Recognition: unknown
Verifiable Model-Free Safety Filters via Reinforcement Learning
Pith reviewed 2026-05-08 08:29 UTC · model grok-4.3
The pith
Learning quadratic programming parameters via reinforcement learning yields a model-free safety filter with formal persistent safety certificates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By casting the safety filter as an unrolled quadratic programming solver and learning its parameters end-to-end with deep reinforcement learning, the method obtains a controller that operates without a system model yet still admits a formal certificate that the closed-loop trajectory satisfies safety constraints at every step.
What carries the argument
The unrolled quadratic programming solver network, whose parameters are tuned by reinforcement learning to encode safety constraints directly from data.
If this is right
- The filter can be applied to systems where obtaining an accurate dynamic model is impractical or costly.
- Formal safety proofs remain available after the learning process completes.
- Per-step computation stays low because the quadratic program structure is retained rather than replaced by a generic neural net.
- Minimal intervention is achieved by optimizing the filter to alter the nominal control action only when necessary for safety.
- Overall performance exceeds both traditional model-based safety filters and standard reinforcement learning controllers in the reported metrics.
Where Pith is reading between the lines
- This learning approach could be combined with other optimization layers to create verifiable policies for tasks beyond safety enforcement.
- Training in simulation followed by direct transfer might be feasible if the certificate depends only on the learned parameters and not on model specifics.
- Extending the method to continuous-time or hybrid systems would require analogous unrolling of the corresponding optimization problems.
Load-bearing premise
The safety certificate that was originally derived assuming quadratic programming parameters come from a known system model remains valid when those parameters are instead produced by reinforcement learning.
What would settle it
Finding a concrete system and learned parameter set where the quadratic programming certificate is satisfied yet the actual closed-loop behavior violates a safety constraint.
Figures


read the original abstract
This paper presents a reinforcement learning approach of a model-free safety filter, drawing inspiration from the framework of model-based Predictive Safety Filters (PSFs). Similar to conventional PSFs, our method adopts a Quadratic Programming (QP) formulation by representing the filter as an unrolled QP solver network. However, unlike existing PSFs that derive QP parameters explicitly from system models, we learn these parameters directly through Deep Reinforcement Learning (DRL), thereby eliminating the dependency on accurate system identification. Furthermore, compared to traditional neural network-based methods, this QP structure allows us to furnish a formal certificate for the persistent safety of the learned filter. Numerical results demonstrate that our method outperforms both conventional model-based PSFs and RL-trained Multi-Layer Perceptron (MLP) baselines in terms of safety guarantees, minimal intervention, and per-step computational load.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a model-free safety filter by representing a predictive safety filter (PSF) as an unrolled quadratic programming (QP) solver whose parameters are learned end-to-end via deep reinforcement learning rather than derived from an explicit system model. It claims that the retained QP structure nevertheless permits a formal certificate of persistent safety, and reports numerical results showing reduced intervention, stronger safety, and lower per-step compute compared with both classical model-based PSFs and plain MLP-based RL baselines.
Significance. If the formal certificate can be shown to survive the replacement of model-derived QP parameters by RL-optimized ones, the approach would constitute a concrete step toward verifiable, model-free safety filters. The structural choice of an unrolled QP network is a strength that could aid both interpretability and certification; the reported computational and safety gains are practically relevant for real-time control.
major comments (2)
- [Abstract, §4] Abstract and §4 (safety-certificate claim): the manuscript asserts that the QP structure 'allows us to furnish a formal certificate for the persistent safety of the learned filter,' yet supplies neither the explicit algebraic conditions that the learned parameters must satisfy nor a proof that RL optimization preserves those conditions. Standard PSF certificates rely on model-derived quantities (e.g., barrier gradients or constraint matrices) that guarantee CBF invariance; without an independent verification step or a derivation showing that the RL objective enforces the same algebraic relations, the certificate claim is unsupported.
- [§3.2] §3.2 (unrolled QP network and RL training): the reward function balances safety and performance, but the paper does not demonstrate that the resulting parameters continue to satisfy the linear independence or positive-definiteness conditions required for the QP to recover a valid safety filter. If these conditions are violated post-training, the formal certificate cannot be invoked.
minor comments (2)
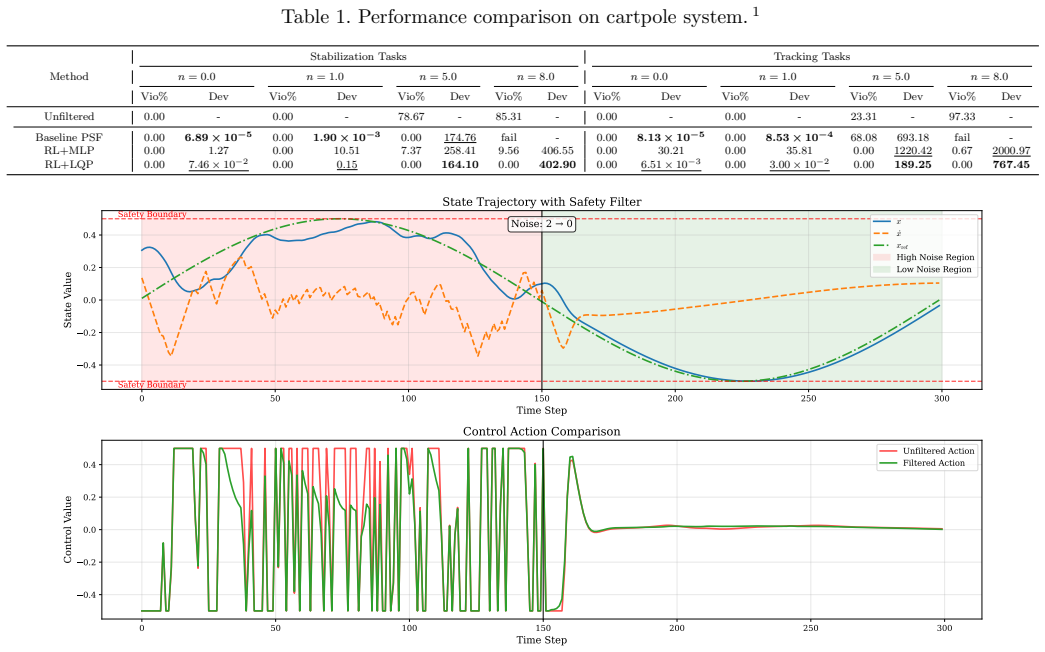
- [Figure 3] Figure 3 (comparison plots): axis labels and legend entries are too small for print; enlarge or split into separate panels.
- [§3.1, Appendix] Notation: the symbol for the learned QP matrix is introduced inconsistently between §3.1 and the appendix; adopt a single definition.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important points regarding the rigor of our safety-certificate claim. We address each major comment below, agreeing where the manuscript is incomplete and outlining specific revisions that will strengthen the presentation without altering the core contribution.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (safety-certificate claim): the manuscript asserts that the QP structure 'allows us to furnish a formal certificate for the persistent safety of the learned filter,' yet supplies neither the explicit algebraic conditions that the learned parameters must satisfy nor a proof that RL optimization preserves those conditions. Standard PSF certificates rely on model-derived quantities (e.g., barrier gradients or constraint matrices) that guarantee CBF invariance; without an independent verification step or a derivation showing that the RL objective enforces the same algebraic relations, the certificate claim is unsupported.
Authors: We agree that the current manuscript does not explicitly state the algebraic conditions on the learned QP parameters or provide a derivation showing that the RL objective preserves them. The formal certificate is inherited from standard PSF theory: persistent safety follows from CBF invariance provided the QP is well-posed (positive-definite Hessian and linearly independent active constraints). Our approach retains this structure, so the certificate applies whenever the learned parameters satisfy those conditions; the RL reward penalizes violations and thereby encourages feasible, safe behavior. However, we did not include an explicit derivation or post-training verification step. In the revised manuscript we will add a dedicated paragraph in §4 that (i) recalls the precise algebraic conditions required for the QP to define a valid CBF-based safety filter and (ii) describes a lightweight post-training check (eigenvalue test for positive-definiteness and rank test for constraint independence) that can be performed on the learned parameters. This clarification will make the certificate claim fully supported while preserving the model-free training procedure. revision: yes
-
Referee: [§3.2] §3.2 (unrolled QP network and RL training): the reward function balances safety and performance, but the paper does not demonstrate that the resulting parameters continue to satisfy the linear independence or positive-definiteness conditions required for the QP to recover a valid safety filter. If these conditions are violated post-training, the formal certificate cannot be invoked.
Authors: The referee is correct that §3.2 does not explicitly verify satisfaction of the QP regularity conditions after training. While the unrolled QP architecture guarantees that any output is the exact solution of the parameterized QP, the safety-filter interpretation requires the learned parameters to meet positive-definiteness and linear-independence requirements. In the reported experiments the learned filters achieved the stated safety performance, which is consistent with the conditions holding, yet we did not report explicit checks. We will revise §3.2 to state the conditions mathematically and add a short table (or paragraph) in the numerical-results section showing that, for every trained instance across the reported trials, the Hessian eigenvalues were positive and the constraint matrix had full row rank. These additions will allow readers to invoke the formal certificate with the same rigor as in model-based PSFs. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present a model-free extension of PSFs by learning QP parameters via DRL rather than explicit model derivation, with the formal safety certificate attributed to the QP structure itself. No equations, derivation steps, or self-citations are available in the text to exhibit any reduction of the claimed certificate to the RL fitting process by construction (e.g., no case where a safety condition is shown to hold tautologically because it was optimized into the reward or parameters). The approach is described as preserving the QP form for verifiability while removing model dependency, which is an independent methodological choice rather than a self-referential loop. Numerical results are presented separately as empirical support. Per the rules, without a quotable specific reduction, no circularity is flagged.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The QP formulation supplies a formal safety certificate when its parameters satisfy certain conditions.
- ad hoc to paper Reinforcement learning can discover parameters that preserve the safety properties of the QP.
Reference graph
Works this paper leans on
-
[1]
Agrawal, A. and Sreenath, K. (2017). Discrete control barrier functions for safety-critical control of discrete systems with application to bipedal robot navigation. doi:10.15607/RSS.2017.XIII.073
-
[2]
Ames, A.D., Xu, X., Grizzle, J.W., and Tabuada, P. (2017). Control barrier function based quadratic programs for safety critical systems. IEEE Transactions on Automatic Control, 62(8), 3861--3876
2017
-
[3]
and Tomlin, C.J
Bansal, S. and Tomlin, C.J. (2021). Deepreach: A deep learning approach to high-dimensional reachability. In 2021 IEEE International Conference on Robotics and Automation (ICRA), 1817--1824
2021
-
[4]
Bastani, O. (2021). Safe reinforcement learning with nonlinear dynamics via model predictive shielding. In 2021 American Control Conference (ACC), 3488--3494
2021
-
[5]
Borrelli, F., Bemporad, A., and Morari, M. (2017). Predictive Control for Linear and Hybrid Systems. Cambridge University Press
2017
-
[6]
Journal of Mathematical Imaging and Vision40(1), 120–145 (2010)
Chambolle, A. and Pock, T. (2011). A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision, 40(1), 120--145. doi:10.1007/s10851-010-0251-1
-
[7]
Choi, J.J., Castañeda, F., Jung, W., Zhang, B., Tomlin, C.J., and Sreenath, K. (2025). Constraint-guided online data selection for scalable data-driven safety filters in uncertain robotic systems. IEEE Transactions on Robotics, 41, 3779--3798. doi:10.1109/TRO.2025.3577022
-
[8]
Cosner, R.K., Rodriguez, I.D.J., Molnar, T.G., Ubellacker, W., Yue, Y., Ames, A.D., and Bouman, K.L. (2022). Self-supervised online learning for safety-critical control using stereo vision. In 2022 International Conference on Robotics and Automation (ICRA), 11487--11493
2022
-
[9]
Dawson, C., Qin, Z., Gao, S., and Fan, C. (2022). Safe nonlinear control using robust neural lyapunov-barrier functions. In A. Faust, D. Hsu, and G. Neumann (eds.), Proceedings of the 5th Conference on Robot Learning, volume 164 of Proceedings of Machine Learning Research, 1724--1735. PMLR
2022
-
[10]
A Cartpole Experiment Benchmark for Trainable Controllers
Geva, S. and Sitte, J. (1993). A cartpole experiment benchmark for trainable controllers. IEEE Control Systems Magazine, 13(5), 40--51. doi:10.1109/37.236324
-
[11]
Herbert, S., Choi, J.J., Sanjeev, S., Gibson, M., Sreenath, K., and Tomlin, C.J. (2021). Scalable learning of safety guarantees for autonomous systems using hamilton-jacobi reachability. In 2021 IEEE International Conference on Robotics and Automation (ICRA), 5914–5920. IEEE Press
2021
-
[12]
Hsu, K.C., Hu, H., and Fisac, J.F. (2023). The safety filter: A unified view of safety-critical control in autonomous systems
2023
-
[13]
Johansson, K. (2000). The quadruple-tank process: a multivariable laboratory process with an adjustable zero. IEEE Transactions on Control Systems Technology, 8(3), 456--465. doi:10.1109/87.845876
-
[14]
Lasserre, J.B. (2001). Global optimization with polynomials and the problem of moments. SIAM Journal on Optimization, 11(3), 796--817. doi:10.1137/S1052623400366802
-
[15]
Lavanakul, W., Choi, J.J., Sreenath, K., and Tomlin, C.J. (2024). Safety filters for black-box dynamical systems by learning discriminating hyperplanes. In Conference on Learning for Dynamics & Control
2024
-
[16]
Li, Z., Yang, B., Li, J., Yan, J., and Mo, Y. (2023). Linear model predictive control under continuous path constraints via parallelized primal-dual hybrid gradient algorithm. 2023 62nd IEEE Conference on Decision and Control (CDC), 159--164
2023
- [17]
- [18]
-
[19]
and Lygeros, J
Margellos, K. and Lygeros, J. (2011). Hamilton–jacobi formulation for reach–avoid differential games. IEEE Transactions on Automatic Control, 56(8), 1849--1861
2011
- [20]
-
[21]
Monga, V., Li, Y., and Eldar, Y.C. (2021). Algorithm unrolling: Interpretable, efficient deep learning for signal and image processing. IEEE Signal Processing Magazine, 38(2), 18--44. doi:10.1109/MSP.2020.3018525
-
[22]
Parrilo, P.A. (2003). Semidefinite programming relaxations for semialgebraic problems. Mathematical programming, 96(2), 293--320
2003
-
[23]
Robey, A., Hu, H., Lindemann, L., Zhang, H., Dimarogonas, D.V., Tu, S., and Matni, N. (2020). Learning control barrier functions from expert demonstrations. In 2020 59th IEEE Conference on Decision and Control (CDC), 3717--3724
2020
-
[24]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. (2017). Proximal policy optimization algorithms. CoRR, abs/1707.06347
work page internal anchor Pith review arXiv 2017
-
[25]
So, O., Serlin, Z., Mann, M., Gonzales, J., Rutledge, K., Roy, N., and Fan, C. (2024). How to train your neural control barrier function: Learning safety filters for complex input-constrained systems. In 2024 IEEE International Conference on Robotics and Automation (ICRA), 11532--11539. doi:10.1109/ICRA57147.2024.10610418
-
[26]
and Barto, A.G
Sutton, R.S. and Barto, A.G. (2018). Reinforcement learning: An introduction. MIT press
2018
-
[27]
Tang, Y., Chu, X., Huang, J., and Samuel Au, K.W. (2024). Learning-based mpc with safety filter for constrained deformable linear object manipulation. IEEE Robotics and Automation Letters, 9(3), 2877--2884. doi:10.1109/LRA.2024.3362643
- [28]
-
[29]
Wabersich, K.P. and Zeilinger, M.N. (2018). Linear model predictive safety certification for learning-based control. In 2018 IEEE Conference on Decision and Control (CDC), 7130--7135. doi:10.1109/CDC.2018.8619829
-
[30]
and Zeilinger, M.N
Wabersich, K.P. and Zeilinger, M.N. (2021). A predictive safety filter for learning-based control of constrained nonlinear dynamical systems. Automatica, 129, 109597
2021
-
[31]
and Allgöwer, F
Wieland, P. and Allgöwer, F. (2007). Constructive safety using control barrier functions. IFAC Proceedings Volumes, 40(12), 462--467. 7th IFAC Symposium on Nonlinear Control Systems
2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.