Recognition: no theorem link
Think, then Score: Decoupled Reasoning and Scoring for Video Reward Modeling
Pith reviewed 2026-05-13 07:34 UTC · model grok-4.3
The pith
Decoupling chain-of-thought from scoring produces more accurate video reward models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
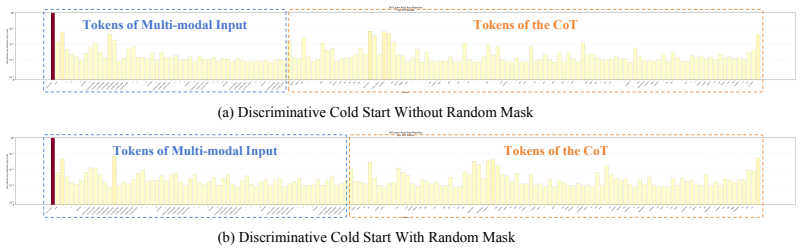
DeScore shows that an MLLM can first generate an explicit chain-of-thought rationale for video preference, after which a dedicated discriminative module consisting of a learnable query token and regression head predicts the final reward; this separation is maintained through a discriminative cold-start phase with random masking and a subsequent dual-objective reinforcement-learning phase that refines reasoning quality and reward calibration independently.
What carries the argument
The decoupled think-then-score paradigm: an MLLM autoregressively produces explicit chain-of-thought reasoning, which is then passed to a separate discriminative scoring module containing a learnable query token and regression head.
If this is right
- Reward predictions align more closely with human preferences because explicit reasoning supplies fine-grained semantic supervision.
- Generalization improves across diverse video scenarios without requiring the same scale of data needed by pure discriminative models.
- Training stability increases because the scoring step is performed by a dedicated discriminative head rather than inside a long generative sequence.
- The generated chain-of-thought remains inspectable and can be used independently for debugging or additional verification.
Where Pith is reading between the lines
- The same separation could be tested on image or text reward models to check whether the stability benefit generalizes beyond video.
- At test time the explicit chain-of-thought could be fed into an additional verification step before the reward is accepted, potentially improving test-time scaling.
- Different MLLMs could be swapped in for the reasoning stage without retraining the scoring head, allowing modular upgrades.
Load-bearing premise
That training reasoning and scoring separately in two stages will make higher-quality chain-of-thought outputs produce correspondingly better final reward scores without creating new alignment problems between the two stages.
What would settle it
If a controlled experiment finds that reward accuracy on held-out human preference videos does not improve, or worsens, when the chain-of-thought quality is deliberately varied while the scoring module stays fixed, the central claim would be falsified.
Figures






read the original abstract
Recent advances in generative video models are increasingly driven by post-training and test-time scaling, both of which critically depend on the quality of video reward models (RMs). An ideal reward model should predict accurate rewards that align with human preferences across diverse scenarios. However, existing paradigms face a fundamental dilemma: \textit{Discriminative RMs} regress rewards directly on features extracted by multimodal large language models (MLLMs) without explicit reasoning, making them prone to shortcut learning and heavily reliant on massive data scaling for generalization. In contrast, \textit{Generative RMs} with Chain-of-Thought (CoT) reasoning exhibit superior interpretability and generalization potential, as they leverage fine-grained semantic supervision to internalize the rationales behind human preferences. However, they suffer from inherent optimization bottlenecks due to the coupling of reasoning and scoring within a single autoregressive inference chain. To harness the generalization benefits of CoT reasoning while mitigating the training instability of coupled reasoning and scoring, we introduce DeScore, a training-efficient and generalizable video reward model. DeScore employs a decoupled ``think-then-score'' paradigm: an MLLM first generates an explicit CoT, followed by a dedicated discriminative scoring module consisting of a learnable query token and a regression head that predicts the final reward. DeScore is optimized via a two-stage framework: (1) a discriminative cold start incorporating a random mask mechanism to ensure robust scoring capabilities, and (2) a dual-objective reinforcement learning stage that independently refines CoT reasoning quality and calibrates the final reward, ensuring that higher-quality reasoning directly translates to superior model performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DeScore, a decoupled video reward model for aligning generative video models with human preferences. An MLLM first produces explicit Chain-of-Thought reasoning; a separate discriminative module (learnable query token plus regression head) then outputs the scalar reward. Training proceeds in two stages: a discriminative cold-start phase that uses random masking to build robust scoring, followed by dual-objective reinforcement learning that independently optimizes CoT quality and reward calibration.
Significance. If the empirical claims are substantiated, the decoupled architecture would offer a practical way to combine the interpretability and generalization of generative reward models with the training stability of discriminative ones, potentially improving post-training and test-time scaling for video generation.
major comments (1)
- [Abstract and §3] Abstract and §3: the central claim that 'higher-quality reasoning directly translates to superior model performance' is presented without any quantitative results, ablation studies, or baseline comparisons. The two-stage procedure is described at a high level, but no evidence is supplied that the random-mask cold start plus dual-objective RL actually decouples the optimization bottlenecks or yields measurable gains over coupled generative RMs.
minor comments (1)
- [§4.2] §4.2: the precise formulation of the dual-objective RL loss (weighting between reasoning quality and reward calibration terms) is not stated; an explicit equation would clarify how independence is enforced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the concern about insufficient quantitative support for the central claims by clarifying the structure of the paper and adding explicit cross-references and additional ablations.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3: the central claim that 'higher-quality reasoning directly translates to superior model performance' is presented without any quantitative results, ablation studies, or baseline comparisons. The two-stage procedure is described at a high level, but no evidence is supplied that the random-mask cold start plus dual-objective RL actually decouples the optimization bottlenecks or yields measurable gains over coupled generative RMs.
Authors: We appreciate the referee highlighting this point. The abstract and §3 are intentionally concise to introduce the decoupled 'think-then-score' paradigm and the two-stage training framework. Quantitative validation, including ablation studies and baseline comparisons against coupled generative RMs, is provided in §4 (Experiments) and §5 (Analysis and Ablations). These sections report results on multiple video preference datasets demonstrating improved reward accuracy, better generalization, and reduced training instability. Specific ablations quantify the contribution of the random-mask cold-start phase and the dual-objective RL in decoupling reasoning from scoring, with metrics showing measurable gains over coupled baselines. We have revised the abstract and §3 to include direct forward references to these experimental results. We have also added a new ablation that explicitly measures the correlation between CoT reasoning quality (via controlled perturbations) and final reward prediction performance, further substantiating the claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces DeScore as an architectural change: an MLLM generates explicit CoT reasoning, followed by a separate discriminative scoring module (learnable query token + regression head). Training uses a two-stage process (discriminative cold-start with random masking, then dual-objective RL). No equations, derivations, or self-referential definitions appear in the abstract or description that reduce the claimed performance gains to fitted parameters, self-citations, or inputs by construction. The central claim rests on the explicit decoupling of reasoning and scoring, which is presented as an independent design choice rather than a tautological redefinition of existing quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can generate explicit chain-of-thought reasoning that captures human preference rationales for video quality
invented entities (1)
-
DeScore decoupled reward model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Luma.https://lumalabs.ai/dream-machine, 2025
Luma AI. Luma.https://lumalabs.ai/dream-machine, 2025
work page 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons.Biometrika, 39(3/4):324–345, 1952
work page 1952
-
[4]
Dreamina.https://dreamina.capcut.com/, 2024
ByteDance. Dreamina.https://dreamina.capcut.com/, 2024
work page 2024
-
[5]
Seedream.https://seed.bytedance.com/zh/seedream4_0, 2025
ByteDance. Seedream.https://seed.bytedance.com/zh/seedream4_0, 2025
work page 2025
-
[6]
Seedance.https://seed.bytedance.com/zh/seedance2_0, 2026
ByteDance. Seedance.https://seed.bytedance.com/zh/seedance2_0, 2026
work page 2026
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gemini-2.5-pro.https://deepmind.google/models/gemini/pro/, 2025
Google. Gemini-2.5-pro.https://deepmind.google/models/gemini/pro/, 2025
work page 2025
-
[9]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan
Xuan He, Dongfu Jiang, Ping Nie, Minghao Liu, Zhengxuan Jiang, Mingyi Su, Wentao Ma, Junru Lin, Chun Ye, Yi Lu, et al. Videoscore2: Think before you score in generative video evaluation.arXiv preprint arXiv:2509.22799, 2025
-
[10]
Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation
Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Sherman Siu, Haonan Chen, Abhranil Chandra, Ziyan Jiang, Aaran Arulraj, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 2105–2123, 2024
work page 2024
-
[11]
Vl norm: Rethink loss aggregation in rlvr.arXiv preprint arXiv:2509.07558, 2025
Zhiyuan He, Xufang Luo, Yike Zhang, Yuqing Yang, and Lili Qiu. Vl norm: Rethink loss aggregation in rlvr.arXiv preprint arXiv:2509.07558, 2025
-
[12]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
work page 2024
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Dongfu Jiang, Max Ku, Tianle Li, Yuansheng Ni, Shizhuo Sun, Rongqi Fan, and Wenhu Chen. Genai arena: An open evaluation platform for generative models.Advances in Neural Information Processing Systems, 37:79889–79908, 2024. 10
work page 2024
-
[16]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Kling.https://app.klingai.com/cn/, 2026
Kuaishou. Kling.https://app.klingai.com/cn/, 2026
work page 2026
- [18]
-
[19]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Improving Video Generation with Human Feedback
Jie Liu, Gongye Liu, Jiajun Liang, Ziyang Yuan, Xiaokun Liu, Mingwu Zheng, Xiele Wu, Qiulin Wang, Menghan Xia, Xintao Wang, et al. Improving video generation with human feedback.arXiv preprint arXiv:2501.13918, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Nanye Ma, Shangyuan Tong, Haolin Jia, Hexiang Hu, Yu-Chuan Su, Mingda Zhang, Xuan Yang, Yandong Li, Tommi Jaakkola, Xuhui Jia, et al. Inference-time scaling for diffusion models beyond scaling denoising steps.arXiv preprint arXiv:2501.09732, 2025
- [22]
-
[23]
Gpt-5.https://openai.com/index/introducing-gpt-5/, 2025
OpenAI. Gpt-5.https://openai.com/index/introducing-gpt-5/, 2025
work page 2025
-
[24]
Sora.https://openai.com/zh-Hans-CN/sora/, 2025
OpenAI. Sora.https://openai.com/zh-Hans-CN/sora/, 2025
work page 2025
-
[25]
Yuta Oshima, Masahiro Suzuki, Yutaka Matsuo, and Hiroki Furuta. Inference-time text-to-video alignment with diffusion latent beam search.arXiv preprint arXiv:2501.19252, 2025
- [26]
-
[27]
Pejaver V Rao and Lawrence L Kupper. Ties in paired-comparison experiments: A generaliza- tion of the bradley-terry model.Journal of the American Statistical Association, 62(317):194– 204, 1967
work page 1967
-
[28]
Gen-2.https://runwayml.com/research/gen-2, 2023
Runway. Gen-2.https://runwayml.com/research/gen-2, 2023
work page 2023
-
[29]
Gen-3.https://runwayml.com/research/introducing-gen-3-alpha, 2024
Runway. Gen-3.https://runwayml.com/research/introducing-gen-3-alpha, 2024
work page 2024
-
[30]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A stable and generalizable r1-style large vision-language model.CoRR, abs/2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Longcat-video technical report
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report. arXiv preprint arXiv:2510.22200, 2025
-
[34]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Qunzhong Wang, Jie Liu, Jiajun Liang, Yilei Jiang, Yuanxing Zhang, Yaozhi Zheng, Xintao Wang, Pengfei Wan, Xiangyu Yue, and Jiaheng Liu. Vr-thinker: Boosting video reward models through thinking-with-image reasoning.arXiv preprint arXiv:2510.10518, 2025. 11
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.CoRR, abs/2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Llava-critic-r1: Your critic model is secretly a strong policy model.CoRR, abs/2509.00676, 2025
Xiyao Wang, Chunyuan Li, Jianwei Yang, Kai Zhang, Bo Liu, Tianyi Xiong, and Furong Huang. Llava-critic-r1: Your critic model is secretly a strong policy model.CoRR, abs/2509.00676, 2025
-
[39]
Yibin Wang, Zhimin Li, Yuhang Zang, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. Unified multimodal chain-of-thought reward model through reinforcement fine-tuning.arXiv preprint arXiv:2505.03318, 2025
-
[40]
Lift: Leveraging human feedback for text-to-video model alignment,
Yibin Wang, Zhiyu Tan, Junyan Wang, Xiaomeng Yang, Cheng Jin, and Hao Li. Lift: Leveraging human feedback for text-to-video model alignment.arXiv preprint arXiv:2412.04814, 2024
-
[41]
Unified Reward Model for Multimodal Understanding and Generation
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation.arXiv preprint arXiv:2503.05236, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
RewardDance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
Jie Wu, Yu Gao, Zilyu Ye, Ming Li, Liang Li, Hanzhong Guo, Jie Liu, Zeyue Xue, Xiaoxia Hou, Wei Liu, et al. Rewarddance: Reward scaling in visual generation.arXiv preprint arXiv:2509.08826, 2025
-
[43]
Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, et al. Visionreward: Fine-grained multi-dimensional human preference learning for image and video generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11269–11277, 2026
work page 2026
-
[44]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation. arXiv preprint arXiv:2505.07818, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Wenqian Ye, Guangtao Zheng, and Aidong Zhang. Rectifying shortcut behaviors in preference- based reward learning.arXiv preprint arXiv:2510.19050, 2025
-
[46]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Ailing Zeng, Yuhang Yang, Weidong Chen, and Wei Liu. The dawn of video generation: Preliminary explorations with sora-like models.arXiv preprint arXiv:2410.05227, 2024
-
[48]
Sample efficient reinforce- ment learning with reinforce
Junzi Zhang, Jongho Kim, Brendan O’Donoghue, and Stephen Boyd. Sample efficient reinforce- ment learning with reinforce. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 10887–10895, 2021
work page 2021
-
[49]
Yifan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, Haojie Ding, Jiankang Chen, Fan Yang, Zhang Zhang, Tingting Gao, and Liang Wang. R1-reward: Training multimodal reward model through stable reinforcement learning.CoRR, abs/2505.02835, 2025. 12 A Analysis on Optimization Direction In gen...
-
[50]
Prompt Decoding & Visual Expectation: Analyze the text prompt to establish a “Gold Standard” for evaluation before looking at the video. •Explicit Elements: List specific entities, actions, texts, or objects mentioned. • Implicit/Abstract Translation: If the prompt contains abstract concepts (e.g., “loneli- ness”, “cinematic”, “chaos”), translate them int...
-
[51]
Visual Evidence Extraction: Look at the video and describe what you actually see objectively, without forcing a match to the prompt. • What/Who is the main subject? • What are the exact actions and movements? • Are there any visual artifacts, hallucinations, or typos in generated text?
-
[52]
Dimensional Analysis & Score Calculation: Compare the Visual Evidence against the Prompt Expectations across 5 dimensions. •Subject (Primary): Accuracy of main entities and text generation (spelling). •Dynamics (Primary): Accuracy of actions, physics, and temporal flow. •Camera (Secondary): Movement, angles, shot types. •Environment (Secondary): Backgroun...
-
[53]
and VideoAlign [20], which are trained to predict point-wise rewards using MSE loss and BT loss, respectively. Furthermore, we compare DeScore with state-of-the-art generative models, including VisionReward [43], UnifiedReward [41], UnifiedReward-Thinking [39], and VideoScore2 [9]. While the first two directly generate reward tokens, the latter two utiliz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.