Recognition: unknown
TableVista: Benchmarking Multimodal Table Reasoning under Visual and Structural Complexity
Pith reviewed 2026-05-08 10:53 UTC · model grok-4.3
The pith
TableVista shows current multimodal models hold up across rendering styles but drop sharply on complex table structures and vision-only inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TableVista consists of 3,000 base table reasoning problems each expanded through a multi-style rendering pipeline into ten variants that include diverse scenario styles, robustness perturbations, and vision-only setups, producing 30,000 total samples; evaluation of 29 models shows stability across rendering styles but pronounced drops on complex structural layouts and vision-only conditions, indicating models lose reasoning consistency precisely when structural complexity meets visually integrated presentations.
What carries the argument
The multi-style rendering and transformation pipeline that systematically generates scenario styles, robustness perturbations, and vision-only configurations from each base table problem.
If this is right
- Future models must improve integration of visual cues with intricate row-column relationships.
- Training data for table tasks should include more examples where text is embedded only in images.
- Benchmarking protocols need separate tracks for structural complexity to track progress.
- Applications that rely on tables in documents or screenshots will require additional safeguards.
Where Pith is reading between the lines
- The same controlled variant generation approach could be applied to other structured visual data such as charts or forms.
- Developers may need new architectural components that explicitly model table grid relations before visual encoding.
- Real deployment in data-entry or analysis tools could benefit from hybrid systems that fall back to text extraction when vision-only performance is low.
Load-bearing premise
The 3,000 base problems and the visual variants generated from them are taken to represent the full range of real-world multimodal table reasoning difficulties.
What would settle it
A follow-up study that applies the same complex-layout and vision-only test conditions to an independently collected set of real-world tables and finds no performance degradation would falsify the central claim.
Figures




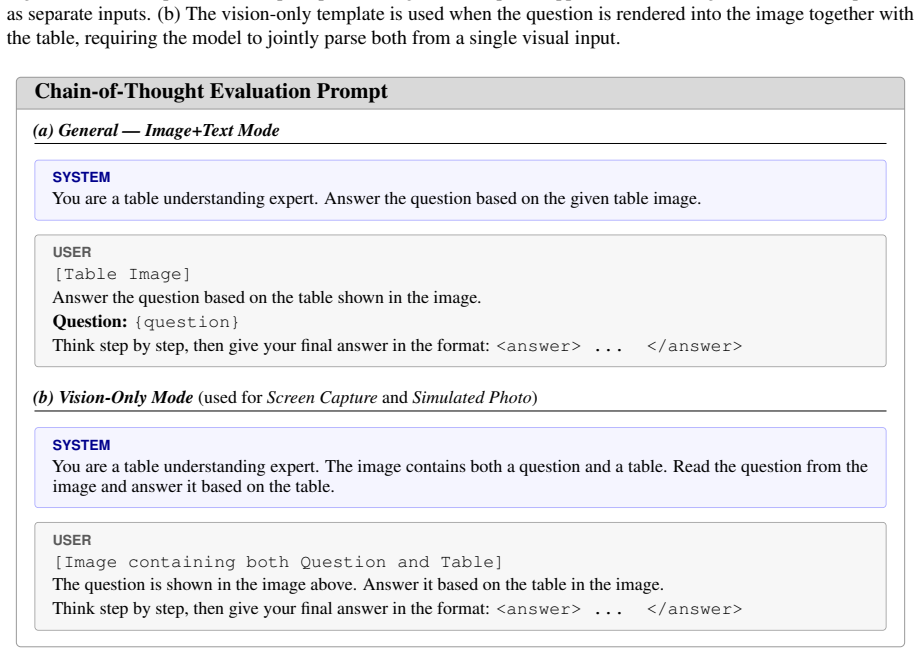


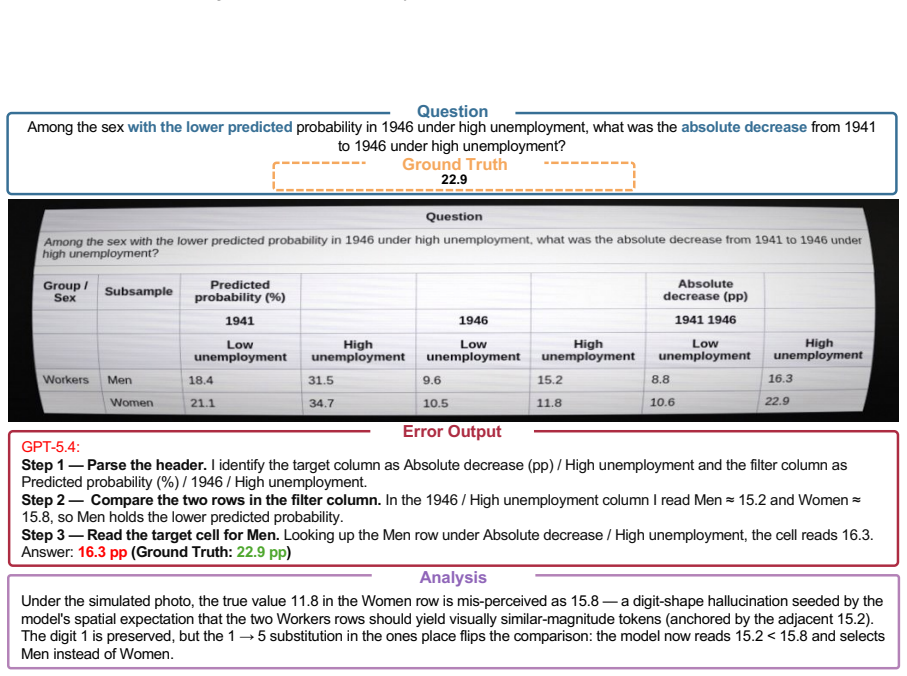
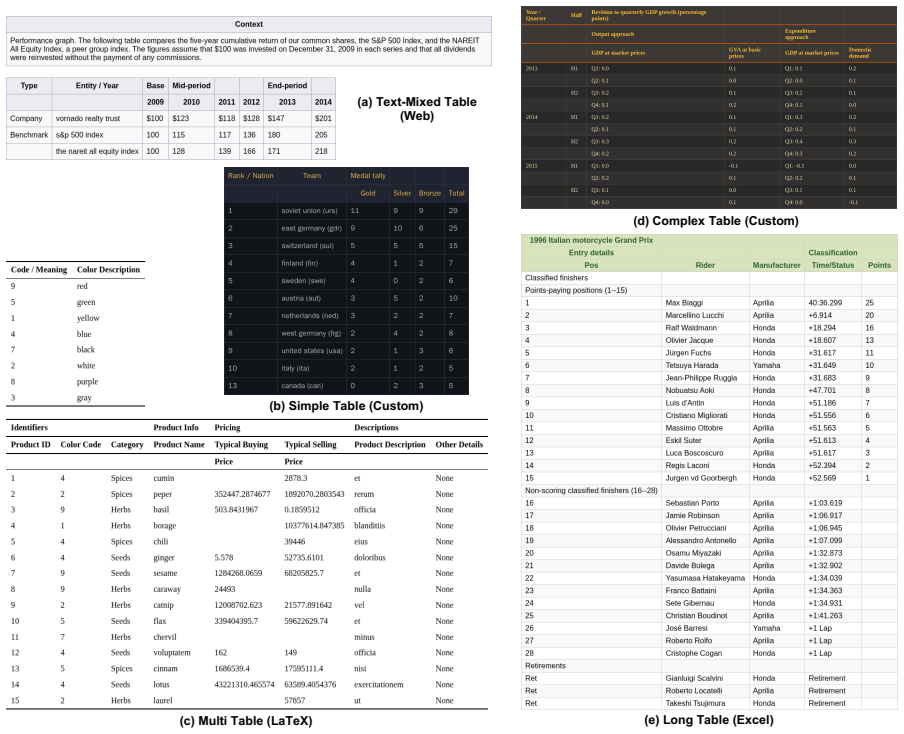
read the original abstract
We introduce TableVista, a comprehensive benchmark for evaluating foundation models in multimodal table reasoning under visual and structural complexity. TableVista consists of 3,000 high-quality table reasoning problems, where each instance is expanded into 10 distinct visual variants through our multi-style rendering and transformation pipeline. This process encompasses diverse scenario styles, robustness perturbations, and vision-only configurations, culminating in 30,000 multimodal samples for a multi-dimensional evaluation. We conduct an extensive evaluation of 29 state-of-the-art open-source and proprietary foundation models on TableVista. Through comprehensive quantitative and qualitative analysis, we find that while evaluated models remain largely stable across diverse rendering styles, they exhibit pronounced performance degradation on complex structural layouts and vision-only settings, revealing that current models struggle to maintain reasoning consistency when structural complexity combines with visually integrated presentations. These findings highlight critical gaps in current multimodal capabilities, providing insights for advancing more robust and reliable table understanding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TableVista, a benchmark with 3,000 table reasoning problems expanded via a multi-style rendering and transformation pipeline into 10 visual variants (including robustness perturbations and vision-only configurations) for a total of 30,000 multimodal samples. It evaluates 29 open-source and proprietary foundation models and reports that models remain largely stable across rendering styles but exhibit pronounced performance degradation on complex structural layouts and vision-only settings, concluding that current models struggle to maintain reasoning consistency when structural complexity combines with visually integrated presentations.
Significance. If the benchmark construction and evaluation protocol hold, this work offers a useful multi-dimensional framework for diagnosing limitations in multimodal table reasoning, particularly the interaction of structural complexity with visual presentation. The scale of the evaluation across 29 models and the isolation of rendering, structure, and vision-only factors provide concrete evidence of gaps that could inform model development. The absence of circularity or fitted parameters in the empirical setup is a strength.
major comments (2)
- [Abstract / benchmark construction] Abstract and benchmark construction section: the central claim of faithful capture of real-world multimodal table reasoning challenges rests on the 3,000 base problems and their variants, yet no details are given on problem validation, inter-annotator agreement, or diversity statistics relative to existing table datasets; this directly affects the interpretability of the reported degradation trends.
- [Evaluation and analysis] Evaluation protocol: the abstract reports performance degradation on complex structural layouts and vision-only settings but provides no information on statistical significance testing, variance across runs, or controls for prompt sensitivity, which is load-bearing for the claim that models 'struggle to maintain reasoning consistency'.
minor comments (2)
- A diagram or table summarizing the 10 visual variants and their generation process would improve clarity of the multi-style rendering pipeline.
- The paper should explicitly state the exact metrics used for table reasoning accuracy and any handling of partial credit or answer normalization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. The comments identify opportunities to strengthen the presentation of benchmark quality and evaluation rigor. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / benchmark construction] Abstract and benchmark construction section: the central claim of faithful capture of real-world multimodal table reasoning challenges rests on the 3,000 base problems and their variants, yet no details are given on problem validation, inter-annotator agreement, or diversity statistics relative to existing table datasets; this directly affects the interpretability of the reported degradation trends.
Authors: We agree that explicit details on base problem quality are necessary for full interpretability. In the revised manuscript, we will expand the benchmark construction section to report: (1) the validation process for the 3,000 problems, including sourcing from public table corpora followed by manual quality review; (2) inter-annotator agreement metrics where multiple annotators participated in labeling or verification; and (3) diversity statistics (e.g., distributions of table sizes, reasoning types, and domain coverage) with direct comparisons to existing datasets such as WikiTableQuestions, TabFact, and HybridQA. These additions will better ground the claim that the observed degradation trends reflect real-world multimodal table reasoning challenges. revision: yes
-
Referee: [Evaluation and analysis] Evaluation protocol: the abstract reports performance degradation on complex structural layouts and vision-only settings but provides no information on statistical significance testing, variance across runs, or controls for prompt sensitivity, which is load-bearing for the claim that models 'struggle to maintain reasoning consistency'.
Authors: We acknowledge that formal statistical support and controls for prompt sensitivity strengthen the central claims. Although our experiments already included multiple prompt phrasings and consistent trends across all 29 models, these were not reported with sufficient detail. In the revision, we will add a dedicated subsection on the evaluation protocol that includes: (1) statistical significance testing (e.g., paired tests or bootstrap confidence intervals) for the reported performance drops on complex structures and vision-only settings; (2) variance measures (mean and standard deviation) across repeated runs with varied random seeds and prompt templates; and (3) explicit analysis of prompt sensitivity. These changes will provide quantitative backing for the conclusion that models struggle to maintain reasoning consistency under combined structural and visual complexity. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper that introduces TableVista (3,000 base problems expanded via rendering pipeline into 30,000 samples) and reports direct evaluation results on 29 models. The central claims are observational findings about model stability and degradation; there are no derivations, equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the results to the inputs by construction. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected 3,000 problems test genuine table reasoning rather than superficial pattern matching
Reference graph
Works this paper leans on
-
[1]
I \ n igo Alonso, Imanol Miranda, Eneko Agirre, and Mirella Lapata. 2026. https://openreview.net/forum?id=5UbeQDlYDj TABLET : A large-scale dataset for robust visual table understanding . In The Fourteenth International Conference on Learning Representations
2026
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, and 45 others. 2025 a . https://arxiv.org/abs/2511.21631 Qwen3-vl technical report . Preprint, arXiv:2511.21631
work page internal anchor Pith review arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025 b . https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review arXiv 2025
- [4]
-
[5]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. https://doi.org/10.18653/v1/2021.emnlp-main.300 F in QA : A dataset of numerical reasoning over financial data . In Proceedings of the 2021 Conference on Empirical Methods in Natural Lang...
-
[6]
Zhoujun Cheng, Haoyu Dong, Zhiruo Wang, Ran Jia, Jiaqi Guo, Yan Gao, Shi Han, Jian-Guang Lou, and Dongmei Zhang. 2022. https://doi.org/10.18653/v1/2022.acl-long.78 H i T ab: A hierarchical table dataset for question answering and natural language generation . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volum...
-
[7]
Google DeepMind. 2026. https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ Gemma 4
2026
-
[8]
Naihao Deng, Zhenjie Sun, Ruiqi He, Aman Sikka, Yulong Chen, Lin Ma, Yue Zhang, and Rada Mihalcea. 2024. https://doi.org/10.18653/v1/2024.findings-acl.23 Tables as texts or images: Evaluating the table reasoning ability of LLM s and MLLM s . In Findings of the Association for Computational Linguistics: ACL 2024, pages 407--426, Bangkok, Thailand. Associat...
-
[9]
Allen Institute for AI. 2025. https://allenai.org/papers/molmo2 Molmo2: Open weights and data for vision-language models with video understanding and grounding
2025
-
[10]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/s41586-025-09422-z Deepseek-r1 incentivizes reasoning in llms through reinforcement lear...
-
[11]
Jun-Peng Jiang, Yu Xia, Hai-Long Sun, Shiyin Lu, Qing-Guo Chen, Weihua Luo, Kaifu Zhang, De-Chuan Zhan, and Han-Jia Ye. 2026. https://openreview.net/forum?id=AuBSUgFVgq Multimodal tabular reasoning with privileged structured information . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
- [12]
-
[13]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024 a . Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26296--26306
2024
-
[14]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024 b . https://llava-vl.github.io/blog/2024-01-30-llava-next/ Llava-next: Improved reasoning, ocr, and world knowledge
2024
-
[15]
Suyash Vardhan Mathur, Jainit Sushil Bafna, Kunal Kartik, Harshita Khandelwal, Manish Shrivastava, Vivek Gupta, Mohit Bansal, and Dan Roth. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.822 Knowledge-aware reasoning over multimodal semi-structured tables . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 14054--14073...
-
[16]
Meta. 2025. https://ai.meta.com/blog/llama-4-multimodal-intelligence/ Llama 4
2025
-
[17]
Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kry \'s ci \'n ski, Hailey Schoelkopf, Riley Kong, Xiangru Tang, Mutethia Mutuma, Ben Rosand, Isabel Trindade, Renusree Bandaru, Jacob Cunningham, Caiming Xiong, and Dragomir Radev. 2022. https://doi.org/10.1162/tacl_a_00446 F e T a QA : Free-form table question answ...
-
[18]
OpenAI. 2026 a . https://openai.com/index/introducing-gpt-5-4/ Gpt-5.4
2026
-
[19]
OpenAI. 2026 b . http://openai.com/index/introducing-gpt-5-4-mini-and-nano/ Gpt-5.4-mini
2026
-
[20]
Panupong Pasupat and Percy Liang. 2015. https://doi.org/10.3115/v1/P15-1142 Compositional semantic parsing on semi-structured tables . In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 1470--1480, Beijing, China...
-
[21]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.6-35b-a3b Qwen3.6-35B-A3B : Agentic coding power, now open to all
2026
-
[22]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
work page internal anchor Pith review arXiv 2025
-
[23]
Qwen Team. 2026. https://qwen.ai/blog?id=qwen3.5 Qwen3.5: Accelerating productivity with native multimodal agents
2026
- [24]
-
[25]
Lanrui Wang, Mingyu Zheng, Hongyin Tang, Zheng Lin, Yanan Cao, Jingang Wang, Xunliang Cai, and Weiping Wang. 2026. https://openreview.net/forum?id=z5vZDI2r6J Needlein AT able: Exploring long-context capability of large language models towards long-structured tables . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2026
-
[26]
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, and 56 others. 2025. https://arxiv.org/abs/2508.18265 Internvl3.5: Advancing open-source multimodal models in versatility, r...
work page internal anchor Pith review arXiv 2025
-
[27]
Jian Wu, Linyi Yang, Dongyuan Li, Yuliang Ji, Manabu Okumura, and Yue Zhang. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/794a425a2e47e05d29d30f79b79a692d-Paper-Conference.pdf Mmqa: Evaluating llms with multi-table multi-hop complex questions . In International Conference on Learning Representations, volume 2025, pages 48626--48643
2025
- [28]
-
[29]
Zheyuan Yang, Lyuhao Chen, Arman Cohan, and Yilun Zhao. 2025 b . https://doi.org/10.18653/v1/2025.emnlp-main.1040 Table-r1: Inference-time scaling for table reasoning tasks . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20605--20624, Suzhou, China. Association for Computational Linguistics
-
[30]
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wenshuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, Bokai Xu, Junbo Cui, Yingjing Xu, Liqing Ruan, Luoyuan Zhang, Hanyu Liu, Jingkun Tang, Hongyuan Liu, Qining Guo, and 15 others. 2025. https://arxiv.org/abs/2509.18154 Minicpm-v 4.5: Cooking efficient mllms via architecture, data,...
- [31]
-
[32]
Tianshu Zhang, Xiang Yue, Yifei Li, and Huan Sun. 2024. https://doi.org/10.18653/v1/2024.naacl-long.335 T able L lama: Towards open large generalist models for tables . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6024--6044,...
-
[33]
Weichao Zhao, Hao Feng, Qi Liu, Jingqun Tang, Shu Wei, Binghong Wu, Lei Liao, Yongjie Ye, Hao Liu, Wengang Zhou, Houqiang Li, and Can Huang. 2024 a . https://doi.org/10.52202/079017-0230 Tabpedia: Towards comprehensive visual table understanding with concept synergy . In Advances in Neural Information Processing Systems, volume 37, pages 7185--7212. Curra...
-
[34]
Yilun Zhao, Yitao Long, Hongjun Liu, Ryo Kamoi, Linyong Nan, Lyuhao Chen, Yixin Liu, Xiangru Tang, Rui Zhang, and Arman Cohan. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.852 D oc M ath-eval: Evaluating math reasoning capabilities of LLM s in understanding long and specialized documents . In Proceedings of the 62nd Annual Meeting of the Association...
-
[35]
Yilun Zhao, Zhenting Qi, Linyong Nan, Boyu Mi, Yixin Liu, Weijin Zou, Simeng Han, Ruizhe Chen, Xiangru Tang, Yumo Xu, Dragomir Radev, and Arman Cohan. 2023 a . https://doi.org/10.18653/v1/2023.emnlp-main.74 QTS umm: Query-focused summarization over tabular data . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pa...
-
[36]
Yilun Zhao, Chen Zhao, Linyong Nan, Zhenting Qi, Wenlin Zhang, Xiangru Tang, Boyu Mi, and Dragomir Radev. 2023 b . https://doi.org/10.18653/v1/2023.acl-long.334 R obu T : A systematic study of table QA robustness against human-annotated adversarial perturbations . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (...
-
[37]
Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, and Weiping Wang. 2024. https://doi.org/10.18653/v1/2024.acl-long.493 Multimodal table understanding . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9102--9124, Bangkok, Thailand. Association for Computat...
-
[38]
Bangbang Zhou, Zuan Gao, Zixiao Wang, Boqiang Zhang, Yuxin Wang, Zhineng Chen, and Hongtao Xie. 2025 a . Syntab-llava: Enhancing multimodal table understanding with decoupled synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 24796--24806
2025
-
[39]
Wei Zhou, Mohsen Mesgar, Heike Adel, and Annemarie Friedrich. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.117 Texts or images? a fine-grained analysis on the effectiveness of input representations and models for table question answering . In Findings of the Association for Computational Linguistics: ACL 2025, pages 2307--2318, Vienna, Austria. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.