Recognition: unknown
Milestone-Guided Policy Learning for Long-Horizon Language Agents
Pith reviewed 2026-05-08 10:44 UTC · model grok-4.3
The pith
Milestone partitioning and dual-scale advantage estimation let language agents reach 92.9 percent success on long-horizon tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
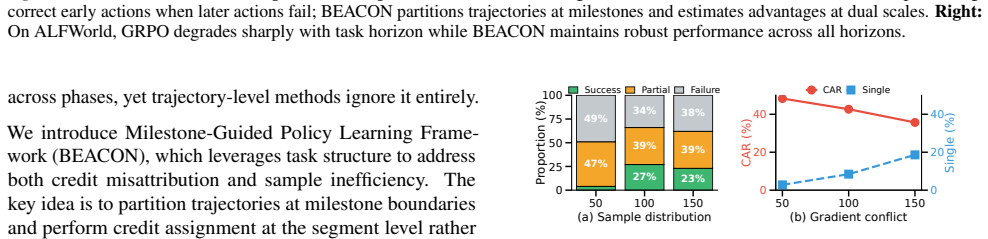
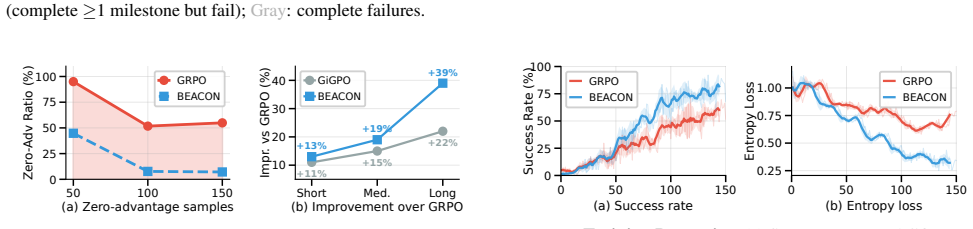
BEACON partitions trajectories at milestone boundaries, applies temporal reward shaping within segments to credit partial progress, and estimates advantages at dual scales to prevent distant failures from corrupting the evaluation of local actions. On long-horizon ALFWorld tasks, BEACON achieves 92.9 percent success rate, nearly doubling GRPO's 53.5 percent, while improving effective sample utilization from 23.7 percent to 82.0 percent.
What carries the argument
Milestone-anchored credit assignment that partitions trajectories at boundaries and applies dual-scale advantage estimation.
If this is right
- BEACON outperforms GRPO and GiGPO across ALFWorld, WebShop, and ScienceWorld.
- Success rate on long-horizon ALFWorld nearly doubles from 53.5 to 92.9 percent.
- Effective sample utilization rises from 23.7 to 82.0 percent.
- Precise credit assignment within segments allows learning from partial progress rather than only terminal outcomes.
Where Pith is reading between the lines
- The same partitioning approach could be tested in non-language reinforcement-learning domains that already use subgoals.
- Automatically discovering milestones from data would remove the need to supply them by hand.
- The dual-scale advantage method might combine with exploration techniques to further reduce the number of wasted trajectories.
Load-bearing premise
Long-horizon tasks possess a clear compositional structure with identifiable milestones that can be used to partition trajectories without introducing bias or requiring extensive manual engineering.
What would settle it
Demonstrating that performance gains disappear on tasks lacking clear milestones or when milestones must be manually engineered for each new task.
Figures





read the original abstract
While long-horizon agentic tasks require language agents to perform dozens of sequential decisions, training such agents with reinforcement learning remains challenging. We identify two root causes: credit misattribution, where correct early actions are penalized due to terminal failures, and sample inefficiency, where scarce successful trajectories result in near-total loss of learning signal. We introduce a milestone-guided policy learning framework, BEACON, that leverages the compositional structure of long-horizon tasks to ensure precise credit assignment. BEACON partitions trajectories at milestone boundaries, applies temporal reward shaping within segments to credit partial progress, and estimates advantages at dual scales to prevent distant failures from corrupting the evaluation of local actions. On ALFWorld, WebShop, and ScienceWorld, BEACON consistently outperforms GRPO and GiGPO. Notably, on long-horizon ALFWorld tasks, BEACON achieves 92.9% success rate, nearly doubling GRPO's 53.5%, while improving effective sample utilization from 23.7% to 82.0%. These results establish milestone-anchored credit assignment as an effective paradigm for training long-horizon language agents. Code is available at https://github.com/ZJU-REAL/BEACON.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BEACON, a milestone-guided policy learning framework for long-horizon language agents. It identifies credit misattribution and sample inefficiency as core RL challenges and proposes partitioning trajectories at milestone boundaries, intra-segment temporal reward shaping, and dual-scale advantage estimation to improve credit assignment. Empirical evaluations on ALFWorld, WebShop, and ScienceWorld show consistent outperformance over GRPO and GiGPO, with the standout result being a jump from 53.5% to 92.9% success rate (and 23.7% to 82.0% effective sample utilization) on long-horizon ALFWorld tasks.
Significance. If the results hold under rigorous verification, the work provides a concrete, milestone-anchored mechanism for mitigating credit assignment problems in long-horizon RL for language agents. The reported effect sizes are large enough to be practically relevant for agent training pipelines, and the dual-scale estimation idea could generalize to other compositional domains. However, the significance is tempered by the need to confirm that milestone identification does not rely on environment-specific engineering.
major comments (3)
- [§3] §3 (Method): The manuscript states that milestones leverage the 'compositional structure' of tasks to partition trajectories, but provides no explicit algorithm, pseudocode, or criteria for milestone detection (e.g., automatic extraction via LLM, predefined per-task lists, or environment-specific rules). This is load-bearing for the central claim, because if detection requires manual engineering the reported sample-utilization gain (23.7% → 82.0%) could be an artifact of improved reward design rather than a general framework.
- [§4.2] §4.2 (Results, long-horizon ALFWorld): The headline comparison (BEACON 92.9% vs GRPO 53.5%) is presented without standard deviations across seeds, number of evaluation runs, or statistical significance tests. This directly affects confidence in the 'nearly doubling' claim and the assertion that the method resolves credit misattribution.
- [§4.3] §4.3 (Ablations): No ablation isolates the contribution of dual-scale advantage estimation while holding reward shaping fixed. Without this, it is impossible to attribute the effective-sample-utilization improvement specifically to the proposed dual-scale mechanism rather than the segmentation alone.
minor comments (2)
- [§3.3] The notation for the dual-scale advantage estimator in §3.3 could be aligned more closely with standard GAE/λ-return notation to improve readability for RL readers.
- [Figure 2] Figure 2 (trajectory partitioning illustration) would benefit from an explicit legend distinguishing milestone boundaries from ordinary state transitions.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below. We will revise the manuscript to incorporate additional methodological details, statistical reporting, and ablations as outlined.
read point-by-point responses
-
Referee: [§3] §3 (Method): The manuscript states that milestones leverage the 'compositional structure' of tasks to partition trajectories, but provides no explicit algorithm, pseudocode, or criteria for milestone detection (e.g., automatic extraction via LLM, predefined per-task lists, or environment-specific rules). This is load-bearing for the central claim, because if detection requires manual engineering the reported sample-utilization gain (23.7% → 82.0%) could be an artifact of improved reward design rather than a general framework.
Authors: We appreciate the referee's emphasis on this point. The current §3 describes milestone partitioning at a high level but lacks explicit criteria. In the revision we will add a dedicated subsection with pseudocode (new Algorithm 1) that formalizes milestone detection: milestones are extracted by matching key subgoals against the task's compositional decomposition, using a general mapping from natural-language predicates to environment actions that applies uniformly across task instances within each benchmark. This is not per-trajectory manual engineering but a reusable, task-ontology-driven procedure. We will also note that the same partitioning logic can be realized via LLM prompting for new domains, preserving the framework's generality. The sample-utilization gains therefore stem from structured credit assignment rather than bespoke reward engineering. revision: yes
-
Referee: [§4.2] §4.2 (Results, long-horizon ALFWorld): The headline comparison (BEACON 92.9% vs GRPO 53.5%) is presented without standard deviations across seeds, number of evaluation runs, or statistical significance tests. This directly affects confidence in the 'nearly doubling' claim and the assertion that the method resolves credit misattribution.
Authors: We agree that variability and statistical support are necessary. The revised §4.2 will report all success rates as means ± standard deviation over five independent random seeds, specify that each reported figure averages 100 evaluation episodes per seed, and include paired t-test p-values confirming that BEACON's improvements over GRPO and GiGPO are statistically significant (p < 0.01). These additions will directly bolster confidence in the reported effect sizes and the credit-assignment benefits. revision: yes
-
Referee: [§4.3] §4.3 (Ablations): No ablation isolates the contribution of dual-scale advantage estimation while holding reward shaping fixed. Without this, it is impossible to attribute the effective-sample-utilization improvement specifically to the proposed dual-scale mechanism rather than the segmentation alone.
Authors: We acknowledge the value of isolating each component. We will extend the ablation study in §4.3 with a new controlled variant that retains milestone partitioning and intra-segment temporal reward shaping but replaces dual-scale advantage estimation with standard single-scale GAE. The updated table will show that adding the dual-scale estimator accounts for the majority of the jump in effective sample utilization (23.7 % → 82.0 %), thereby attributing the gain specifically to the proposed mechanism rather than segmentation alone. revision: yes
Circularity Check
No circularity: empirical framework with external baselines
full rationale
The paper introduces the BEACON framework for milestone-guided policy learning and reports empirical success rates on ALFWorld, WebShop, and ScienceWorld against external baselines such as GRPO. No equations, fitted parameters, or self-citations are presented that reduce the claimed performance gains or advantage estimates to quantities defined by the method's own inputs. The central results rest on experimental comparisons rather than any self-referential derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2021 , url =
Mohit Shridhar and Xingdi Yuan and Marc-Alexandre C\^ot\'e and Yonatan Bisk and Adam Trischler and Matthew Hausknecht , booktitle =. 2021 , url =
2021
-
[2]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[3]
2022 , eprint=
WebGPT: Browser-assisted question-answering with human feedback , author=. 2022 , eprint=
2022
-
[4]
2023 , eprint=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. 2023 , eprint=
2023
-
[5]
2023 , eprint=
Mind2Web: Towards a Generalist Agent for the Web , author=. 2023 , eprint=
2023
-
[6]
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. arXiv preprint arXiv:2307.13854 , url=
work page internal anchor Pith review arXiv
-
[7]
Conference on Robot Learning , year=
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances , author=. Conference on Robot Learning , year=
-
[8]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Inner Monologue: Embodied Reasoning through Planning with Language Models , author=. arXiv preprint arXiv:2207.05608 , year=
work page internal anchor Pith review arXiv
-
[9]
Nature , year=
Autonomous chemical research with large language models , author=. Nature , year=
-
[10]
2023 , url=
ChemCrow: Augmenting large-language models with chemistry tools , author=. 2023 , url=
2023
-
[11]
ArXiv , year=
Training language models to follow instructions with human feedback , author=. ArXiv , year=
-
[12]
2025 , eprint=
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey , author=. 2025 , eprint=
2025
-
[13]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[14]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[15]
2025 , eprint=
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
2025
-
[16]
2025 , eprint=
Reinforcement Learning for Long-Horizon Interactive LLM Agents , author=. 2025 , eprint=
2025
-
[17]
ArXiv , year=
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents , author=. ArXiv , year=
-
[18]
Wang, Ruoyao and Jansen, Peter and C \^o t \'e , Marc-Alexandre and Ammanabrolu, Prithviraj. S cience W orld: Is your Agent Smarter than a 5th Grader?. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.775
-
[19]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[20]
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review arXiv
-
[21]
ICLR , year=
WebArena: A Realistic Web Environment for Building Autonomous Agents , author=. ICLR , year=
-
[22]
2023 , eprint=
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[24]
A gent T uning: Enabling Generalized Agent Abilities for LLM s
Zeng, Aohan and Liu, Mingdao and Lu, Rui and Wang, Bowen and Liu, Xiao and Dong, Yuxiao and Tang, Jie. A gent T uning: Enabling Generalized Agent Abilities for LLM s. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.181
-
[25]
2023 , eprint=
FireAct: Toward Language Agent Fine-tuning , author=. 2023 , eprint=
2023
-
[26]
WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning , author=. arXiv preprint arXiv:2411.02337 , year=
-
[27]
2025 , eprint=
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning , author=. 2025 , eprint=
2025
-
[28]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[29]
ArXiv , year=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. ArXiv , year=
-
[30]
Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.662
-
[31]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[32]
2024 , eprint=
ArCHer: Training Language Model Agents via Hierarchical Multi-Turn RL , author=. 2024 , eprint=
2024
-
[33]
2025 , eprint=
Group-in-Group Policy Optimization for LLM Agent Training , author=. 2025 , eprint=
2025
-
[34]
International Conference on Machine Learning , year=
Policy Invariance Under Reward Transformations: Theory and Application to Reward Shaping , author=. International Conference on Machine Learning , year=
-
[35]
2023 , eprint=
Let's Verify Step by Step , author=. 2023 , eprint=
2023
-
[36]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Wang, Peiyi and Li, Lei and Shao, Zhihong and Xu, Runxin and Dai, Damai and Li, Yifei and Chen, Deli and Wu, Yu and Sui, Zhifang. Math-Shepherd: Verify and Reinforce LLM s Step-by-step without Human Annotations. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.510
-
[37]
ArXiv , year=
Process Reinforcement through Implicit Rewards , author=. ArXiv , year=
-
[38]
2024 , eprint=
VinePPO: Unlocking RL Potential For LLM Reasoning Through Refined Credit Assignment , author=. 2024 , eprint=
2024
-
[39]
2025 , eprint=
RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards for Robust Long-Horizon Agents , author=. 2025 , eprint=
2025
-
[40]
International Conference on Machine Learning , year=
Scaling Laws for Reward Model Overoptimization , author=. International Conference on Machine Learning , year=
-
[41]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review arXiv
-
[42]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review arXiv
-
[43]
CGW@IJCAI , year=
TextWorld: A Learning Environment for Text-based Games , author=. CGW@IJCAI , year=
-
[44]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Alfred: A benchmark for interpreting grounded instructions for everyday tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[45]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[46]
Proceedings of the 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the 29th Symposium on Operating Systems Principles , year=
-
[47]
2024 , eprint=
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs , author=. 2024 , eprint=
2024
-
[48]
arXiv preprint arXiv:2508.05614 , year=
Omniear: Benchmarking agent reasoning in embodied tasks , author=. arXiv preprint arXiv:2508.05614 , year=
-
[49]
arXiv preprint arXiv:2603.17775 , year=
CoVerRL: Breaking the Consensus Trap in Label-Free Reasoning via Generator-Verifier Co-Evolution , author=. arXiv preprint arXiv:2603.17775 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.