Recognition: unknown
HaM-World: Soft-Hamiltonian World Models with Selective Memory for Planning
Pith reviewed 2026-05-08 10:51 UTC · model grok-4.3
The pith
A world model that splits latent states into a soft-Hamiltonian (position-momentum) subspace and a separate context memory with selective state-space updates stabilizes long-horizon planning and improves robustness to dynamics shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HaM-World decomposes the latent state into a canonical (q, p) subspace that evolves through an energy-derived Hamiltonian vector field plus learnable residual and control dynamics, together with a context subspace c informed by Mamba selective state-space memory. This single latent representation is shared by dynamics prediction, reward and value estimation, imagined rollouts, and CEM planning. On four DeepMind Control Suite tasks the model records the highest average AUC of 117.9, reduces long-horizon rollout error to 45 percent of a strong baseline, and wins 11 of 12 cells in multi-horizon MSE comparisons. Under twelve out-of-distribution perturbations that include dynamics shifts, action,
What carries the argument
The soft-Hamiltonian vector field acting on the (q, p) subspace, augmented by learnable residuals and fed by Mamba selective memory into the context subspace c.
If this is right
- Bounded action-free Hamiltonian-energy drift across rollouts
- Structured energy variation that increases under policy-driven rollouts
- Coherent control-induced energy transfer between subspaces
- Highest return in every tested out-of-distribution condition
- Consistent wins across 3-, 5-, and 7-step MSE cells on control tasks
Where Pith is reading between the lines
- The same (q, p) plus context decomposition could be grafted onto other world-model backbones to test whether the geometric organization itself, rather than the specific Mamba memory, drives the stability gains.
- If the soft-Hamiltonian constraint truly limits energy drift, the approach may extend naturally to domains where physical conservation laws are known, such as robotic manipulation with contact dynamics.
- A direct test on tasks with longer horizons or partial observability would reveal whether the selective memory continues to supply sufficient Markov completeness when the planning horizon exceeds the training distribution.
- The observed energy-transfer diagnostics suggest that adding explicit dissipation terms to the c subspace might further reduce error accumulation in highly dissipative environments.
Load-bearing premise
Decomposing the latent state into a canonical (q, p) subspace evolving through an energy-derived Hamiltonian vector field plus learnable residuals, together with a context subspace c and Mamba memory, provides approximate Markov completeness and geometric organization sufficient to stabilize planning.
What would settle it
Long-horizon rollouts that exhibit unbounded Hamiltonian-energy drift or HaM-World failing to outperform strong baselines on additional tasks under the same twelve out-of-distribution perturbations would falsify the central claim.
Figures



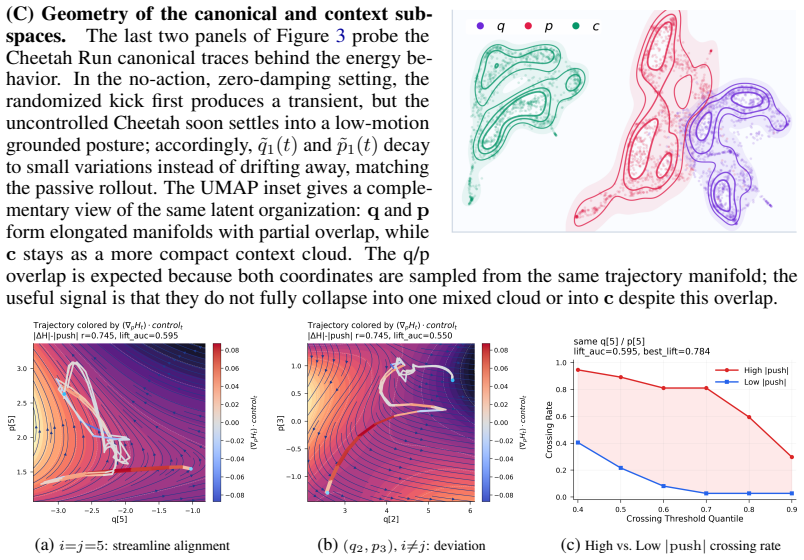

read the original abstract
World models enable model-based planning through learned latent dynamics, but imagined rollouts become unstable as the planning horizon grows or the dynamics distribution shifts. We argue that this instability reflects two missing structures in planner-facing latents: history-conditioned memory for approximate Markov completeness, and geometric organization that separates configuration, momentum, and task semantics. We propose HaM-World (HMW), a structured world model that decomposes the latent state into a canonical (q, p) subspace and a context subspace c, while using Mamba selective state-space memory as the history-conditioned input to the same latent dynamics. Within this interface, (q, p) evolves through an energy-derived Hamiltonian vector field plus learnable residual/control dynamics, while c captures semantic, dissipative, and non-conservative factors. This gives the planner a single latent state shared by dynamics prediction, reward/value estimation, imagined rollouts, and CEM action search. On four DeepMind Control Suite tasks, HaM-World reaches the highest Avg. AUC (117.9, +9.5%), reduces long-horizon rollout error to 45% of a strong baseline model, and wins 11/12 k in {3,5,7} MSE cells. Under 12 OOD perturbations spanning dynamics shifts, action delay, and observation masking, HaM-World achieves the highest return in every condition, with average OOD-return gains of 10.2% on Finger Spin and 13.6% on Reacher Easy. Mechanism diagnostics further show bounded action-free Hamiltonian-energy drift, structured energy variation under policy rollouts, and coherent control-induced energy transfer, supporting the intended Soft-Hamiltonian dynamics design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HaM-World, a structured world model for model-based planning that decomposes the latent state into a canonical (q, p) subspace evolving under an energy-derived soft-Hamiltonian vector field plus learnable residuals, a context subspace c capturing semantic and dissipative factors, and Mamba selective state-space memory for history-conditioned dynamics. The shared latent state supports dynamics prediction, reward estimation, imagined rollouts, and CEM planning. On four DeepMind Control Suite tasks, it reports the highest Avg. AUC (117.9, +9.5%), long-horizon rollout error reduced to 45% of a strong baseline, wins in 11/12 MSE cells across horizons, and highest returns under all 12 OOD perturbations (dynamics shifts, action delay, observation masking), with mechanism diagnostics showing bounded energy drift.
Significance. If the results hold, this demonstrates that injecting Hamiltonian geometric structure alongside selective memory into planner-facing latents can stabilize long-horizon rollouts and improve OOD robustness in world models. The paper supplies concrete, multi-task empirical gains on standard benchmarks together with energy-drift diagnostics that directly test the intended soft-Hamiltonian design.
major comments (2)
- [Section 5.2 and 5.3] The central claim attributes rollout stability and OOD gains to the joint (q, p) Hamiltonian evolution plus Mamba memory, yet the manuscript contains no ablation that retains the latent decomposition and Mamba input while replacing the energy-derived Hamiltonian vector field with an unstructured learned dynamics function. Without this control, the 55% rollout-error reduction and consistent OOD gains cannot be attributed to the Hamiltonian term rather than the decomposition or memory alone (abstract; Section 5.2 rollout results; Section 5.3 mechanism diagnostics).
- [Section 5.3] The mechanism diagnostics confirm bounded action-free energy drift and coherent control-induced energy transfer under the full model, but provide no comparative diagnostics under a non-Hamiltonian dynamics variant; this leaves open whether the geometric organization is load-bearing for the reported stability (Section 5.3).
minor comments (2)
- [Abstract] The abstract states 'wins 11/12 k in {3,5,7} MSE cells' without defining k or the cells; this should be clarified or cross-referenced to the corresponding table or figure.
- [Model description] The precise mathematical form combining the Hamiltonian vector field with the learnable residual/control dynamics is described in prose but would benefit from an explicit equation in the model section.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our paper. We address the major concerns regarding the attribution of performance gains to the Hamiltonian structure by committing to additional ablation studies in the revised manuscript.
read point-by-point responses
-
Referee: [Section 5.2 and 5.3] The central claim attributes rollout stability and OOD gains to the joint (q, p) Hamiltonian evolution plus Mamba memory, yet the manuscript contains no ablation that retains the latent decomposition and Mamba input while replacing the energy-derived Hamiltonian vector field with an unstructured learned dynamics function. Without this control, the 55% rollout-error reduction and consistent OOD gains cannot be attributed to the Hamiltonian term rather than the decomposition or memory alone (abstract; Section 5.2 rollout results; Section 5.3 mechanism diagnostics).
Authors: We agree that an ablation isolating the Hamiltonian vector field is necessary to strengthen the causal attribution of the observed improvements. The current experiments demonstrate the overall effectiveness of HaM-World, but do not directly compare against a non-Hamiltonian dynamics model with the same decomposition and memory components. In the revised version, we will introduce this control experiment: a variant that uses the same latent decomposition into (q, p) and c subspaces, Mamba memory, but replaces the energy-derived soft-Hamiltonian dynamics with a standard learned residual dynamics function (e.g., MLP-based). We will evaluate this variant on the same rollout error metrics, OOD perturbations, and include energy diagnostics for comparison. This will be detailed in updated Sections 5.2 and 5.3, allowing readers to assess the specific contribution of the geometric structure. revision: yes
-
Referee: [Section 5.3] The mechanism diagnostics confirm bounded action-free energy drift and coherent control-induced energy transfer under the full model, but provide no comparative diagnostics under a non-Hamiltonian dynamics variant; this leaves open whether the geometric organization is load-bearing for the reported stability (Section 5.3).
Authors: We concur that comparative energy diagnostics are important to confirm that the bounded drift and structured energy behavior are due to the soft-Hamiltonian design rather than other model components. As part of the ablation study outlined in response to the first comment, we will compute and report the action-free energy drift and control-induced energy transfer for the non-Hamiltonian variant. This will provide direct evidence on whether the geometric organization is load-bearing for stability. These results will be incorporated into Section 5.3 of the revised manuscript. revision: yes
Circularity Check
No load-bearing circularity; performance claims rest on external benchmark comparisons
full rationale
The paper's core contribution is an architectural proposal (latent decomposition into (q,p) + c with soft-Hamiltonian evolution plus Mamba memory) whose value is asserted via direct empirical comparisons on DeepMind Control Suite tasks, long-horizon MSE, and 12 OOD perturbations. No equation or 'prediction' is shown to equal its own fitted inputs by construction, and no uniqueness theorem or ansatz is imported via self-citation to force the design. The reported gains (AUC 117.9, 55% error reduction, consistent OOD wins) are therefore falsifiable against baselines rather than tautological. A score of 2 accounts for the possibility of minor unexamined self-citations in the full text while confirming the central claims remain independently testable.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights for dynamics, memory, and reward models
axioms (1)
- domain assumption Latent states can be structured into (q, p) and c subspaces with Hamiltonian evolution providing geometric organization and approximate Markov completeness
invented entities (1)
-
Soft-Hamiltonian vector field in latent (q, p) subspace
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution.Ad- vances in neural information processing systems, 31, 2018
2018
-
[2]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[3]
Hamiltonian neural networks.Advances in neural information processing systems, 32, 2019
Samuel Greydanus, Misko Dzamba, and Jason Yosinski. Hamiltonian neural networks.Advances in neural information processing systems, 32, 2019
2019
-
[4]
Symplectic ode-net: Learning hamiltonian dynamics with control
Yaofeng Desmond Zhong, Biswadip Dey, and Amit Chakraborty. Symplectic ode-net: Learning hamiltonian dynamics with control. InInternational Conference on Learning Representations, 2020
2020
-
[5]
When to trust your model: Model-based policy optimization.Advances in neural information processing systems, 32, 2019
Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. When to trust your model: Model-based policy optimization.Advances in neural information processing systems, 32, 2019
2019
-
[6]
Denoised MDPs: Learning world models better than the world itself
Tongzhou Wang, Simon Du, Antonio Torralba, Phillip Isola, Amy Zhang, and Yuandong Tian. Denoised MDPs: Learning world models better than the world itself. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of ...
2022
-
[7]
Learning world models with identifiable factorization.Advances in Neural Information Processing Systems, 36:31831–31864, 2023
Yuren Liu, Biwei Huang, Zhengmao Zhu, Honglong Tian, Mingming Gong, Yang Yu, and Kun Zhang. Learning world models with identifiable factorization.Advances in Neural Information Processing Systems, 36:31831–31864, 2023
2023
-
[8]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024
2024
-
[9]
Action-conditioned hamiltonian generative networks (ac-hgn) for supervised and reinforcement learning
Arne Troch, Kevin Mets, and Siegfried Mercelis. Action-conditioned hamiltonian generative networks (ac-hgn) for supervised and reinforcement learning. In7th Annual Learning for Dynamics & Control Conference, 04-06 June, 2025, Ann Arbor, Michigan, USA, pages 310–322, 2025
2025
-
[10]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
2023
-
[11]
The cross-entropy method for combinatorial and continuous optimization
Reuven Y Rubinstein. The cross-entropy method for combinatorial and continuous optimization. Methodology and computing in applied probability, 1(2):127–190, 1999
1999
-
[12]
Yuval Tassa, Yotam Doron, Alistair Muldal, Tom Erez, Yazhe Li, Diego de Las Casas, David Budden, Abbas Abdolmaleki, Josh Merel, Andrew Lefrancq, Timothy Lillicrap, and Martin Riedmiller. Deepmind control suite.arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[13]
Dyna, an integrated architecture for learning, planning, and reacting.ACM Sigart Bulletin, 2(4):160–163, 1991
Richard S Sutton. Dyna, an integrated architecture for learning, planning, and reacting.ACM Sigart Bulletin, 2(4):160–163, 1991
1991
-
[14]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
2019
-
[15]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representa- tions, 2020
2020
-
[16]
Mastering atari with discrete world models
Danijar Hafner, Timothy P Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models. InInternational Conference on Learning Representations, 2021. 10
2021
-
[17]
Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Si- mon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
2020
-
[18]
Temporal difference learning for model predictive control
Nicklas A Hansen, Hao Su, and Xiaolong Wang. Temporal difference learning for model predictive control. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvari, Gang Niu, and Sivan Sabato, editors,Proceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 8387–8406. PMLR, 1...
2022
-
[19]
TD-MPC2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[20]
Learning hierarchical world models with adaptive temporal abstractions from discrete latent dynamics
Christian Gumbsch, Noor Sajid, Georg Martius, and Martin V Butz. Learning hierarchical world models with adaptive temporal abstractions from discrete latent dynamics. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
Bootstrapped model predictive control
Yuhang Wang, Hanwei Guo, Sizhe Wang, Long Qian, and Xuguang Lan. Bootstrapped model predictive control. In Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors,International Conference on Learning Representations, volume 2025, pages 54241–54259, 2025
2025
-
[22]
PWM: Policy learn- ing with multi-task world models
Ignat Georgiev, Varun Giridhar, Nicklas Hansen, and Animesh Garg. PWM: Policy learn- ing with multi-task world models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[23]
Parallelizing model-based reinforcement learning over the sequence length.Advances in Neural Information Processing Systems, 37: 131398–131433, 2024
ZiRui Wang, Yue Deng, Junfeng Long, and Yin Zhang. Parallelizing model-based reinforcement learning over the sequence length.Advances in Neural Information Processing Systems, 37: 131398–131433, 2024
2024
-
[24]
SOMBRL: Scalable and optimistic model-based RL
Bhavya Sukhija, Lenart Treven, Carmelo Sferrazza, Florian Dorfler, Pieter Abbeel, and Andreas Krause. SOMBRL: Scalable and optimistic model-based RL. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[26]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[27]
Transformers are sample-efficient world models
Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient world models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[28]
Storm: Efficient stochastic transformer based world models for reinforcement learning.Advances in Neural Information Processing Systems, 36:27147–27166, 2023
Weipu Zhang, Gang Wang, Jian Sun, Yetian Yuan, and Gao Huang. Storm: Efficient stochastic transformer based world models for reinforcement learning.Advances in Neural Information Processing Systems, 36:27147–27166, 2023
2023
-
[29]
ivideogpt: Interactive videogpts are scalable world models.Advances in Neural Information Processing Systems, 37:68082–68119, 2024
Jialong Wu, Shaofeng Yin, Ningya Feng, Xu He, Dong Li, Jianye Hao, and Mingsheng Long. ivideogpt: Interactive videogpts are scalable world models.Advances in Neural Information Processing Systems, 37:68082–68119, 2024
2024
-
[30]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
2024
-
[31]
EDELINE: Enhancing memory in diffusion-based world models via linear-time sequence modeling
Jia-Hua Lee, Bor-Jiun Lin, Wei-Fang Sun, and Chun-Yi Lee. EDELINE: Enhancing memory in diffusion-based world models via linear-time sequence modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[32]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024. 11
2024
-
[33]
Learning interactive real-world simulators
Sherry Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[34]
Genrl: Multimodal-foundation world models for generalization in embodied agents.Advances in neural information processing systems, 37:27529–27555, 2024
Pietro Mazzaglia, Tim Verbelen, Bart Dhoedt, Aaron Courville, and Sai Rajeswar. Genrl: Multimodal-foundation world models for generalization in embodied agents.Advances in neural information processing systems, 37:27529–27555, 2024
2024
-
[35]
Operator world models for reinforcement learning.Advances in Neural Information Processing Systems, 37: 111432–111463, 2024
Pietro Novelli, Marco Pratticò, Massimiliano Pontil, and Carlo Ciliberto. Operator world models for reinforcement learning.Advances in Neural Information Processing Systems, 37: 111432–111463, 2024
2024
-
[36]
Policy-shaped prediction: avoiding distractions in model-based reinforcement learning.Advances in Neural Information Processing Systems, 37: 13124–13148, 2024
Miles Hutson, Isaac Kauvar, and Nick Haber. Policy-shaped prediction: avoiding distractions in model-based reinforcement learning.Advances in Neural Information Processing Systems, 37: 13124–13148, 2024
2024
-
[37]
Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
2025
-
[38]
Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. Featured Certification
2024
-
[39]
Connecting joint-embedding predictive architecture with contrastive self-supervised learning.Advances in neural information processing systems, 37: 2348–2377, 2024
Shentong Mo and Shengbang Tong. Connecting joint-embedding predictive architecture with contrastive self-supervised learning.Advances in neural information processing systems, 37: 2348–2377, 2024
2024
-
[40]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review arXiv 2025
-
[41]
Learning invariant representations for reinforcement learning without reconstruction
Amy Zhang, Rowan Thomas McAllister, Roberto Calandra, Yarin Gal, and Sergey Levine. Learning invariant representations for reinforcement learning without reconstruction. InInter- national Conference on Learning Representations, 2021
2021
-
[42]
Dreaming: Model-based reinforcement learning by latent imagination without reconstruction
Masashi Okada and Tadahiro Taniguchi. Dreaming: Model-based reinforcement learning by latent imagination without reconstruction. In2021 ieee international conference on robotics and automation (icra), pages 4209–4215. IEEE, 2021
2021
-
[43]
Dreamerpro: Reconstruction-free model-based rein- forcement learning with prototypical representations
Fei Deng, Ingook Jang, and Sungjin Ahn. Dreamerpro: Reconstruction-free model-based rein- forcement learning with prototypical representations. InInternational conference on machine learning, pages 4956–4975. PMLR, 2022
2022
-
[44]
TD- JEPA: Latent-predictive representations for zero-shot reinforcement learning
Marco Bagatella, Matteo Pirotta, Ahmed Touati, Alessandro Lazaric, and Andrea Tirinzoni. TD- JEPA: Latent-predictive representations for zero-shot reinforcement learning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[45]
Solar: Deep structured representations for model-based reinforcement learning
Marvin Zhang, Sharad Vikram, Laura Smith, Pieter Abbeel, Matthew Johnson, and Sergey Levine. Solar: Deep structured representations for model-based reinforcement learning. In International conference on machine learning, pages 7444–7453. PMLR, 2019
2019
-
[46]
Planning to explore via self-supervised world models
Ramanan Sekar, Oleh Rybkin, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, and Deepak Pathak. Planning to explore via self-supervised world models. InInternational conference on machine learning, pages 8583–8592. PMLR, 2020
2020
-
[47]
Disentangled world models: Learning to transfer semantic knowledge from distracting videos for reinforcement learning
Qi Wang, Zhipeng Zhang, Baao Xie, Xin Jin, Yunbo Wang, Shiyu Wang, Liaomo Zheng, Xiaokang Yang, and Wenjun Zeng. Disentangled world models: Learning to transfer semantic knowledge from distracting videos for reinforcement learning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2599–2608, 2025. 12
2025
-
[48]
Dymodreamer: World modeling with dynamic modulation
Boxuan Zhang, Runqing Wang, Wei Xiao, Weipu Zhang, Jian Sun, Gao Huang, Jie Chen, and Gang Wang. Dymodreamer: World modeling with dynamic modulation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[49]
Banerjee
Frank Röder, Jan Benad, Manfred Eppe, and Pradeep Kr. Banerjee. Dynamics-aligned latent imagination in contextual world models for zero-shot generalization. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[50]
DMWM: Dual-mind world model with long-term imagination
Lingyi Wang, Rashed Shelim, Walid Saad, and Naren Ramakrishnan. DMWM: Dual-mind world model with long-term imagination. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[51]
Roth, Dominik K
Fabian J. Roth, Dominik K. Klein, Maximilian Kannapinn, Jan Peters, and Oliver Weeger. Stable port-hamiltonian neural networks. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[52]
Roboscape: Physics-informed embodied world model
Yu Shang, Xin Zhang, Yinzhou Tang, Lei Jin, Chen Gao, Wei Wu, and Yong Li. Roboscape: Physics-informed embodied world model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[53]
Spectral normalization for generative adversarial networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. InInternational Conference on Learning Representations, 2018
2018
-
[54]
Structured state space models for in-context reinforcement learning
Chris Lu, Yannick Schroecker, Albert Gu, Emilio Parisotto, Jakob Foerster, Satinder Singh, and Feryal Behbahani. Structured state space models for in-context reinforcement learning. Advances in Neural Information Processing Systems, 36:47016–47031, 2023
2023
-
[55]
Decision mamba: A multi-grained state space model with self-evolution regularization for offline rl.Advances in neural information processing systems, 37:22827–22849, 2024
Qi Lv, Xiang Deng, Gongwei Chen, Michael Y Wang, and Liqiang Nie. Decision mamba: A multi-grained state space model with self-evolution regularization for offline rl.Advances in neural information processing systems, 37:22827–22849, 2024
2024
-
[56]
Accelerating model- based reinforcement learning with state-space world models
Elie Aljalbout, Maria Krinner, Angel Romero, and Davide Scaramuzza. Accelerating model- based reinforcement learning with state-space world models. InICLR 2025 Workshop on World Models: Understanding, Modelling and Scaling, 2025
2025
-
[57]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceeding...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.