Recognition: unknown
Detecting AI-Generated Videos with Spiking Neural Networks
Pith reviewed 2026-05-09 16:11 UTC · model grok-4.3
The pith
Spiking neural networks detect AI-generated videos by responding to temporal smoothness gaps at object boundaries, achieving 93.14% accuracy across unseen generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We identify that AI-generated videos exhibit smoother temporal residuals and compact semantic trajectories, and that SNNs fire at boundaries for fakes unlike reals. Based on this, we propose MAST which processes multi-channel temporal residuals with a spike-driven temporal branch and a frozen semantic encoder. On the GenVideo benchmark, MAST achieves 93.14% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or surpassing the strongest ANN-based detectors.
What carries the argument
The MAST detector, which processes multi-channel temporal residuals using a spike-driven temporal branch alongside a frozen semantic encoder to capture the temporal smoothness gap in AI-generated videos.
If this is right
- SNN-based detection matches or exceeds ANN performance in cross-generator settings for AI video identification.
- The identified signatures of smoother residuals and compact trajectories serve as generalizable cues for detection.
- Firing at object and motion boundaries in SNNs aligns with the sparse nature of temporal artifacts in fakes.
- The approach demonstrates that event-driven dynamics suit the structure of residual signals better than dense backbones.
Where Pith is reading between the lines
- This method could enable more energy-efficient detection systems since SNNs use sparse activation.
- The cues might apply to detecting other forms of synthetic media with temporal inconsistencies.
- Testing on future AI generators would verify if the signatures remain reliable beyond the current benchmark.
Load-bearing premise
The smoother temporal residuals and SNN firing at boundaries are consistent and generalizable indicators of AI-generated videos across all generators.
What would settle it
A new video generator that produces fakes with temporal residuals as rough as real videos or where MAST's accuracy drops below ANN detectors in cross-evaluation would falsify the claim.
Figures


















read the original abstract
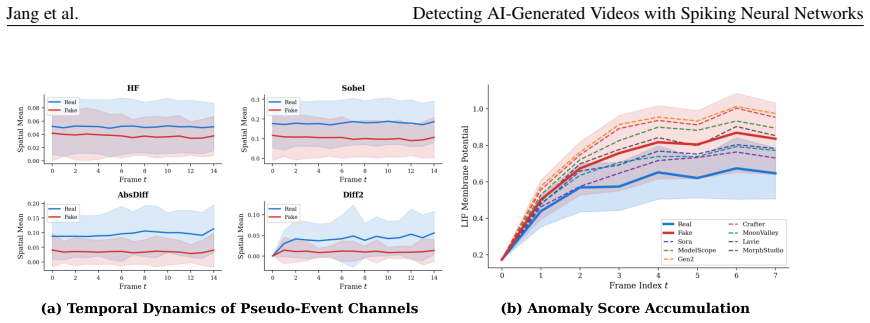
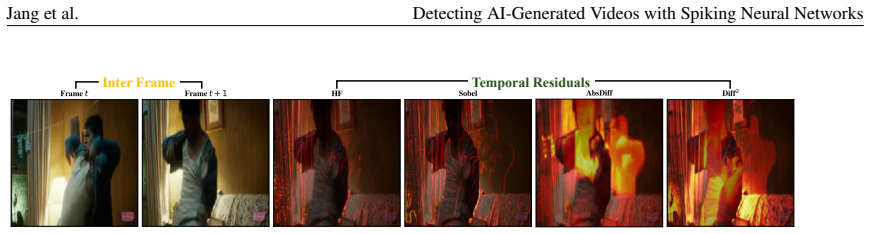
Modern AI-generated videos are photorealistic at the single-frame level, leaving inter-frame dynamics as the main remaining axis for detection. Existing detectors typically handle this temporal evidence in three ways: feeding the full frame sequence to a generic temporal backbone, reducing one dominant temporal cue to fixed video-level descriptors, or comparing temporal features to real-video statistics through a detection metric. These strategies degrade sharply under cross-generator evaluation, where artifact type and timescale vary across generators. On caption-paired benchmark, GenVidBench, we identify two signatures that prior detectors do not jointly exploit: AI-generated videos exhibit smoother frame-to-frame temporal residuals at the pixel level, and more compact trajectories in the semantic feature space, indicating a temporal smoothness gap at both levels. We further observe that, when raw video is fed into a Spiking Neural Networks (SNNs), fake clips elicit firing predominantly at object and motion boundaries, unlike real clips, suggesting that the SNN responds to temporal artifacts localized at edges. These cues are sparse, asynchronous, and concentrated at moments of change, which makes SNNs a natural choice for this task: their event-driven, sparsely-activated dynamics align with the structure of the residual signal in a way that dense ANN backbones do not. Building on this observation, we propose MAST, a detector that processes multi-channel temporal residuals with a spike-driven temporal branch alongside a frozen semantic encoder for cross-generator generalization. On the GenVideo benchmark, MAST achieves 93.14\% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or surpassing the strongest ANN-based detectors and demonstrating the practical applicability of SNNs to AI-generated video detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MAST, a hybrid detector that feeds multi-channel temporal residuals into a spike-driven temporal branch (SNN) paired with a frozen semantic encoder. It identifies two signatures in AI-generated videos—smoother pixel-level frame-to-frame residuals and more compact semantic trajectories—and observes that SNNs produce boundary-localized firing on fakes but not reals. On the GenVideo benchmark the method reports 93.14% mean accuracy across 10 unseen generators under strict cross-generator evaluation, matching or exceeding prior ANN detectors.
Significance. If the central performance claim is reproducible and the SNN contribution is isolated, the work would provide concrete evidence that event-driven spiking dynamics can exploit sparse temporal artifacts for cross-generator video detection, an area where dense ANN backbones have shown limited generalization.
major comments (3)
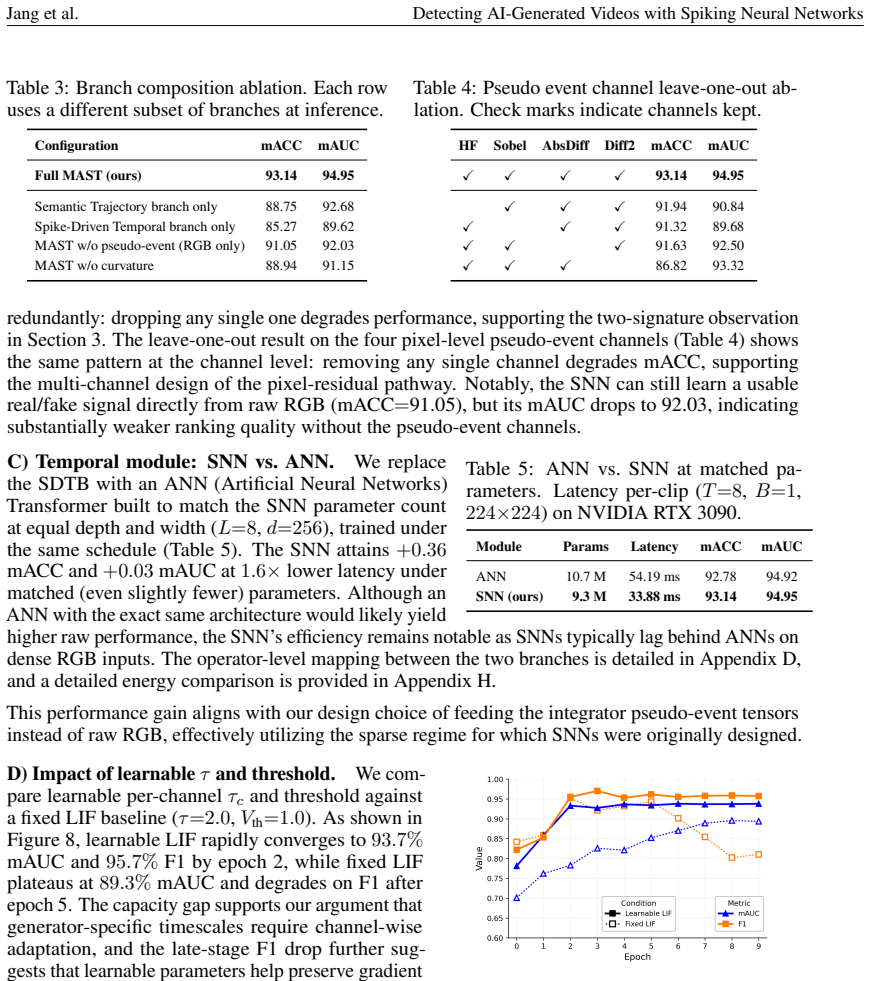
- [Abstract / Experimental results] Abstract and experimental results: the claim that the SNN temporal branch supplies the generalization advantage rests on the differential firing observation and the final accuracy number, yet no ablation is reported that replaces the SNN branch with an equivalent ANN temporal module (identical residual input channels, same training protocol, same semantic encoder). Without this control, it remains possible that the 93.14% figure is carried by the residual representation itself rather than by any property unique to spiking computation.
- [Methods / §4] Methods / §4: the manuscript provides no quantitative statistics (firing-rate histograms, spatial localization metrics, or statistical tests) to support the qualitative statement that “fake clips elicit firing predominantly at object and motion boundaries.” This observation is load-bearing for the argument that SNN dynamics align with the structure of the residual signal.
- [Results] Results: the reported mean accuracy of 93.14% across 10 generators is presented without per-generator breakdowns, confidence intervals, or details on the number of runs and statistical significance testing. Given the cross-generator setting, these omissions prevent assessment of whether the result is robust or driven by a subset of generators.
minor comments (2)
- [Abstract] The abstract refers to both “GenVidBench” and “GenVideo benchmark”; the relationship between these names should be clarified in the text.
- [Methods] Notation for the multi-channel temporal residual input and the precise architecture of the spike-driven branch (layer counts, neuron model, encoding scheme) is not fully specified in the provided sections.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address each major comment in detail below and will incorporate the suggested analyses to strengthen the claims regarding the SNN contribution and result robustness.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the claim that the SNN temporal branch supplies the generalization advantage rests on the differential firing observation and the final accuracy number, yet no ablation is reported that replaces the SNN branch with an equivalent ANN temporal module (identical residual input channels, same training protocol, same semantic encoder). Without this control, it remains possible that the 93.14% figure is carried by the residual representation itself rather than by any property unique to spiking computation.
Authors: We agree that an ablation study is required to isolate the contribution of the spiking dynamics. In the revised manuscript we will replace the SNN temporal branch with an equivalent ANN module that receives identical multi-channel residual inputs, follows the same training protocol, and shares the frozen semantic encoder. We will report the resulting cross-generator accuracy and compare it directly to the SNN version to quantify any advantage attributable to spiking computation. revision: yes
-
Referee: [Methods / §4] Methods / §4: the manuscript provides no quantitative statistics (firing-rate histograms, spatial localization metrics, or statistical tests) to support the qualitative statement that “fake clips elicit firing predominantly at object and motion boundaries.” This observation is load-bearing for the argument that SNN dynamics align with the structure of the residual signal.
Authors: We acknowledge that the qualitative firing observation requires quantitative backing. The revised manuscript will include firing-rate histograms for real versus generated clips, spatial localization metrics (e.g., fraction of spikes occurring at object and motion boundaries), and statistical tests (e.g., Wilcoxon rank-sum) to demonstrate the significance of the boundary-localized firing pattern in fake videos. revision: yes
-
Referee: [Results] Results: the reported mean accuracy of 93.14% across 10 generators is presented without per-generator breakdowns, confidence intervals, or details on the number of runs and statistical significance testing. Given the cross-generator setting, these omissions prevent assessment of whether the result is robust or driven by a subset of generators.
Authors: We agree that detailed reporting is necessary for evaluating robustness in the cross-generator setting. The revised results section will provide per-generator accuracy tables, 95% confidence intervals, the number of independent runs performed, and p-values from appropriate statistical tests comparing MAST against baselines. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no derivation chain
full rationale
The paper identifies empirical signatures (smoother temporal residuals, compact semantic trajectories, boundary-localized SNN firing) from observation on GenVidBench, proposes MAST as a hybrid architecture, and reports measured cross-generator accuracy (93.14%) on held-out generators. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes are present in the abstract or described structure. The central result is an external performance metric on unseen data, not a quantity forced by construction from the inputs or prior self-work. This is a standard empirical ML paper with independent evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI-generated videos exhibit smoother frame-to-frame temporal residuals at the pixel level and more compact trajectories in the semantic feature space
- domain assumption When raw video is fed into SNNs, fake clips elicit firing predominantly at object and motion boundaries unlike real clips
Reference graph
Works this paper leans on
-
[1]
A low power, fully event-based gesture recognition system
Arnon Amir, Brian Taba, David Berg, Timothy Melano, Jeffrey McKinstry, Carmelo Di Nolfo, Tapan Nayak, Alexander Andreopoulos, Guillaume Garreau, Marcela Mendoza, et al. A low power, fully event-based gesture recognition system. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7243–7252, 2017
2017
-
[2]
Ai-generated video detection via spatial-temporal anomaly learning
Jianfa Bai, Man Lin, Gang Cao, and Zijie Lou. Ai-generated video detection via spatial-temporal anomaly learning. InChinese Conference on Pattern Recognition and Computer Vision (PRCV), pages 460–470. Springer, 2024
2024
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024
2024
-
[5]
The laplacian pyramid as a compact image code.IEEE Transactions on Communications, 31(4):532–540, 1983
P Burt and E Adelson. The laplacian pyramid as a compact image code.IEEE Transactions on Communications, 31(4):532–540, 1983
1983
-
[6]
Carnevale and Michael L
Nicholas T. Carnevale and Michael L. Hines.The NEURON Book. Cambridge University Press, 2006
2006
-
[7]
Quo vadis, action recognition? a new model and the kinetics dataset
Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6299–6308, 2017
2017
-
[8]
Recent event camera innovations: A survey
Bharatesh Chakravarthi, Aayush Atul Verma, Kostas Daniilidis, Cornelia Fermuller, and Yezhou Yang. Recent event camera innovations: A survey. InEuropean conference on computer vision, pages 342–376. Springer, 2024
2024
-
[9]
arXiv preprint arXiv:2310.19512 , year=
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, et al. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023
-
[10]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7310–7320, 2024
2024
-
[11]
Demamba: Ai-generated video detection on million-scale genvideo benchmark,
Haoxing Chen, Yan Hong, Zizheng Huang, Zhuoer Xu, Zhangxuan Gu, Yaohui Li, Jun Lan, Huijia Zhu, Jianfu Zhang, Weiqiang Wang, et al. Demamba: Ai-generated video detection on million-scale genvideo benchmark.arXiv preprint arXiv:2405.19707, 2024
-
[12]
Seine: Short-to-long video diffusion model for generative transition and prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short-to-long video diffusion model for generative transition and prediction. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[13]
Yiting Dong, Zhaofei Yu, Jianhao Ding, Zijie Xu, and Tiejun Huang. Unleashing tempo- ral capacity of spiking neural networks through spatiotemporal separation.arXiv preprint arXiv:2512.05472, 2025
-
[14]
Structure and content-guided video synthesis with diffusion models
Patrick Esser, Johnathan Chiu, Parmida Atighehchian, Jonathan Granskog, and Anastasis Germanidis. Structure and content-guided video synthesis with diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 7346–7356, 2023
2023
-
[15]
Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence.Science Advances, 9(40):eadi1480, 2023
Wei Fang, Yanqi Chen, Jianhao Ding, Zhaofei Yu, Timothée Masquelier, Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Yonghong Tian. Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence.Science Advances, 9(40):eadi1480, 2023. 10 Jang et al. Detecting AI-Generated Videos with Spiking Neural Networks
2023
-
[16]
Incorporating learnable membrane time constant to enhance learning of spiking neural networks
Wei Fang, Zhaofei Yu, Yanqi Chen, Timothée Masquelier, Tiejun Huang, and Yonghong Tian. Incorporating learnable membrane time constant to enhance learning of spiking neural networks. InProceedings of the IEEE/CVF international conference on computer vision, pages 2661–2671, 2021
2021
-
[17]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 203–213, 2020
2020
-
[18]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. InProceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019
2019
-
[19]
Event-based vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1):154–180, 2020
Guillermo Gallego, Tobi Delbruck, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew Davison, Jörg Conradt, Kostas Daniilidis, and Davide Scaramuzza. Event-based vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1):154–180, 2020
2020
-
[20]
Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
Samanwoy Ghosh-Dastidar and Hojjat Adeli. Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
2009
-
[21]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
-
[22]
Sharpening Your Density Fields: Spiking Neuron Aided Fast Geometry Learning
Yi Gu, Zhaorui Wang, and Renjing Xu. Sharpening Your Density Fields: Spiking Neuron Aided Fast Geometry Learning. In Beibei Wang and Alexander Wilkie, editors,Eurographics Symposium on Rendering. The Eurographics Association, 2025
2025
-
[23]
Spatiotemporal inconsistency learning for deepfake video detection
Zhihao Gu, Yang Chen, Taiping Yao, Shouhong Ding, Jilin Li, Feiyue Huang, and Lizhuang Ma. Spatiotemporal inconsistency learning for deepfake video detection. InProceedings of the 29th ACM international conference on multimedia, pages 3473–3481, 2021
2021
-
[24]
Enof-snn: Training accurate spiking neural networks via enhancing the output feature
Yufei Guo, Weihang Peng, Xiaode Liu, Yuanpei Chen, Yuhan Zhang, Xin Tong, Zhou Jie, and Zhe Ma. Enof-snn: Training accurate spiking neural networks via enhancing the output feature. Advances in Neural Information Processing Systems, 37:51708–51726, 2024
2024
-
[25]
Reverb-snn: Reversing bit of the weight and activation for spiking neural networks
Yufei Guo, Yuhan Zhang, Zhou Jie, Xiaode Liu, Xin Tong, Yuanpei Chen, Weihang Peng, and Zhe Ma. Reverb-snn: Reversing bit of the weight and activation for spiking neural networks. In International Conference on Machine Learning, pages 21220–21231. PMLR, 2025
2025
-
[26]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
1.1 computing’s energy problem (and what we can do about it)
Mark Horowitz. 1.1 computing’s energy problem (and what we can do about it). In2014 IEEE international solid-state circuits conference digest of technical papers (ISSCC), pages 10–14. IEEE, 2014
2014
-
[28]
Non-negative matrix factorization with sparseness constraints.Journal of machine learning research, 5(Nov):1457–1469, 2004
Patrik O Hoyer. Non-negative matrix factorization with sparseness constraints.Journal of machine learning research, 5(Nov):1457–1469, 2004
2004
-
[29]
v2e: From video frames to realistic dvs events
Yuhuang Hu, Shih-Chii Liu, and Tobi Delbruck. v2e: From video frames to realistic dvs events. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1312–1321, 2021
2021
-
[30]
AI-generated video detection via perceptual straightening
Cristian Internò, Robert Geirhos, Markus Olhofer, Sunny Liu, Barbara Hammer, and David Klindt. AI-generated video detection via perceptual straightening. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[31]
Ivy-Fake: A Unified Explainable Framework and Benchmark for Image and Video AIGC Detection
Changjiang Jiang, Wenhui Dong, Zhonghao Zhang, Chenyang Si, Fengchang Yu, Wei Peng, Xinbin Yuan, Yifei Bi, Ming Zhao, Zian Zhou, and Caifeng Shan. IVY-FAKE: A unified explainable framework and benchmark for image and video AIGC detection.arXiv preprint arXiv:2506.00979, 2025. 11 Jang et al. Detecting AI-Generated Videos with Spiking Neural Networks
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijaya- narasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review arXiv 2017
-
[33]
Text2video-zero: Text-to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text-to-image diffusion models are zero-shot video generators. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023
2023
-
[34]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
2020
-
[35]
Deepfake detection using the rate of change between frames based on computer vision.Sensors, 21(21):7367, 2021
Gihun Lee and Mihui Kim. Deepfake detection using the rate of change between frames based on computer vision.Sensors, 21(21):7367, 2021
2021
-
[36]
Cifar10-dvs: an event- stream dataset for object classification.Frontiers in neuroscience, 11:244131, 2017
Hongmin Li, Hanchao Liu, Xiangyang Ji, Guoqi Li, and Luping Shi. Cifar10-dvs: an event- stream dataset for object classification.Frontiers in neuroscience, 11:244131, 2017
2017
-
[37]
Video- mamba: State space model for efficient video understanding
Kunchang Li, Xinhao Li, Yi Wang, Yinan He, Yali Wang, Limin Wang, and Yu Qiao. Video- mamba: State space model for efficient video understanding. InEuropean conference on computer vision, pages 237–255. Springer, 2024
2024
-
[38]
Mvitv2: Improved multiscale vision transformers for classification and detection
Yanghao Li, Chao-Yuan Wu, Haoqi Fan, Karttikeya Mangalam, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Mvitv2: Improved multiscale vision transformers for classification and detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4804–4814, 2022
2022
-
[39]
Seenn: Towards temporal spiking early exit neural networks.Advances in Neural Information Processing Systems, 36:63327–63342, 2023
Yuhang Li, Tamar Geller, Youngeun Kim, and Priyadarshini Panda. Seenn: Towards temporal spiking early exit neural networks.Advances in Neural Information Processing Systems, 36:63327–63342, 2023
2023
-
[40]
Spik-NeRF: Bridging spiking neural networks and neural radiance fields for real-time rendering
Yuxin Liao, Mingrui Wang, Hao Bian, Cheng Sun, and Bei Yu. Spik-NeRF: Bridging spiking neural networks and neural radiance fields for real-time rendering. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[41]
Tsm: Temporal shift module for efficient video under- standing
Ji Lin, Chuang Gan, and Song Han. Tsm: Temporal shift module for efficient video under- standing. InProceedings of the IEEE/CVF international conference on computer vision, pages 7083–7093, 2019
2019
-
[42]
Video swin transformer
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3202–3211, 2022
2022
-
[43]
Chenxiang Ma, Xinyi Chen, Yanchen Li, Qu Yang, Yujie Wu, Guoqi Li, Gang Pan, Huajin Tang, Kay Chen Tan, and Jibin Wu. Spiking neural networks for temporal processing: Status quo and future prospects.arXiv preprint arXiv:2502.09449, 2025
-
[44]
Detecting ai-generated video via frame consistency
Long Ma, Zhiyuan Yan, Qinglang Guo, Yong Liao, Haiyang Yu, and Pengyuan Zhou. Detecting ai-generated video via frame consistency. In2025 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2025
2025
-
[45]
Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
Xin Ma, Yaohui Wang, Xinyuan Chen, Jia Gengyun, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
2025
-
[46]
Networks of spiking neurons: The third generation of neural network models
Wolfgang Maass. Networks of spiking neurons: The third generation of neural network models. Neural Networks, 10(9):1659–1671, 1997
1997
-
[47]
Moonvalley text to video generator
Moonvalley.ai. Moonvalley text to video generator. https://moonvalley.ai/, 2022. Ac- cessed: 2026-05-04
2022
-
[48]
Hotshot-xl
John Mullan, Duncan Crawbuck, and Aakash Sastry. Hotshot-xl. https://github.com/ hotshotco/hotshot-xl, 2023. Accessed: 2026-05-04. 12 Jang et al. Detecting AI-Generated Videos with Spiking Neural Networks
2023
-
[49]
Surrogate gradient learning in spiking neural networks.IEEE Signal Processing Magazine, 36(6):51–63, 2019
Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks.IEEE Signal Processing Magazine, 36(6):51–63, 2019
2019
-
[50]
Expanding language-image pretrained models for general video recognition
Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xiang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. InEuropean conference on computer vision, pages 1–18. Springer, 2022
2022
-
[51]
Genvidbench: A 6-million benchmark for ai-generated video detection
Zhenliang Ni, Qiangyu Yan, Mouxiao Huang, Tianning Yuan, Yehui Tang, Hailin Hu, Xinghao Chen, and Yunhe Wang. Genvidbench: A 6-million benchmark for ai-generated video detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 15582– 15590, 2026
2026
-
[52]
Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, 2024
2024
-
[53]
Oraibi and Abdulkareem M
Mohammed R. Oraibi and Abdulkareem M. Radhi. Enhancement digital forensic approach for inter-frame video forgery detection using a deep learning technique.Iraqi Journal of Science, 63(6):2686–2701, 2022
2022
-
[54]
Converting static image datasets to spiking neuromorphic datasets using saccades.Frontiers in neuroscience, 9:437, 2015
Garrick Orchard, Ajinkya Jayawant, Gregory K Cohen, and Nitish Thakor. Converting static image datasets to spiking neuromorphic datasets using saccades.Frontiers in neuroscience, 9:437, 2015
2015
-
[55]
Pika ai video generator.https://pika.art, 2024
Pika Labs. Pika ai video generator.https://pika.art, 2024. Accessed: 2026-05-04
2024
-
[56]
Ucf-crime- dvs: A novel event-based dataset for video anomaly detection with spiking neural networks
Yuanbin Qian, Shuhan Ye, Chong Wang, Xiaojie Cai, Jiangbo Qian, and Jiafei Wu. Ucf-crime- dvs: A novel event-based dataset for video anomaly detection with spiking neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 6577–6585, 2025
2025
-
[57]
Nitin Rathi and Kaushik Roy. Diet-snn: A low-latency spiking neural network with direct input encoding and leakage and threshold optimization.IEEE Transactions on Neural Networks and Learning Systems, 34(6):3174–3182, 2021
2021
-
[58]
Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation
Nitin Rathi, Gopalakrishnan Srinivasan, Priyadarshini Panda, and Kaushik Roy. Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. InInternational Conference on Learning Representations, 2020
2020
-
[59]
Spiking pointnet: Spiking neural networks for point clouds.Advances in Neural Information Processing Systems, 36:41797–41808, 2023
Dayong Ren, Zhe Ma, Yuanpei Chen, Weihang Peng, Xiaode Liu, Yuhan Zhang, and Yufei Guo. Spiking pointnet: Spiking neural networks for point clouds.Advances in Neural Information Processing Systems, 36:41797–41808, 2023
2023
-
[60]
Ts-lif: A temporal segment spiking neuron network for time series forecasting
FENG SHIBO, Wanjin Feng, Xingyu Gao, Peilin Zhao, and Zhiqi Shen. Ts-lif: A temporal segment spiking neuron network for time series forecasting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[61]
On learning multi-modal forgery representation for diffusion generated video detection
Xiufeng Song, Xiao Guo, Jiache Zhang, Qirui Li, Lei Bai, Xiaoming Liu, Guangtao Zhai, and Xiaohong Liu. On learning multi-modal forgery representation for diffusion generated video detection. InAdvances in Neural Information Processing Systems, volume 37, pages 122054–122077, 2024
2024
-
[62]
Morph studio text to video generator
Morph studio. Morph studio text to video generator. https://www.morphstudio.com/,
-
[63]
Accessed: 2026-05-04
2026
-
[64]
Spiking neural networks for video analysis: An in-depth review of models and architectures.Neural Networks, page 108844, 2026
SK Sudha and S Aji. Spiking neural networks for video analysis: An in-depth review of models and architectures.Neural Networks, page 108844, 2026
2026
-
[65]
Rethinking the upsampling operations in CNN-based generative network for generalizable deepfake detection
Chuangchuang Tan et al. Rethinking the upsampling operations in CNN-based generative network for generalizable deepfake detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28130–28139, 2024. 13 Jang et al. Detecting AI-Generated Videos with Spiking Neural Networks
2024
-
[66]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020
2020
-
[67]
Lanesnns: Spiking neural networks for lane detection on the loihi neuromorphic processor
Alberto Viale, Alessio Marchisio, Maurizio Martina, Guido Masera, and Muhammad Shafique. Lanesnns: Spiking neural networks for lane detection on the loihi neuromorphic processor. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 79–86. IEEE, 2022
2022
-
[68]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review arXiv 2023
-
[69]
Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks
Lin Wang, Yo-Sung Ho, Kuk-Jin Yoon, et al. Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10081–10090, 2019
2019
-
[70]
arXiv preprint arXiv:2305.10874 (2023)
Wenjing Wang, Huan Yang, Zixi Tuo, Huiguo He, Junchen Zhu, Jianlong Fu, and Jiaying Liu. Videofactory: Swap attention in spatiotemporal diffusions for text-to-video generation.arXiv preprint arXiv:2305.10874, 2023
-
[71]
Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, 133(5):3059–3078, 2025
Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, 133(5):3059–3078, 2025
2025
-
[72]
Internvid: A large-scale video-text dataset for multi- modal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multi- modal understanding and generation. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[73]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InEuropean conference on computer vision, pages 396–416. Springer, 2024
2024
-
[74]
Musev: Infinite-length and high fidelity virtual human video generation with visual conditioned parallel denoising.arxiv, 2024
Zhiqiang Xia, Zhaokang Chen, Bin Wu, Chao Li, Kwok-Wai Hung, Chao Zhan, Yingjie He, and Wenjiang Zhou. Musev: Infinite-length and high fidelity virtual human video generation with visual conditioned parallel denoising.arxiv, 2024
2024
-
[75]
Tall: Thumbnail layout for deepfake video detection
Yuting Xu, Jian Liang, Gengyun Jia, Ziming Yang, Yanhao Zhang, and Ran He. Tall: Thumbnail layout for deepfake video detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22658–22668, 2023
2023
-
[76]
Vript: A video is worth thousands of words.Advances in Neural Information Processing Systems, 37:57240–57261, 2024
Dongjie Yang, Suyuan Huang, Chengqiang Lu, Xiaodong Han, Haoxin Zhang, Yan Gao, Yao Hu, and Hai Zhao. Vript: A video is worth thousands of words.Advances in Neural Information Processing Systems, 37:57240–57261, 2024
2024
-
[77]
Spike- driven transformer.Advances in neural information processing systems, 36:64043–64058, 2023
Man Yao, Jiakui Hu, Zhaokun Zhou, Li Yuan, Yonghong Tian, Bo Xu, and Guoqi Li. Spike- driven transformer.Advances in neural information processing systems, 36:64043–64058, 2023
2023
-
[78]
Scaling spike-driven transformer with efficient spike firing approximation training.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2973–2990, 2025
Man Yao, Xuerui Qiu, Tianxiang Hu, Jiakui Hu, Yuhong Chou, Keyu Tian, Jianxing Liao, Luziwei Leng, Bo Xu, and Guoqi Li. Scaling spike-driven transformer with efficient spike firing approximation training.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(4):2973–2990, 2025
2025
-
[79]
Xingting Yao, Qinghao Hu, Tielong Liu, Zitao Mo, Zeyu Zhu, Zhengyang Zhuge, and Jian Cheng. Spikingnerf: Making bio-inspired neural networks see through the real world.arXiv preprint arXiv:2309.10987, 2023
-
[80]
Loas: Fully temporal-parallel dataflow for dual-sparse spiking neural networks
Ruokai Yin, Youngeun Kim, Di Wu, and Priyadarshini Panda. Loas: Fully temporal-parallel dataflow for dual-sparse spiking neural networks. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 1107–1121. IEEE, 2024. 14 Jang et al. Detecting AI-Generated Videos with Spiking Neural Networks
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.