Recognition: no theorem link
MobileEgo Anywhere: Open Infrastructure for long horizon egocentric data on commodity hardware
Pith reviewed 2026-05-15 07:05 UTC · model grok-4.3
The pith
Smartphones enable collection of 200 hours of long-horizon egocentric data for robot training
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MobileEgo Anywhere uses the built-in sensors of standard smartphones to deliver high-fidelity, long-term camera pose tracking, allowing users to record hour-plus egocentric trajectories anywhere. The authors contribute a 200-hour dataset of diverse long-form egocentric recordings that include persistent state tracking, an open-source mobile application for data capture, and a processing pipeline that turns raw phone footage into standardized formats ready for vision-language-action model training.
What carries the argument
Smartphone sensor fusion for continuous camera pose estimation that maintains persistent state across long recordings without external hardware
If this is right
- Any user with a modern phone can now record hour-scale egocentric trajectories for robot learning.
- Vision-language-action models can train on continuous sequences that span many minutes to hours rather than short clips.
- Data collection becomes feasible outside controlled labs and across many different real-world settings.
- The open processing pipeline turns raw mobile video and sensor logs into uniform training formats for foundation models.
Where Pith is reading between the lines
- Widespread phone-based collection could rapidly expand dataset diversity across global environments and cultures.
- Persistent state labels from phone tracking might support new benchmarks on object permanence and long-term memory in robotic policies.
- The same phone infrastructure could be extended to include additional onboard sensors for richer multimodal egocentric streams.
Load-bearing premise
Ordinary smartphone cameras and sensors can track pose accurately for full hours without accumulating errors that break the data for training.
What would settle it
Quantitative comparison of phone-derived poses against ground-truth motion capture over multiple one-hour sessions, showing whether drift exceeds thresholds that would make the trajectories unusable for long-horizon policy learning.
Figures
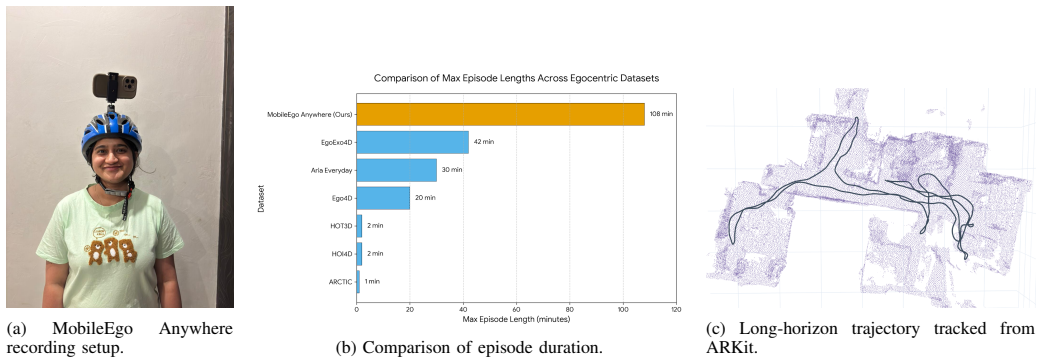
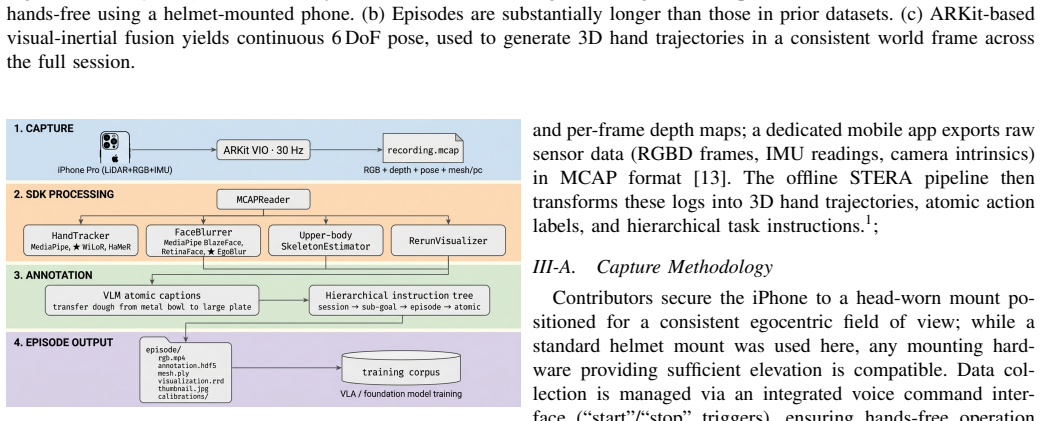
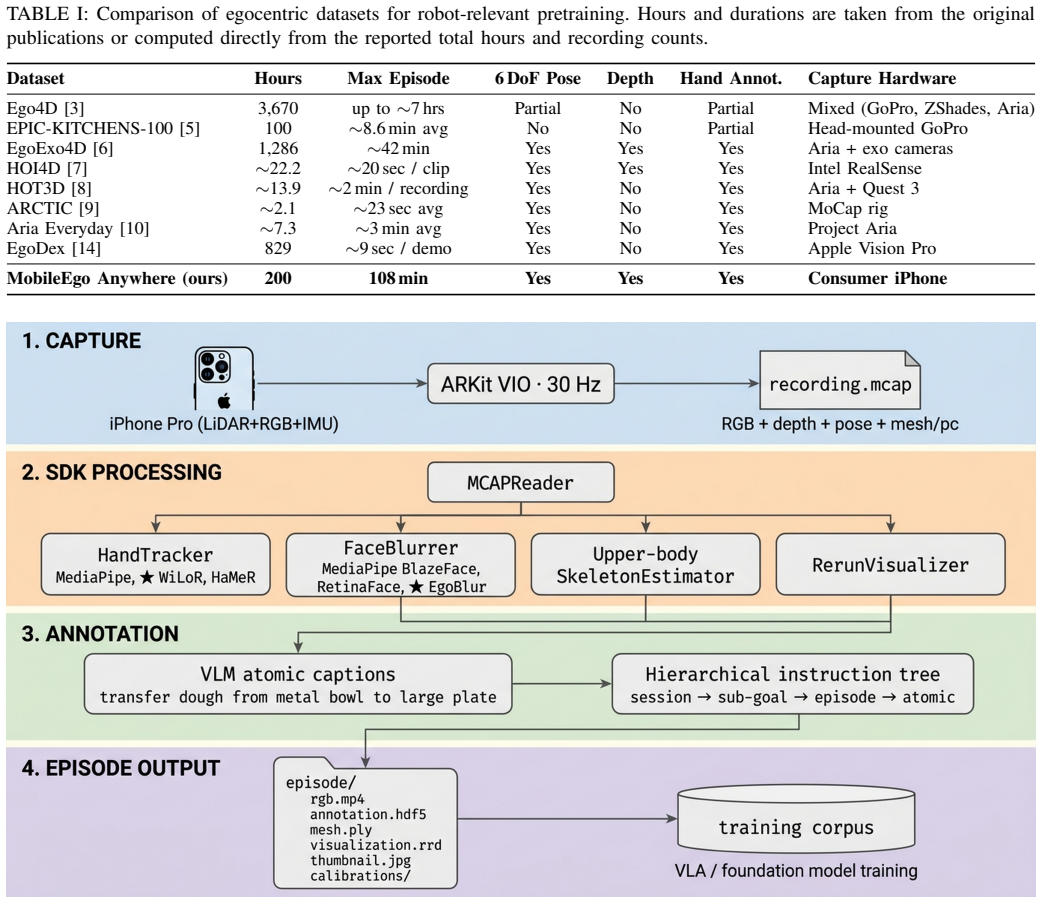




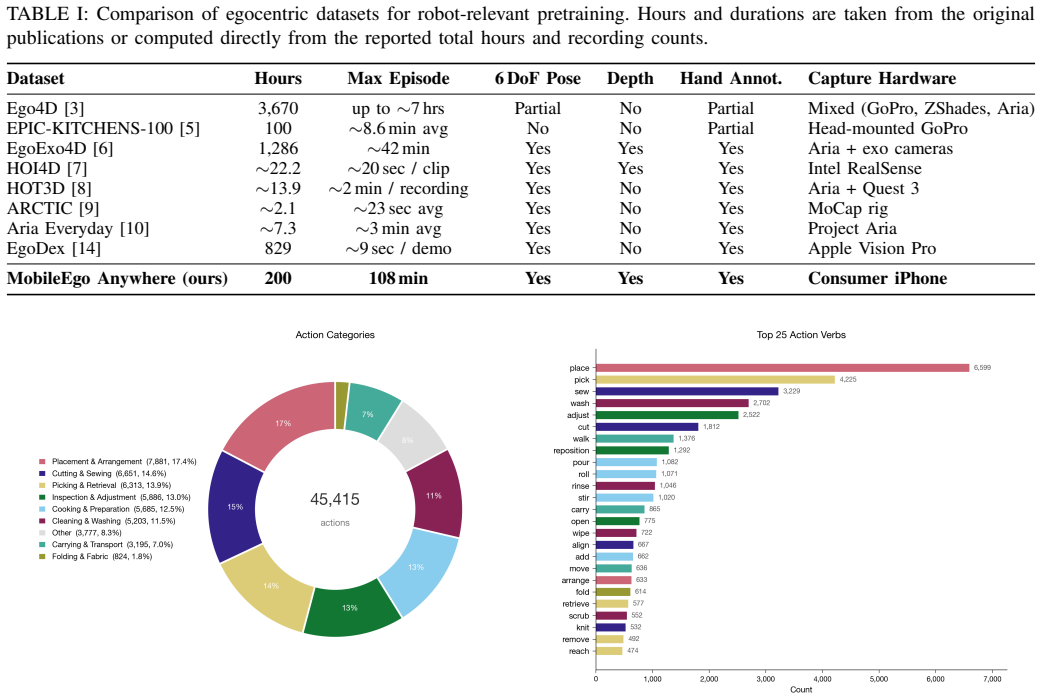






read the original abstract
The recent advancement of Vision Language Action (VLA) models has driven a critical demand for large scale egocentric datasets. However, existing datasets are often limited by short episode durations, typically spanning only a few minutes, which fails to capture the long horizon temporal dependencies necessary for complex robotic task execution. To bridge this gap, we present MobileEgo Anywhere, a framework designed to facilitate the collection of robust, hour plus egocentric trajectories using commodity mobile hardware. We leverage the ubiquitous sensor suites of modern smartphones to provide high fidelity, long term camera pose tracking, effectively removing the high hardware barriers associated with traditional robotics data collection. Our contributions are three fold: (1) we release a novel dataset comprising 200 hours of diverse, long form egocentric data with persistent state tracking; (2) we open source a mobile application that enables any user to record egocentric data, and (3) we provide a comprehensive processing pipeline to convert raw mobile captures into standardized, training ready formats for Vision Language Action model and foundation model research. By democratizing the data collection process, this work enables the massive scale acquisition of long horizon data across varied global environments, accelerating the development of generalizable robotic policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an open infrastructure called MobileEgo Anywhere for collecting long-horizon egocentric data using commodity mobile hardware. Key contributions include releasing a 200-hour dataset of diverse long-form egocentric trajectories with persistent state tracking, open-sourcing a mobile app for data recording, and providing a processing pipeline to convert raw captures into standardized formats for Vision Language Action (VLA) models and foundation model research. The work emphasizes leveraging ubiquitous smartphone sensors to achieve high-fidelity, long-term camera pose tracking, thereby lowering barriers to large-scale data collection.
Significance. If the results hold, this infrastructure could have substantial impact by enabling researchers worldwide to collect massive amounts of long-horizon egocentric data in varied real-world environments without specialized hardware. This would directly address the limitation of short episode durations in existing datasets and support the development of more capable VLA models for complex robotic tasks.
major comments (2)
- [Abstract] The assertion of 'high fidelity, long term camera pose tracking' using smartphone sensors lacks any supporting quantitative evidence, such as absolute trajectory error (ATE), relative pose error (RPE), or accumulated drift metrics over extended trajectories. Without these, it is unclear whether the released dataset maintains the accuracy required for persistent state tracking in long-horizon applications.
- [Abstract] The manuscript provides no ablation studies or error analysis on the tracking performance in challenging conditions like low-texture environments or dynamic scenes, which are essential to substantiate the claim that this approach effectively removes high hardware barriers.
minor comments (1)
- The abstract mentions 'diverse' data but does not specify the range of environments or activities covered, which would help readers assess the dataset's utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that strengthening the quantitative support for the tracking claims will improve the paper and will revise accordingly. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Abstract] The assertion of 'high fidelity, long term camera pose tracking' using smartphone sensors lacks any supporting quantitative evidence, such as absolute trajectory error (ATE), relative pose error (RPE), or accumulated drift metrics over extended trajectories. Without these, it is unclear whether the released dataset maintains the accuracy required for persistent state tracking in long-horizon applications.
Authors: We agree that explicit quantitative metrics would strengthen the claim. The MobileEgo Anywhere app uses the smartphone's native visual-inertial odometry, which is engineered for extended sessions. In the revised manuscript we will add a dedicated evaluation subsection that reports ATE and RPE on a representative subset of trajectories (computed via loop-closure consistency and cross-sequence alignment where external references are available) together with drift statistics over multi-hour captures. These numbers will be included in both the abstract and main text. revision: yes
-
Referee: [Abstract] The manuscript provides no ablation studies or error analysis on the tracking performance in challenging conditions like low-texture environments or dynamic scenes, which are essential to substantiate the claim that this approach effectively removes high hardware barriers.
Authors: We acknowledge the absence of systematic ablation studies. The original manuscript prioritizes the open infrastructure and dataset release over exhaustive benchmarking of the underlying tracker. In revision we will insert a concise robustness analysis section that (1) qualitatively documents failure modes observed in low-texture and dynamic scenes across the 200-hour corpus and (2) provides limited quantitative checks (e.g., pose consistency before/after loop closure) on representative challenging sequences. This will clarify the practical limits of commodity hardware while preserving the paper's primary focus on data accessibility. revision: yes
Circularity Check
No circularity: infrastructure and dataset release paper
full rationale
The paper presents an open-source framework and 200-hour egocentric dataset collected via commodity smartphones. No mathematical derivations, equations, parameter fittings, predictions, or self-citation chains appear in the provided text. The central claims concern data collection infrastructure and release rather than any derived result that reduces to its own inputs by construction. The assumption about smartphone pose tracking fidelity is presented as an enabling premise without any fitted quantities or self-referential logic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Smartphone sensor suites can deliver high fidelity long term camera pose tracking
Reference graph
Works this paper leans on
-
[1]
EgoScale: Scaling Dexterous Manipulation with Diverse Ego- centric Human Data,
R. Zheng, D. Niu, Y . Xie, J. Wang, M. Xu, Y . Jiang, F. Casta ˜neda, F. Hu, Y . L. Tan, L. Fu, T. Darrell, F. Huang, Y . Zhu, D. Xu, and L. Fan, “EgoScale: Scaling Dexterous Manipulation with Diverse Ego- centric Human Data,”arXiv preprint arXiv:2602.16710, 2026. [Online]. Available: https://arxiv.org/abs/2602.16710
-
[2]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots,
C. Chiet al., “Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots,” inProc. Robotics: Science and Systems (RSS), 2024
work page 2024
-
[3]
Ego4D: Around the World in 3,000 Hours of Egocentric Video,
K. Graumanet al., “Ego4D: Around the World in 3,000 Hours of Egocentric Video,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 18973-18990
work page 2022
-
[4]
Scaling Egocentric Video Recognition: The EPIC- KITCHENS Dataset,
D. Damenet al., “Scaling Egocentric Video Recognition: The EPIC- KITCHENS Dataset,” inProc. Eur . Conf. Comput. Vis. (ECCV), 2018, pp. 753-771
work page 2018
-
[5]
Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100,
D. Damenet al., “Rescaling Egocentric Vision: Collection, Pipeline and Challenges for EPIC-KITCHENS-100,”Int. J. Comput. Vis., vol. 130, no. 1, pp. 33-55, 2022
work page 2022
-
[6]
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives,
K. Graumanet al., “Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 19383–19400
work page 2024
-
[7]
HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction,
Y . Liuet al., “HOI4D: A 4D Egocentric Dataset for Category-Level Human-Object Interaction,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 21013–21022
work page 2022
-
[8]
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos,
S. Banerjeeet al., “HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025
work page 2025
-
[9]
ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation,
Z. Fanet al., “ARCTIC: A Dataset for Dexterous Bimanual Hand-Object Manipulation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 12943–12954
work page 2023
-
[10]
Aria Everyday Activities Dataset,
Z. Lvet al., “Aria Everyday Activities Dataset,”arXiv preprint arXiv:2402.13349, 2024. [Online]. Available: https://arxiv.org/abs/2402.13349
-
[11]
WiLoR: End-to-end 3D Hand Localization and Reconstruction in-the- wild,
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou, “WiLoR: End-to-end 3D Hand Localization and Reconstruction in-the- wild,”arXiv preprint arXiv:2409.12259, 2024. [Online]. Available: https://arxiv.org/abs/2409.12259
-
[12]
Embodied Hands: Modeling and Capturing Hands and Bodies Together,
J. Romero, D. Tzionas, and M. J. Black, “Embodied Hands: Modeling and Capturing Hands and Bodies Together,”ACM Trans. Graph. (Proc. SIGGRAPH Asia), vol. 36, no. 6, pp. 245:1–245:17, Nov. 2017
work page 2017
-
[13]
MCAP: serialization-agnostic log container file format,
Foxglove Developers, “MCAP: serialization-agnostic log container file format,”F oxglove Technologies, 2024. [Online]. Available: https://mcap.dev
work page 2024
-
[14]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang, “EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video,” arXiv preprint arXiv:2505.11709, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.