Recognition: unknown
ICU-Bench:Benchmarking Continual Unlearning in Multimodal Large Language Models
Pith reviewed 2026-05-08 10:49 UTC · model grok-4.3
The pith
Existing unlearning methods for multimodal models fail to scale across repeated privacy deletion requests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
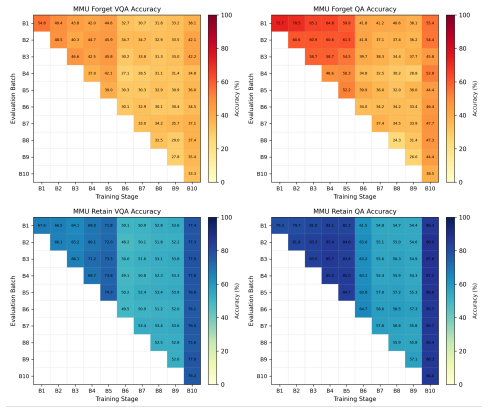
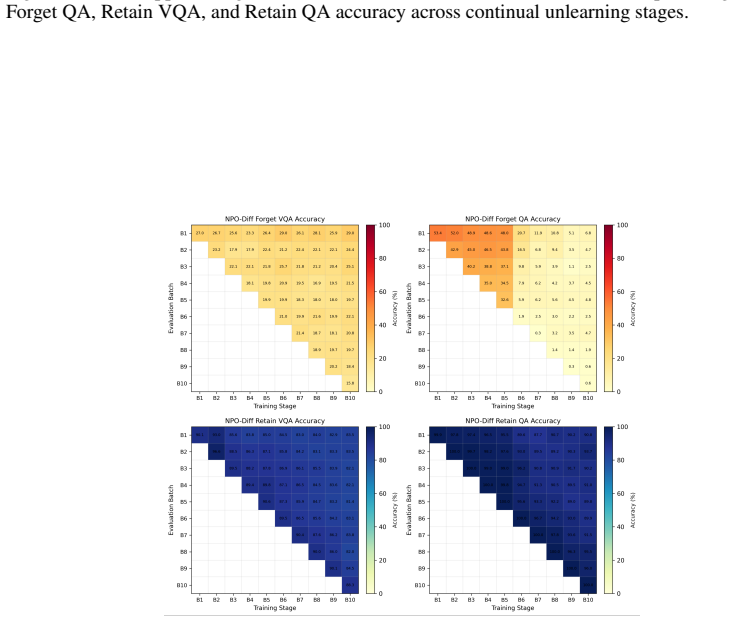
ICU-Bench supplies a continual multimodal unlearning benchmark consisting of 1,000 privacy-sensitive profiles across medical reports and labor contracts, together with 9,500 images, 16,000 question-answer pairs, and 100 forget tasks. It defines new metrics that measure forgetting effectiveness, preservation of earlier forgetting, retained model utility, and stability during the ongoing unlearning process. When representative unlearning methods are applied to the full sequence of tasks, they exhibit consistent limitations in balancing forgetting quality against utility preservation and scalability.
What carries the argument
ICU-Bench, the benchmark dataset and metric suite that simulates sequential privacy deletions on multimodal large language models using document profiles and task sequences.
If this is right
- Unlearning algorithms must be redesigned explicitly for continual sequences instead of relying on adaptations of single-task methods.
- Model utility will degrade over repeated deletions unless new techniques address cumulative interference between tasks.
- Scalability testing becomes essential because performance gaps widen as the number of forget requests grows.
- Deployment in privacy-sensitive domains will require validation against long task sequences before models can be considered compliant.
Where Pith is reading between the lines
- Privacy regulations that mandate data deletion may require more frequent full retraining of models until continual methods improve.
- Similar benchmark construction could be applied to other model types or data modalities facing repeated deletion demands.
- Real-world user deletion logs could serve as an additional test set to check whether the benchmark's task design generalizes beyond the selected domains.
Load-bearing premise
The 100 forget tasks and the two chosen document domains accurately represent the continual privacy deletion requests that multimodal models will encounter in real deployments.
What would settle it
An unlearning method that maintains high scores on all introduced metrics across the complete sequence of 100 tasks while showing no measurable drop in retained utility would falsify the reported limitations of existing approaches.
Figures










read the original abstract
Although Multimodal Large Language Models (MLLMs) have achieved remarkable progress across many domains, their training on large-scale multimodal datasets raises serious privacy concerns, making effective machine unlearning increasingly necessary. However, existing benchmarks mainly focus on static or short-sequence settings, offering limited support for evaluating continual privacy deletion requests in realistic deployments. To bridge this gap, we introduce ICU-Bench, a continual multimodal unlearning benchmark built on privacy-critical document data. ICU-Bench contains 1,000 privacy-sensitive profiles from two document domains, medical reports and labor contracts, with 9,500 images, 16,000 question-answer pairs, and 100 forget tasks. Additionally, new continual unlearning metrics are introduced, facilitating a comprehensive analysis of forgetting effectiveness, historical forgetting preservation, retained utility, and stability throughout the continual unlearning process. Through extensive experiments with representative unlearning methods on ICU-Bench, we show that existing methods generally struggle in continual settings and exhibit clear limitations in balancing forgetting quality, utility preservation, and scalability over long task sequences. These findings highlight the need for multimodal unlearning methods explicitly designed for continual privacy deletion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ICU-Bench, a benchmark for continual unlearning in multimodal large language models (MLLMs) constructed from 1,000 privacy-sensitive profiles in medical reports and labor contracts (9,500 images, 16,000 QA pairs) organized into 100 sequential forget tasks. It proposes new metrics covering forgetting effectiveness, historical preservation, retained utility, and stability, and reports experiments indicating that existing unlearning methods struggle to balance these factors over long task sequences.
Significance. If the benchmark construction accurately captures realistic continual privacy deletion requests, the findings would be significant for highlighting intrinsic limitations of current MLLM unlearning techniques and motivating development of methods suited to sequential, multimodal settings. The release of the dataset and new metrics for historical preservation and stability represents a concrete contribution that could standardize evaluation in this area.
major comments (2)
- Abstract and benchmark description: The central claim that existing methods exhibit clear limitations in balancing forgetting quality, utility preservation, and scalability over long sequences rests on ICU-Bench faithfully representing real-world continual privacy deletion requests; however, the 100 forget tasks are drawn from only two narrow domains without reported details on heterogeneity, dependency structure, cross-modal consistency constraints, or validation against actual deployment patterns (e.g., varying user-initiated deletions), raising the risk that observed failures are artifacts of the synthetic sequence rather than intrinsic method weaknesses.
- Metrics section: The new metrics for historical forgetting preservation and stability are introduced to facilitate analysis, but their validity and interpretation inherit the same representativeness gap; without ablations or correlation studies showing how these metrics align with legal or practical privacy outcomes, they do not yet fully support the comprehensive evaluation claims.
minor comments (1)
- The abstract refers to 'representative unlearning methods' without naming them or their selection criteria, which would improve immediate context for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed the major comments and provide point-by-point responses below, outlining clarifications and planned revisions to improve transparency and rigor.
read point-by-point responses
-
Referee: Abstract and benchmark description: The central claim that existing methods exhibit clear limitations in balancing forgetting quality, utility preservation, and scalability over long sequences rests on ICU-Bench faithfully representing real-world continual privacy deletion requests; however, the 100 forget tasks are drawn from only two narrow domains without reported details on heterogeneity, dependency structure, cross-modal consistency constraints, or validation against actual deployment patterns (e.g., varying user-initiated deletions), raising the risk that observed failures are artifacts of the synthetic sequence rather than intrinsic method weaknesses.
Authors: We agree that representativeness is key to supporting the central claims. The domains of medical reports and labor contracts were deliberately chosen as representative privacy-critical areas involving multimodal data subject to deletion requests. In the revision, we will expand the benchmark construction section (and add an appendix) with explicit details on heterogeneity (e.g., variation in profile attributes, image types, and QA complexity), dependency structures (e.g., overlapping entities across sequential tasks), and cross-modal consistency constraints applied during generation. We will also add a limitations subsection discussing how the task sequences approximate common real-world patterns such as cumulative user deletions, while acknowledging that exhaustive validation against proprietary deployment logs lies outside the scope of this work. These changes will better contextualize the results as evidence of challenges in continual multimodal unlearning rather than artifacts. revision: partial
-
Referee: Metrics section: The new metrics for historical forgetting preservation and stability are introduced to facilitate analysis, but their validity and interpretation inherit the same representativeness gap; without ablations or correlation studies showing how these metrics align with legal or practical privacy outcomes, they do not yet fully support the comprehensive evaluation claims.
Authors: The historical preservation and stability metrics were designed to address gaps in existing single-task evaluations by quantifying retention of prior unlearning and consistency across sequences. To address the validity concern, we will incorporate new ablation studies in the experiments section demonstrating how these metrics relate to standard forgetting and utility measures. We will also extend the metrics description with a discussion of their alignment to practical privacy objectives, such as supporting the right to erasure. While direct correlation studies with jurisdiction-specific legal outcomes are not feasible in this benchmark-focused work, the added analyses will provide stronger empirical grounding for their use in comprehensive evaluation. revision: partial
Circularity Check
No circularity; empirical benchmark with results from direct experimentation on introduced dataset.
full rationale
The paper introduces ICU-Bench as a new benchmark containing 1,000 profiles, 100 forget tasks, and associated multimodal data, then reports experimental outcomes when applying existing unlearning methods to it. No mathematical derivations, equations, fitted parameters, or self-citation chains appear in the abstract or described structure. Central claims about method limitations rest on the experimental measurements of forgetting quality, utility, and stability rather than reducing to inputs by construction, self-definition, or renamed prior results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unlearning techniques can selectively remove private information from trained multimodal models without full retraining
Reference graph
Works this paper leans on
-
[1]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[2]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: En- hancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review arXiv 2023
-
[4]
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, et al. mplug-owl: Modularization empowers large language models with multimodality.arXiv preprint arXiv:2304.14178, 2023
work page Pith review arXiv 2023
-
[5]
Protecting privacy in multimodal large language models with mllmu-bench
Zheyuan Liu, Guangyao Dou, Mengzhao Jia, Zhaoxuan Tan, Qingkai Zeng, Yongle Yuan, and Meng Jiang. Protecting privacy in multimodal large language models with mllmu-bench. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages ...
2025
-
[6]
Single image unlearning: Efficient machine unlearning in multimodal large language models.Advances in Neural Information Processing Systems, 37:35414–35453, 2024
Jiaqi Li, Qianshan Wei, Chuanyi Zhang, Guilin Qi, Miaozeng Du, Yongrui Chen, Sheng Bi, and Fan Liu. Single image unlearning: Efficient machine unlearning in multimodal large language models.Advances in Neural Information Processing Systems, 37:35414–35453, 2024
2024
-
[7]
A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 4(2):100211, 2024
Yifan Yao, Jinhao Duan, Kaidi Xu, Yuanfang Cai, Zhibo Sun, and Yue Zhang. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly.High-Confidence Computing, 4(2):100211, 2024
2024
-
[8]
The eu general data protection regulation (gdpr).A practical guide, 1st ed., Cham: Springer International Publishing, 10(3152676):10–5555, 2017
Paul V oigt and Axel V on dem Bussche. The eu general data protection regulation (gdpr).A practical guide, 1st ed., Cham: Springer International Publishing, 10(3152676):10–5555, 2017
2017
-
[9]
Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
2025
-
[10]
Wagle: Strategic weight attribution for effective and modular unlearning in large language models.Advances in Neural Information Processing Systems, 37:55620–55646, 2024
Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, and Sijia Liu. Wagle: Strategic weight attribution for effective and modular unlearning in large language models.Advances in Neural Information Processing Systems, 37:55620–55646, 2024
2024
-
[11]
Videoeraser: Concept erasure in text-to-video diffusion models
Naen Xu, Jinghuai Zhang, Changjiang Li, Zhi Chen, Chunyi Zhou, Qingming Li, Tianyu Du, and Shouling Ji. Videoeraser: Concept erasure in text-to-video diffusion models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5965–5994, 2025
2025
-
[12]
Yuan: Yielding unblemished aesthetics through a unified network for visual imperfections removal in generated images
Zhenyu Yu and Chee Seng Chan. Yuan: Yielding unblemished aesthetics through a unified network for visual imperfections removal in generated images. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 9716–9724, 2025
2025
-
[13]
Jiali Cheng and Hadi Amiri. Mu-bench: A multitask multimodal benchmark for machine unlearning.arXiv preprint arXiv:2406.14796, 2024
-
[14]
Umu-bench: Closing the modality gap in multimodal unlearning evaluation
Chengye Wang, Yuyuan Li, XiaoHua Feng, Chaochao Chen, Xiaolin Zheng, and Jianwei Yin. Umu-bench: Closing the modality gap in multimodal unlearning evaluation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. 10
2025
-
[15]
Clear: Character unlearning in textual and visual modalities
Alexey Dontsov, Dmitrii Korzh, Alexey Zhavoronkin, Boris Mikheev, Denis Bobkov, Aibek Alanov, Oleg Rogov, Ivan Oseledets, and Elena Tutubalina. Clear: Character unlearning in textual and visual modalities. InFindings of the Association for Computational Linguistics: ACL 2025, pages 20582–20603, 2025
2025
-
[16]
Zhaopan Xu, Pengfei Zhou, Weidong Tang, Jiaxin Ai, Wangbo Zhao, Kai Wang, Xiaojiang Peng, Wenqi Shao, Hongxun Yao, and Kaipeng Zhang. Pebench: A fictitious dataset to benchmark machine unlearning for multimodal large language models.arXiv preprint arXiv:2503.12545, 2025
-
[17]
Forgetme: Benchmarking the selective forgetting capabilities of generative models.Engineering Applica- tions of Artificial Intelligence, 161:112087, 2025
Zhenyu Yu, Mohd Yamani Idna Idris, Pei Wang, Yuelong Xia, and Yong Xiang. Forgetme: Benchmarking the selective forgetting capabilities of generative models.Engineering Applica- tions of Artificial Intelligence, 161:112087, 2025
2025
-
[18]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14389–14408, 2023
2023
-
[19]
Large language model unlearning.Advances in Neural Information Processing Systems, 37:105425–105475, 2024
Yuanshun Yao and Xiaojun Xu. Large language model unlearning.Advances in Neural Information Processing Systems, 37:105425–105475, 2024
2024
-
[20]
arXiv preprint arXiv:2404.05868 , year=
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning.arXiv preprint arXiv:2404.05868, 2024
-
[21]
Mmunlearner: Reformulating multimodal machine unlearning in the era of multimodal large language models
Jiahao Huo, Yibo Yan, Xu Zheng, Yuanhuiyi Lyu, Xin Zou, Zhihua Wei, and Xuming Hu. Mmunlearner: Reformulating multimodal machine unlearning in the era of multimodal large language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 7190–7206, 2025
2025
-
[22]
Modality-aware neuron pruning for unlearning in multimodal large language models
Zheyuan Liu, Guangyao Dou, Xiangchi Yuan, Chunhui Zhang, Zhaoxuan Tan, and Meng Jiang. Modality-aware neuron pruning for unlearning in multimodal large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5913–5933, 2025
2025
-
[23]
Mllm machine unlearning via visual knowledge distillation.arXiv preprint arXiv:2512.11325, 2025
Yuhang Wang, Zhenxing Niu, Haoxuan Ji, Guangyu He, Haichang Gao, and Gang Hua. Mllm machine unlearning via visual knowledge distillation.arXiv preprint arXiv:2512.11325, 2025
-
[24]
On large language model continual unlearning
Chongyang Gao, Lixu Wang, Kaize Ding, Chenkai Weng, Xiao Wang, and Qi Zhu. On large language model continual unlearning. InThe Thirteenth International Conference on Learning Representations
-
[25]
Tatsuki Kawakami, Kazuki Egashira, Atsuyuki Miyai, Go Irie, and Kiyoharu Aizawa. Pulse: Practical evaluation scenarios for large multimodal model unlearning.arXiv preprint arXiv:2507.01271, 2025
-
[26]
arXiv preprint arXiv:2407.06460 , year=
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A Smith, and Chiyuan Zhang. Muse: Machine unlearning six-way evaluation for language models.arXiv preprint arXiv:2407.06460, 2024
-
[27]
Knowledge unlearning for llms: Tasks, methods, and challenges.arXiv preprint arXiv:2311.15766, 2023
Nianwen Si, Hao Zhang, Heyu Chang, Wenlin Zhang, Dan Qu, and Weiqiang Zhang. Knowledge unlearning for llms: Tasks, methods, and challenges.arXiv preprint arXiv:2311.15766, 2023
-
[28]
Unrolling sgd: Understanding factors influencing machine unlearning
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P), pages 303–319. IEEE, 2022
2022
-
[29]
Continual learning and private unlearning
Bo Liu, Qiang Liu, and Peter Stone. Continual learning and private unlearning. InConference on Lifelong Learning Agents, pages 243–254. PMLR, 2022
2022
-
[30]
arXiv preprint arXiv:2401.06121 , year=
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms.arXiv preprint arXiv:2401.06121, 2024. 11
-
[31]
Variational bayesian unlearning.Advances in Neural Information Processing Systems, 33:16025–16036, 2020
Quoc Phong Nguyen, Bryan Kian Hsiang Low, and Patrick Jaillet. Variational bayesian unlearning.Advances in Neural Information Processing Systems, 33:16025–16036, 2020
2020
-
[32]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[33]
Efuf: Efficient fine-grained unlearning framework for mitigating hallucinations in multimodal large language models
Shangyu Xing, Fei Zhao, Zhen Wu, Tuo An, Weihao Chen, Chunhui Li, Jianbing Zhang, and Xinyu Dai. Efuf: Efficient fine-grained unlearning framework for mitigating hallucinations in multimodal large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1167–1181, 2024
2024
-
[34]
Trishna Chakraborty, Erfan Shayegani, Zikui Cai, Nael Abu-Ghazaleh, M Salman Asif, Yue Dong, Amit K Roy-Chowdhury, and Chengyu Song. Cross-modal safety alignment: Is textual unlearning all you need?arXiv preprint arXiv:2406.02575, 2024
-
[35]
fluency_score
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 881–916, 2025. 12 A Implementation Details A.1 Dataset Statistics...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.