Recognition: unknown
Navigating by Old Maps: The Pitfalls of Static Mechanistic Localization in LLM Post-Training
Pith reviewed 2026-05-08 10:39 UTC · model grok-4.3
The pith
Static mechanisms extracted from current LLM parameters suffer temporal latency and cannot reliably guide future updates during fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
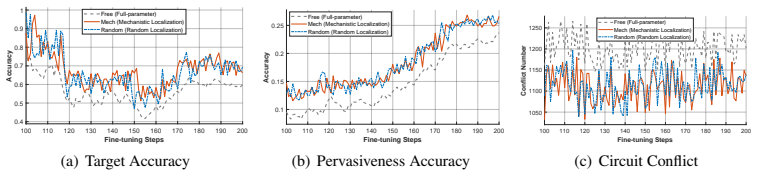
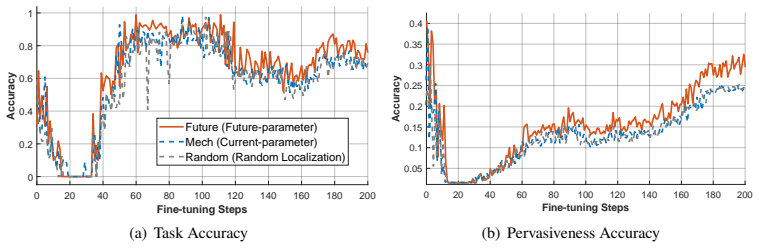
By systematically tracking the structural evolution of Transformer circuits throughout supervised fine-tuning, the authors reveal that circuits exhibit free evolution. This leads to the conclusion that static mechanisms extracted from current states inevitably suffer from temporal latency and are fundamentally inadequate for guiding future states.
What carries the argument
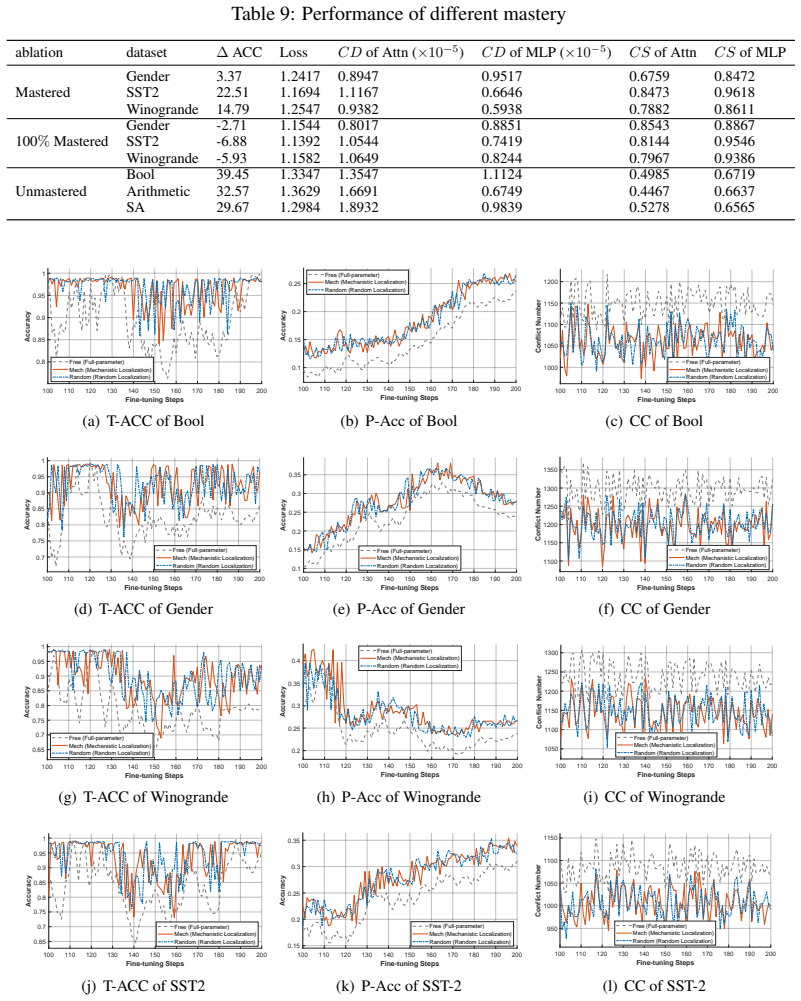
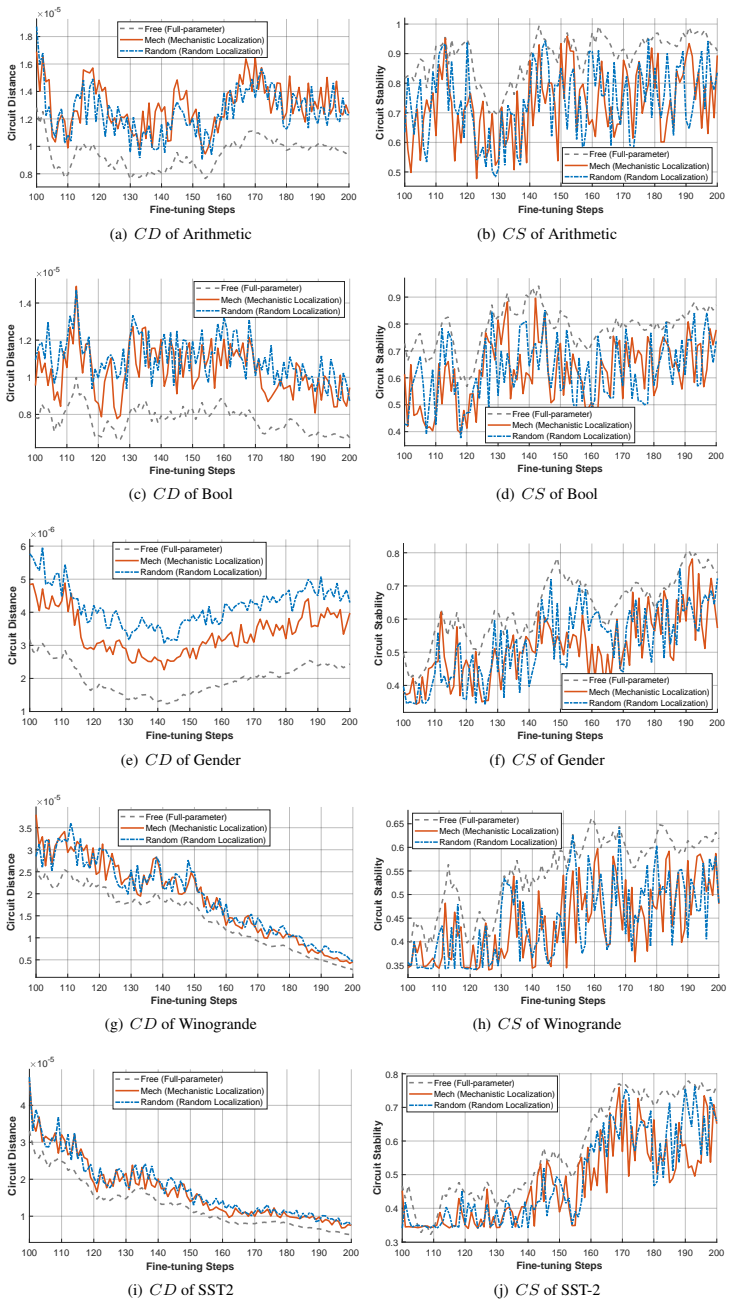
Three new metrics—Circuit Distance, Circuit Stability, and Circuit Conflict—that quantify neural migration, semantic stability, and cross-task interference to reveal the free evolution of circuits during parameter updates.
If this is right
- Locate-then-update methods lose effectiveness as training progresses because circuits drift from their initial locations.
- The apparent success of existing mechanistic localization techniques partly reflects an illusion created by short evaluation windows that do not capture ongoing evolution.
- Mechanistic interventions in LLMs will require predictive models of circuit change rather than one-time snapshots from the current state.
Where Pith is reading between the lines
- Developers may need to interleave fresh localization steps with training rather than performing it only at the beginning.
- This pattern could explain why some editing techniques degrade on longer fine-tunes even when they succeed on short ones.
- A natural extension would be to test whether forecasting circuit trajectories in advance improves the precision of targeted updates.
Load-bearing premise
The new metrics accurately capture the mechanistically relevant changes in circuits, and the observed free evolution generalizes beyond the specific models and tasks examined.
What would settle it
Repeating the localization step at multiple points during fine-tuning and finding no improvement in edit success or task performance compared with using the initial static localization.
Figures




read the original abstract
The "Locate-then-Update" paradigm has become a predominant approach in the post-training of large language models (LLMs), identifying critical components via mechanistic interpretability for targeted parameter updates. However, this paradigm rests on a fundamental yet unverified assumption: can mechanisms derived from current static parameters reliably guide future dynamic parameter updates? To investigate this, we systematically track the structural evolution of Transformer circuits throughout the supervised fine-tuning (SFT) process, revealing the underlying dynamics of task mechanisms. We introduce three novel metrics-Circuit Distance, Circuit Stability, and Circuit Conflict-to analyze circuit evolution across three dimensions: neural migration, semantic stability, and cross-task interference. Our empirical results reveal that circuits inherently exhibit "Free Evolution" during parameter updates. Consequently, static mechanisms extracted from current states inevitably suffer from temporal latency, making them fundamentally inadequate for guiding future states. Moreover, by deconstructing the "illusion of effectiveness" in existing methods, this work underscores the necessity of "foresight" in mechanistic localization and proposes a predictive framework for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that the dominant 'Locate-then-Update' paradigm in LLM post-training is fundamentally limited because static mechanistic localizations extracted from current model states cannot reliably guide future parameter updates. It supports this by tracking Transformer circuit evolution during supervised fine-tuning (SFT), introducing three new metrics (Circuit Distance for neural migration, Circuit Stability for semantic consistency, and Circuit Conflict for cross-task interference) that reveal 'Free Evolution'—ongoing structural drift independent of the localization process. The work deconstructs the apparent success of existing methods as illusory and calls for predictive, foresight-based localization frameworks.
Significance. If the empirical observations hold, the paper identifies a previously under-examined temporal mismatch in mechanistic interpretability for post-training, with potential to redirect research from static circuit discovery toward dynamic or predictive approaches. The explicit tracking of circuit changes across training steps and the introduction of evolution-specific metrics constitute a concrete empirical contribution that could be built upon, provided the metrics are shown to track causally relevant mechanisms rather than incidental parameter shifts.
major comments (2)
- [Abstract / metrics introduction] Abstract and metrics section: The central claim that static mechanisms 'inevitably suffer from temporal latency' and are 'fundamentally inadequate' rests on the three new metrics demonstrating 'Free Evolution.' However, the manuscript provides no ablation or comparison against established causal tools (activation patching, causal tracing, or path patching) to establish that Circuit Distance, Stability, and Conflict track task-relevant mechanisms rather than non-causal parameter noise. Without such validation, the inference from observed numerical drift to fundamental inadequacy of the locate-then-update paradigm does not follow.
- [Empirical results] Empirical results section: The reported structural drift is presented as generalizing beyond the specific models and tasks studied, yet the manuscript does not include controls for whether the observed evolution correlates with downstream task performance degradation or with changes in causal importance of the localized components. This is load-bearing for the 'free evolution' generalization.
minor comments (2)
- [Introduction] The abstract and introduction would benefit from explicit citation of prior work on circuit evolution or dynamic interpretability (e.g., studies tracking attention heads or MLP circuits across training checkpoints) to better situate the novelty of the proposed metrics.
- [Methods] Notation for the three metrics should be formalized with equations or pseudocode in the methods section to allow reproducibility; currently the descriptions remain high-level.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which identifies key areas for strengthening the validation of our metrics and the generalization of our findings. We address each major comment below and will incorporate revisions to enhance the manuscript.
read point-by-point responses
-
Referee: Abstract / metrics introduction: The central claim that static mechanisms 'inevitably suffer from temporal latency' and are 'fundamentally inadequate' rests on the three new metrics demonstrating 'Free Evolution.' However, the manuscript provides no ablation or comparison against established causal tools (activation patching, causal tracing, or path patching) to establish that Circuit Distance, Stability, and Conflict track task-relevant mechanisms rather than non-causal parameter noise. Without such validation, the inference from observed numerical drift to fundamental inadequacy of the locate-then-update paradigm does not follow.
Authors: We agree that direct validation against causal intervention methods is necessary to confirm our metrics track task-relevant mechanisms. The metrics were constructed to measure structural properties of circuits localized via standard interpretability techniques, with free evolution observed as consistent drift across training steps independent of the localization process. To address the concern, we will revise the paper by adding ablation experiments that compare metric values against activation patching and path patching outcomes, verifying alignment between numerical drift and changes in causal effects. These will be included in an expanded metrics validation subsection. revision: yes
-
Referee: Empirical results: The reported structural drift is presented as generalizing beyond the specific models and tasks studied, yet the manuscript does not include controls for whether the observed evolution correlates with downstream task performance degradation or with changes in causal importance of the localized components. This is load-bearing for the 'free evolution' generalization.
Authors: We acknowledge that explicit controls correlating drift with performance degradation and causal importance would bolster the generalization claim. Our current results demonstrate consistent free evolution across multiple models and tasks, supporting the temporal latency issue. In revision, we will add analyses correlating Circuit Distance and Stability with performance drops when applying static localizations to later training states, plus causal importance checks via patching to show that evolved components retain relevance. This will be integrated into the empirical results section to directly address the load-bearing requirement. revision: yes
Circularity Check
No circularity: central claim follows from direct empirical tracking of circuit evolution
full rationale
The paper's argument rests on systematic empirical tracking of Transformer circuit structural changes across SFT steps, using three newly introduced metrics (Circuit Distance, Circuit Stability, Circuit Conflict) to document 'Free Evolution'. The conclusion that static mechanisms suffer temporal latency is presented as a direct inference from these observations rather than any derivation, fitted parameter, or self-referential definition. No equations reduce a 'prediction' to an input by construction, and the provided text contains no load-bearing self-citations or uniqueness theorems imported from prior author work. The analysis is self-contained against external benchmarks via its empirical methodology.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Mechanistic interpretability techniques can reliably identify and track task-relevant circuits across training steps
- ad hoc to paper The proposed metrics (Circuit Distance, Stability, Conflict) capture the dimensions relevant to localization effectiveness
invented entities (1)
-
Free Evolution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of post-training scaling in large language models
Hanyu Lai, Xiao Liu, Junjie Gao, Jiale Cheng, Zehan Qi, Yifan Xu, Shuntian Yao, Dan Zhang, Jinhua Du, Zhenyu Hou, et al. A survey of post-training scaling in large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2771–2791, 2025
2025
-
[2]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[3]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[4]
Teaching large language models to reason with reinforcement learning
Alexander Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. Teaching large language models to reason with reinforcement learning. InAI for Math Workshop @ ICML 2024, 2024
2024
-
[5]
Editing large language models: Problems, methods, and opportunities
Yunzhi Yao, Peng Wang, Bozhong Tian, Siyuan Cheng, Zhoubo Li, Shumin Deng, Huajun Chen, and Ningyu Zhang. Editing large language models: Problems, methods, and opportunities. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 10222–10240, 2023
2023
-
[6]
Yuanpu Cao, Tianrong Zhang, Bochuan Cao, Ziyi Yin, Lu Lin, Fenglong Ma, and Jinghui Chen. Personalized steering of large language models: Versatile steering vectors through bi-directional preference optimization.Advances in Neural Information Processing Systems, 37:49519–49551, 2024
2024
-
[7]
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Qibo Xue, et al. Locate, steer, and improve: A practical survey of actionable mechanistic interpretability in large language models.arXiv preprint arXiv:2601.14004, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Depn: Detecting and editing privacy neurons in pretrained language models
Xinwei Wu, Junzhuo Li, Minghui Xu, Weilong Dong, Shuangzhi Wu, Chao Bian, and Deyi Xiong. Depn: Detecting and editing privacy neurons in pretrained language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2875–2886, 2023
2023
-
[9]
Effective skill unlearning through intervention and abstention
Yongce Li, Chung-En Sun, and Tsui-Wei Weng. Effective skill unlearning through intervention and abstention. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6358–6371, 2025
2025
-
[10]
Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
2022
-
[11]
Knowledge neurons in pretrained transformers
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. Knowledge neurons in pretrained transformers. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493–8502, 2022
2022
-
[12]
Lecheng Yan, Ruizhe Li, Guanhua Chen, Qing Li, Jiahui Geng, Wenxi Li, Vincent Wang, and Chris Lee. Spurious rewards paradox: Mechanistically understanding how rlvr activates memorization shortcuts in llms.arXiv preprint arXiv:2601.11061, 2026
-
[13]
Rethinking circuit completeness in language models: And, or, and adder gates
Hang Chen, Jiaying Zhu, Xinyu Yang, and Wenya Wang. Rethinking circuit completeness in language models: And, or, and adder gates. In D. Belgrave, C. Zhang, H. Lin, L. Montoya, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Advances in Neural Information Processing Systems, volume 38, pages 150511–150540. Curran Associates, Inc., 2025
2025
-
[14]
Does localization inform editing? surprising differences in causality-based localization vs
Peter Hase, Mohit Bansal, Been Kim, and Asma Ghandeharioun. Does localization inform editing? surprising differences in causality-based localization vs. knowledge editing in language models.Advances in Neural Information Processing Systems, 36:17643–17668, 2023. 11
2023
-
[15]
Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
2023
-
[16]
Attribution patching outperforms automated circuit discovery
Aaquib Syed, Can Rager, and Arthur Conmy. Attribution patching outperforms automated circuit discovery. InProceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, pages 407–416, 2024
2024
-
[17]
Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. Rethinking machine unlearning for large language models.Nature Machine Intelligence, 7(2):181–194, 2025
2025
-
[18]
Knowledge editing for large language models: A survey.ACM Computing Surveys, 57(3):1–37, 2024
Song Wang, Yaochen Zhu, Haochen Liu, Zaiyi Zheng, Chen Chen, and Jundong Li. Knowledge editing for large language models: A survey.ACM Computing Surveys, 57(3):1–37, 2024
2024
-
[19]
Visualizing and understanding neural models in nlp
Jiwei Li, Xinlei Chen, Eduard Hovy, and Dan Jurafsky. Visualizing and understanding neural models in nlp. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 681–691, 2016
2016
-
[20]
Language-specific neurons: The key to multilingual capabilities in large language models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Wayne Xin Zhao, Furu Wei, and Ji-Rong Wen. Language-specific neurons: The key to multilingual capabilities in large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5701–5715, 2024
2024
-
[21]
A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis
Alessandro Stolfo, Yonatan Belinkov, and Mrinmaya Sachan. A mechanistic interpretation of arithmetic reasoning in language models using causal mediation analysis. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7035–7052, 2023
2023
-
[22]
How large language models encode context knowledge? a layer-wise probing study
Tianjie Ju, Weiwei Sun, Wei Du, Xinwei Yuan, Zhaochun Ren, and Gongshen Liu. How large language models encode context knowledge? a layer-wise probing study. InProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 8235–8246, 2024
2024
-
[23]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
A mathematical framework for transformer circuits.Transformer Circuits Thread,
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Nova DasSarma, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. A...
-
[25]
https://transformer-circuits.pub/2021/framework/index.html
2021
-
[26]
Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, and Ziyu Yao. A practical review of mech- anistic interpretability for transformer-based language models.arXiv preprint arXiv:2407.02646, 2024
-
[27]
Wagle: Strategic weight attribution for effective and modular unlearning in large language models.Advances in Neural Information Processing Systems, 37:55620–55646, 2024
Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, and Sijia Liu. Wagle: Strategic weight attribution for effective and modular unlearning in large language models.Advances in Neural Information Processing Systems, 37:55620–55646, 2024
2024
-
[28]
Saes can improve unlearning: Dynamic sparse autoencoder guardrails for precision unlearning in llms
Aashiq Muhamed, Jacopo Bonato, Mona T Diab, and Virginia Smith. Saes can improve unlearning: Dynamic sparse autoencoder guardrails for precision unlearning in llms. InSecond Conference on Language Modeling, 2025
2025
-
[29]
Continual learning and private unlearning
Bo Liu, Qiang Liu, and Peter Stone. Continual learning and private unlearning. InConference on Lifelong Learning Agents, pages 243–254. PMLR, 2022
2022
-
[30]
Tofu: A task of fictitious unlearning for llms
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary Chase Lipton, and J Zico Kolter. Tofu: A task of fictitious unlearning for llms. InFirst Conference on Language Modeling, 2024. 12
2024
-
[31]
Negative preference optimization: From catastrophic collapse to effective unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. InFirst Conference on Language Modeling, 2024
2024
-
[32]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Stefan Heimersheim and Neel Nanda. How to use and interpret activation patching.arXiv preprint arXiv:2404.15255, 2024
-
[33]
Investigating gender bias in language models using causal mediation analysis.Advances in neural information processing systems, 33:12388–12401, 2020
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. Investigating gender bias in language models using causal mediation analysis.Advances in neural information processing systems, 33:12388–12401, 2020
2020
-
[34]
Causal scrub- bing, a method for rigorously testing interpretability hypotheses.AI Alignment Fo- rum, 2022
Lawrence Chan, Adrià Garriga-Alonso, Nicholas Goldwosky-Dill, Ryan Greenblatt, Jenny Nitishinskaya, Ansh Radhakrishnan, Buck Shlegeris, and Nate Thomas. Causal scrub- bing, a method for rigorously testing interpretability hypotheses.AI Alignment Fo- rum, 2022. https://www.alignmentforum.org/posts/JvZhhzycHu2Yd57RN/ causal-scrubbing-a-method-for-rigorously-testing
2022
-
[35]
Localizing Model Behavior with Path Patching , journal =
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
-
[36]
Circuit stability characterizes language model generalization
Alan Sun. Circuit stability characterizes language model generalization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9025–9040, 2025
2025
-
[37]
CLUE: Conflict-guided localization for LLM unlearning framework
Hang Chen, Jiaying Zhu, Xinyu Yang, and Wenya Wang. CLUE: Conflict-guided localization for LLM unlearning framework. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[38]
Guiding high-performance sat solvers with unsat-core predictions
Daniel Selsam and Nikolaj Bjørner. Guiding high-performance sat solvers with unsat-core predictions. InInternational conference on theory and applications of satisfiability testing, pages 336–353. Springer, 2019
2019
-
[39]
A simple and flexible way of computing small unsatisfiable cores in sat modulo theories
Alessandro Cimatti, Alberto Griggio, and Roberto Sebastiani. A simple and flexible way of computing small unsatisfiable cores in sat modulo theories. InInternational Conference on Theory and Applications of Satisfiability Testing, pages 334–339. Springer, 2007
2007
-
[40]
Alloy+ hotcore: A fast approximation to unsat core
Nicolás D’Ippolito, Marcelo F Frias, Juan P Galeotti, Esteban Lanzarotti, and Sergio Mera. Alloy+ hotcore: A fast approximation to unsat core. InInternational Conference on Abstract State Machines, Alloy, B and Z, pages 160–173. Springer, 2010
2010
-
[41]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InEMNLP, 2018
2018
-
[42]
Chris Mathwin, Guillaume Corlouer, Esben Kran, Fazl Barez, and Neel Nanda. Identifying a preliminary circuit for predicting gendered pronouns in gpt-2 small.URL: https://itch. io/jam/mechint/rate/1889871, page 2, 2023
-
[43]
Springer Nature, 2022
Ido Dagan, Dan Roth, Fabio Zanzotto, and Mark Sammons.Recognizing textual entailment: Models and applications. Springer Nature, 2022
2022
-
[44]
Interpretability in the wild: a circuit for indirect object identification in gpt-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. InThe Eleventh International Conference on Learning Representations
-
[45]
A circuit for python docstrings in a 4-layer attention-only transformer
Stefan Heimersheim and Jett Janiak. A circuit for python docstrings in a 4-layer attention-only transformer. InAlignment Forum, 2023
2023
-
[46]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. InProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, Seattle, Washington, USA, October 2013. Association for Co...
2013
-
[47]
Winogrande: An adversarial winograd schema challenge at scale. 2019. 13
2019
-
[48]
Tracr: Compiled transformers as a laboratory for interpretability.Advances in Neural Information Processing Systems, 36:37876–37899, 2023
David Lindner, János Kramár, Sebastian Farquhar, Matthew Rahtz, Tom McGrath, and Vladimir Mikulik. Tracr: Compiled transformers as a laboratory for interpretability.Advances in Neural Information Processing Systems, 36:37876–37899, 2023
2023
-
[49]
How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model.Advances in Neural Information Processing Systems, 36:76033–76060, 2023
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does gpt-2 compute greater-than?: Interpreting mathematical abilities in a pre-trained language model.Advances in Neural Information Processing Systems, 36:76033–76060, 2023
2023
-
[50]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. In Marilyn Walker, Heng Ji, and Amanda Stent, editors,Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long...
2018
-
[51]
Zero-shot relation extraction via reading comprehension
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading comprehension. In Roger Levy and Lucia Specia, editors,Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pages 333–342, Vancouver, Canada, August 2017. Association for Computational Linguistics
2017
-
[52]
Challenging big-bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging big-bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Compu- tational Linguistics: ACL 2023, pages 13003–13051, 2023
2023
-
[53]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwi...
2020
-
[54]
Lei Yu, Jingcheng Niu, Zining Zhu, and Gerald Penn. Functional faithfulness in the wild: Circuit discovery with differentiable computation graph pruning.arXiv preprint arXiv:2407.03779, 2024
-
[55]
Transformer feed-forward layers are key-value memories
Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. Transformer feed-forward layers are key-value memories. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 5484–5495, 2021
2021
-
[56]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review arXiv 2017
-
[57]
In-context learning and induction heads.Transformer Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, a...
2022
-
[58]
An information- theoretic parameter-free bayesian framework for probing labeled dependency trees from atten- tion score
Hongxu Liu, Jing Ma, Xiaojie Wang, Caixia Yuan, and Fangxiang Feng. An information- theoretic parameter-free bayesian framework for probing labeled dependency trees from atten- tion score. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[59]
knowledge
Vaidehi Patil, Peter Hase, and Mohit Bansal. Can sensitive information be deleted from llms? objectives for defending against extraction attacks. InThe Twelfth International Conference on Learning Representations, 2023. 14 A Details of Logical Circuit Framework At first, we systematically introduce three fundamental circuit logic types: theANDgate,ORgate,...
2023
-
[60]
Therefore, Mechanistic Localization for these knowledge-centric tasks genuinely imparts meaningful guidance for future parameter updates
MLP-dominated circuitsare significantly less prone to migration. Therefore, Mechanistic Localization for these knowledge-centric tasks genuinely imparts meaningful guidance for future parameter updates
-
[61]
foresight
Attention-dominated circuitsare highly susceptible to migration, leading to profound structural discrepancies across different parameter states. Consequently, Mechanistic Lo- calization for these skill-centric tasks suffers from severe temporal latency, rendering it ineffective for guiding dynamic updates. F Extended Analysis of Future Mechanistic Localiz...
-
[62]
Inherent Limitations of Circuit Discovery:The process of circuit discovery itself is notoriously difficult to scale to exceptionally large LLMs and imposes stringent requirements on data quality. Consequently, this computational bottleneck precludes further analysis under massive data and model scaling scenarios, thereby restricting the direct application...
-
[63]
Coupling of Localization and Parameter Update Mechanisms:Many contemporary Mechanistic Localization methodologies introduce bespoke parameter update techniques paired with their localization strategies; the effects of these two components are rarely strictly independent. Although employing standard SFT as our observational baseline allows us to capture un...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.