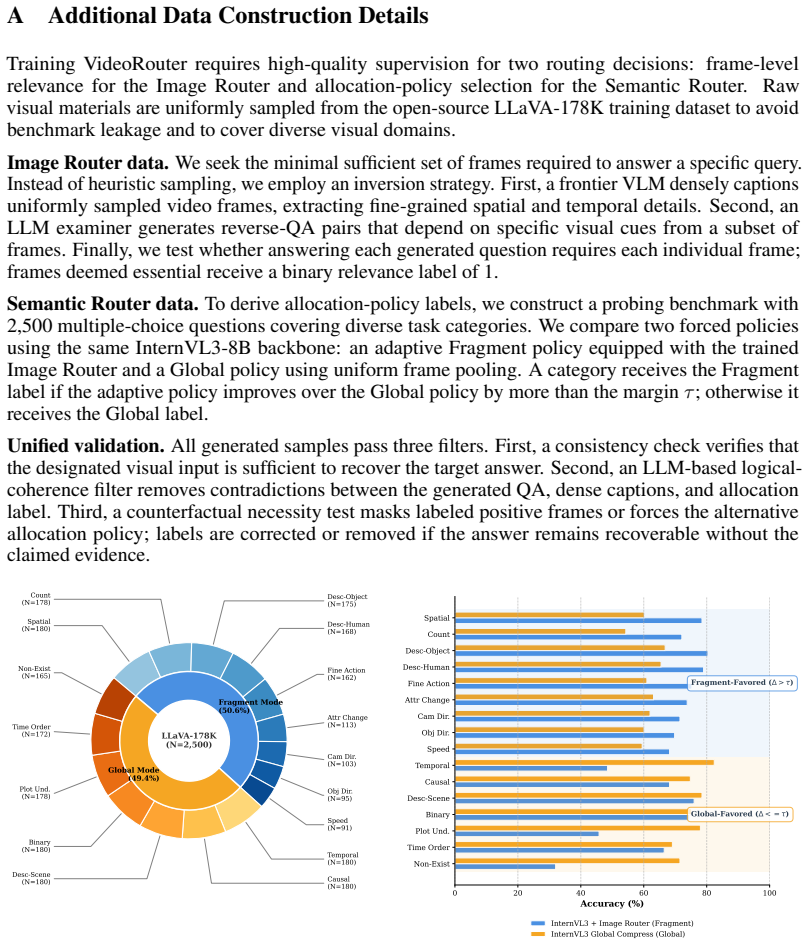
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 13 A Additional Data Construction Details Training VideoRouter requires high-quality supervision for two routing decisions: frame-level relevance for the Image Router a...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.