Recognition: unknown
Beyond Uniform Credit Assignment: Selective Eligibility Traces for RLVR
Pith reviewed 2026-05-09 15:36 UTC · model grok-4.3
The pith
Selective Eligibility Traces replace uniform credit assignment in critic-free RLVR by masking low-entropy tokens to focus learning on critical reasoning steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
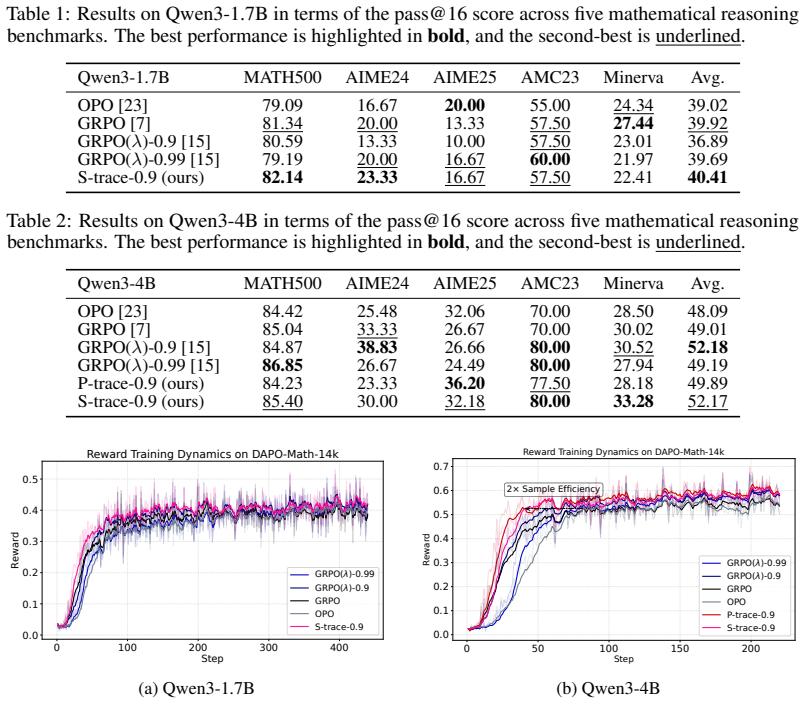
S-trace implements sparse eligibility traces by selectively masking low-entropy tokens, thereby achieving fine-grained credit assignment under the critic-free RLVR objective; it rests on the partial trust-region preservation intuition and identifies GSPO as the uniform-credit special case of the same framework. On Qwen3 models the method improves average pass@16 by 0.49 percent at 1.7B scale, 3.16 percent at 4B scale, and 2.98 percent at 8B scale while also raising sample and token efficiency.
What carries the argument
S-trace, the sparse eligibility traces mechanism that selectively masks low-entropy tokens to restrict credit propagation to high-entropy positions while remaining critic-free.
If this is right
- S-trace outperforms GRPO by 0.49% on Qwen3-1.7B, 3.16% on Qwen3-4B, and 2.98% on Qwen3-8B in average pass@16.
- The method simultaneously improves sample efficiency and token efficiency.
- GSPO corresponds to the uniform-credit special case inside the eligibility-traces framework.
- The partial trust-region preservation argument supports stable updates in the critic-free setting.
Where Pith is reading between the lines
- Entropy-based masking may serve as a general proxy for locating reasoning-critical tokens across other policy-gradient algorithms.
- The same sparsity idea could be applied to reduce variance in longer-horizon reasoning trajectories without increasing model size.
- Combining S-trace with occasional critic updates might further tighten credit assignment while retaining most of the efficiency gain.
- The approach suggests that uniform credit assignment is a hidden bottleneck that limits scaling of pure RLVR methods.
Load-bearing premise
Masking low-entropy tokens removes only non-critical information and the partial trust-region preservation property still holds without a learned critic.
What would settle it
If S-trace and GRPO produce statistically indistinguishable pass@16 scores and efficiency metrics when trained on the same Qwen3 models for the same number of steps on standard math-reasoning benchmarks, the performance claim would be falsified.
Figures






read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) has become a key approach for improving the reasoning abilities of large language models. However, widely used critic-free algorithms such as Group Relative Policy Optimization (GRPO) necessitate a ``uniform credit assignment'' assumption that indiscriminately broadcast trajectory-level advantages, hindering learning efficiency by failing to distinguish critical reasoning steps. To address this limitation, we propose Selective Eligibility Traces (S-trace). Grounded in the intuition of partial trust region preservation, we initially introduce P-trace as a sample-efficient, critic-free eligibility traces method, upon which we build S-trace, implementing a sparse eligibility traces mechanism to further mitigate variance and achieve fine-grained credit assignment by selectively masking low-entropy tokens. Theoretically, we contextualize the recent Group Sequence Policy Optimization (GSPO) method within the critic-free eligibility traces framework, identifying it as a special instance of the eligibility traces method operating under uniform credit assignment. Experiments demonstrate that S-trace not only outperforms GRPO, showing gains of 0.49\% on Qwen3-1.7B and 3.16\% on Qwen3-4B, and maintaining a robust 2.98\% improvement when scaled further to Qwen3-8B in average pass@16, but notably achieves this with simultaneously higher sample and token efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Selective Eligibility Traces (S-trace) for critic-free RLVR in LLMs to move beyond uniform credit assignment in methods like GRPO. It first introduces P-trace as a sample-efficient eligibility traces approach grounded in partial trust-region preservation, then extends it to S-trace via sparse masking of low-entropy tokens for finer-grained assignment. The work frames GSPO as a special case of eligibility traces under uniform credit assignment and reports empirical gains of 0.49% (Qwen3-1.7B), 3.16% (Qwen3-4B), and 2.98% (Qwen3-8B) in average pass@16 alongside improved sample and token efficiency.
Significance. If the empirical gains and efficiency claims hold under rigorous validation, the method could meaningfully advance critic-free RL for LLM reasoning by enabling more targeted credit assignment, potentially reducing training costs while improving performance on verifiable-reward tasks.
major comments (3)
- [Abstract] Abstract: the claim that GSPO is a special instance of the eligibility traces method operating under uniform credit assignment is asserted but no derivation, update-rule comparison, or mathematical contextualization is supplied, which is load-bearing for the paper's theoretical framing.
- [Abstract] Abstract: the reported percentage gains (0.49%, 3.16%, 2.98%) and efficiency improvements are presented without error bars, statistical significance tests, ablation studies, or full experimental protocol details, undermining assessment of whether the improvements are robust or attributable to the selective masking mechanism.
- [Abstract] Abstract: the central assumption that selectively masking low-entropy tokens produces fine-grained credit assignment without discarding critical reasoning information (and that the partial trust-region intuition remains valid under the critic-free RLVR objective) receives no supporting analysis, trajectory inspection, or counter-example check, yet this selectivity rule directly determines the eligibility trace sparsity and advantage signal.
minor comments (1)
- [Abstract] The abstract introduces the 'partial trust region preservation intuition' without indicating how it is formalized in the P-trace or S-trace update rules or how it differs from standard eligibility trace decay.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, providing clarifications from the full manuscript and committing to targeted revisions in the abstract and related sections to improve clarity and self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GSPO is a special instance of the eligibility traces method operating under uniform credit assignment is asserted but no derivation, update-rule comparison, or mathematical contextualization is supplied, which is load-bearing for the paper's theoretical framing.
Authors: The full manuscript derives this in Section 3.3 by showing that the GSPO update rule is recovered exactly when the eligibility trace is set to uniform (non-selective) credit assignment, with explicit comparison of the advantage propagation and trust-region terms. The abstract condenses the result for brevity. To strengthen the abstract's theoretical framing, we will revise it to include a one-sentence reference to this derivation and the uniform-credit special case. revision: yes
-
Referee: [Abstract] Abstract: the reported percentage gains (0.49%, 3.16%, 2.98%) and efficiency improvements are presented without error bars, statistical significance tests, ablation studies, or full experimental protocol details, undermining assessment of whether the improvements are robust or attributable to the selective masking mechanism.
Authors: The abstract summarizes headline numbers; the manuscript reports full protocols in Section 4.1, ablation studies isolating the masking mechanism in Section 4.4 and Figure 5, and results averaged over multiple random seeds. We agree the abstract would benefit from explicit robustness indicators. We will revise the abstract to report gains with standard deviations and note that improvements remain consistent and statistically significant across seeds and model scales. revision: yes
-
Referee: [Abstract] Abstract: the central assumption that selectively masking low-entropy tokens produces fine-grained credit assignment without discarding critical reasoning information (and that the partial trust-region intuition remains valid under the critic-free RLVR objective) receives no supporting analysis, trajectory inspection, or counter-example check, yet this selectivity rule directly determines the eligibility trace sparsity and advantage signal.
Authors: Section 3.2 derives the partial trust-region preservation for P-trace and its extension to S-trace under the critic-free objective. Section 4.3 and Appendix D supply trajectory inspections, entropy histograms, and counter-example cases demonstrating that low-entropy masking targets non-critical tokens while preserving reasoning steps. We will add a concise clause to the abstract referencing this supporting analysis to make the assumption's grounding explicit. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces P-trace and S-trace as novel extensions of eligibility traces for critic-free RLVR, with GSPO positioned as a special case under uniform credit assignment. No step reduces a claimed result or prediction to a fitted parameter or self-citation by construction; the entropy-based masking rule is presented as an empirical heuristic rather than a derived necessity, and performance gains are reported as experimental outcomes without tautological re-derivation of inputs. The central claims rest on algorithmic definitions and empirical validation rather than self-referential loops.
Axiom & Free-Parameter Ledger
free parameters (1)
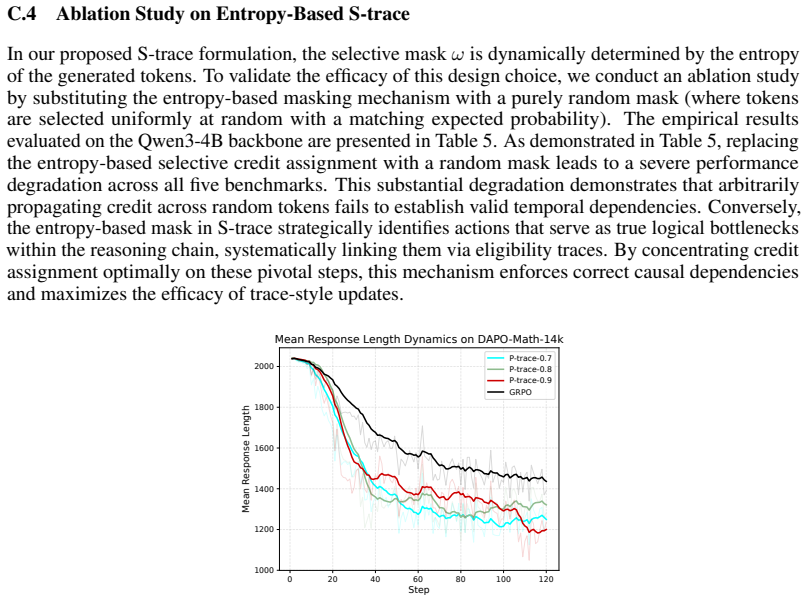
- entropy threshold for selective masking
axioms (1)
- domain assumption Partial trust region preservation allows stable learning when eligibility traces are applied in a critic-free setting.
Reference graph
Works this paper leans on
-
[1]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[2]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[3]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomek Korbak, David Lindner, Pedro Freire, Tony Tong Wang, Samuel Marks, Charbel-Raphael Segerie, Micah Carroll, Andi Peng, Phillip J.K. Christoffersen, Mehul Damani, Stewart Slocum, Usman Anwar, Anand Siththaranjan, Max Nadeau, Eric J Michau...
2023
-
[4]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
2025
-
[5]
Inter- preting emergent planning in model-free reinforcement learning
Thomas Bush, Stephen Chung, Usman Anwar, Adrià Garriga-Alonso, and David Krueger. Inter- preting emergent planning in model-free reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[6]
Hanna and Nicholas E
Josiah P. Hanna and Nicholas E. Corrado. When can model-free reinforcement learning be enough for thinking? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
A survey of temporal credit assignment in deep reinforcement learning.Transactions on Machine Learning Research, 2024
Eduardo Pignatelli, Johan Ferret, Matthieu Geist, Thomas Mesnard, Hado van Hasselt, and Laura Toni. A survey of temporal credit assignment in deep reinforcement learning.Transactions on Machine Learning Research, 2024. Survey Certification
2024
-
[10]
Learning to predict by the methods of temporal differences.Machine learning, 3(1):9–44, 1988
Richard S Sutton. Learning to predict by the methods of temporal differences.Machine learning, 3(1):9–44, 1988
1988
-
[11]
MIT press Cambridge, 1998
Richard S Sutton, Andrew G Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[12]
Expected eligibility traces
Hado van Hasselt, Sephora Madjiheurem, Matteo Hessel, David Silver, André Barreto, and Diana Borsa. Expected eligibility traces. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 9997–10005, 2021
2021
-
[13]
From past to future: rethinking eligibility traces
Dhawal Gupta, Scott M Jordan, Shreyas Chaudhari, Bo Liu, Philip S Thomas, and Bruno Castro da Silva. From past to future: rethinking eligibility traces. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 12253–12260, 2024. 10
2024
-
[14]
An analysis of actor/critic algorithms using eligibility traces: Reinforcement learning with imperfect value function
Hajime Kimura and Shigenobu Kobayashi. An analysis of actor/critic algorithms using eligibility traces: Reinforcement learning with imperfect value function. InProceedings of the Fifteenth International Conference on Machine Learning, ICML ’98, page 278–286, San Francisco, CA, USA, 1998. Morgan Kaufmann Publishers Inc
1998
-
[15]
Grpo-λ: Credit assignment improves llm reasoning.arXiv preprint arXiv:2510.00194, 2025
Prasanna Parthasarathi, Mathieu Reymond, Boxing Chen, Yufei Cui, and Sarath Chandar. Grpo-λ: Credit assignment improves llm reasoning.arXiv preprint arXiv:2510.00194, 2025
-
[16]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InThe Thirty-ninth Annual Confe...
2025
-
[17]
Veronica Chelu, Diana Borsa, Doina Precup, and Hado van Hasselt. Selective credit assignment. CoRR, abs/2202.09699, 2022
-
[18]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models
Ziniu Li, Tian Xu, Yushun Zhang, Zhihang Lin, Yang Yu, Ruoyu Sun, and Zhi-Quan Luo. Remax: A simple, effective, and efficient reinforcement learning method for aligning large language models. InForty-first International Conference on Machine Learning, 2024
2024
-
[20]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational...
2024
-
[21]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, and Wei Shen. Reinforce++: An efficient rlhf algorithm with robustness to both prompt and reward models.arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling, 2025
2025
-
[23]
On-policy rl with optimal reward baseline.arXiv preprint arXiv:2505.23585, 2025
Yaru Hao, Li Dong, Xun Wu, Shaohan Huang, Zewen Chi, and Furu Wei. On-policy rl with optimal reward baseline.arXiv preprint arXiv:2505.23585, 2025
-
[24]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
2025
-
[25]
Yi-Fan Zhang, Xingyu Lu, Xiao Hu, Chaoyou Fu, Bin Wen, Tianke Zhang, Changyi Liu, Kaiyu Jiang, Kaibing Chen, Kaiyu Tang, et al. R1-reward: Training multimodal reward model through stable reinforcement learning.arXiv preprint arXiv:2505.02835, 2025
-
[26]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review arXiv 2025
-
[27]
Han Zhang, Ruibin Zheng, Zexuan Yi, Zhuo Zhang, Hanyang Peng, Hui Wang, Zike Yuan, Cai Ke, Shiwei Chen, Jiacheng Yang, et al. Gepo: Group expectation policy optimization for stable heterogeneous reinforcement learning.arXiv preprint arXiv:2508.17850, 2025. 11
-
[28]
Learning to reason under off-policy guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[29]
Exgrpo: Learning to reason from experience
Runzhe Zhan, Yafu Li, Zhi Wang, Xiaoye Qu, Dongrui Liu, Jing Shao, Derek F Wong, and Yu Cheng. Exgrpo: Learning to reason from experience.arXiv preprint arXiv:2510.02245, 2025
-
[30]
Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, et al. Countering capability boundary collapse of llms in reinforcement learning with hybrid-policy optimization.arXiv preprint arXiv:2508.00222, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Tapered off-policy reinforce-stable and efficient reinforcement learning for large language models
Nicolas Le Roux, Marc G Bellemare, Jonathan Lebensold, Arnaud Bergeron, Joshua Greaves, Alexandre Fréchette, Carolyne Pelletier, Eric Thibodeau-Laufer, Sándor Tóth, and Sam Work. Tapered off-policy reinforce-stable and efficient reinforcement learning for large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[32]
Asymmetric REINFORCE for off-policy reinforcement learning: Balancing positive and negative rewards
Charles Arnal, Gaëtan Narozniak, Vivien Cabannes, Yunhao Tang, Julia Kempe, and Remi Munos. Asymmetric REINFORCE for off-policy reinforcement learning: Balancing positive and negative rewards. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[33]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
-
[34]
arXiv preprint arXiv:2509.03646 , year=
Haozhe Wang, Qixin Xu, Che Liu, Junhong Wu, Fangzhen Lin, and Wenhu Chen. Emergent hierarchical reasoning in llms through reinforcement learning.arXiv preprint arXiv:2509.03646, 2025
-
[35]
KTAE: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning
Wei Sun, Wen Yang, Pu Jian, Qianlong Du, Fuwei Cui, Shuo Ren, and Jiajun Zhang. KTAE: A model-free algorithm to key-tokens advantage estimation in mathematical reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[36]
Process reward model with q-value rankings
Wendi Li and Yixuan Li. Process reward model with q-value rankings. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[37]
Stop summation: Min-form credit assignment is all process reward model needs for reasoning
Jie Cheng, Gang Xiong, Ruixi Qiao, Lijun Li, Chao Guo, Junle Wang, Yisheng Lv, and Fei-Yue Wang. Stop summation: Min-form credit assignment is all process reward model needs for reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[38]
Do we need to verify step by step? rethinking process supervision from a theoretical perspective
Zeyu Jia, Alexander Rakhlin, and Tengyang Xie. Do we need to verify step by step? rethinking process supervision from a theoretical perspective. InForty-second International Conference on Machine Learning, 2025
2025
-
[39]
VinePPO: Refining credit assignment in RL training of LLMs
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. VinePPO: Refining credit assignment in RL training of LLMs. InForty-second International Conference on Machine Learning, 2025
2025
-
[40]
Trajectory bellman residual minimization: A simple value-based method for LLM reasoning
Yurun Yuan, Fan Chen, Zeyu Jia, Alexander Rakhlin, and Tengyang Xie. Trajectory bellman residual minimization: A simple value-based method for LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[41]
Sutton, and Satinder P
Doina Precup, Richard S. Sutton, and Satinder P. Singh. Eligibility traces for off-policy policy evaluation. InProceedings of the Seventeenth International Conference on Machine Learning, ICML ’00, page 759–766, San Francisco, CA, USA, 2000. Morgan Kaufmann Publishers Inc
2000
-
[42]
Machado, Adam White, and Martha White
Esraa Elelimy, Brett Daley, Andrew Patterson, Marlos C. Machado, Adam White, and Martha White. Deep reinforcement learning with gradient eligibility traces. InReinforcement Learning Conference, 2025. 12
2025
-
[43]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael Jordan, and Pieter Abbeel. High- dimensional continuous control using generalized advantage estimation.arXiv preprint arXiv:1506.02438, 2015
work page internal anchor Pith review arXiv 2015
-
[44]
Selective dyna-style planning under limited model capacity
Zaheer Abbas, Samuel Sokota, Erin Talvitie, and Martha White. Selective dyna-style planning under limited model capacity. InInternational Conference on Machine Learning, pages 1–10. PMLR, 2020
2020
-
[45]
Preferential temporal difference learning
Nishanth Anand and Doina Precup. Preferential temporal difference learning. InInternational Conference on Machine Learning, pages 286–296. PMLR, 2021
2021
-
[46]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297, New York, NY , USA, 2025. Association for Computing Machinery
2025
-
[47]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[49]
Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quan- titative reasoning problems with language models.Advances in neural information processing systems, 35:3843–3857, 2022
2022
-
[50]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13(9):9, 2024
2024
- [51]
-
[52]
Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting.The journal of machine learning research, 15(1):1929–1958, 2014
1929
-
[53]
Making memories last: the synaptic tagging and capture hypothesis.Nature reviews neuroscience, 12(1):17–30, 2011
Roger L Redondo and Richard GM Morris. Making memories last: the synaptic tagging and capture hypothesis.Nature reviews neuroscience, 12(1):17–30, 2011
2011
-
[54]
A minimalist approach to llm reasoning: from rejection sampling to reinforce, 2025
Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, et al. A minimalist approach to llm reasoning: from rejection sampling to reinforce.arXiv preprint arXiv:2504.11343, 2025. 13 A Implementation Details In this section, we provide comprehensive details on the experimental setup, followed by an ...
-
[55]
|o|X t=1 rt(θ) ˆAt # 16 =E x∼Q o∼πθold(·|x)
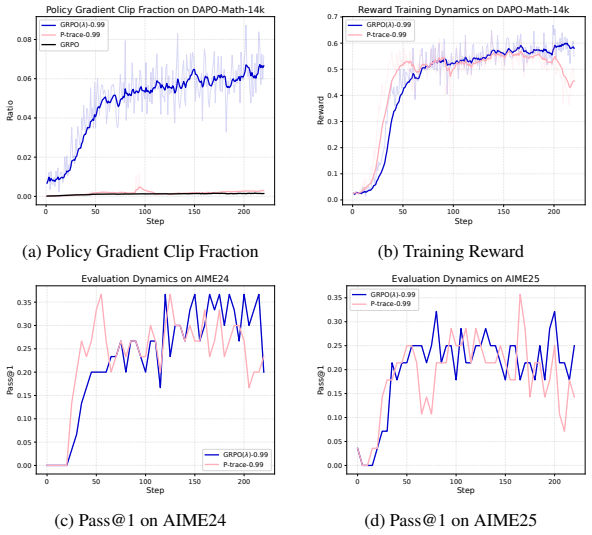
To elucidate the underlying dynamics, we compared the clipping behavior of GRPO( λ)-0.99 and P-trace-0.99 on the DAPO-Math-14k dataset. As evidenced in Figure 6a, the clipping fraction associated with GRPO(λ)-0.99 is substantially higher than that of P-trace-0.99, notably dwarfing the latter by nearly 24 times around step 200. We deem that the stochastic ...
-
[56]
leverages gradient sparsity (effectively masking out low-entropy tokens) to invoke the “80/20 rule” , our LOWO formulation avoids this confounding factor. By ensuring that the gradient update for every token explicitly includes the intrinsic contribution from its own importance weight, we guarantee that any observed performance gains are strictly attribut...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.