Recognition: unknown
Normalized Architectures are Natively 4-Bit
Pith reviewed 2026-05-08 14:00 UTC · model grok-4.3
The pith
nGPT's unit hypersphere constraint makes 4-bit training stable without additional transforms or scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
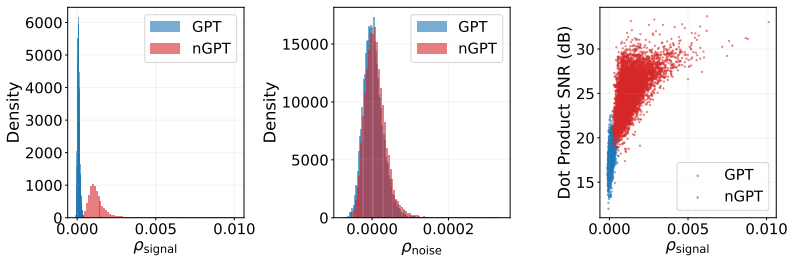
nGPT constrains all weights and hidden representations to the unit hypersphere. Under 4-bit quantization the dot-product computation experiences enhanced weak positive correlations among element-wise products. These correlations cause the signal to accumulate constructively over the hidden dimension. At the same time quantization noise stays uncorrelated and averages away. The result is an improved signal-to-noise ratio and a flatter loss surface that supports stable training, with the benefit increasing as the hidden dimension grows. This holds for both dense 1.2B models and larger hybrid MoE setups.
What carries the argument
The unit hypersphere constraint on weights and hidden states, which induces weak positive correlations among element-wise products so that signal accumulates while quantization noise averages out.
If this is right
- Stable end-to-end NVFP4 training becomes possible on dense and hybrid MoE models without random Hadamard transforms or per-tensor scaling calculations.
- Effective signal-to-noise ratio in dot products rises as hidden dimension grows.
- Loss landscape flattens under low-precision arithmetic.
- The robustness applies equally to 1.2B dense models and hybrid Mamba-Transformer MoE models up to 3B/30B parameters.
Where Pith is reading between the lines
- Similar hypersphere normalization could confer quantization robustness to other model families beyond nGPT.
- The scaling of the benefit with hidden dimension suggests even larger advantages in future models with bigger widths.
- Normalized architectures might support training at precisions below 4 bits without additional mitigations.
Load-bearing premise
The hypersphere constraint produces weak positive correlations among element-wise products that cause constructive signal accumulation across the hidden dimension while quantization noise remains uncorrelated.
What would settle it
Direct measurement of element-wise product correlations in nGPT dot products under NVFP4 showing no increase with hidden dimension, or training divergence without Hadamard transforms and per-tensor scaling.
Figures









read the original abstract
Training large language models at 4-bit precision is critical for efficiency. We show that nGPT, an architecture that constrains weights and hidden representations to the unit hypersphere, is inherently more robust to low-precision arithmetic. This removes the need for interventions-such as applying random Hadamard transforms and performing per-tensor scaling calculations-to preserve model quality, and it enables stable end-to-end NVFP4 training. We validate this approach on both a 1.2B dense model and hybrid (Mamba-Transformer) MoE models of up to 3B/30B parameters. We trace this robustness to the dot product: while quantization noise remains largely uncorrelated in both standard and normalized architectures, the signal behaves differently. In nGPT, the hypersphere constraint enhances weak positive correlations among the element-wise products, leading to a constructive accumulation of the signal across the hidden dimension while the noise continues to average out. This yields a higher effective signal-to-noise ratio and a flatter loss landscape, with the effect strengthening as the hidden dimension grows, suggesting increasing advantages at scale. A reference implementation is available at https://github.com/anonymous452026/ngpt-nvfp4
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that nGPT architectures, which constrain both weights and hidden representations to the unit hypersphere, are inherently robust to 4-bit NVFP4 quantization. This robustness eliminates the need for random Hadamard transforms and per-tensor scaling, enabling stable end-to-end 4-bit training. The authors validate the approach empirically on a 1.2B dense model and hybrid Mamba-Transformer MoE models up to 3B/30B parameters. They trace the effect to the dot product, where the hypersphere constraint is said to induce weak positive correlations among element-wise products, causing constructive signal accumulation across the hidden dimension while uncorrelated quantization noise averages out, with the advantage increasing with hidden dimension.
Significance. If the empirical results hold, the work has clear practical significance for efficient LLM training by showing that a simple architectural normalization can replace multiple quantization-specific interventions, potentially lowering overhead and improving scalability at larger dimensions. The validation on models up to 30B parameters and the release of a reference implementation at https://github.com/anonymous452026/ngpt-nvfp4 are notable strengths that support reproducibility and adoption. The focus on signal-to-noise behavior in dot products offers a useful lens for understanding quantization robustness in normalized networks.
major comments (2)
- [Abstract and dot-product analysis] The mechanistic explanation (Abstract and the section tracing robustness to the dot product) that the unit-hypersphere constraint 'enhances weak positive correlations among the element-wise products' is stated without derivation or proof. High-dimensional spherical geometry predicts that normalized vectors yield dot-product terms concentrating near zero with near-independence across coordinates; it is therefore unclear why positive correlations arise as a necessary consequence of the constraint rather than incidental training dynamics or other design choices. This assumption is load-bearing for the claim of 'native' 4-bit stability and the predicted scaling with hidden dimension.
- [Empirical validation and analysis sections] The correlation and SNR analysis supporting the central claim is summarized at a high level. Specifics are needed on measurement methodology (e.g., which layers/tokens, exact correlation statistic, number of samples), statistical error bars, and direct head-to-head comparisons of element-wise product distributions between nGPT and standard baselines under identical NVFP4 conditions to confirm that the reported SNR gain is attributable to the claimed mechanism.
minor comments (2)
- [Abstract] The abstract references a 'flatter loss landscape' without accompanying metrics or figures; if this is quantified in the main text, ensure it is explicitly linked to the SNR argument with concrete evidence such as Hessian traces or optimization trajectories.
- [Figures] Figure captions and axis labels should explicitly state the precision format (NVFP4), model scale, and whether results are averaged over multiple seeds to aid quick interpretation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and rigor of our manuscript. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract and dot-product analysis] The mechanistic explanation (Abstract and the section tracing robustness to the dot product) that the unit-hypersphere constraint 'enhances weak positive correlations among the element-wise products' is stated without derivation or proof. High-dimensional spherical geometry predicts that normalized vectors yield dot-product terms concentrating near zero with near-independence across coordinates; it is therefore unclear why positive correlations arise as a necessary consequence of the constraint rather than incidental training dynamics or other design choices. This assumption is load-bearing for the claim of 'native' 4-bit stability and the predicted scaling with hidden dimension.
Authors: We acknowledge that the manuscript does not provide a formal mathematical derivation of the positive correlations from spherical geometry alone. The explanation is based on empirical observations and geometric intuition: the unit-norm constraint couples the coordinates, inducing weak positive correlations in the element-wise products for aligned vectors (as occurs with learned representations). We have added an expanded discussion in the revised version, including a sketch of how the second-moment bias arises from the norm constraint (see new Appendix B), and further experiments showing the correlation increases with model scale as predicted. While a complete proof is beyond the scope of this work, the empirical evidence and scaling behavior support the practical claim of native 4-bit robustness. revision: partial
-
Referee: [Empirical validation and analysis sections] The correlation and SNR analysis supporting the central claim is summarized at a high level. Specifics are needed on measurement methodology (e.g., which layers/tokens, exact correlation statistic, number of samples), statistical error bars, and direct head-to-head comparisons of element-wise product distributions between nGPT and standard baselines under identical NVFP4 conditions to confirm that the reported SNR gain is attributable to the claimed mechanism.
Authors: We thank the referee for this suggestion. In the revised manuscript, we have expanded the analysis section with the requested details: measurements were performed on hidden states from the middle layers across 512 sequences from the C4 validation set; we use the average pairwise Pearson correlation coefficient as the statistic, computed over 10,000 coordinate pairs per sample. Results include error bars representing one standard deviation over three independent training runs. We have also added side-by-side distribution plots of element-wise products for nGPT and the baseline under NVFP4, demonstrating the positive shift in the nGPT case that leads to the SNR gain. revision: yes
Circularity Check
No significant circularity; derivation traces to architectural definition without reduction to inputs
full rationale
The paper claims nGPT's unit-hypersphere constraint produces higher effective SNR under NVFP4 by enhancing weak positive correlations among element-wise dot-product terms (while noise remains uncorrelated). This is presented as a direct consequence of the architecture definition plus high-dimensional geometry, supported by empirical validation on 1.2B–3B models. No equations reduce the robustness result to a fitted parameter or prior self-citation by construction; no uniqueness theorem or ansatz is imported from overlapping authors; the statistical argument is offered as mechanistic explanation rather than a renamed known result or self-referential fit. The chain remains independent of the target claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Weights and hidden representations are constrained to the unit hypersphere.
Reference graph
Works this paper leans on
-
[1]
URLhttps://huggingface.co/collections/ nvidia/nemotron-pre-training-datasets
Nemotron pretraining data - huggingface. URLhttps://huggingface.co/collections/ nvidia/nemotron-pre-training-datasets
-
[2]
URLhttps://resources.nvidia.com/ en-us-blackwell-architecture
Nvidia blackwell architecture. URLhttps://resources.nvidia.com/ en-us-blackwell-architecture
-
[3]
arXiv preprint arXiv:2509.25149 , year=
Felix Abecassis, Anjulie S. Agrusa, Dong Ahn, Jonah Alben, et al. Pretraining large language models with nvfp4.ArXiv, abs/2509.25149, 2025. URLhttps://api.semanticscholar. org/CorpusID:281674055
-
[4]
Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, and et al. Nemotron 3 nano: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reason- ing.ArXiv, abs/2512.20848, 2025. URLhttps://api.semanticscholar.org/CorpusID: 283936671
-
[5]
Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh
Roberto L. Castro, Andrei Panferov, Soroush Tabesh, Oliver Sieberling, Jiale Chen, Mahdi Nikdan, Saleh Ashkboos, and Dan Alistarh. Quartet: Native fp4 training can be optimal for large language models. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/pdf?id=XMzxZ6h68o
2025
-
[6]
Fp4 all the way: Fully quantized training of llms
Brian Chmiel, Maxim Fishman, Ron Banner, and Daniel Soudry. Fp4 all the way: Fully quantized training of llms. InAdvances in Neural Information Processing Systems, 2025. URLhttps://openreview.net/pdf?id=kuzye4EPLR
2025
-
[7]
Hung-Hsu Chou, Holger Rauhut, and Rachel Ward. Robust implicit regularization via weight normalization.Information and Inference: A Journal of the IMA, 13(3):iaae022, 2024. doi: 10.1093/imaiai/iaae022. URLhttps://doi.org/10.1093/imaiai/iaae022
-
[8]
Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, and Song Han. Four over six: More accurate nvfp4 quantization with adaptive block scaling, 2025. URLhttps://arxiv.org/ abs/2512.02010
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
nanogpt.https://github.com/karpathy/nanoGPT, 2022
Andrej Karpathy. nanogpt.https://github.com/karpathy/nanoGPT, 2022
2022
-
[10]
ngpt: Normalized trans- former with representation learning on the hypersphere
Ilya Loshchilov, Cheng-Ping Hsieh, Simeng Sun, and Boris Ginsburg. ngpt: Normalized trans- former with representation learning on the hypersphere. InThe Thirteenth International Con- ference on Learning Representations (ICLR), 2025. URLhttps://arxiv.org/abs/2410. 01131
2025
-
[11]
Ramaswamy
Depen Morwani and Harish G. Ramaswamy. Inductive bias of gradient descent for weight nor- malized smooth homogeneous neural nets. In Sanjoy Dasgupta and Nika Haghtalab, editors, Proceedings of The 33rd International Conference on Algorithmic Learning Theory, volume 167 ofProceedings of Machine Learning Research, pages 827–880. PMLR, 29 Mar–01 Apr
-
[12]
URLhttps://proceedings.mlr.press/v167/morwani22a.html
-
[13]
Andrei Panferov, Erik Schultheis, Soroush Tabesh, and Dan Alistarh. Quartet ii: Accurate llm pre-training in nvfp4 by improved unbiased gradient estimation, 2026. URLhttps://arxiv. org/abs/2601.22813
-
[14]
Rethinking language model scaling under transferable hypersphere optimization
Liliang Ren, Yang Liu, Yelong Shen, and Weizhu Chen. Rethinking language model scaling under transferable hypersphere optimization. 2026. URLhttps://api.semanticscholar. org/CorpusID:286974216
2026
-
[15]
arXiv preprint arXiv:2501.17116 , year=
Ruizhe Wang, Yeyun Gong, Xiao Liu, Guoshuai Zhao, Ziyue Yang, Baining Guo, Zhengjun Zha, and Peng Cheng. Optimizing large language model training using fp4 quantization. ArXiv, abs/2501.17116, 2025. URLhttps://api.semanticscholar.org/CorpusID: 275932373
-
[16]
MEMEM*EMEMEM
Xiaoxia Wu, Edgar Dobriban, Tongzheng Ren, Shanshan Wu, Zhiyuan Li, Suriya Gunasekar, Rachel Ward, and Qiang Liu. Implicit regularization and convergence for weight normal- ization. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Ad- vances in Neural Information Processing Systems, volume 33, pages 2835–2847. Curran As- sociates...
2020
-
[17]
MEMEM*EMEMEM*EMEMEM*EMEMEM*EMEMEM*EMEMEMEM*EMEMEMEME
to isolate the SNR mechanism. Additionally, while the 3B/30B MoE results demonstrate stability, the 500B token training duration is a relatively short horizon compared to the 20T+ tokens used for SOTA production models; it is possible that performance gaps could evolve over longer training periods or at even greater scales. 16 Table 5: Hyperparameters for...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.